一、什么是爬虫
网络爬虫,也叫网络蜘蛛(Web Spider)。它根据网页地址(URL)爬取网页内容,而网页地址(URL)就是我们在浏览器中输入的网站链接。
URL 专业一些的叫法是统一资源定位符(Uniform Resource Locator),它的一般格式如下(带方括号[]的为可选项):
protocol :// hostname[:port] / path / [;parameters][?query]#fragment
URL 的格式主要由前个三部分组成:
- protocol:第一部分就是协议,例如百度使用的就是https协议;
- hostname[:port]:第二部分就是主机名(还有端口号为可选参数),一般网站默认的端口号为80,例如百度的主机名就是www.baidu.com,这个就是服务器的地址;
- path:第三部分就是主机资源的具体地址,如目录和文件名等。
网络爬虫就是根据这个 URL 来获取网页信息的。
还是,以百度为例,举个简单的例子:
http://www.baidu.com:80
https://www.baidu.com:443
这两个URL都可以打开网页,区别在于一个是 http 协议,一个是 https 协议。
http协议默认使用的端口是80,https协议默认使用的端口是443。
每一个URL的背后,其实都是对应着一台服务器的,甚至成千上万台。
通俗一点讲,URL就是每个服务器的地址。例如,老王家住在北京市朝阳区,老李家住在北京市海淀区。
你想串门溜达去,就得通过这个URL家庭地址,找到他们。
如果有一天,你想去老王家,跟他老婆聊聊天,你仅仅知道老王家住在北京市朝阳区是不够的。
因为,你还得知道他家在哪个楼,几单元,几零几。
对应ULR上,也就是你光知道hostname不够,你还得有个更详细的地址,那就得补充path:
https://cuijiahua.com/blog/spider/
比如,cuijiahua.com 是我的 hostname,想找到爬虫系列的文章,还得去 blog 目录下的spider目录下找,这个就是具体的地址path。
老王家的详细家庭住址知道了,如果你还想夜晚去,并且趁着老王不在,与老王的老婆聊聊天。
那这个情况就有点复杂了。不仅需要知道 protocol 、hostname 和 path,你还得满足一些条件,这个条件就是[;parameters][?query]#fragment,这些东西。
比如,为了完成此次夜探老王家的目标,你可能大概需要这样的 URL:
https://chaoyanglaowang.com/2haolou/3danyuan/702/s?laowangzaijia=0&baitian=0
这个 URL 的意思就是,baitian=0表明是晚上,laowangzaiji=0表示老王不在家,在满足这个条件的时候,你进了2号楼3单元702的朝阳区老王家,就可以夜探老王家了。
?laowangzaiji=0&baitian=0,这是一种询问,在这个条件下访问。
二、审查元素
在讲解爬虫内容之前,我们需要先学习一项写爬虫的必备技能:审查元素。
在浏览器的地址栏输入 URL 地址,在网页处右键单击,找到检查。(不同浏览器的叫法不同,Chrome 浏览器叫做检查,Firefox 浏览器叫做查看元素,但是功能都是相同的)
浏览器就是作为客户端从服务器端获取信息,然后将信息解析,并展示给我们的。我们可以在本地修改 HTML 信息,为网页”整容”,但是我们修改的信息不会回传到服务器,服务器存储的 HTML 信息不会改变。刷新一下界面,页面还会回到原本的样子。这就跟人整容一样,我们能改变一些表面的东西,但是不能改变我们的基因。
三、简单示例
- 1.requests库安装
pip install requests
- 2.requests库的基础用法
import requestsif __name__ == '__main__':target = "http://fanyi.baidu.com/"req = requests.get(url = target)req.encoding = 'utf-8'print(req.text)
二、Python爬虫架构
Python 爬虫架构主要由五个部分组成,分别是调度器、URL管理器、网页下载器、网页解析器、应用程序(爬取的有价值数据)。
- 调度器:相当于一台电脑的CPU,主要负责调度URL管理器、下载器、解析器之间的协调工作。
URL管理器:包括待爬取的URL地址和已爬取的URL地址,防止重复抓取URL和循环抓取URL,实现URL管理器主要用三种方式,通过内存、数据库、缓存数据库来实现。 - 网页下载器:通过传入一个URL地址来下载网页,将网页转换成一个字符串,网页下载器有urllib2(Python官方基础模块)包括需要登录、代理、和cookie,requests(第三方包)
- 网页解析器:将一个网页字符串进行解析,可以按照我们的要求来提取出我们有用的信息,也可以根据DOM树的解析方式来解析。网页解析器有正则表达式(直观,将网页转成字符串通过模糊匹配的方式来提取有价值的信息,当文档比较复杂的时候,该方法提取数据的时候就会非常的困难)、html.parser(Python自带的)、beautifulsoup(第三方插件,可以使用Python自带的html.parser进行解析,也可以使用lxml进行解析,相对于其他几种来说要强大一些)、lxml(第三方插件,可以解析 xml 和 HTML),html.parser 和 beautifulsoup 以及 lxml 都是以 DOM 树的方式进行解析的。
- 应用程序:就是从网页中提取的有用数据组成的一个应用。
下面用一个图来解释一下调度器是如何协调工作的: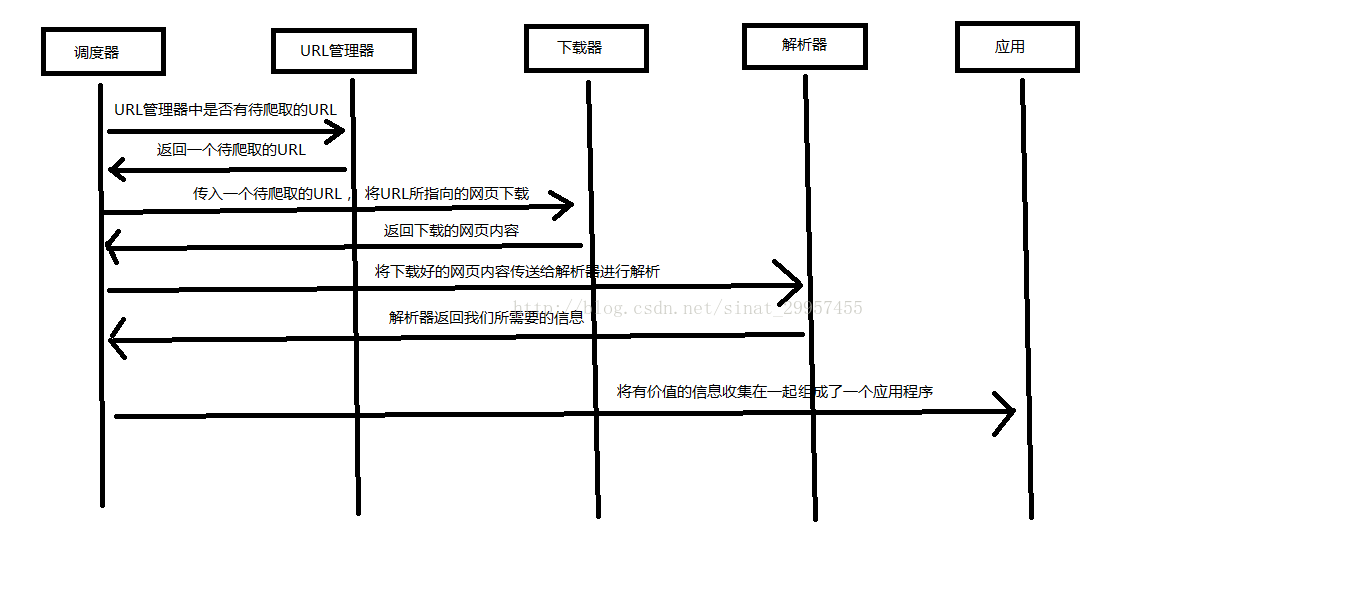
2.爬虫步骤
大致分三个步骤:
- 发起请求:明确如何发起Http请求,获取到数据;
- 解析数据:获取到杂乱的数据,对数据进行清理;
- 保存数据:保存为自己想要的格式。
发起请求就用requests
解析数据有xpath、Beautiful Soup、正则表达式等,本文用BeautifulSoup
保存数据:用常规的文本保存,后续继续用docx和xlsx保存
3.Beautiful Soup
pip install bs4

若有收获,就点个赞吧
0 人点赞
