一、背景
疫情期间,每天需要搜集新冠肺炎相关新闻,编写了一个python脚本用户爬取新浪网相关新闻
二、实例解析
- 模块:requests、BeautifulSoup、re
url:https://search.sina.com.cn/?q=新冠&c=news&sort=time
1.初始化
定义一个GetNews类,在init中写入初始化参数
class GetNews:def __init__(self,keyword,name):self.headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36 Edg/88.0.705.74','Referer':'https://search.sina.com.cn/'}self.keyword=keywordself.txtname=nameself.news_url=[] #存储每条新闻的urlself.news_title=[] #存储每条新闻的标题self.news_content=[] #存储新闻内容self.news_time=[] #存储新闻的发表时间self.page_cout=0 #搜索结果的页码
2.获取搜索结果的页码
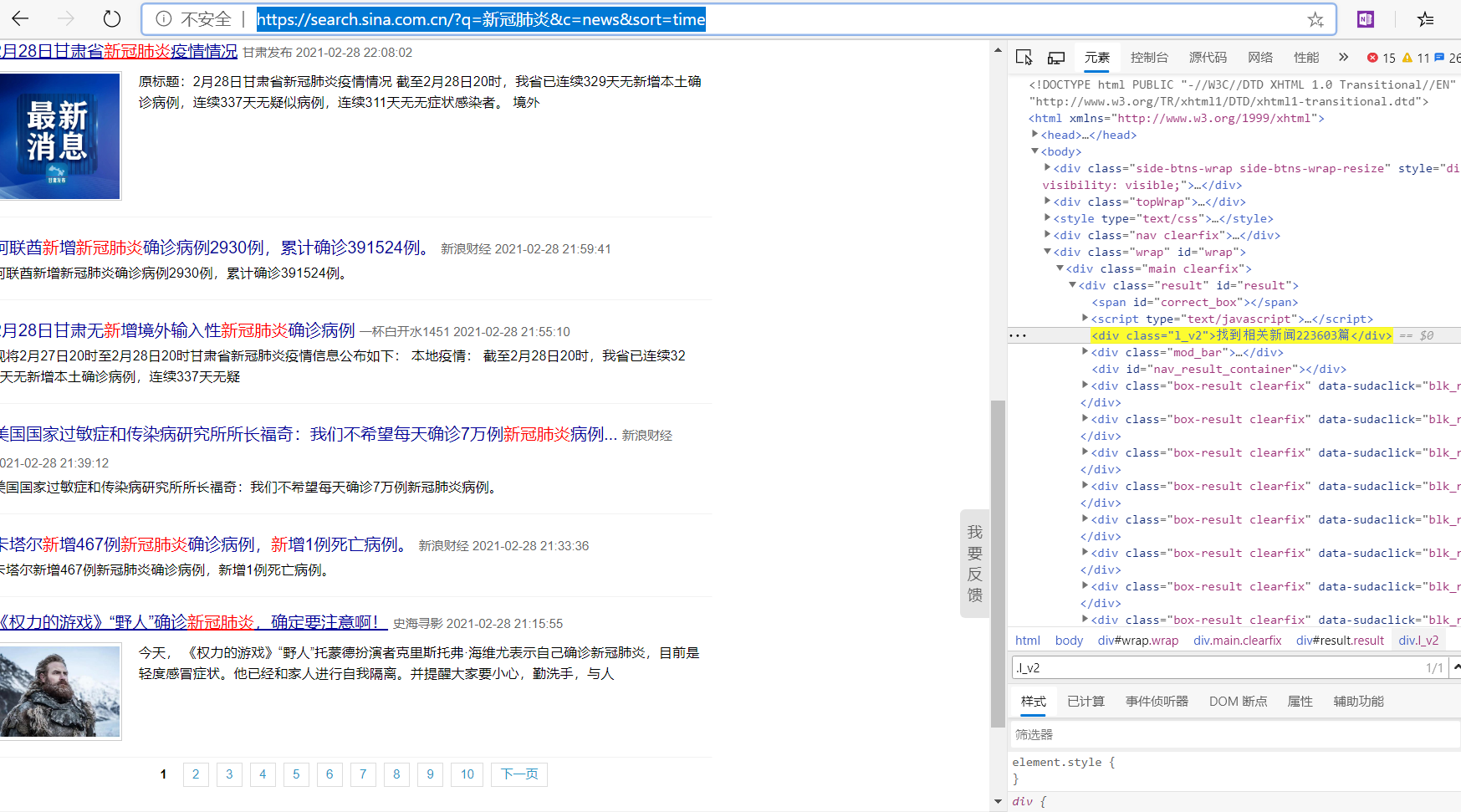
如上图所示,新浪的搜索结果是分页保存的,先获取搜索结果的总页数,可用于后续爬取所以相关新闻。
def get_page_cout(self):url = 'https://search.sina.com.cn/?q={0}&c=news&from=channel&ie=utf-8'.format(self.keyword) #查找的关键字urlresponse = requests.get(url)response.encoding = 'utf-8'html =response.textsoup =BeautifulSoup(html,'lxml')try:page = soup.select('.l_v2')[0].textexcept Exception as e:page = ''print(e)if page !='' :purl = ''self.page_cout = re.findall(r'[0-9]\d*',page)for x in self.page_cout:purl = purl+xprint(purl)self.page_cout = int(purl)//20 +1 #总的页数else:self.page_cout = 0return self.page_cout
3.获取新闻页的具体链接
- 检查网页元素,找到新闻链接保存在h2下的a标签中
利用a.text和a.get(‘href’)分别获取新闻的标题和链接
#获取新闻链接def get_news_url(self):url = 'https://search.sina.com.cn/?q={0}&c=news&from=&col=&range=all&source=&country=&size=10&stime=&etime=&time=&dpc=0&a=&ps=0&pf=0&page={1}'count =input('共找到{}页信息,输入需要爬取的页数(输入【a】将爬取全部):'.format(self.page_cout))if count=='a':count = self.page_coutprint('开始爬取新闻链接....')for x in range(1,int(count)):url=url.format(self.keyword,x)req=requests.get(url=url)req.encoding='utf-8'soup=BeautifulSoup(req.text,'lxml')div=soup.find_all('h2')a_bs=BeautifulSoup(str(div),'lxml')a=a_bs.find_all('a')for each in a:self.news_title.append(each.text)self.news_url.append(each.get('href'))
3.获取新闻页的具体内容
利用检查元素找到新闻内容和时间具体位置,再利用soup.select和re.findall去查找获取就行了
#获取新闻内容def get_news_content(self):print('开始爬取新闻内容....')for url in self.news_url:req=requests.get(url)req.encoding='utf-8'soup=BeautifulSoup(req.text,'lxml')#获取新闻发布时间reg_time=soup.select('div.date-source>span.date')str_time=re.findall('<span class="date">(.*?)</span>',str(reg_time),re.S)self.news_time.append(str_time)#获取新闻内容reg_content=soup.select('#article')data=re.findall('<p cms-style="font-L">(.*?)</p>',str(reg_content),re.S) #re.S参数,多行匹配str_data=''.join(data).replace('\u3000\u3000','\n\u3000\u3000') #将data中的数组拼成一个字符串,以|u3000全角空白符换行显示res=r'<font cms-style=".*">.*?</font>'if re.search(res,str_data) !='':str_data=re.sub(res,'',str_data) #去掉内容中多余的标签self.news_content.append(str_data)
4.保存新闻内容
将新闻的标题、时间、内容写入txt文档中
def writer(self):print('开始写入文本....')write_flag = Truewith open(self.txtname, 'w', encoding='utf-8') as f:for i in range(len(self.news_title)):if self.news_content[i]!='':f.writelines(self.news_title[i])f.writelines('\n')f.writelines(self.news_time[i])f.writelines(self.news_content[i])else:continuef.write('\n\n')f.close()
5.运行
if __name__=='__main__':keyword='新冠肺炎'name='0301.txt'gn=GetNews(keyword,name)gn.get_page_cout()gn.get_news_url()gn.get_news_content()gn.writer()print('sucsuss')
三、小结
新浪网的新闻页HTML格式不统一,获取的新闻链接、内容的select位置不统一,所以本文中的代码只爬取了
(.*?)
这个位置中的内容,不是这个格式就找不到,如果要匹配所有内容,修改下正则表达式就可以了。

若有收获,就点个赞吧
0 人点赞
