一、背景
前段时间写了个爬虫获取新浪的新闻,但新浪新闻页面文档页格式不统一,新闻质量也较差,经过筛选,环球时报上面的新闻质量稍好,且页面格式比较统一。
二、实例解析
1.思路
- 我们这里主要获取环球时报上面的国际新闻
- 国际性新闻URL:https://world.huanqiu.com/
爬取新闻的三步法:解析主页上面的新闻链接——>解析每个新闻链接里面的内容——>格式化文本写入文档
2.新闻链接解析
常规套路,打开主页,检查元素,找到一个新闻的元素位置

容易发现上图中,“多米尼克”新闻的元素位置如下:
selector为”#recomend li a”,但写入代码后,可以发现是找不到这个元素的,可以猜测是动态加载的网页
- 同样的可以验证,打开主页源代码,我们搜索这条新闻是搜索不到的。

- 点击检查元素的‘网络’选项卡,容易发现该网页动态加载的,在‘预览’中可以发现包含了当前页面的20条新闻数据,Json格式保存;
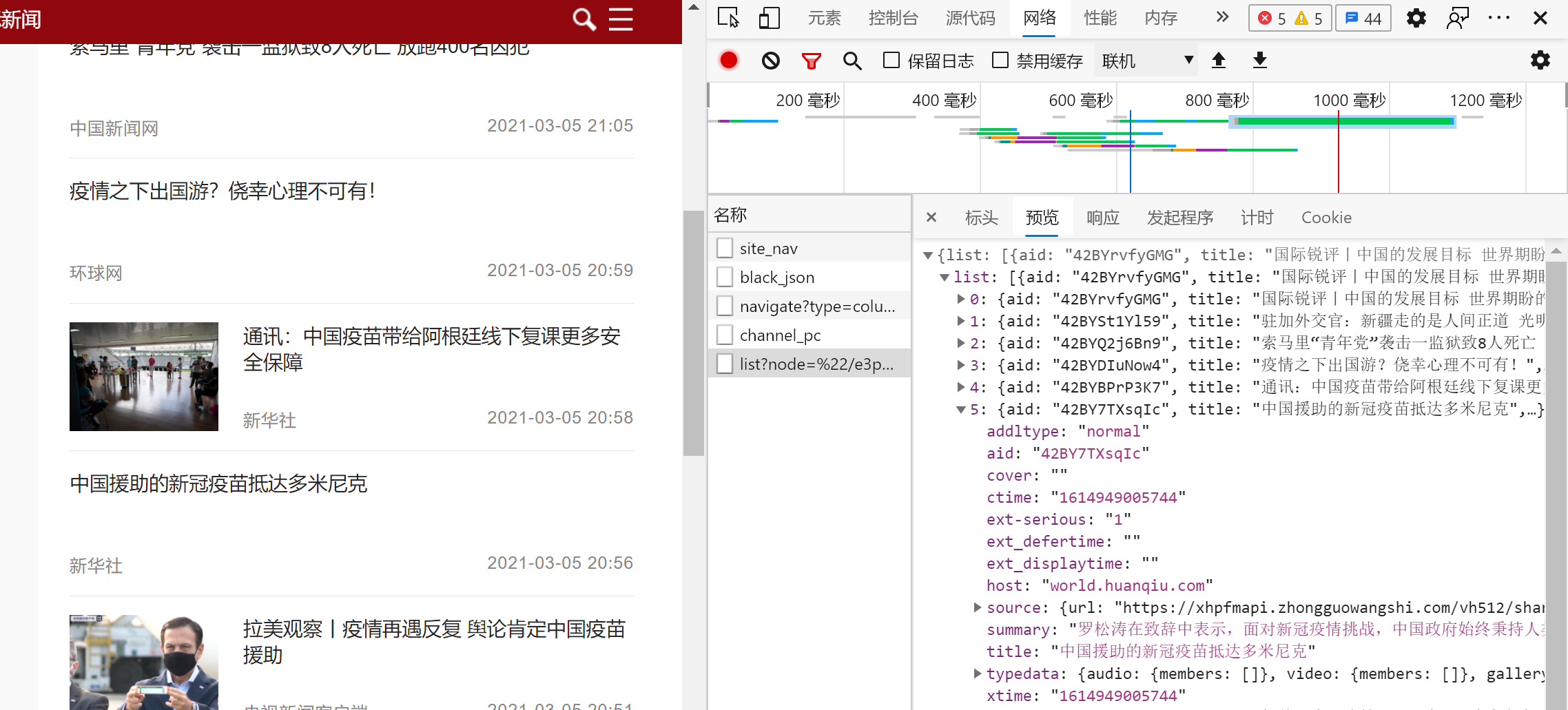
- 接下来就是拼凑新闻链接
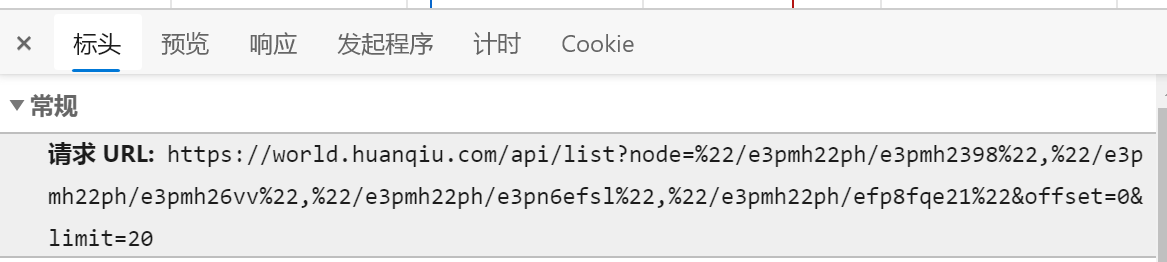
- 这里主要关注下url中的offset为偏移量,通俗的讲就是页码,offset=0即为第1页,offset=20即为第2页,依次类推
接着解析每条新闻的地址,jsons数据中,aid即为该新闻的保存名,如aid为42BY7TXsqIc,那么该新闻的链接就是:https://world.huanqiu.com/article/42BY7TXsqIc;title为标题名,我们从json中获取这两条就够了
下面是新闻链接解析模块的代码
#获取新闻链接keyword='新冠'count=int(input('请输入爬取页码数(1,2,3.....):'))news_title=[]news_url=[]headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36 Edg/88.0.705.81","Cookie":'''UM_distinctid=177f21c29bf10d-043ddbd82b4eef-7a667166-144000-177f21c29c039b; _ma_tk=hewd6oh2rs0o2mqybcrd3s60un56m46w; REPORT_UID_=cJ869QdbSP132oZ6591juDJYZZ8wK0SC; Hm_lvt_1fc983b4c305d209e7e05d96e713939f=1614674668,1614738118,1614738291,1614908983; CNZZDATA1000010102=1231572127-1614671036-https%253A%252F%252Fwww.huanqiu.com%252F%7C1614914069; Hm_lpvt_1fc983b4c305d209e7e05d96e713939f=1614914406'''}path = 'https://world.huanqiu.com/api/list?node=%22/e3pmh22ph/e3pmh2398%22,%22/e3pmh22ph/e3pmh26vv%22,%22/e3pmh22ph/e3pn6efsl%22,%22/e3pmh22ph/efp8fqe21%22&offset={0}&limit=20'print('开始爬取新闻链接...')for i in tqdm(range(0,count)):try:url=path.format(20*i) #offset为20res = requests.get(url,headers=headers)if res.content:items=res.json().get('list')for item in items:title=item.get('title')aid=item.get('aid')if keyword in str(title) and title not in news_title: #筛选关键词url='https://world.huanqiu.com/article/'+str(aid)news_title.append(item.get('title'))news_url.append(url)else:print('无内容')except res.ConnectionError:print('error')
3.新闻内容解析
内容解析就很简单了,选定元素位置循环起来就ok了

#获取新闻内容news_content=[]news_time=[]news_source=[]print('开始爬取新闻内容....')for url in tqdm(news_url):req=requests.get(url)req.encoding='utf-8'soup=BeautifulSoup(req.text,'lxml')#获取新闻发布时间和来源reg_source=soup.select('div.metadata-info')str_source=re.findall('<a href=".*">(.*)</a>',str(reg_source),re.S)news_source.append(str_source)str_time=re.findall('<p class="time">(.*)</p>',str(reg_source),re.S)news_time.append(str_time)#获取新闻内容reg_content=soup.select('.l-con.clear')str_data=re.findall('<p>(.*?)</p>',str(reg_content),re.S) #re.S参数,多行匹配str_data=''.join(str_data) #将data中的数组拼成一个字符串#剔除<i>标签中的内容pat_str1='<i class="pic-con">.*</i>'pat_str2='<em data-scene="strong">.*</em>' #剔除:<em data-scene="strong">海外网3月5日电</em>str_data=re.sub(pat_str1,'',str_data)str_data=re.sub(pat_str2,'',str_data)news_content.append(str_data)
4.保存文本
#写入txt文本print('开始写入文本....')write_flag = Truetxtname='0305.txt'with open(txtname, 'w', encoding='utf-8') as f:for i in range(len(news_title)):if news_content[i]!='':f.writelines(news_title[i])f.writelines('\n')f.writelines(news_source[i])f.writelines('\n')f.writelines(news_time[i])f.writelines('\n')f.writelines(news_content[i])else:continuef.write('\n\n\n')f.close()
三、小结
- 动态网页的爬取,关键在于解析新闻链接,通过抓包分析出请求链接和json数据包,从中找到关键信息即可
四、代码
```python import requests import re import json from urllib.parse import urlencode from bs4 import BeautifulSoup from tqdm import tqdm
下载新闻链接
keyword=’新冠’ count=int(input(‘请输入爬取页码数(1,2,3…..):’)) newstitle=[] news_url=[] headers = { “User-Agent”: “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36 Edg/88.0.705.81”, “Cookie”:’’’UM_distinctid=177f21c29bf10d-043ddbd82b4eef-7a667166-144000-177f21c29c039b; _ma_tk=hewd6oh2rs0o2mqybcrd3s60un56m46w; REPORT_UID=cJ869QdbSP132oZ6591juDJYZZ8wK0SC; Hm_lvt_1fc983b4c305d209e7e05d96e713939f=1614674668,1614738118,1614738291,1614908983; CNZZDATA1000010102=1231572127-1614671036-https%253A%252F%252Fwww.huanqiu.com%252F%7C1614914069; Hm_lpvt_1fc983b4c305d209e7e05d96e713939f=1614914406’’’ } path = ‘https://world.huanqiu.com/api/list?node=%22/e3pmh22ph/e3pmh2398%22,%22/e3pmh22ph/e3pmh26vv%22,%22/e3pmh22ph/e3pn6efsl%22,%22/e3pmh22ph/efp8fqe21%22&offset={0}&limit=20‘
print(‘开始爬取新闻链接…’)
for i in tqdm(range(0,count)):
try:
url=path.format(20*i) #offset为20
res = requests.get(url,headers=headers)
if res.content:
items=res.json().get(‘list’)
for item in items:
title=item.get(‘title’)
aid=item.get(‘aid’)
if keyword in str(title) and title not in news_title: #筛选关键词
url=’https://world.huanqiu.com/article/'+str(aid)
news_title.append(item.get(‘title’))
news_url.append(url)
else:
print(‘无内容’)
except res.ConnectionError:
print(‘error’)
获取新闻内容
news_content=[]
news_time=[]
news_source=[]
print(‘开始爬取新闻内容….’)
for url in tqdm(news_url):
req=requests.get(url)
req.encoding=’utf-8’
soup=BeautifulSoup(req.text,’lxml’)
#获取新闻发布时间和来源reg_source=soup.select('div.metadata-info')str_source=re.findall('<a href=".*">(.*)</a>',str(reg_source),re.S)news_source.append(str_source)str_time=re.findall('<p class="time">(.*)</p>',str(reg_source),re.S)news_time.append(str_time)#获取新闻内容reg_content=soup.select('.l-con.clear')str_data=re.findall('<p>(.*?)</p>',str(reg_content),re.S) #re.S参数,多行匹配str_data=''.join(str_data) #将data中的数组拼成一个字符串#剔除<i>标签中的内容pat_str1='<i class="pic-con">.*</i>'pat_str2='<em data-scene="strong">.*</em>' #剔除:<em data-scene="strong">海外网3月5日电</em>str_data=re.sub(pat_str1,'',str_data)str_data=re.sub(pat_str2,'',str_data)news_content.append(str_data)
写入txt文本
print(‘开始写入文本….’)
write_flag = True
txtname=’0305.txt’
with open(txtname, ‘w’, encoding=’utf-8’) as f:
for i in tqdm(range(len(news_title))):
if news_content[i]!=’’:
f.writelines(news_title[i])
f.writelines(‘\n’)
f.writelines(news_source[i])
f.writelines(‘\n’)
f.writelines(news_time[i])
f.writelines(‘\n’)
f.writelines(news_content[i])
else:
continue
f.write(‘\n\n\n\n’)
f.close()
print(‘—-结束—-‘) ```

若有收获,就点个赞吧
0 人点赞
