所有胶囊检测中的特征的状态的重要信息,都将以向量的形式被胶囊封装。
CNN的缺陷
CNN着力于检测图像像素中的重要特征。考虑简单的人脸检测任务,一张脸是由代表脸型的椭圆、两只眼睛、一个鼻子和一个嘴巴组成。而基于CNN的原理,只要存在这些对象就有一个很强的刺激,而组件的朝向和空间上的相对关系对CNN来说并不是很重要。
这看起来并不是一张十分正确的人脸图,虽然图中包含了人脸的每一个组成部分。人类可以很容易分辨出这不是一张正确的人脸,但是CNNs却很难判断这不是一张真实的人脸,因为它仅仅看图像中的这些特征,而没有注意这些特征的姿态信息。(组织之间相对的位置信息)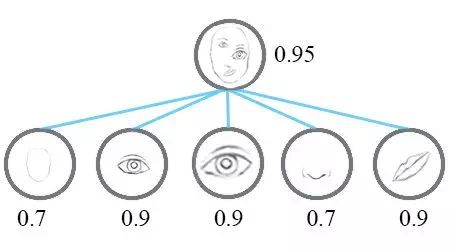
胶囊网络(capsule networks)解决这个问题的方法是,实现对空间信息进行编码同时也计算物体的存在概率。这可以用向量来表示,向量的模表示特征存在的概率,向量的方向表示特征的姿态信息。如果对象有轻微的变化(例如移位、旋转、改变大小等),那么胶囊将输出相同长度但方向略有不同的向量,因此,胶囊是等变化的(Equivariance)。
胶囊网络通过重现它检测到的对象,然后将重现结果与训练数据中的标记示例进行比较来学习如何预测。通过反复的学习,它将可以实现较为准确的实例参数预测。
常使用两个损失函数。主要是为了实现capsules之间的等效性。这意味着,在图像中移动特征会改变Capsule向量,但是不影响特征存在的概率。底层Capsules提取特征之后,就传递到匹配的更高层的Capsules。
如上图所示,所有特征的姿态参数用来决定最后结果。
胶囊内的操作
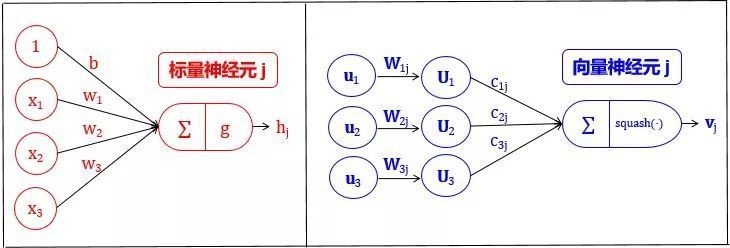
在传统神经网络里,一个神经元一般会进行如下的标量操作:
- 输入标量的标量加权;
- 对加权后的标量求和;
- 对和进行非线性变换生成新标量。
而在胶囊网络里面,这些操作有有一些的改变:
- 输入向量与权重矩阵的矩阵乘法。这编码了图像中低级特征和高级特征之间非常重要的空间关系。
- 加权输入向量。这些权重决定当前胶囊将其输出发送到哪个更高级的胶囊。这是通过动态路由(dynamic routing)的过程完成的。
- 对加权后的向量求和。 (这一点没什么差别)
- 非线性化使用squash函数。该函数将向量进行压缩使得它的最大长度为1,最小长度为0,同时保持其方向不变。**
研究内容
胶囊是什么
简单来说,可以理解成:
- 人造神经元输出单个标量。卷积网络运用了卷积核从而使得将同个卷积核对于二维矩阵的各个区域计算出来的结果堆叠在一起形成了卷积层的输出。
- 通过最大池化方法来实现视角不变性,因为最大池持续搜寻二维矩阵的区域,选取区域中最大的数字,所以满足了我们想要的活动不变性(即我们略微调整输入,输出仍然一样),换句话说,在输入图像上我们稍微变换一下我们想要检测的对象,模型仍然能够检测到对象
- 池化层损失了有价值的信息,同时也没有考虑到编码特征间的相对空间关系,因此我们应该使用胶囊,所有胶囊检测中的特征的状态的重要信息,都将以向量形式被胶囊封装(神经元是标量)

囊间动态路由算法
低层胶囊i 需要决定如何将其输出向量发送给高层胶囊 j 。低层胶囊改变标量权重c,输出向量乘以该权重后,发送给高层胶囊,作为高层胶囊的输入。关于权重c,需要知道有:
- 权重均为非负标量
- 对每个低层胶囊i 而言,所有权重c的总和等于1
- 对每个低层胶囊i 而言,权重的数量等于高层胶囊的数量
- 这些权重由迭代动态路由算法确定
低层胶囊将其输出发送给对此表示“同意”的高层胶囊,算法伪码如下:
权重更新可以用如下图来直观理解。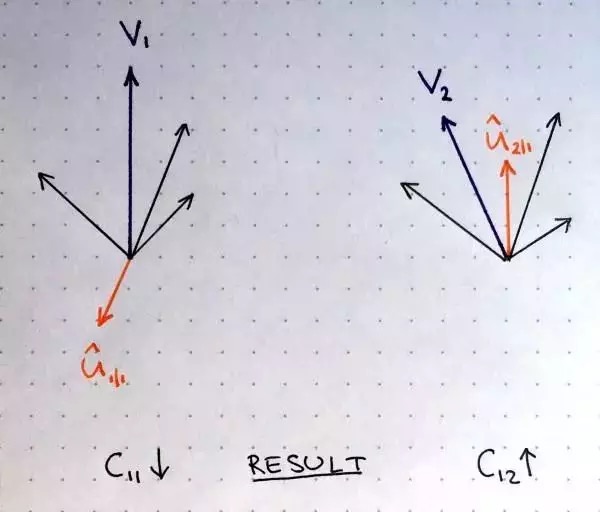
其中两个高层胶囊的输出用紫色向量 v 和 v 表示,橙色向量表示接受自某个低层胶囊的输入,其他黑色向量表示接受其他低层胶囊的输入。左边的紫色输出 v 和橙色输入 u 指向相反的方向,所以它们并不相似,这意味着它们点积是负数,更新路由系数的时候将会减少 c 。右边的紫色输出 v 和橙色输入 u 指向相同方向,它们是相似的,因此更新参数的时候路由系数 c 会增加。在所有高层胶囊及其所有输入上重复应用该过程,得到一个路由参数集合,达到来自低层胶囊的输出和高层胶囊输出的最佳匹配。采用多少次路由迭代?
论文在MNIST和CIFAR数据集上检测了一定范围内的数值,得到以下结论:
- 更多的迭代往往会导致过拟合
-
整体框架
CapsNet由两部分组成:编码器和解码器。前3层是编码器,后3层是解码器:
第一层:卷积层
- 第二层:PrimaryCaps(主胶囊)层
- 第三层:DigitCaps(数字胶囊)层
- 第四层:第一个全连接层
- 第五层:第二个全连接层
-
编码器
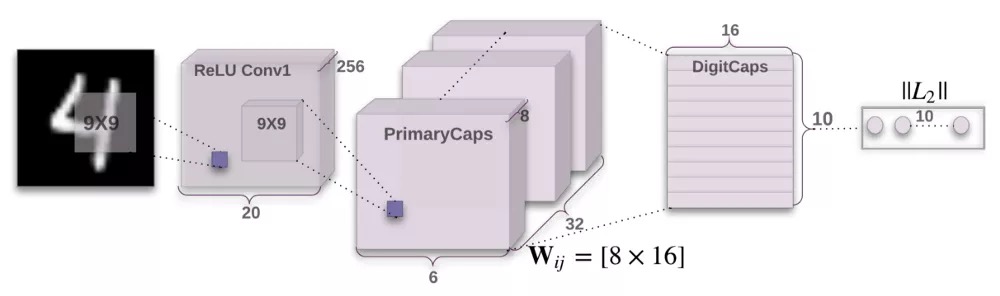 编码器接受一张28×28的MNIST数字图像作为输入,将它编码为实例参数构成的16维向量。
编码器接受一张28×28的MNIST数字图像作为输入,将它编码为实例参数构成的16维向量。
卷积层 输入:28×28图像(单色)
- 输出:20×20×256张量
- 卷积核:256个步长为1的9×9×1的核
- 激活函数:ReLU
PrimaryCaps层(32个胶囊)
- 输入:20×20×256张量
- 输出:6×6×8×32张量(共有32个胶囊)
- 卷积核:8个步长为1的9×9×256的核/胶囊
DigitCaps层(10个胶囊)
- 输入:6×6×8×32张量
-
损失函数
解码器
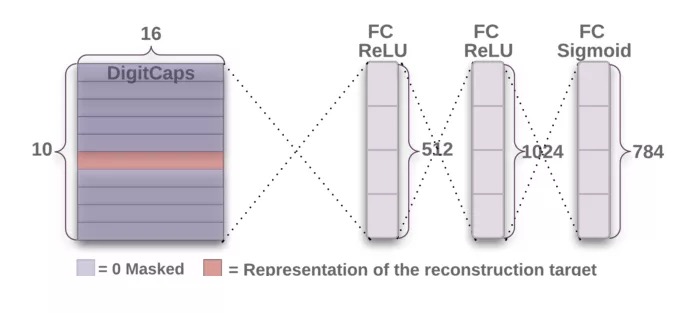
解码器从正确的DigitCap中接受一个16维向量,并学习将其编码为数字图像(注意,训练时候只采用正确的DigitCap向量,而忽略不正确的DigitCap)。解码器用来作为正则子,它接受正确的DigitCap的输出作为输入,重建一张28×28像素的图像,损失函数为重建图像和输入图像之间的欧式距离。解码器强制胶囊学习对重建原始图像有用的特征,重建图像越接近输入图像越好,下面展示重建图像的例子。
第一个全连接层 输入:16×10矩阵
- 输出:512向量

第二个全连接层
- 输入:512向量
- 输出:1024向量
第三个全连接层
- 输入:1024向量
- 输出:784向量
胶囊网络优点
- 由于胶囊网络集合了位姿信息,因此其可以通过一小部分数据即学习出很好的表示效果,所以这一点也是相对于CNN的一大提升。举个例子,为了识别手写体数字,人脑需要几十个最多几百个例子,但是CNN却需要几万规模的数据集才能训练出好结果,这显然还是太暴力了
更加贴近人脑的思维方式,更好地建模神经网络中内部知识表示的分层关系,胶囊背后的直觉非常简单优雅。
胶囊网络缺点
胶囊网络的当前实现比其他现代深度学习模型慢很多(我觉得是更新耦合系数以及卷积层叠加影响的),提高训练效率是一大挑战。
- 在简单的数据集MNIST上表现出了很好的性能,但是在更复杂的数据集如ImageNet、CIFAR-10上,却没有这种表现。这是因为在图像中发现的信息过多会使胶囊脱落。

若有收获,就点个赞吧
0 人点赞
