什么东西适合用AI?AI能帮助我们做那些事情?
2.3.1、底层逻辑
思考计算机擅长什么?
熟悉递推关系式,对于用计算机进行实际计算有很大的帮助。这是因为计算机不擅长导数计算,但擅长处理递推关系式。
2.3.2、数据
传统的编程基于规则,我们认为制定好规则,计算机负责计算。而AI 最核⼼的底层逻辑是:「基于数据」,给大量的数据去喂养计算机 。
基于数据简单说就是:从海量数据中找规律,这些规律是很抽象的,并不能总结成具象的规则。⽐如:给机器看海量的猫和狗的照⽚,它就具备了「区分猫和狗」的能力;给机器海量的中英⽂对照⽂章,它就具备了「中英⽂翻译」的能⼒给机器海量的⽂章,它甚⾄可以具备「写⽂章」的能⼒
基于数据的好处是:只要有⾜够多的优质数据,那么机器就能学会某些技能,数据越多, 能力越强。
但是基于数据的⽅法也有明显的弊端:机器只能告诉你「是什么」,但是⽆法告诉你「为什么」。(柯洁:半人半狗)
没有数据,就⽆从基于数据。所以想要⽤⼈⼯智能,需要考虑业务场景的数据3要素:
- 数据可获取
- 数据全⾯且完整,最好有人为的标注结果
- 海量的数据
特征
并非所有问题都需要 AI 来解决,AI 的优势是可以处理海量的特征,不但可以处理表面的特征,还能找到背后隐藏的特征。但是很多情况下,没必要用大炮打蚊子。能够有效归纳出一些规则的问题,都不太需要 AI,而那些很难总结归纳出规则的问题可以考虑使用 AI 来解决。
当我们把特征数量和确定性画一个坐标,就能指导我们什么问题适合用 AI,什么问题不适合用:
持续学习
基于规则的能力边界很小,很多实际问题无法通过规则的方法来解决。人工智能可以扩大计算机的能力边界。
除了扩大能力边界外,人工智能还有一个非常重要的特性——持续学习,不断提升能力上限。
所以:让机器持续的学习,是人工智能的灵魂。想要利用人工智能技术来解决实际问题,你必须考虑2个问题:
- 我需要解决的问题是动态变化的吗?需要持续学习的能力吗?
- 我能否让人工智能实现持续学习?
想要让机器实现持续学习的能力,需要具备2个条件:
- 是否可以获得反馈数据?
- 数据是否可以形成闭环?
所谓的数据闭环就是将“行动 – 反馈 – 修正 – 再行动”循环自动的在机器上运转,完全不需要人参与。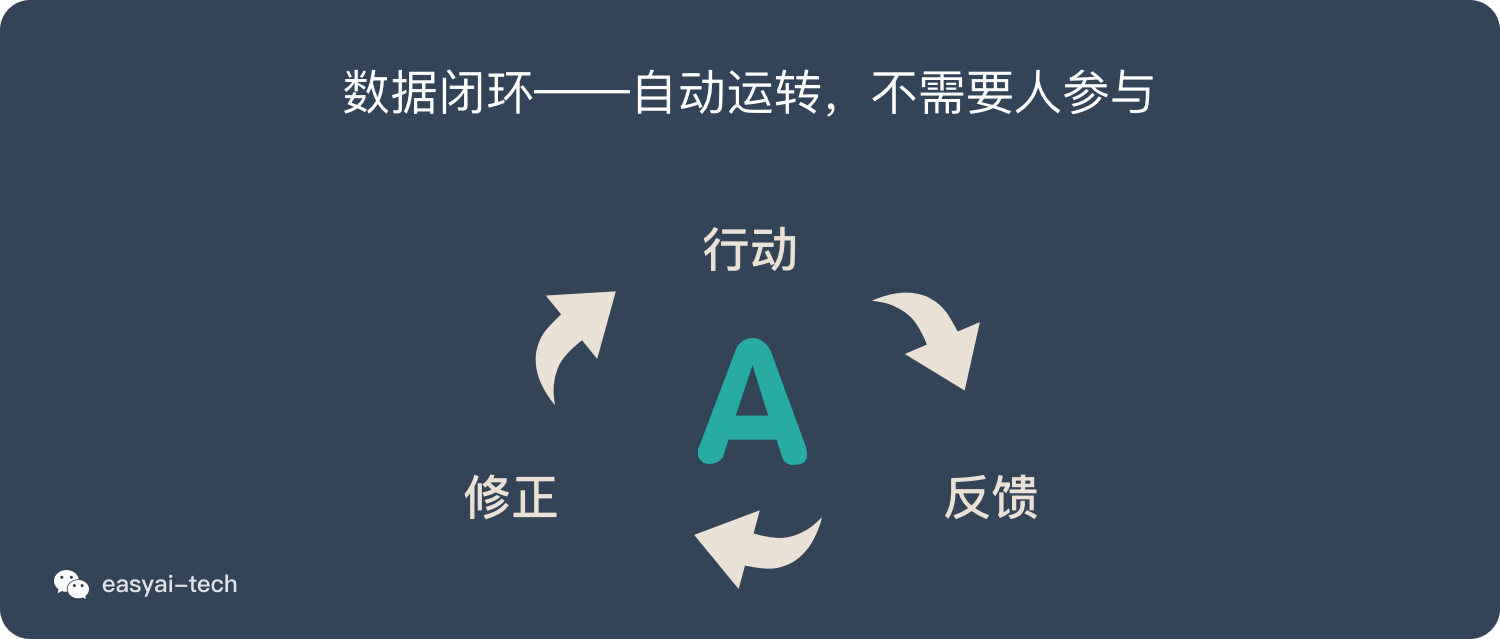
黑箱是人工智能的缺点
并非所有人工智能都是黑箱的,大家说的黑箱主要指当下最热门、效果也最好的“深度学习”。
深度学习的工作原理不是讲逻辑(基于规则),而是大力出奇迹(基于统计)。
大力出奇迹会导致几个结果:
- 深度学习只能告诉你“是什么”,但是不能告诉你“为什么”
- 没人能预知在什么情况下会出现错误
而最可怕的是:当我们发现问题时,并不能针对具体问题来对症下药。
我们过去的计算机科学大部分是基于规则的,很像一台汽车,我们很清楚的知道这台车是如何组装起来的,所以发现螺丝松了就柠紧,哪个零件老化了就换一个。完全可以做到对症下药。
而深度学习则完全不一样,当我们发现问题时,不能做到对症下药,只能全局优化(比如灌更多的数据)。
**
哪些问题不适合“依赖” AI ?
由于深度学习的黑箱特性,并非所有问题都适合用深度学习来解决。
我们评估哪些问题适合,哪些问题不适合的时候,可以从2个角度来评估:
- 是否需要解释
- 错误容忍度
我们先从这2个角度来看看普及率较高的AI应用:
| 案例 | 是否需要解释 | 错误容忍度 |
|---|---|---|
| 语音识别 | 用户只关心效果好不好,并不关心背后的原理是什么 | 偶尔出现一些错误并不影响对整句话的理解。少量出错是可以接受的。 |
| 人脸识别 | 同上 | 相比语音识别,用户对出错的容忍度要低一些,因为需要重新刷脸。 |
| 机器翻译 | 同上 | 跟语音识别类似,只要大面上准确,并不影响整体的理解。 |
我们再看一些 AI 和人力结合的具体应用:
| 案例 | 是否需要解释 | 错误容忍度 |
|---|---|---|
| 智能客服 | 用户不关心是人工服务还是机器服务,只要能解决我的问题就行 | 如果机器客服不能理解我的意图,无法帮我解决问题,用户会很不满意。所以当机器搞不定 的时候需要人工来补位 |
| 内容审核 | 对于审核不通过的内容,需要解释原因。通过的内容不需要解释为什么。 | 有一种职业叫“鉴黄师”,目前正在逐步被机器替代,但是并没有完全替代,因为有时候机器会拿不准,这个时候人工来复审 |
最后看一些不适合AI落地的场景:
| 案例 | 是否需要解释 | 错误容忍度 |
|---|---|---|
| 推导定理 | 科学是绝对严谨的,一定是从逻辑上推导出来的,而不是统计出来的。 | 如果有例外就不能称作定理,一定是绝对正确没有错误的。 |
| 写论文 | 人工智能已经可以写小说,诗歌,散文。但是论文这种文体要求非常严谨的上下文逻辑。 | 论文里是不允许有错误的,全文的逻辑要非常清晰,哪怕一个细节出现了逻辑问题,也会造成整篇论文没有价值。 |
如果我们把上面提到的案例全部放在象限中,大致如下: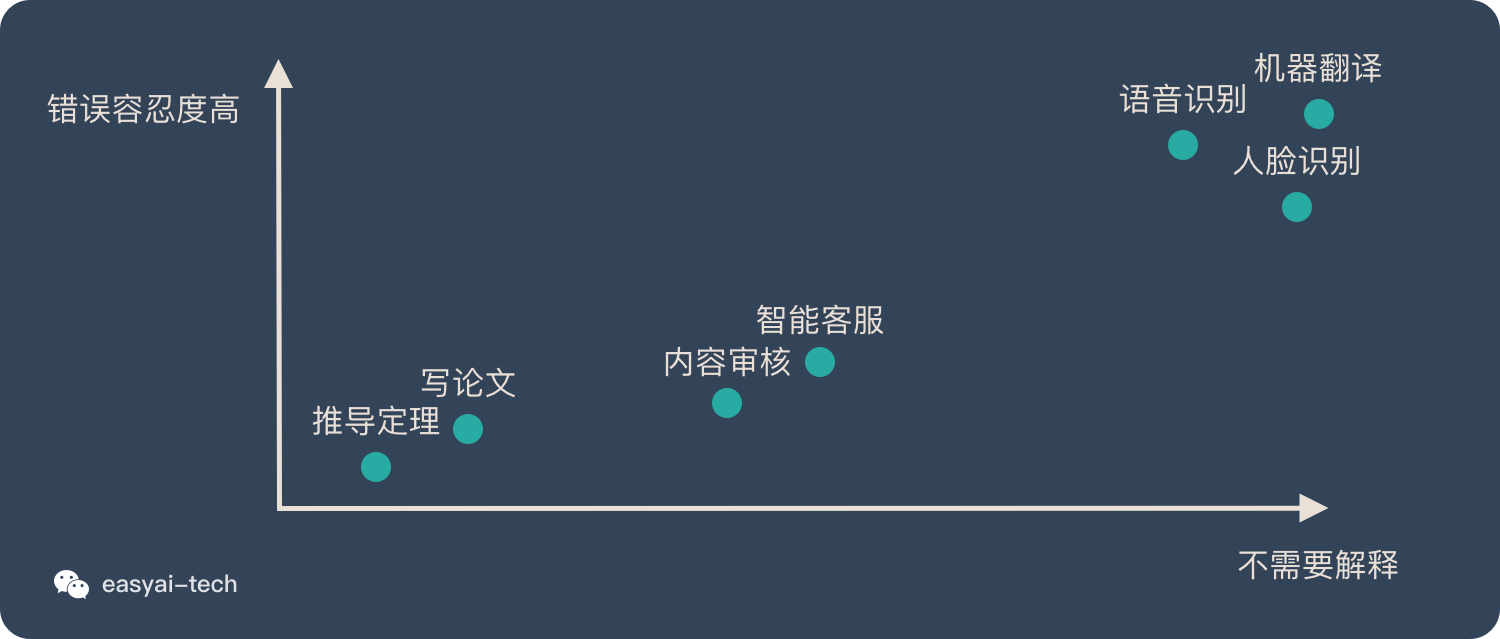
所以,在评估的时候有3条原则:
- 解决方案越需要解释背后的原因,越不适合用深度学习
- 对错误的容忍度越低,越不适合使用深度学习
上面2条并非绝对判断标准,还需要看商业价值和性价比,自动驾驶和医疗就是反例。
案例分析:医疗
人工智能在医疗行业的应用被大家广泛看好,因为医疗行业有很多痛点:
医疗资源不足,尤其是优质的医生
- 医疗资源的分配极度不均衡,中国很多疾病只有北京能治
- 其实医生的误诊率也很高(恶性肿瘤误诊率40%,器官异位误诊率60%)
目前的人工智能已经可以帮助人类做诊断并提供治疗手段。
奇怪的是:无论是从可解释性还是从错误的容忍度上来讲,医疗诊断都不适合用人工智能。
但当我们将人工智能作为一种辅助,最终还是靠人类来做判断和下决定时。人类和机器可以形成很好的互补。

若有收获,就点个赞吧
0 人点赞
