雾散了,露出一片雄伟的古老森林。古老的铁杉,数不清的,在你的头顶上形成了一个绿色的大教堂。树叶上的彩色玻璃华盖把阳光碎裂成金色的薄雾。在巨大的树干之间,你可以看到远处的大片森林。
这是我们作为游戏开发者所梦想的一种超凡脱俗的设定,而像这样的场景往往是由一种模式所促成的,这种模式的名字再普通不过了:不起眼的Flyweight。
独木成林
我三言两语即可描绘出一片盘根错节的林地,但真要去在实际的游戏中实现它可就两说了。游戏中我们在屏幕上看到的满眼森林,在图形程序员眼里则是每六十分之一秒就得在GPU上处理的数百万个多边形。
我们讨论的是成千的树木,每棵都是细节满满,包含上千多边形的几何结构。就算内存足够挥霍,想要去渲染这个图形,数据必须能从CPU到GPU的总线上传输过去。
每棵树都维系有一串比特位:
- 一个多边形的网格,定义了树干、树枝和绿色植物的形状。
- 树皮和叶子的纹理。
- 它在森林中的位置和方向。
- 调整大小和颜色等参数,使每棵树看起来都不同。
简单写成代码大概是这个样子:
class Tree{private:Mesh mesh_;Texture bark_;Texture leaves_;Vector position_;double height_;double thickness_;Color barkTint_;Color leafTint_;};
这数据量可不小,尤其是网格和纹理。整个森林对象对于一帧内的GPU来说实在是太多工作了。幸运的是,有一个久经考验的技巧来处理这个问题。
关键的观察结果是,尽管森林里可能有成千上万棵树,但它们大多看起来很相似。它们可能都使用相同的网格和纹理。这意味着这些对象中的大多数字段在所有这些实例之间是相同的。
钱多人傻才会要想让艺术家们为整片森林中的每棵树分别制作模型。
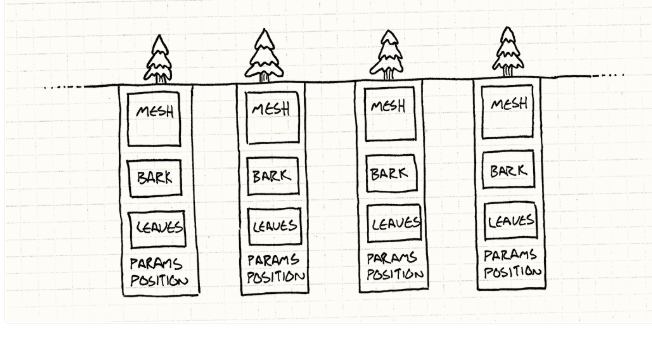
注意每棵树小盒子中的内容都是相同的。
我们可以通过将对象一分为二来显式地对其建模。首先,我们提取所有树共有的数据,并将其移动到一个单独的类中:
class TreeModel{private:Mesh mesh_;Texture bark_;Texture leaves_;};
游戏只需其中之一,因为没有理由在内存中持有一千个相同的网格和纹理。
然后,环境中树的每个实例都有对共享的 TreeModel 的一个引用。剩下的部分就是每个实例独立的状态了:
class Tree{private:TreeModel* model_;Vector position_;double height_;double thickness_;Color barkTint_;Color leafTint_;};
画出来大概就是这个样子: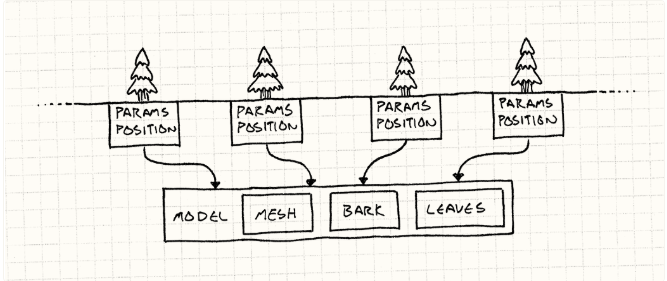
看起来这很像Type Object 模式。两者都涉及将对象的部分状态委托给一些实例之间共享的其他对象。 然而,两者用意是不同的。 使用类型对象,目标是通过将“类型”提升到您自己的对象模型中来最小化必须定义的类的数量。从中获得的任何内存共享都是一种加成。Flyweight模式纯粹是为了提高效率。
这种资源共享节省了内存,但对渲染没有帮助。在树登上屏幕前,它还必须要经过GPU。我们需要以显卡能够理解的方式来表达这种资源共享。
上千实例
为了最小化我们必须推送到GPU的数据量,我们希望能够发送共享数据—— TreeModel ———一次就好。然后,我们分别遍历每个树实例的唯一数据——它的位置、颜色和比例。最后,我们告诉GPU,“使用那个模型来渲染每个实例。”
幸运的是,今天的图形api和卡片恰好支持这一点。细节是繁琐的,超出了这本书的范围,但Direct3D和OpenGL都可以做一些所谓的实例渲染。
在这两个api中,都提供了两种数据流。第一个是将被呈现多次的公共大型二进制数据——我们树木例子中的网格和材质。第二个是实例及其参数的列表,这些实例及其参数将用于在每次绘制第一块数据时进行更改。只需绘制一次即可展现森林之全貌。
这个API是通过显卡直接实现的,这一事实意味着Flyweight模式可能是唯一具有实际硬件支持的设计模式四人组。 译者注设计模式四人组即:Erich Gamma, Richard Helm, Ralph Johnson, John Vlissides.他们是《设计模式》一书的作者。
享元模式
现在我们已经有了一个具体的例子,我可以向您介绍一般的模式。Flyweight,正如它的名字所暗示的那样,当有需要使用更轻量的对象时它就会发挥作用,而这通常是因为程序持有了太多的对象。
有了实例渲染,不是说会占用太多内存而耗时,更多的时间被用在将总线上的每一棵单独的树推送给GPU,但基本思想是一样的。
该模式通过将对象的数据分为两类来解决这个问题。第一类数据不是特定于该对象的一个实例的,而是可以跨所有实例共享的。设计模式四人组称之为内部状态,但我喜欢把它看作“上下文无关”的东西。在这个例子中,它就是树的几何和纹理。
剩下的数据就是外部状态,实例中独一无二的东西。在本例中,这是每棵树的位置、比例和颜色。就像上面的示例代码块一样,该模式通过在对象出现的每个地方共享一个内部状态副本来节省内存。
从我们目前看到的情况来看,这似乎是基本的资源共享,不值得称为模式。部分原因在于,在本例中,我们可以为共享状态提供一个明确的单独标识: TreeModel 。
我认为这种模式在共享对象没有真正定义良好的标识的情况下会更不明显(也因此显得更机智巧妙)。在这些情况下,感觉更像是一个对象神奇地同时出现在多个地方。容我再举个例子。
落地生根
现在使树生长的土地也需要在游戏中表现出来了。可以是一片片的草地、泥土、山丘、湖泊、河流,或者你能想象到的其他任何地形。我们会以基于瓦片产生地表:世界的表面是一个由微小的瓦片构成的巨大网格。每块瓦片都覆盖着一种地形。
每种地形类型都有一些影响游戏玩法的属性:
- 决定玩家移动快慢的消耗。
- 一个标记,标识能过船的水面
- 渲染的材质
因为我们这些游戏程序员对效率非常在意,所以我们不可能将所有的状态都存储在世界上的每个块中。相反,一种常用的方法是对地形类型使用枚举类型:
毕竟,我们已经从那些树中吸取了教训。
enum Terrain{TERRAIN_GRASS,TERRAIN_HILL,TERRAIN_RIVER// Other terrains...};
然后世界就会维护一个巨大的网格:
class World{private:Terrain tiles_[WIDTH][HEIGHT];};
这里我们使用了二维数组保存2D网格。在C/C++中这很有效率,因为它将把所有的元素打包在一起。在Java或其他内存管理型语言中,这样做实际上会给你一个行数组,其中每个元素都是对列数组的引用,这可能不像你希望的那样对内存友好。 在这两种情况下,真正的代码最好将这个实现细节隐藏在一个漂亮的2D网格数据结构后面。我这样做只是为了简单。
为了获得真正有用的瓦片数据,我们可以这样做:
int World::getMovementCost(int x, int y){switch (tiles_[x][y]){case TERRAIN_GRASS: return 1;case TERRAIN_HILL: return 3;case TERRAIN_RIVER: return 2;// Other terrains...}}bool World::isWater(int x, int y){switch (tiles_[x][y]){case TERRAIN_GRASS: return false;case TERRAIN_HILL: return false;case TERRAIN_RIVER: return true;// Other terrains...}}
你懂得。上面的代码虽然管用但却丑陋,我想把移动消耗和湿度作为地形数据,但这里则是嵌入在代码中的。更糟糕的是,单一地形类型的数据被分散到一堆方法中,最好是把这些都封装在一起。
如果我们能有一个真实的地形类就太好了,比如:
class Terrain{public:Terrain(int movementCost,bool isWater,Texture texture): movementCost_(movementCost),isWater_(isWater),texture_(texture){}int getMovementCost() const { return movementCost_; }bool isWater() const { return isWater_; }const Texture& getTexture() const { return texture_; }private:int movementCost_;bool isWater_;Texture texture_;};
您会注意到这里的所有方法都是const。这不是巧合。由于在多个上下文中使用同一个对象,所以如果要修改它,更改将同时出现在多个位置。 你可能意非如此。为了节省内存而共享对象应该是一种不影响应用程序可见行为的优化。正因如此,Flyweight对象几乎总是不可变的。
但是我们不想在世界上的每块瓦片实例化上浪费资源。如果你研究下这个类,你会注意到这里面没有对瓦片位置的描述。在flyweight中,地形的所有状态都是“固有的”或“上下文无关的”。
考虑到这一点,没有理由每种地形类型都有多个。地上的每一块草的瓦片都是一样的。它将不再是一个由枚举或地形对象组成的网格,而是一个指向地形对象的指针网格:
class World{private:Terrain* tiles_[WIDTH][HEIGHT];// Other stuff...};
使用相同地形的每个瓦片将指向相同的地形实例。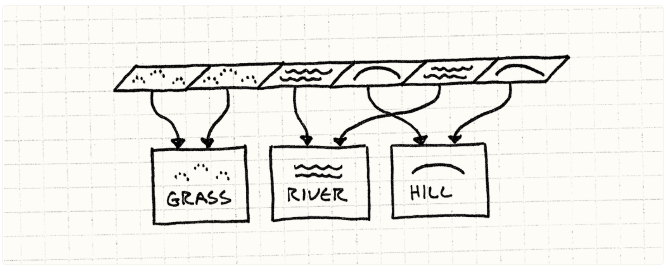
由于在多个地方使用了地形实例,如果是用动态分配,那么管理它们的生命周期会稍微复杂一些。所以我们直接就把他们保存到世界中去。
class World{public:World(): grassTerrain_(1, false, GRASS_TEXTURE),hillTerrain_(3, false, HILL_TEXTURE),riverTerrain_(2, true, RIVER_TEXTURE){}private:Terrain grassTerrain_;Terrain hillTerrain_;Terrain riverTerrain_;// Other stuff...};
然后我们可以用这些把地面绘制成这样:
void World::generateTerrain(){// Fill the ground with grass.for (int x = 0; x < WIDTH; x++){for (int y = 0; y < HEIGHT; y++){// Sprinkle some hills.if (random(10) == 0){tiles_[x][y] = &hillTerrain_;}else{tiles_[x][y] = &grassTerrain_;}}}// Lay a river.int x = random(WIDTH);for (int y = 0; y < HEIGHT; y++) {tiles_[x][y] = &riverTerrain_;}}
我得承认这算不上世界上最好的程序地形生成算法。
现在我们不再使用World上的方法来访问地形属性,我们可以直接暴露Terrain对象:
const Terrain& World::getTile(int x, int y) const{return *tiles_[x][y];}
这样,世界就不再与各种地形的细节相耦合。如果你想要瓦片的一些属性,你可以从那个对象得到它:
int cost = world.getTile(2, 3).getMovementCost();
我们又可以在实际对象上愉快地使用API了,而且我们几乎没有开销就做到了这一点——指针通常不会比枚举值大。
性能考量
我说“几乎”没有开销是指那些对性能斤斤计较的人想要知到和枚举相比它到底表现如何。通过指针引用地形意味着间接查找。要获得一些地形数据,如移动消耗,首先要按照网格中的指针找到地形对象,然后在那里找到该值。跟踪这样的指针可能会导致缓存丢失,从而减慢速度。
有关指针追逐和缓存丢失的更多信息,请参见Data Locality一章。
一如既往,优化的黄金法则是先给出概要分析。现代计算机硬件过于复杂,性能已不再是纯粹理性的游戏。在我对这一章的测试中,相比enum,使用flyweight并没有什么损失。flyweight实际上明显更快。但这完全取决于其他东西在内存中的布局排列。
我所确信的是,使用flyweight对象不应该立即放弃。它们提供了面向对象风格的优点,而不需要花费大量资源创建和维护对象。如果你发现自己创建了一个枚举并对其进行了大量切换,那么可以考虑使用这个模式。
如果您担心性能,至少在将代码更改为可维护性较差的样式之前先进行概要分析。
另请参见
- 在tile的例子中,我们只是急切地为每个地形类型创建一个实例,并将其存储在World中。这使得查找和重用共享实例变得很容易。但在很多情况下,你不会预先创建所有的flyweight。
- 如果你不知道哪些是你真正需要的,最好是按需创建它们。为了利用好共享数据,当您请求一个对象时,首先要查看是否已经创建了一个相同的对象。如果是,则返回该实例。
- 这通常意味着您必须将构造封装在某些接口之后,以便首先查找现有对象。隐藏这样的构造函数是工厂模式的一个例子。
- 为了返回之前创建的flyweight,您必须跟踪已经实例化的线程池。顾名思义,这意味着对象池(object pool)可能是存储它们的好地方。
- 当使用State模式时,通常会有“State”对象,这些对象没有任何向机器指明其正在被使用的字段。状态的标识和方法就足够有用了。在这种情况下,您可以应用此模式并在多个状态机中同时重用相同的状态实例,而不会出现任何问题。

若有收获,就点个赞吧
0 人点赞
