目的
动机
人们眼中的计算机可谓顺序执行的性能怪兽。计算机的这种力量来自于其能够将大型任务拆解成诸多微小个体并依次执行。而通常来说,用户希望看到的是,多任务立即发生或者多任务同时进行。
虽说线程化和多核架构使得这种说法不再完全准确了,但即使是在多核状态下,只有少数操作才可以并发进行。
一个典型的例子就是,每个游戏引擎都要解决的渲染操作。当游戏展现玩家眼中的世界时,引擎将一次渲染一块场景—远处的高山峻岭,花鸟鱼虫,都要依次渲染。如果玩家看到的世界是逐渐绘制出来的,那么这个本应连贯世界图景表现就碎片化了。游戏场景必须做到丝滑更新,立刻就能展现一系列完整绘制出的帧。
双缓冲(Double Buffer)解决了这一问题,但要理解它是如何做到的,我们首先需要回顾一下计算机绘制图像的原理。
计算机图形的绘制简述
像电脑显示器这样的视频显示设备一次只绘制一个像素。它会从左到右扫过每一行像素然后移至下一行。当扫描到右下角时,再重新从左上角进行新一轮的扫描。绘制像素和扫描是很快的—每秒钟可以进行60次—人眼根本不会察觉到扫描过程。对于我们来说这就是一整个静态的彩色像素,也就是一幅图像。
这种解释简化了很多内容。如果你是搞底层硬件的,现在可能对此嗤之以鼻了,你可以随时跳过这一章节,你已经理解了余下的内容。但如果不是这种情况,我的任务也只是给足你理解我们将要讨论的设计模式的上下文知识。
你可以把这个过程看作是一个小管道将像素输出到屏幕上,每个像素由管道后端进入,接着一次一个像素地播撒到整个屏幕。那么,这个管道是如何知道何种颜色输出到何处呢?
在大多属计算机中,方案是从一个帧缓存(framebuffer)中拿出像素。帧缓存是内存中的像素数组,每一组内存中的字节数据代表着某个像素的颜色。当管道朝着屏幕泼洒像素时,它会从这个数组中以字节为单位读取颜色。
具体的字节到颜色的映射是由像素格式和系统颜色深度所定义的。在目前主流的游戏主机上,每个像素是32位色:红蓝绿通道各占八位,剩下的八位留作其他用途。
最终,想要把游戏放在屏幕上,我们只需要把颜色写至该数组。我们所有高精尖的图形算法归根到底就是这样:在帧缓存中摆弄字节的值。但是,还有一个小问题。
我先前说计算机是顺序的。如果机器正在执行渲染操作,那我们就不能指望它还能同时做其他事情了。这大体准确,但实际上确实有那么一两项任务会在程序运行时进行。其中一个就是在游戏运行时持续不断的从帧缓存中读取像素。这可能会为我们带来问题。
假设我们要在屏幕上显示一张笑脸的图像。程序开始迭代帧缓存中的颜色像素,我们没有意识到的是,在图像驱动从帧缓存中读取像素时,我们同时也在写像素。随着写操作的进行,笑脸图像开始显现,但霎时间读操作越过了写操作,读取到了我们还没有写入的位置。这就造成了图像撕裂(tearing),这是一个会导致图像显示不全的恶性Bug。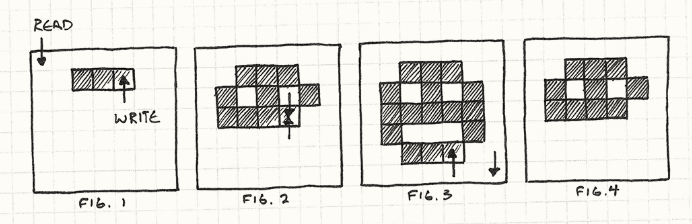
Fig.1 开始读写帧缓存 Fig.2 图像驱动的读操作速度越过写操作 Fig.3 完成正常写操作的绘制,Fig.4 图像驱动的读操作由于领先一个身位,并未读取并显示我们写入的内容。 结果就是在Fig.4中我们会看到半张图像。“撕裂”说的就是图像下半部分被强行损毁移去的现象。
因此我们需要这样一个设计模式。程序一次渲染一个像素,但我们需要让驱动一次性地将它们全部显示出来—上一帧笑脸图像还不存在,但下一帧就刷新出来了。双缓冲模式解决了这一问题,接下我会通过类比来解释。
第一场,第一幕
假如你在看舞台剧,想象一下这样的情形:场景一刚刚结束而场景二就要开始,工作人员需要更换舞台布景。如果我们在场景结束后允许场务上台设置布景,就会破坏戏营造的连贯景象。我们可以进行调光使空间昏暗下来(现实中剧院里就是这么做的),但观众们并不傻,他们知道有事发生。而我们则想要在场景进行无缝切换。
于是我们想出了这样一种聪明的方式,只需借助一块地皮:我们要搭建两个舞台,观众们可以同时看到它们。没个舞台的灯效是独立的,我们将其命名为“舞台A”和“舞台B”。舞台A上演场景一,与此同时,舞台B灯光暗淡,幕后正悄悄设置着场景二的布景。当场景一结束的时候,我们断开舞台A的灯光同时打亮舞台B,观众们立即看向新舞台,场景二马上开演。
而在这时,昏暗灯光下的舞台A上遍布了场务人员,他们要拿下场景一,重新布置场景三。只待场景二结束,我们立刻切换会舞台A。整场剧下来我们都在重复这些套路,用一个黯淡的舞台充当下一场景的布置工作间。每一次转场,我们只需要开关两个舞台的灯光就行了。至于观众,他们则得到了连续场景的无延迟观赏体验。没有场务会进入观众的视野。
使用单面镜或者其他巧妙的设计,你其实真的可以搭建一个地点容纳两个面向观众的舞台布景。在灯光切换的瞬间,观众们的注意力已经投向的新舞台而不必改变视线朝向。读者们可以试着做一下,权当练习了。
回到图像
上面的例子就是双缓冲的工作原理,这一过程存在于你所见的每个游戏的渲染系统之中。你拥有的不是单一的帧缓冲,而是一对。其中一个缓冲代表的是当前帧,也就是案例中的“舞台A”。视频硬件读取的正是这一缓冲。GPU可以随心所欲地读取这一部分。
然而并非所有的游戏和主机都使用这一方案。老式和简易主机对内存的限制更为谨慎,它们会在视频刷新时进行绘制同步。做到这一点可不简单。
同时,控制渲染的代码则把内容写入到另一个帧缓存上,也就是案例中的“舞台B”。当我们的渲染代码完成场景绘制时,会进行缓冲交换(swap)。这将告知视频硬件开始从第二个帧缓存中读取内容。只要掌握好每次刷新结束的切换时机,我们的画面不会有任何的撕裂,因为这一场景是作为整体出现的。
在这时,旧的帧缓存的状态变为可用。我们开始向其中渲染下一帧。大功告成!
双缓冲模式
缓冲类(Buffered Class)中封装了一个缓冲(Buffer): 一个可供修改的状态区域。对这一缓冲的编辑是递增的(译者按还记得逐行渲染的帧吗),但我们希望外部代码的将其视为单个的原子操作。要做到这一点,这个缓冲类要持有两个缓冲实例:next buffer和current buffer。
当从缓冲中读信息时,总是选择current buffer。当写入到缓冲时,总是使用next buffer。当变更完成时,会进行交换操作,立即交换current buffer 和next buffer,使得新buffer公共可见。相对应的,旧的current buffer成为了新的next buffer。
使用时机
很多模式的应用场景十分典型,你自会知道什么时候会使用到它们,双缓冲就是其中的一员。如果你的系统缺少双缓冲,那么该系统在视觉上就不对劲(画面撕裂等)或者行为上出现异常。但这也只是泛泛而谈,具体来说,这项模式契合以下场景:
- 有一些状态是以递增的模式来被编辑的。
- 这些状态有可能在被编辑的同时被访问。
- 我们不希望编辑的过程对访问这些状态的代码可见。
- 我们希望能够在状态被写入时也能被无延迟地读取。
谨记在心
与其他结构型模式迥异,双缓冲存在于更底层的实现中。也正因为此,它对其余代码的影响更少—大部分游戏感知不到个中区别。但是仍有几点需要预先说明。
交换本身也要消耗时间
双缓冲要求状态被编辑完毕时立刻进行交换操作。这项操作必须是原子的—在交换过程中不能有其他代码进行插足修改状态。通常这一操作的速度和赋值一个指针一样快,但是,如果这还是要比修改一开始的状态来的要慢的话,这项模式就完全起不到作用。
必须持有两个缓冲
双缓冲的另一个影响是内存使用的提升。双缓冲正如其名,这一模式总是要求你持有同一内存状态的两份拷贝。在内存受限的设备上,这样做的代价可能极为高昂。而如果你承担不起两份缓冲,你就必须要另寻他法来保证状态不会在修改时被访问。
译者注 这种情况和多线程对共享资源的争用是有区别的,因为从根本上,我们不是想要确保同时只有一项任务在修改状态,而是确保在修改的过程中仍能正常显示状态应有的内容,因此加锁的逻辑甚至比双缓冲的代价更为高昂,因为读锁和写锁本身就是冲突的,而潜在的阻塞对于渲染画面这样频繁的任务也是不可忍受。
示例代码
理论结合实践方可成功。接下来我们会写一个简易的图像系统,它的功能包括在一个帧缓存中绘制像素点。在大部分的PC和主机上,视频驱动已经提供了图形图像的底层部分,但通过手工实现这一模式能够产出更好的理解。首先是buffer本身的实现:(译者注注释是我加的)
class FrameBuffer{public:FrameBuffer(){ clear(); }// Set to default color is a lazy way to avoid deallocationvoid clear(){for(int i = 0; i < WIDTH * HEIGHT; i++){pixels_[i] = WHITE;}}// In this corrodination, the (0,0) is the left-top pixelvoid draw(int x, int y){pixels_[(WIDTH * y) + x] = BLACK;}const char* getPixels(){return pixels_;}private:static const int WIDTH = 160;static const int HEIGHT = 120;// Using a one-dimesion array is simpler than manipulating a 2-d array// but when it comes to calculation, 2-d array is the efficient one.char pixels_[WIDTH * HEIGHT];};
此类包括了清空整个缓冲的方法(设置为默认颜色)以及设置单个像素的颜色。它同时包括 getPixels() 方法来暴露内存中持有像素数据的数组。我们不会在例子中看到这一方法,但视频驱动会时常调用此方法来把内存中的缓冲传递到屏幕上。
我们将这个类封装到 Scene 类里面,这个类通过不断调用buffer上的 draw() 方法完成渲染工作:
class Scene{public:void draw(){buffer_clear();buffer_.draw(1,1);buffer_.draw(4, 1);buffer_.draw(1, 3);buffer_.draw(2, 4);buffer_.draw(3, 4);buffer_.draw(4, 3);}FrameBuffer& getBuffer() { return buffer_; }private:FrameBuffer buffer_;};
这就你画出的杰作:
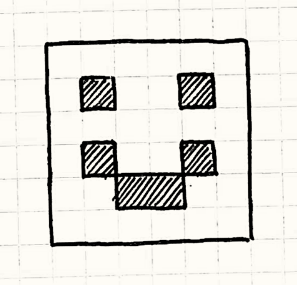
游戏在每一帧都会调用场景类的绘制方法。每一次调用都会使得场景类清空缓冲重绘像素。同时场景类还提供了 getBuffer() 方法用来访问内部的缓冲,这样视频驱动就可以调用它了。
这些都是很直白的事情,但是如果代码到这里就结束了,就会引发一系列的问题。因为视频驱动有可能在绘制像素的任何一处调用上使用 getPixels() 方法:
buffer_.draw(1, 1);buffer_.draw(4, 1);// <- 视频驱动在此处读取了像素!buffer_.draw(1, 3);buffer_.draw(2, 4);buffer_.draw(3, 4);buffer_.draw(4, 3);
这一情况的结果就是,用户只能看到我们绘制的眼睛,但是有一帧是看不到嘴的。而在下一帧里,则有可能在其他的任意一处产生中断。最终结果就是十分可怖的混乱画面。我们可以使用双缓冲解决这一问题:
class Scene{public:Scene(): current_(&buffers_[0]), next_(&buffer_[1]){}void draw(){next_->clear();next_->draw(1,1);// ... draw callsnext_->draw(4,3);swap();}FrameBuffer& getBuffer(){ return *current_; }private:void swap(){// 仅仅交换指针。Framebuffer* temp = current_;current_ = next_;next_ = temp;}Framebuffer buffers_[2];Framebuffer* current_;Framebuffer* next_;}
现在场景类包括两个缓冲,存储在 buffer_ 数组里。我们并不会直接使用数组引用,而是使用 next_ 和 current_ 指向数组,当执行绘制时,在 next_ 缓冲上调用 draw() ,当视频驱动需要获取像素时,它只会使用到 current_ 来访问对应的缓冲。
这种方式让处于绘制状态的缓冲永远对视频驱动不可见。仅剩的问题就是在场景绘制时调用的 swap() 方法。这个方法简单地交换了 next_ 和 current_ 引用。视频驱动下一次调用 getBuffer() 方法时就会获得新的缓冲,也就是我们刚刚完成了绘制工作的那一个。这一次不会有画面问题。(译者按前提是swap 方法的执行过程不能被其他行为打断,也就是前面说的这个问题)
不仅只为图像而生
双缓冲解决的核心问题是访问正在被修改的状态。这样做的目的有两个,我们在上面的例子中已经介绍过了其中一个—直接从另一线程中的代码里访问状态或中断任务。
然而还有另一缘由:当 编辑这一状态 的代码正在访问正被编辑的同一状态时。这在很多场景下都有体现,尤其是物理和AI方面,实体之间进行着交互行为。双缓冲在这时也很有帮助。
人工智障
假设我们要为某个搞笑游戏中的所有事物构建一套行为系统。这个游戏有一个舞台,舞台上有一群到处乱跑的演员,他们不停地胡闹,做恶作剧等等。下面就是我们的基本演员类:
class Actor{public:Actor() : slapped_(false) {}virtual ~Actor() {}virtual void update() = 0;void reset() { slapped_ = false; }void slap() { slapped_ = true; }bool wasSlapped() { return slapped_; }private:bool slapped_;};
每一帧游戏都会调用演员的 update() 方法使其能够处理一些事情。在用户看来,所有演员都应该立刻进行刷新。
这里是关于Update Method模式的例子。
演员之间可以进行交互,也就是说,他们能够相互打击碰撞。演员在刷新时会调用其他演员的 slap() 方法完成打击,而其自身则掉用 wasSlapped() 来判断自身是否被打击。
演员需要舞台供他们交互,现在来构建这个类:
class Stage{public:void add(Actor* actor, int index){actors_[index] = actor;}void update(){for (int i = 0; i < NUM_ACTORS; i++){actors_[i]->update();actors_[i]->reset();}}private:static const int NUM_ACTORS = 3;Actor* actors_[NUM_ACTORS];};
Stage 类可以添加演员,并能在一个 update 方法里刷新所有演员。对于用户来说,这些演员的行动是同时发生的,但是在内部这些演员其实是逐个更新的。
需要注意的另一点就是,每个演员的“slapped”状态在其更新后就会被清空。这样一个演员对于一个打击(slap)行为只会做出唯一一次响应。
接着来定义实体类来作为演员的子类。“喜剧演员”类看起来很简单。它会面对(faces)着一个演员,当它被任何人打击时都会对它面对的演员执行打击。(谁打我我就打另外一个人)
class Comedian : public Actor{public:void face(Actor* actor){facing_ = actor;}virtual void update(){if(wasSlapped()) facing_->slap();}private:Actor* facing_;};
现在我们要在舞台上增加一些喜剧演员然后静观其变。我们总共设置三个演员,每一个演员面对着他的下一个演员。最后一个演员面对着第一个,形成一个大环。
Stage stage;Comedian* harry = new Comedian();Comedian* baldy = new Comedian();Comedian* chump = new Comedian();harry->face(baldy);baldy->face(chump);chump->face(harry);stage.add(harry, 0);stage.add(baldy, 1);stage.add(chump, 2);
最后舞台设置上就如下图所示。箭头代表演员的朝向,数字代表演员在舞台内部数组中的索引。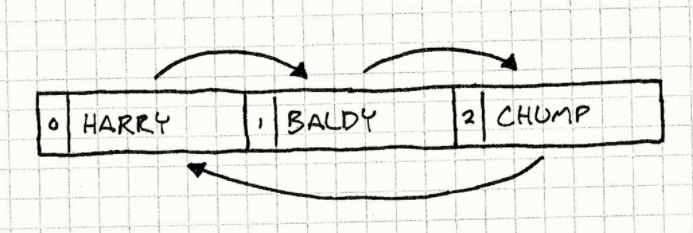
我们先让Harry被打击,然后来看看会发生什么事:
harry->slap();stage.update();
记住,舞台类中的 update() 方法是逐个更新演员的,如果我们调试这段代码,会发生下面的事情:
Stage updates actor 0 (Harry)Harry was slapped, so he slaps BaldyStage updates actor 1 (Baldy)Baldy was slapped, so he slaps ChumpStage updates actor 2 (Chump)Chump was slapped, so he slaps HarryStage update ends
在同一帧内,我们在Harry身上执行的初始动作传播给了所有的喜剧演员。现在再来混合一下这些行为,假设我们给这三个演员调整了位置,但是面部朝向不变: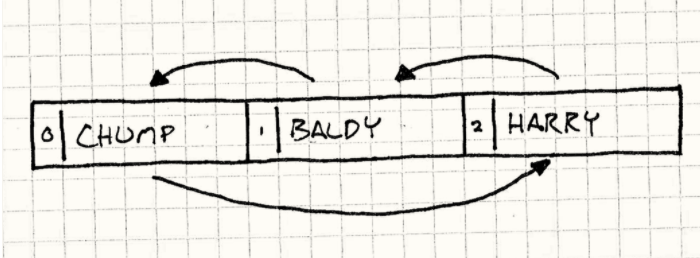
然后重新设置这个舞台,但这次我们要执行下面的代码:
stage.add(harry, 2);stage.add(baldy, 1);stage.add(chump, 0);
再次运行上面的实验,结果会像这样:
Stage updates actor 0 (Chump)Chump was not slapped, so he does nothingStage updates actor 1 (Baldy)Baldy was not slapped, so he does nothingStage updates actor 2 (Harry)Harry was slapped, so he slaps BaldyStage update ends
这次完全不一样,而问题出在哪显而易见,当我们更新演员时,我们修改的是他们的“slapped”状态,这一状态恰恰是我们要在更新(译者注这里最终是指的 Comedian 类中的虚方法 update )过程中读取的内容。也正因为此,在更新过程中先更改的状态会给后面的更新带来影响。
如果你继续更新舞台,你会看到每一帧里打击效果级联传递给演员的景象。在第一帧,Harry打了Badly,在下一帧,Badly打了Chump,接下来都是这样。
最终结果就是,演员要么在被打的同一帧响应,要么在下一帧响应,这完全基于他们在舞台上被安排的位置。这违背了我们想要演员并行响应的意愿———他们在舞台上的位置不应该影响他们在一帧里的状态更新。
缓冲掌掴
好在双缓冲模式可以救场。这一次,我们不再持有两份“buffer”对象的拷贝,而是以更具细粒度的形式进行缓冲:每一个演员的“slapped”状态。
class Actor{public:Actor():currentSlapped_(false){}virtual ~Actor(){}virtual void update() = 0;void swap(){// Swap the buffer.currentSlapped_ = nextSlapped_;// Clear the new "next" buffer.nextSlapped_ = false;}void slap() { nextSlapped_ = true;}bool wasSlapped() {return currentSlapped_;}private:bool currentSlapped_;bool nextSlapped_;};
每个演员现在都有两个”slapped”状态。就像先前的图像更新的例子一样,当前状态用作读,下一状态用在写。
reset() 方法被更改为 swap() 方法。在清空被交换的状态前,它会将下一状态拷贝至当前状态,成为新的当前状态。 Stage 类也需要做出小小改动。
void Stage::update(){for(int i = 0; i < nUM_ACTORS; i++){actors_[i]->update();}for(int i = 0; i < NUM_ACTORS; i++){actors_[i]->swap();}}
update() 方法现在会先更新所有演员的状态然后在对每一个演员执行状态交换。最终结果就是,只有在被实际击打之后,演员才能在一帧中表现为被击打的样子。这样无论演员在舞台的位置情况如何都能做到同步更新行为。在用户和外部代码看来,所有演员都是在同一帧里同时更新的。
译者按 我觉得对于上面这个例子,相当于所有人都在等待首次的传播结束再进行更新,由于你已经保证了方法的原子性,所以实际情况其实是在Harry被打的第一帧没有人会响应,而在第二帧所有人才会同时进行响应。如果你每次都恰好使得第一帧的响应同步让所有人没有显示动作,虽然演员确实是同步更新了,却会始终产生一帧的延迟。当然,这比不使用双缓冲的结果还是好很多的。
设计决策
双缓冲非常简单易懂,我们使用的例子已经覆盖了大部分情况。对于实现此模式来说,有两处主要决定需要我们考虑。
如何交换缓冲?
交换(swap)操作是双缓冲模式中至关重要的一环,我们必须在这一操作发生时为两个buffer的读写操作统统加锁。而且这一过程必须要尽可能地快才能不影响最佳性能。
- 交换buffer的指针或者引用:
我们在绘制图像的例子中使用的就是这种方法,这也是解决图像双缓冲的最常用方式。
- 快速。无论缓冲本身有多大,交换操作只是对几个指针进行赋值。就速度和简洁性而言,这种做法几乎无懈可击。
- 外部代码无法存储缓冲的持久化指针。这是最主要的限制。因为我们并不会真正地移动数据,我们只是周期性地告诉其余的代码新的缓冲区域在哪里,在上面那个舞台的例子中就是如此。这就使得其余代码无法存储指向缓冲内部数据的指针——它们很可能在一段时间后指向了其他地方。有些系统的视频驱动需要固定的帧缓冲内存地址,这就很成问题,而我们也不能使用这一选项做为解决方案。
- 缓冲中既存的数据是两帧之前的数据而不是最新的。后继的帧会在替代后的缓冲的上进行绘制,其中不存在数据交换。就像下面这样:
在第三帧时数据存在于第一帧曾使用的缓冲A,而不是第二帧读取的缓冲。大多数情况下这不成问题——我们通常会在交换之后,绘制之前清空整个缓冲的内容。但是,如果我们想重用某些缓冲中的既存数据,就必须要考虑到这一点,数据可能并不像我们所期望的那样,它们可能是来自于先前的一帧。Frame 1 drawn on buffer AFrame 2 drawn on buffer BFrame 3 drawn on buffer A...
使用旧缓冲的经典案例就是模拟动态模糊。当前帧与已经渲染的上一帧的一部分进行融合,致使画面更贴近于真实的相机摄制。
- 在buffer之间复制数据:
如果我们无法让用户重新指向其他缓冲,剩下的唯一选择就是直接去进行上下帧缓冲间的数据复制。我们互相击打的喜剧演员的例子中就是这样做的。在那个例子中,由于状态只是一个布尔类型的标记,这种方法不会比重新赋值指针慢太多。
- 下一缓冲所存的数据仅过时了一帧。在这点上复制数据比指针赋值更好。我们访问上一缓冲会获得更新一些的数据。
- 交换操作耗费更多时间。这自然是一大缺点。现在交换就意味着内存中整块缓冲数据的拷贝。如果缓冲本身比较大,比如一整个帧缓冲,交换操作会显著地消耗时间。而又因为交换操作要锁住整个缓冲的读写,这会是个较大的限制。
缓冲细粒度
另一个问题是缓冲区本身是如何组织的——是单一的整体数据块还是在对象集合中分布? 我们在绘制图形的例子中使用了前者,而在喜剧演员的例子中使用了后者。
大多数情况下,被缓冲的内容本身就会为你提供答案,但其中确有一定的灵活性。 例如,我们的所有演员都可以将他们的消息存储在一个消息块中,并通过索引将其全部引用到该消息块中。另请参阅
- 在每一种图形图像API中你都会看到双缓冲模式的身影。比如,在OpenGL中的
swapBuffers()方法,Direct3D的swap chains,还有微软XNA框架中交换帧缓冲的endDraw()方法。

若有收获,就点个赞吧
0 人点赞
