我是从《设计模式》一书种得知这个模式的。当下可谓是无人不谈此模式,可说到底他们未必是在讲设计模式。我们会讨论到这一情况,不过我也会让你见识“prototype”和其背后概念显示出的其他更加有趣的地方,但首先,让我们温故而知新。
“故”字不是随口一说的。《设计模式》引用到的Ivan Sutherland1963年传奇的Sketchpad项目是这一模式范例的首次亮相。当所有人还在听Bob Dylan和Beatles的歌的时候,Sutherland却已经忙于研发CAD,交互图形和面向对象编程的基本概念了。 瞧瞧这个让人亮瞎🐕👁的demo吧。
原型设计模式
假设我们正在开发一款Gauntlet风的游戏。怪兽和恶鬼在角色四周攒动,觊觎体味玩家的血肉之躯。这些不怎么光彩的食客是通过“产生者(spwaners,下同)”来到竞技场的,每种怪都有不同的产生者。
译者注Gauntlet是一款中世纪魔法背景的地下城RPG,有点像暗黑3和火炬之光,但没那么无聊。
就本例来说,我们的游戏中有几种不同的怪物—幽灵(Ghost)、恶魔(Demon)、术士(Sorcerer)等。比如:
class Monster{// Stuff...};class Ghost:public Monster{};class Demon : public Monster {};class Sorcerer : public Monster {};
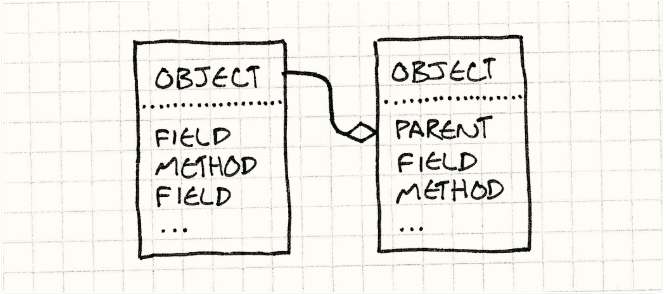
产生者会构建具体的怪物实例。我们可以暴力地给每个怪物安排一个产生者,导致平行的继承关系: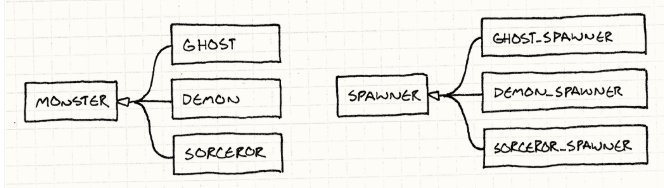
我参考了尘封的UML书才画出来这个图。这个箭头表示“继承自”。
实现可以是这个样子:
class Spawner{public:virtual ~Spawner() {}virtual Monster* spawnMonster() = 0;};class GhostSpawner : public Spawner{public:virtual Monster* spawnMonster(){return new Ghost();}};class DemonSpawner : public Spawner{public:virtual Monster* spawnMonster(){return new Demon();}};// You get the idea...
除非你写的代码是按行数发工资,否则这么个写法明显不怎么样。一堆的类和范例,充斥着冗余和复制,自我重复……
原型设计模式提供了解决方案。关键思想是 一个对象能够生成其他和自己相似的对象 。要是你有一个Ghost(对象),你就能产生更多的Ghost;有一个Demon,就等催生其他的Demon。任何能以原型对待的怪物能被用来产生其他版本的自身。
要实现这个,我们给基类Monster添加一个抽象的clone()方法:
class Monster{public:virtual ~Monster() {}virtual Monster* clone() = 0;// Other stuff...};
每个怪物的子类都要去实现这个方法然后返回一个新的该类型的怪物对象:
class Ghost : public Monster {public:Ghost(int health, int speed): health_(health),speed_(speed){}virtual Monster* clone(){return new Ghost(health_, speed_);}private:int health_;int speed_;};
而当所有的怪物都支持这一点后,它们的产生者就不需要了,我们只要定义一个就可以:
class Spawner{public:Spawner(Monster* prototype): prototype_(prototype){}Monster* spawnMonster(){return prototype_->clone();}private:Monster* prototype_;};
它永远持有一个monster,这个隐藏的对象唯一作用就是被当作生成其他类型怪物的模板,就有点像从不离开自己巢穴的蜂后一样。
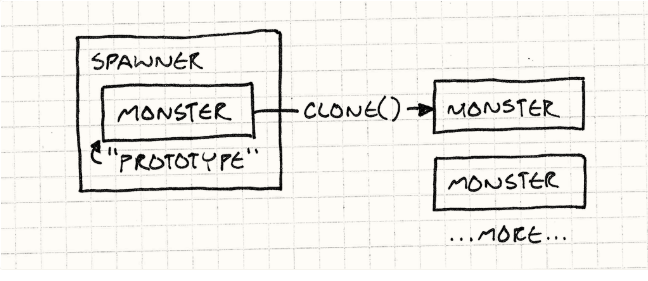
要创建一个ghost的产生者,我们要创建一个ghost的原型然后创建一个持有该原型的产生者。
Monster* ghostPrototype = new Ghost(15, 3);Spawner* ghostSpawner = new Spawner(ghostPrototype);
这个模式有一个做的很棒的地方,它不仅克隆原型的类,还会克隆原型的状态。这意味着我们可以通过创建合适的ghost原型来产生快速的ghost、弱鸡ghost或者慢速ghost。
我还觉得这个模式优雅而惊人。我想破脑袋也想不出这么好的设计模式,但是一旦我知道有了这个模式,就再也忘不掉了。
效果如何?
我们不用给每个怪物分别写产生者了,这还不错。然而我们又必须实现每个怪物类中的clone()方法。相比写产生者省不了多少功夫。
而且当你要写clone()方法时还有一些语义上的坑等着你去踩。应该深拷贝还是浅拷贝?换句话说,如果一个恶魔拿了一只草叉,我们也需要把草叉给克隆过来吗?
另外,在这个人为的问题上不能少写一些代码不说,它本身就是一个人为的问题。我们不得不将每个怪物分为不同的类,这在时下可绝对不是大部分游戏引擎工作的方式。我们大多数人都很难理解这样的大类层次结构是很难管理的,这就是为什么我们使用Component和Type Object这样的模式来对不同类型的实体建模,而不是将它们包含在自己的类中。
生成函数
即使真的让每个怪物都有不同的类,也有其他的方式来解构(原文为 decorticate this Felis catus)。我们使用spawn函数而不是类,如:
Monster * spawnGhost(){return new Ghost();}
这样比把整个类用作构建某种怪物的做法要不那么死板。然后在一个产生者的类里简单地存储一个函数指针即可:
typedef Monster* (*SpawnCallback)();class Spawner{public:Spawner(SpawnCallback spawn): spawn_(spawn){}Monster* spawnMonster(){return spawn_();}private:SpawnCallback spawn_;};
要创建一个Ghost的生产者,你可以这样做:
Spawner* ghostSpawner = new Spawner(spawnGhost);
模板
时至今日的大多数C++开发者们对模板是很熟悉的。我们的产生者类需要构建某类的实例,但同时我们又不想给具体的怪物类硬编码。自然的解决方案就落到了类型参数的头上,也就是模板:
class Spawner{public:virtual ~Spawner() {}virtual Monster* spawnMonster() = 0;};template <class T>class SpawnerFor : public Spawner{public:virtual Monster* spawnMonster() { return new T(); }};
我不确定C++程序员对模板是爱是恨。不管如何,时下我看到的C++程序员都在使用模板。
使用起来是这样的:
Spawner* ghostSpawner = new SpawnerFor<Ghost>();
Spawner这个类的意义在于代码不需要关心究竟是产生什么怪物而只是以Monster类的指针的形式使用。 如果我只有SpawnerFor
类的话,就没有任何共享的超类实例化了,也就是任何能和任何怪物spawners工作的代码都需要接受一个模板参数。 译者注即在实例化之前上述代码中的T需要传递给有需要的地方,而这明显是个负担。
一等公民
上面两种解决方式都是强调了要拥有一个类,Spawner,作为类型参数。在C++中,类型通常不是一等类(first-class),所以需要一些技巧。如果你在使用像Javascript,python或者ruby这样的动态类型语言,它们的类就是你可以传递的正常对象,你可以用更直截了当的方法解决问题。
某种意义上,TypeObject模式是对一等类缺失问题的另一种变通之法。这个模式即使是在已经拥有它的语言当中依旧很有用处,以为它允许你定义什么是一个“type”。你可能需要一些和语言提供的内置类型不同的词法语义。
当你写了一个spawner后,只需传入应该被构建的怪物即可——实际代表怪物类的运行时对象。轻而易举。
即使有了这么些个选择,我还是要如实地说我并没有找到原型模式才是最佳解决方案的例子。这点倒是因人而异,但目前还是把这些撇在一边,来讲点别的吧:作为编程语言范例的原型
原型语言的典范
可能有人会觉得“面向对象编程”和“类”是同义词。OOP的定义更像是异教信仰的圭臬,但公平且无可争议的理解应该是OOP允许你定义把数据和代码绑定在一起的对象。相比于像C这样的结构化语言和像Scheme这样函数式语言,OOP的定义特点在于它把状态和行为牢牢绑定在一起。
你可能觉得类才是唯一能够这样做的方式,但其实零星的有几个人却有异议,包括Dave Ungar和Randll Smith。他们在80年代创造了名为Self的语言。OOP能做的,它也能做,而且它没有类的概念。
Self
纯粹凭感觉来说,比起基于类的语言,Self更加面向对象。我们把OOP看作让状态和行为联姻,但有类的编程语言实际上对待它们是泾渭分明的。
以你最喜欢的基于类的编程语言为例。要获取某个对象的状态,你会在内存中找到这个实例本身。状态容纳在该实例中。
要调用一个方法你则需要找到实例的类然后再来找其中的方法。行为容纳再类之中。总是可以通过某个层级的非直接途径去办法获取一个方法,也就是说字段和方法是不同的。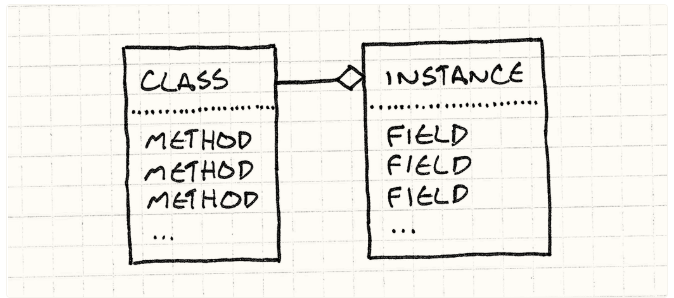
例如,要调用C++中的虚方法,你要再实例中找到其虚函数表中的指针,然后在那里查找方法。
Self根除了这种差异。找任何东西都可以在对象中去找。一个实例既可以包含状态也可以包括行为。你可以持有一个其中的包含个一个独一无二的方法的单个对象。(注不论内存是怎样规划的,至少不用去类所在的/所指向的那部分内存去找了,其实我觉得只是省了点时间。)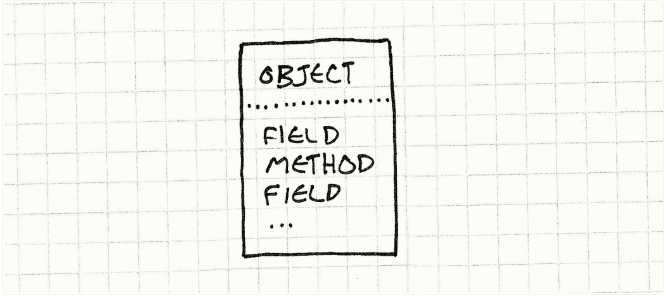
没有人是一座孤岛,但这个对象可以。
要是以上就是Self的全部工作,那使用它也未免太难了点。基于类的语言中的继承,虽然这个特性有缺陷,但也确实给予了程序员重用多种形态代码避免复制的有用机制。为了达成类似于class的机制,Self有委托(delegation)。
要想找到某个对象的字段或者调用它的方法,我们首先需要查找对象本身,如果该对象持有我们要找的东西,那直接就完事儿了。如若不然,我们再去对象的父类上去找。这里只是表示另外的对象。当我们在第一个对象中没能找到某个属性时,我们就找它的父类,再找它父类的父类,如是皆然。换句话说,查找失败其实就是委托给了一个对象的父类对象。
我这里是在简化内容。Self实际上支持多父类,父类只需特别指出字段,这意味着你能在运行时做到像继承父类或改变他们这样的事情,也就引出了所谓的动态继承。
父类对象使得我们能越过多个对象重用行为(和状态),因此我们这样了已经涵盖了类的实用部分。类所做的另一个关键点是提供了创建实例的方式。当你需要新建点什么东西的时候,你只需 new Thingumabob() 或是你倾向于使用的任何一种语言的语法。一个类就是自身实例的一个工厂。
没有类我们又该如何新建实例呢?具体一点,我们该怎么创建一大堆有着共同特点的新东西呢?正如原型模式所言,在Self里你是通过克隆来完成的。
在Self中,好似所有对象都自动支持原型模式。任何对象都能被克隆。要像创建一堆近似的对象,你可以:
- 给你想要的对象塑形。你可以只克隆系统内置的Obejct基类然后把字段和方法塞到里面。
- 想克隆几个就…呃…克隆几个
这种方式给予我们实现原型模式的优雅之处而不必拖泥带水地自己实现clone()方法。系统都内置好了。
我刚一了解这样一个美丽动人,冰雪聪明,最小化的系统就开始去创造一个基于原型模式的编程语言去了以加强其使用经验。
我发觉学习(一门编程语言)最好的方式就是从零开始一笔一画地构建一门语言,我能说啥呢?我这人有点怪。你要是好奇这门语言是什么的话,我告诉你他叫Finch。
后来怎么了?
刚开始捣鼓纯原型模式的编程语言时我超级激动的, 然而当我调试好去运行的时候, 我发现了一个令人不快的事实: 用它写代码比较累.
小道消息称很多Self程序员也是这么想的. 这个项目倒是远谈不上失败, 只是Self动态性过强, 要想让它跑得快需要虚拟机技术上的革新. 运行时编译, 垃圾回收和优化分配算法的好点子也是一样的技术—都是同一个人实现的—这使得现在世界上的动态类型语言的运行速度能够满足流行的大型应用的需求.
好吧, 编程语言做起来容易用起来难, 因为它把难事儿踢给了用户. 我在使用它的时候发现其丢失了class能给的结构性. 我在运行库的阶段就放弃尝试了, 因为这个语言压根就没有库.
也有可能我的头脑已经被基于类的面向对象给调教的服服帖帖了, 但我觉得大家都想要定义好了的东西.
在基于类的编程语言大获成功之余, 瞧瞧现在有多少游戏拥有具体而微的角色类, 满满一单子的怪物类, 物品类, 技能类等等, 无一不被清晰地标记上了. 游戏里的怪物们不是独一无二的雪花(注没有两片雪花的形状是完全一样的), 也往往不是缝合在一起的怪物形象.
原型虽好, 我也希望人们多了解了解, 但我同时也很高兴大家其实不用每天自己造原型模式的轮子. 我见过一些完全的原型模式, 这些软趴趴的代码透着古怪气, 实在让人一头雾水.
它还告诉我们,实际上用原型风格编写的代码是多么少。 我看过这些代码.
那么JavaScript又如何?
好吧,如果基于原型的语言如此不友好,我该如何解释JavaScript呢?这是一种每天有数以百万计的人使用的原型语言。运行JavaScript的计算机比地球上任何其他语言都多.
JavaScript的创建者Brendan Eich直接从Self那里获得了灵感,而且JavaScript的许多语义都是基于原型的。
每个对象都可以有一组任意的属性,包括字段和“方法”(它们实际上只是存储为字段的函数)。
一个对象也可以有另一个对象,称为它的“prototype”,如果字段访问失败,它会委托给这个对象。
作为一名语言设计师,原型的一个吸引人的地方是它们比类更容易实现。Eich充分利用了这一点:JavaScript的第一个版本只用了10天就完成了。
但是,尽管如此,我相信JavaScript在实践中与基于类的语言比原型语言有更多的共同点。暗示JavaScript已经远离Self的一个迹象是,基于原型的语言中的核心操作—克隆—不复存在。
JavaScript中没有克隆对象的方法。与之最接近的是 object.create() ,它允许创建一个委托给现有对象的新对象。而且直到JavaScript问世14年后,ECMAScript 5才添加了这一功能。
与其进行克隆,不如让我介绍一下用JavaScript定义类型和创建对象的典型方法。你从一个构造函数开始:
function Weapon(range, damage) {this.range = range;this.damage = damage;}
这将创建一个新对象并初始化其字段。你可以这样调用它:
var sword = new Weapon(10, 16);
这里的new调用了Weapon()函数的主体,并将其绑定到一个新的空对象。主体向它添加了一组字段,然后自动返回现在已填入的对象。
new还做了另一件事。当它创建那个空白对象时,它将其连接起来以委托给一个原型对象。你可以直接使用 Weapon.prototype 获取目标对象。
虽然状态是被添加到构造函数体中去了,但要定义行为,通常需要向原型对象添加方法:
Weapon.prototype.attack = function(target){if(distanceTo(target) > this.range){console.log("Out of range");}else{ target.health -= this.damage; }}
这将向武器原型添加一个attack属性,该属性的值是一个函数。
因为 new Weapon() 返回的每个对象都委托给了 Weapon.prototype现在,你可以调用 sword.attack() ,它将调用该函数。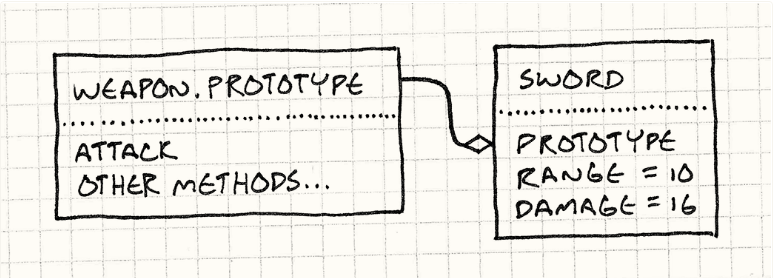
复习一下:
- 使用new来创建新对象,会调用其构造函数
- 状态存储在实例本身上
- 行为通过一定程度上间接——委托给原型——存储在一个单独的对象中,该对象表示所有特定类型的对象共享的一组方法。
说起来你可别不信, 这看起来就像是之前我们对class的描述. 你可以在Javascript中写出不带克隆的prototype风格的代码, 但是这种语言的语法和习惯用法鼓励基于类的方法。
我个人认为这是一件好事。我说过,在原型上加倍投入会使代码更难处理,所以我喜欢JavaScript将核心语义包装在一些更优雅的东西中。
数据建模中的原型
好吧,我一直在谈论我不喜欢的原型,这使得这一章非常令人沮丧。我认为这本书更多的是喜剧而不是悲剧,所以让我们谈谈有用的原型,或者更具体地说,委托。
如果你将游戏中所有的代码字节数与数据字节数进行比较,你会发现自编程诞生以来,数据的比例一直在稳步增加。早期的游戏程序化地生成了几乎所有内容,所以它们能够适合于软盘和旧游戏卡。在今天的许多游戏中,代码只是驱动游戏的“引擎”,它完全是在数据中定义的。
这很好,但是将成堆的内容放入数据文件并不能神奇地解决大型项目的组织挑战。如果说有什么不同的话,那就是它让事情变得更困难了。我们使用编程语言的原因是因为它们有管理复杂工作的手段。
我们不再将代码块复制粘贴到10个位置,而是将其移动到一个可以按名称调用的函数中。我们可以将一个方法放在一个单独的类中,而不是复制到一堆类中,这些类从这些类中继承或混合。
当你的游戏数据达到一定的大小时,你便会想要拥有类似的功能。数据建模是一门深奥的学科,我不能指望在这里做公正的解释,但我确实想提出一个特性供你在自己的游戏中考虑:使用原型和委托来重用数据。
假设我们正在为我前面提到的山寨版__Gauntlet定义数据模型。游戏设计者需要在某些文件中指定怪物和物品的属性
我是指完全原创的名头,没从先前任何方式和任何现有的竖版的多人地牢爬街机游戏获取灵感。求别给我律师函警告.
一种常见的方法是使用JSON。数据实体基本上是地图、属性包或其他十几个术语中的任何一个,因为程序员最喜欢为已有的东西发明一个新名称。
我们已经多次重新发明了它们,以至于Steve Yegge称它们为“通用设计模式”。
所以游戏中的哥布林可能是这样定义的:
{"name": "goblin grunt","minHealth": 20,"maxHealth": 30,"resists": ["cold", "poison"],"weaknesses": ["fire", "light"]}
这非常简单,即使是最不喜欢文本的设计师也能处理。所以你在地精的族谱上加上几个兄弟姐妹的分支:
{"name": "goblin wizard","minHealth": 20,"maxHealth": 30,"resists": ["cold", "poison"],"weaknesses": ["fire", "light"],"spells": ["fire ball", "lightning bolt"]}{"name": "goblin archer","minHealth": 20,"maxHealth": 30,"resists": ["cold", "poison"],"weaknesses": ["fire", "light"],"attacks": ["short bow"]}
现在,如果这就是代码的话那我们就得如坐针毡了。这些实体之间有很多重复,受过良好训练的程序员不喜欢这样。它浪费空间和更多的时间来写。它浪费空间和更多的时间来写。你必须仔细阅读才能判断数据是否相同。这是一个令人头疼的维护问题。如果我们决定让游戏中的所有哥布林更强大,我们需要记住更新他们三个的生命值。糟糕之极矣。
如果这是代码,我们将为“goblin”创建一个抽象,并跨三种goblin类型重用它。但是傻傻的 JSON对此一无所知。我们要让它更智能一点。
我们将声明,如果一个对象有一个“prototype”字段,那么它将定义这个对象所委托的另一个对象的名称。在第一个对象上不存在的任何属性都会回到原型上进行查找。
这使得“原型”成为元数据而不是数据。哥布林长着绿色的疣状皮肤和黄色的牙齿。他们没有原型。原型是代表妖精的数据对象的属性,而不是妖精本身。
有了这个,我们可以简化我们的哥布林部落的JSON:
{"name": "goblin grunt","minHealth": 20,"maxHealth": 30,"resists": ["cold", "poison"],"weaknesses": ["fire", "light"]}{"name": "goblin wizard","prototype": "goblin grunt","spells": ["fire ball", "lightning bolt"]}{"name": "goblin archer","prototype": "goblin grunt","attacks": ["short bow"]}
由于弓箭手和法师都以 goblin grunt 作为原型,我们不需要重复他们各自的生命值、抵抗和弱点。我们添加到数据模型的逻辑非常简单——基本的单个委托——但是我们已经摆脱了大量的重复。
有意思的是,我们没有为要委托给的三种具体的妖精类型设置第四个“base goblin”抽象原型。相反,我们只选择了其中一个最简单的妖精并委托给它。
这在一个基于原型的系统中是很自然的,任何对象都可以作为一个克隆来创建新的精细对象,我认为这在这里也是很自然的。对于那些在游戏世界中拥有一次性特殊实体的游戏来说,这是一个非常适合的数据。
想想Boss和独特物品。这些通常是游戏中更常见对象的改进,原型委托非常适合于定义这些对象。
斩颅魔剑(Lv.25),其实就是一把带点附加属性的长剑,可以这样直接表达:
{"name": "Sword of Head-Detaching","prototype": "longsword","damageBonus": "20"}
在你的游戏引擎的数据建模系统中添加一些额外的功能,可以让设计师更容易地为你的游戏世界添加许多小的变化,而这种丰富正是玩家所喜欢的。

若有收获,就点个赞吧
0 人点赞
