Ant Design Charts 起源于蚂蚁,作为中后台可视化解决方案,对内服务于数百加大型系统,今天,我们做一次较全的介绍,可以选择性精读,如果你目前还不是高级前端,相信读完后你一定会有收获。
本篇文章会先介绍下 Ant Design Charts(下文简称 Charts),然后从关键实现及代码结构方面展开,带你探索如何实现 React 版本的综合可视化解决方案。
简介
Ant Design Charts 是一个基于 React 的可视化组件库,无需可视化基础就可快速实现各种可视化场景。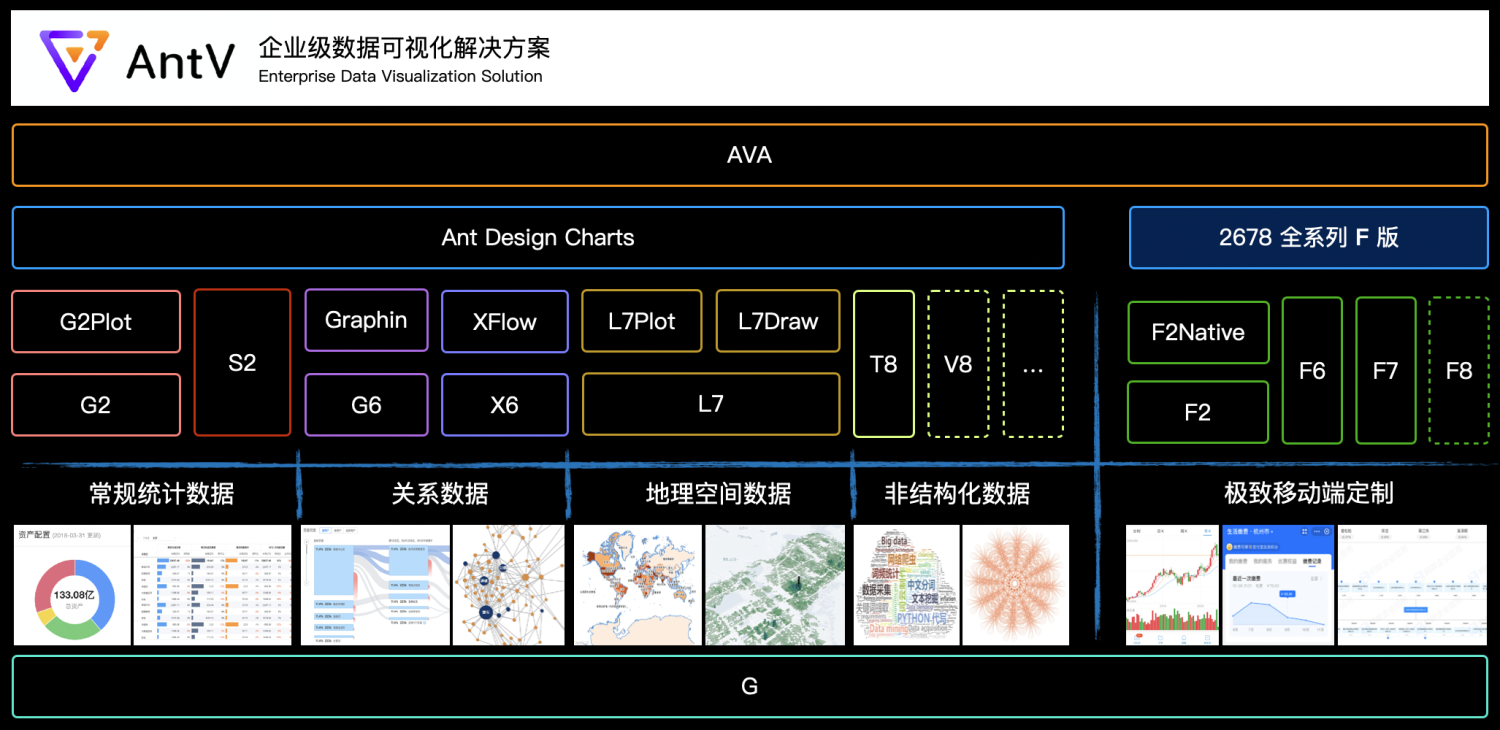
先介绍下 AntV。AntV 是蚂蚁企业级可视化解决方案,由可视化领域专家御术负责(业界朋友一般叫他林峰 |【开源访谈】ECharts 作者 林峰 访谈实录)。
Charts 作为 AntV 的上层 React 可视化组件库,目前已经集成了 G2、G6、X6、L7 等底层,涵盖常规统计图表、关系图、流程图以及地理可视化等可视化组件。
| 统计图表 | 地理可视化 |
|---|---|
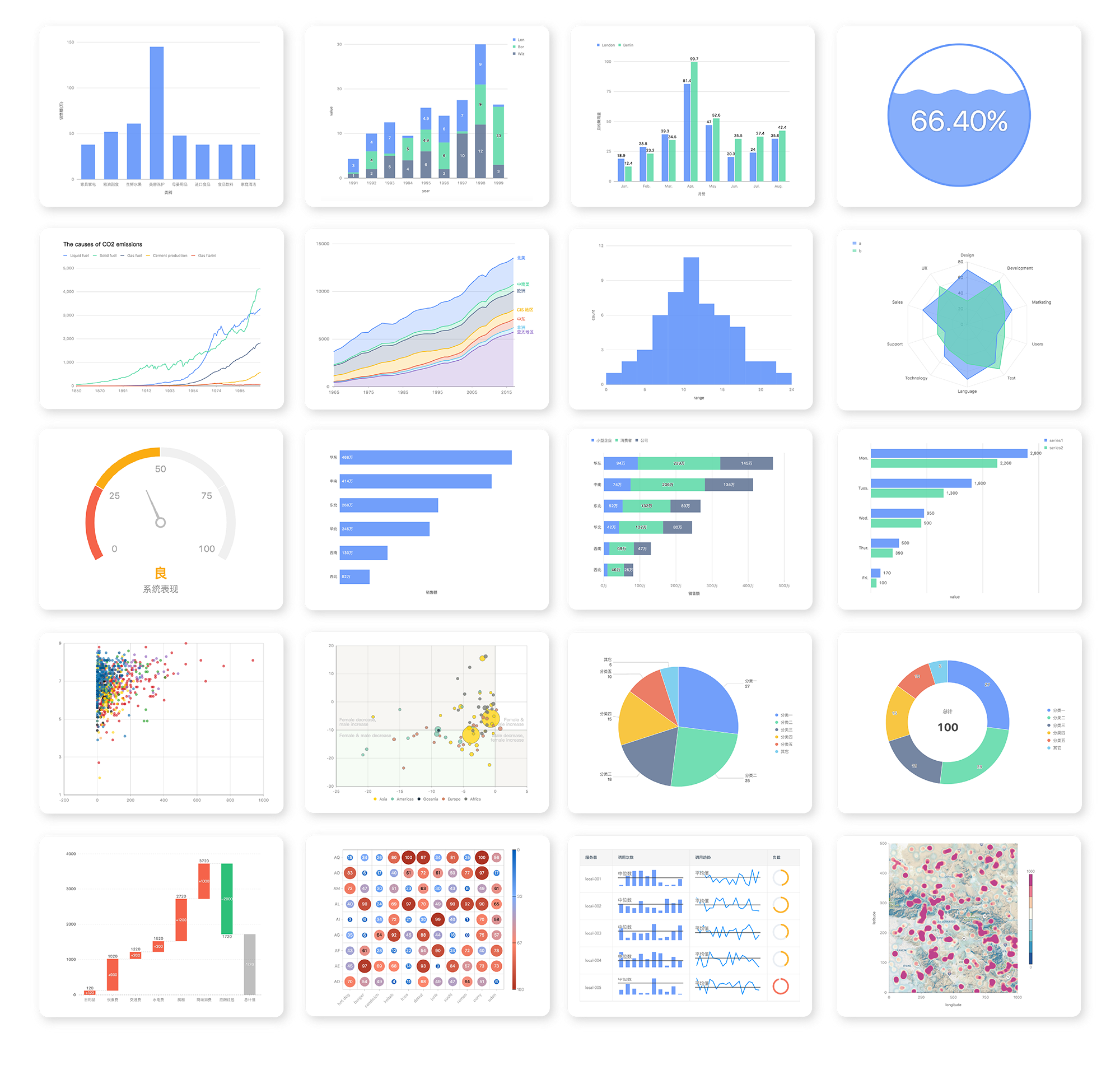 |
 |
| 关系图 | 流程图 |
 |
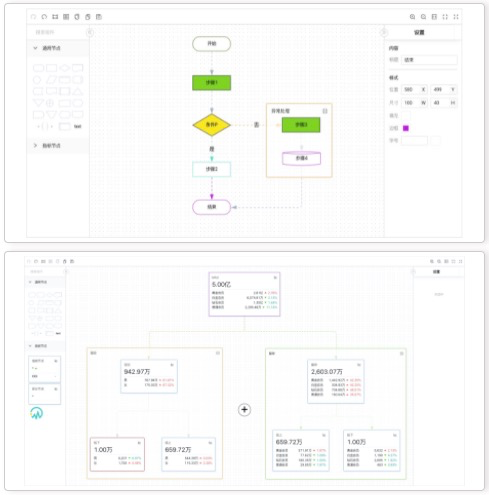 |
诞生背景与优势
Charts 作为蚂蚁中后台可视化组件库,从接入 G2Plot 开始就直接服务于蚂蚁各大系统、解决方案,同时为了让其更好、更全面地满足业务需求,我们在底层集成了诸多可视化库(从统计图表延展到关系图、流程图以及地理图表)。
那相对底层库来说,它的优势是什么呢?
减少概念
这里以 G6 的封装为例,为了减少业务同学的学习成本和使用门槛,Charts 内置一系列处理逻辑,你只需关注数据和配置,不需要去理解底层一系列概念,例如 changeData、update、render、refresh、paint 等。
| G6 | Ant Design Charts |
|---|---|
 |
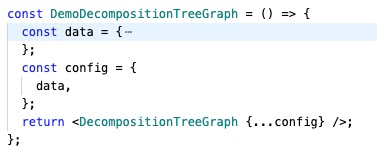 |
丰富业务 API
我们在 BI 业务领域下有着相对丰富的经验,同样作为业务同学,深知业务同学常有的述求。我们把常用的业务功能进行收敛沉淀,内置到 Charts 中 ,方便业务同学直接调用使用。例如:
1、图表下载:这应该比较常见,老板或 PD 经常会要求你将图表下载给他,如果用底层库,你可能花费半天时间也找不到,因为压根没有相关 API ,Ant Design Charts 封装了这类功能,只需 plot.downloadImage() 即可。
2、请求动画:真实业务中,绝大部分数据都是从接口请求获取,如果缺少相关动画,会比较生硬,Charts 只需配置 loading 即可。
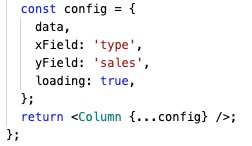 |
 |
|---|---|
3、React 特性:例如支持 React 语法的 tooltip 、statistic 等
| G2Plot | Ant Design Charts |
|---|---|
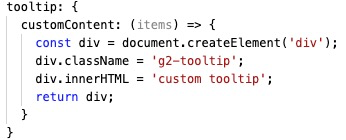 |
 |
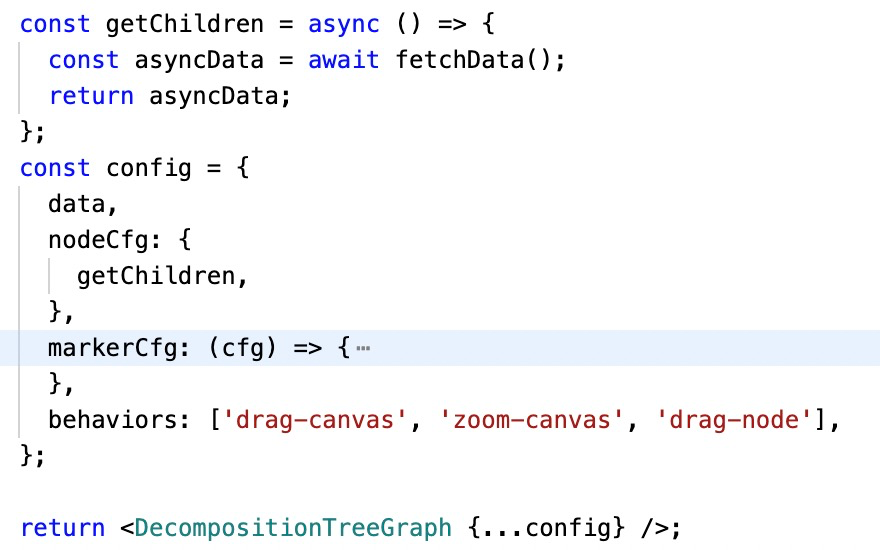
4、异步请求:对于层次结构的数据,后端往往一次只返回部分数据,当用户点击展开时再请求下一层级数据。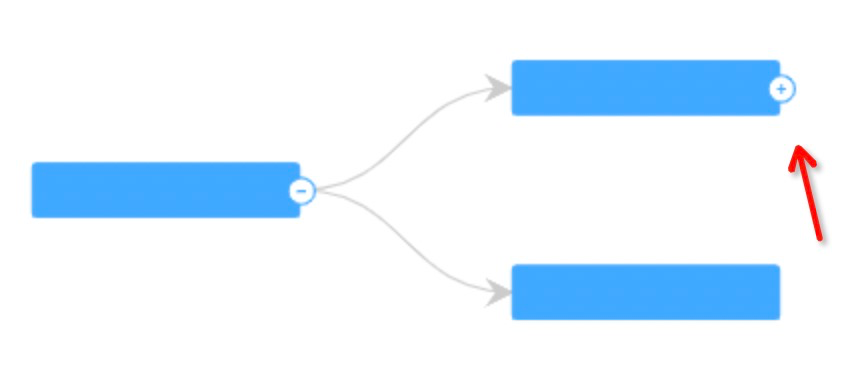
这种情况,如果不做支持,意味着用户需要对下一次请求的数据进行处理,和前面的数据拼接,转树结构之后再交给底层库 , 使用成本会直线上升。 Ant Design Charts 从业务角度出发,内置相关功能。
| 配置 | 模拟请求 |
|---|---|
 |
 |
5、默认层级:上面提到默认层级,通过接口依次获取层级数据,但有没有一种情况,后端就是要一次返回全量数据,而且 PD 要求你默认只展示 2 层数据呢?
别慌,这是好事,回复 PD 要 2 天开发时间,使用 Ant Design Charts 你只需一个配置,所有的交互态都已经给你内置了。
6、ErrorBoundary:边界错误,避免图表出错时白屏,提升使用体验。
7、等等…
一方面减少概念、另一方面丰富常用的业务 API,通过 React 封装,较大程度上方便了很多 react 用户,但它也并不是说“简单的 React 封装,没有什么挑战点”,毕竟人都是懒惰的,可以用工具实现的就一定不用人工的方式。试想一下,底层库更新频繁,上层如何快速更新迭代(同步最新 features)、文档如何保持同步、以及质量又如何保证。
关键实现
下面,我们来看下关键实现部分:
- 通过“代码同步”来解决功能、文档同步问题(便于快速更新迭代)
- 通过“API 合理调用”和“打标(索引)”来保障上层性能
- 借助 Github actions 实现自动化测试(单元测试 + e2e),保证质量问题
代码同步
为保护键盘,减少不必要的 CV 操作,我们选择将正确(重复)的事情交给机器,因为机器不仅高效,而且可靠,为此,我们推出了基于 AST(抽象语法树,abstract syntax tree 的缩写)的代码同步能力。
代码同步是指将底层库示例、组件、文档等必要信息通过一定的规则 React 化,如下是 Bar 示例在 G2Plot 和 Charts 下的展现形式,两者之间的转化不需要任何的 CV 操作,一个简单的命令即可完成,一起看看实现原理。
| G2Plot | Ant Design Charts |
|---|---|
 |
 |
AST 在国内的介绍资料相对欠缺,你可能并不感冒,但提及它的使用场景,你可能会大吃一惊。
- Babel 编译 ES6 语法
- 代码高亮
- 语法解析
- 代码压缩
- 关键字匹配
如果学过编译原理,你大概知道它是干嘛的了,一个简单了例子,假如你有一辆二八大扛自行车和一把螺丝刀,你可以通过螺丝刀对自行车进行拆解,然后通过机械原理巧妙的将各零件组装到一起,得到一辆新的自行车。这一整个过程 ,如果把自行车比作代码,那么 AST 就扮演着螺丝刀的角色。
整个过程可以拆解为以下三个步骤:
- 拆:对自行车进行拆解
- 改:将拆解后的零件进行合理改造
- 装:将改造后的零件进行组装
接下来我们把自行车换成一段真正的 G2Plot 代码片段,看一下整个过程
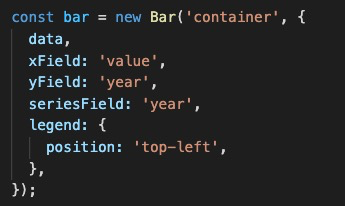
const bar = new Bar('container', {data,xField: 'value',yField: 'year',seriesField: 'year',legend: {position: 'top-left',},});
假如有如上原始 js 代码,我们想通过 AST 抽取 config 配置,该如何实现呢?
const config = {data,xField: 'value',yField: 'year',seriesField: 'year',legend: {position: 'top-left',},}
首先我们需要对拆解后的代码有一定的认知,我们可以在 https://astexplorer.net/ 上看到代码经过 AST 后的 Tree 以及 JSON 结构,如下就是将原始 js 进行拆解后的 Tree 结构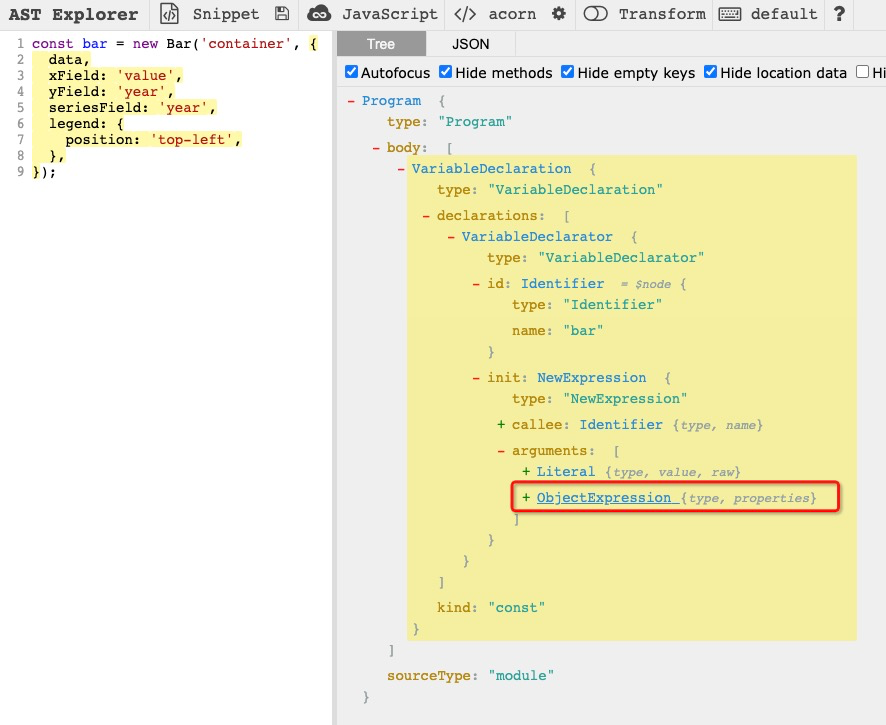
可以清晰的看出,要达到我们的目的,只需提取 NewExpression 的第二个参数,赋值给 Identifier,然后组装即可,修改的过程可以通过 babel 提供的插件机制来完成。但你可能有点蒙圈,JSON 里面的 VariableDeclarator、Identifier 这些代表啥?
在进一步看 AST 代码之前,我们先了解一下计算机语言,其一般都是由 Statement、expression 和 declaration 组成
- Statement:用来控制程序流程或者用来管理零个或多个语句,eg:
- BlockStatement: 大括号括起来的语句块
- IfStatement:if 语句
- ForStatement: for 语句
- expression: 表达式,用来计算或者返回一个结果的,比如所有的运算操,函数的调用等
- ArrowFunctionExpression: 箭头函数表达式
- ConditionalExpression: 条件表达式
- NewExpression: new 表达式
- declaration:变量声明,js中,不外乎 var、let 和 const 三种方式,还有二个特殊的, 函数声明和类声明,除此之外,es6还有 import 声明。
现在你知道了 VariableDeclarator 是一个变量声明,说明该语句声明了一个变量,详细信息可参考 Babel AST。
有了上面的基础,我们看看具体实现吧,拆、改、装这些过程会有很多工具(例如🔧),我们借助市场上比较流行的 babel 来做,也可以选择 sprima、estraverse、escodegen 这些插件。
step1: 拆,交由 babel 完成即可
step2: 改,通过babel 插件定义访问器,在访问器中修改,可以理解为对一棵树的遍历过程
step3: 装,交由 babel 完成
| 原始代码 | AST | 结果 |
|---|---|---|
 |
parse.js | 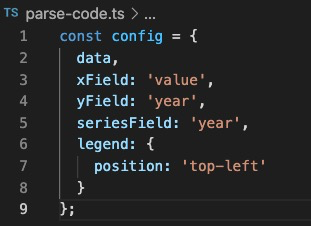 |
parse.js
const fs = require('fs');const path = require('path');const babel = require('@babel/core');const { get } = require('lodash');const fPath = path.join(__dirname, './code.ts');/*** new表达式* @param {*} node*/const isNewExpression = (node) => {return get(node, 'init.type') === 'NewExpression' || node.type === 'NewExpression';};const visitor = {// 抽取 configVariableDeclarator(path) {const { node } = path;if (isNewExpression(node)) {if (get(node, 'init.callee.type') === 'Identifier') {chartName = get(node, 'init.callee.name');node.id.name = 'config';node.init = node.init.arguments[1];path.replaceWith(node);}}},};const vistorPlugins = {visitor: visitor,};const parseFile = (filePath) => {const jsCode = fs.readFileSync(filePath, 'utf-8');const { code } = babel.transform(jsCode, {plugins: [vistorPlugins],});fs.writeFileSync(path.join(__dirname, './parse-code.ts'), code);};parseFile(fPath);
可以看出这个改的过程其实就是 visitor ,当遇到 new 表达式时(NewExpression)取出第二个参数,并赋值给 node.init,然后通过 replaceWith 修改即可。
这就是一个最简单的 AST,拆、组过程由 babel.transform 完成,我们通过 visitor 操控改过程,如果要处理更多类型,在 visitor 里面新增即可,例如处理箭头函数 ArrowFunctionExpression 。
const visitor = {VariableDeclarator(path) {// 参考上文},ArrowFunctionExpression(path){// TODO}};
Ant Design Charts 示例同步,文档更新,新增组件都是通过 AST 实现,相比上面的示例差别在于 visitor 相对复杂而已,感兴趣的可以在 scripts/ast 目录查看,建议大家自行完成一个箭头函数转 es5 的 AST 。
性能保障
除了前面提到的相对于底层库的一些基本优势点之外,组件性能也是我们考虑的一大因素,这里会分为两块,一是底层性能,二是上层性能,我们重点解决第二个点。
API合理调用
每个库都会提供一些 changeData、update、refresh 等方法,结果可能一样,但这些方法的复杂度肯定是不一样的,上层需要合理控制,做到最小开销。
| 原始数据 | 变更 |
|---|---|
 |
 |
例如有如上数据,当用户 data 发生变化,Omit(config, ‘data’) 无变化时,Column 组件需要能准确识别出变化项,调用底层的 changeData , 而不是 update 。
打标(索引)
前面提到默认层级,针对后端一次返回全量数据的这种骚操作,如何保证渲染性能呢?
同样别慌,Ant Design Charts 遵循最快原则,使用打标机制,确保每次操作都能第一时间能看到有效数据,而不被过多的 CPU 计算拖延。
假如用户有 5W 条数据,为了更好描述,假设这些数据是自平衡的二叉树 ,如果用户配置的 level 是 2,表示用户只想展开 2 个层级的数据,也就是 3 个节点, 这个时候如果对 5W 条数据进行布局,之后在隐藏其它数据,很明显,不可取。
Ant Design Charts 做法:
step1: 抽取前三条数据进行布局
step2: 全量数据交由 webWorker 进行打标
step3: 打标完成之后挂载到 Graph 实例上
step4: 每次点击 + - 时判断当前节点是否已经有子节点,有的话直接展开/收起,没有的时候通过 Tag 去全量 Data 里面获取。
数据打标
上文提到了从全量 Data 里面获取数据,这也是我们的重点,对于一般数据,如果我们想要从中查找某条数据(例如我要查找当前节点的一级子节点),时间复杂度为 O(n),看上去已经很好了,但如果我们每次点击都去消耗 O(n),会不会有点浪费资源?
是否有可能做到 O(log(n)) 甚至更低,当然,在非极端条件下是可以的,对于每层只有一个节点的数据,那就另提吧。
数据打标可以理解为给每条数据加上一个指针,我们可以通过该指针快速定位数据位置。实际上,我们会加入多个标签。
- level: 树层级(深度)
- parentId:父节点 ID
- path:节点所在路径 ```typescript const prefix = “g”; const setTag = (data, level = 0, parentId = “”, path: string = “p”) => { const { id, children = [] } = data; return {
[`${prefix}_level`]: level,[`${prefix}_parentId`]: parentId,[`${prefix}_currentPath`]: path,...data,children: children?.map((item, index: number) => {return setTag(item,level + 1,parentId ? `${parentId}-${id}` : id,`${path}-${index}`);})
}; };
setTag(data);
<a name="hCXwj"></a>##### 数据查找我们在点击节点的时候,可以从节点对象上获取被点击节点的路径信息 (g_currentPath) , 通过该路径可以从全量 Data 中快速定位到该节点,并返回该节点的 Children 作为要加入的节点。```typescriptconst getChildrenByPath = (graph: IGraph, currentPath: string) => {// 打标时已经做了编码,这直接取值即可const path = currentPath.split("-");path.shift(); // 根节点没有 pathlet current = graph.get('tagData');path.forEach((childrenIndex: string) => {current = current.children[Number(childrenIndex)];});if (!current?.children) {return [];}return current.children.map((item) => ({...item,children: []}));};
从查找算法可以看出,时间复杂度主要体现在 path.forEach , 而 path.length = node.level - 1,我们知道,在满二叉树中,深度为 K 的树有 2^k-1 个节点。
也就是说,如果用户的数据倾向于满二叉树,我们点击 + 时的复杂度就从 O(n) 降到了 O(log(n)) 。
如果用户每个节点的子节点数大于 2,我们再次点击 + 时复杂度会更低,降到O(loga(n))。
当然,极端情况是,用户的每个节点下面仅有一个节点,这个时候为O(n),但可以降低内存占用情况。
质量
质量是个老生常谈的话题,庞大的工程,如何保证质量和稳定性显的至关重要,Ant Design Charts 借助 GitHub Action 实现自动化测试。
GitHub Actions makes it easy to automate all your software workflows, now with world-class CI/CD. Build, test, and deploy your code right from GitHub. Make code reviews, branch management, and issue triaging work the way you want.
抓住几个关键词 automate/CI/CD,一句话描述“自动化”,可以理解为一台可操控远程机器。
单测
单元测试的简称,单元测试是所有测试中最底层的一类测试,是第一个环节,也是最重要的一个环节,有效防止了开发的后期因 bug 过多而失控,性价比是最高的,推荐使用 jest 。目前 Ant Design Charts 底层库覆盖率(一般指代码执行量与代码总量间的比例,也有一些其它统计规则)都在 90% 以上。
看一个简单的测试示例:
import React, { useRef, createRef } from 'react';import { create } from 'react-test-renderer';import { renderHook } from '@testing-library/react-hooks';import ReactDOM from 'react-dom';import { act } from 'react-dom/test-utils';import Area from '../../src/plots/area';import ChartLoading from '../../src/util/createLoading';const refs = renderHook(() => useRef());describe('Area render', () => {let container;const data = [{date: '2010-01',scales: 1998,},{date: '2010-02',scales: 1850,},];beforeEach(() => {container = document.createElement('div');document.body.appendChild(container);});afterEach(() => {document.body.removeChild(container);container = null;});it('classname * loading * style', () => {const props = {style: {height: '80%',},className: 'container',loading: true,};const testRenderer = create(<Area {...props} />);const testInstance = testRenderer.root;const renderTree = testRenderer.toTree();expect(renderTree.rendered[0].nodeType).toBe('component');expect(renderTree.rendered[1].props.className).toBe('container');expect(renderTree.rendered[1].props.style).toEqual({height: '80%',});expect(testInstance.findAllByType(ChartLoading).length).toBe(1);});});
上面测试案例测试的是 Area 组件,里面有个测试 case ‘classname loading style’,目的是确保 props 配置生效且正确,如此多的测试用例,正确的执行时间是什么时候呢?这个取决于项目,一般如下:
- 提交 PR 时
- 修改 PR 代码时
这就会用到我们上面提到的 GitHub Action,该 Action 的作用就是当用户在 GitHub 上提交 PR 的时候,自动执行 yarn test,效果和本地运行一样,但解放了🙌。
name: Teston: [push, pull_request]jobs:test:runs-on: macos-lateststrategy:matrix:node-version: [14.x]steps:- uses: actions/checkout@v2- name: Use Node.js ${{ matrix.node-version }}uses: actions/setup-node@v2with:node-version: ${{ matrix.node-version }}- run: yarn- run: yarn test- name: Coverallsuses: coverallsapp/github-action@masterwith:github-token: ${{ secrets.GITHUB_TOKEN }}
抽几个点说明一下,详情参看 GitHub Actions 官网
- on:触发时机
- runs-on:运行系统
- uses:具体使用的 Action ,可以到 GitHub Marketplace 上查找,前端常用的并不多
- run: 运行命令
- with: 相关 Action 参数
e2e
通常情况下,单元测试确实能够帮助我们发现大部分的问题,但对于可视化组件,由于内容都绘制在canvas 上,我们虽然保证了正常渲染,但渲染结果是否如预期呢?这是单测触及不到的。于是我们寻求一份能保证准确性的 e2e 测试方案,但遗憾的是市场上并没有合适的 Action。
因此我们利用 GitHub Action 的能力,开发了 Surge UIInsight 服务,通过简单的配置,就可以实现 PR 前后的截图 DIFF 对比,来进行集成测试,进一步提升 PR 和版本的质量。
流程
描述了整个 Surge UIInsight 的过程,从发起 PR 触发 GitHub Action,到整个 GitHub Action 执行完成,返回测试结果。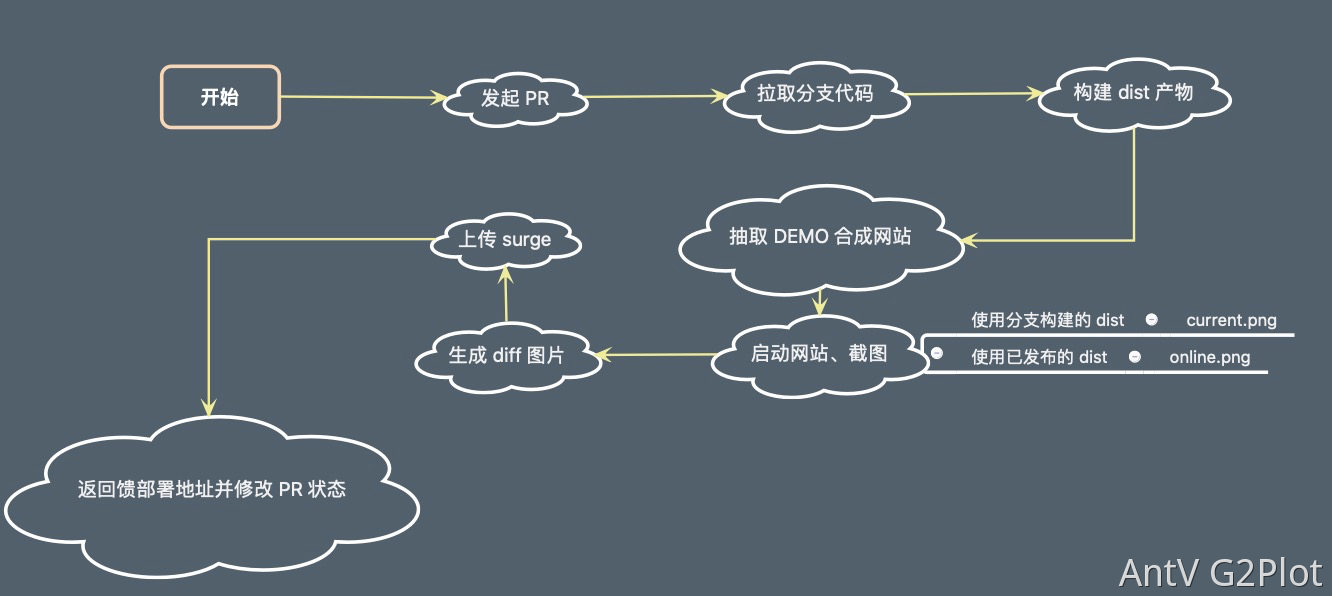
PR 状态
Surge UIInsight 执行完成后,会在 PR 控制台返回产物地址。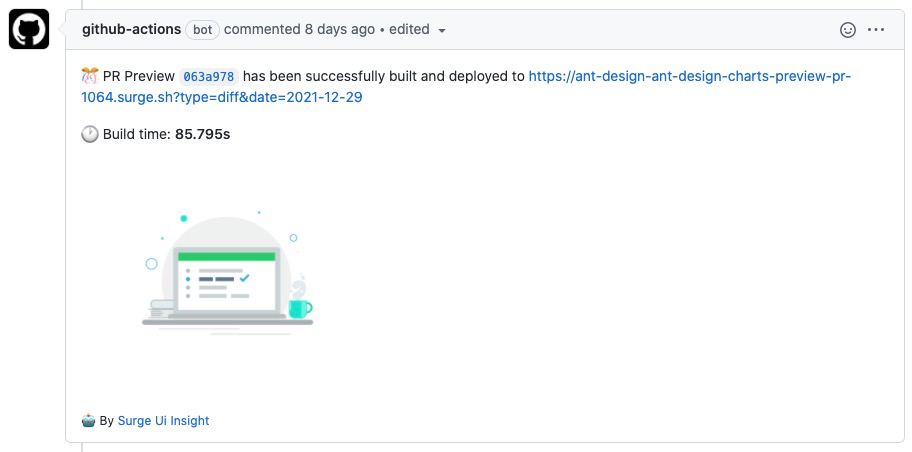
产物
产物分为三个模块,左侧是当前分支代码效果,右侧是线上代码效果,中间是 diff 结果,会自动计算出差异度。
有了 Surge UIInsight 和单测的保证,代码的每次迭代变得极具保障性,如果偶尔发现 bug ,一般是发布同学没等相关 Action 执行完成就匆匆利用管理员权限对代码进行了合并。
代码结构
代码结构决定了一个包的可扩展性和维护成本,底层如此多的包,我们应该如何合理管理各模块呢?
Ant Deisgn Charts 使用了和知名开源项目 React、Babel 一样的 Monorepo 模式进行包管理,并通过 Lerna 优化工作流程进。
Monorepo
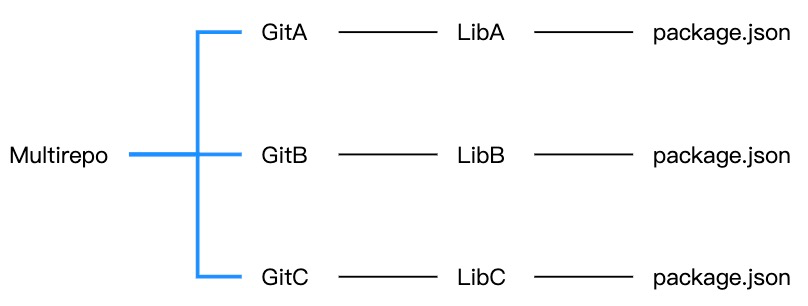
Monorepo 的意思是在版本控制系统的单个代码库里包含了许多项目的代码;不同于 Multirepo,一个项目一个仓库。
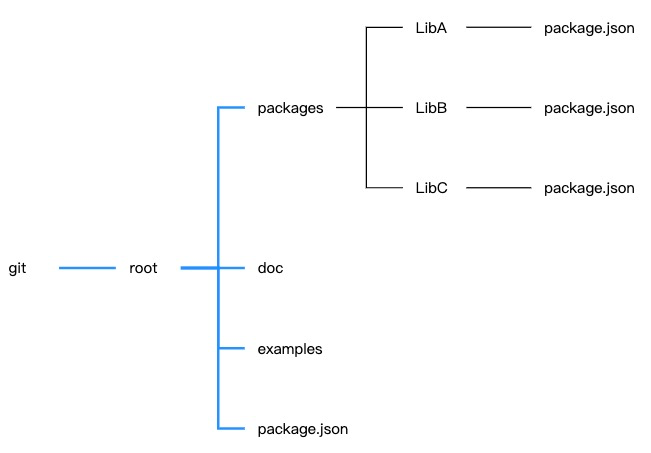
| Multirepo | Monorepo |
|---|---|
 |
 |
Monorepo 策略优势
从上图我们可以发现如下一些优势(from 前辈):
- 依赖清晰:由于所有的项目代码都集中于一个代码仓库,我们将很容易抽离出各个项目通用组件或工具,并通过 Lerna 或其他工具进行代码内引用。同理,由于项目之间的引用路径内化在同一个仓库之中,我们很容易追踪当某个项目的代码修改后,被影响到的项目。
- 改动可控:想想究竟是什么在阻止你进行代码重构,很多时候,原因来自于「不确定性」,你不确定对某个项目的修改是否对于其他项目而言是「致命的」,出于对未知的恐惧,你会倾向于不重构代码,这将导致整个项目代码的腐烂度会以惊人的速度增长。而在 monorepo 策略的指导下,你能够明确知道你的代码的影响范围,并且能够对被影响的项目可以进行统一的测试,这会鼓励你不断优化代码。
Monorepo 策略劣势
有优必有劣,关键在于取舍了,可能会带来如下一些问题:
- 新同学上手成本高:不同于一个模块一个仓库,新人只需要了解该模块逻辑即可,Monorepo 模式下需要了解个模块之间的相互逻辑,前期投入成本相对较高
- 臃肿:模块过多时会显得项目臃肿,在非浅 clone 模式下拉取代码会比较耗时
Monorepo 和 Lerna 什么关系?
Lerna is a tool that optimizes the workflow around managing multi-package repositories with git and npm.
Lerna 是 Monorepo 策略的一种解决方案,从官方描述可以可以知道,Lerna 是一个用来优化托管在 git、npm 上的多 package 代码库的工作流的一个管理工具,可以让你在主项目下管理多个子项目,从而解决了多个包互相依赖,发布时手动维护多个包的问题。
Lerna
Lerna 使用上比较简单,只需 lerna init 就可以生成 packages 目录和 lerna.json 文件,一般目录结构如下。
- packages- project1 // 项目名- src- index.ts- package.json- project2- src- index.ts- package.json- lerna.json- package.json- tsconfig.json
Ant Design Charts 也是遵循这种目录结构
- packages- charts- src- index.ts- package.json- flowchart- src- index.ts- package.json- graphs- src- index.ts- package.json- maps- src- index.ts- package.json- plots- src- index.ts- package.json- lerna.json- package.json- tsconfig.json
packages 内部依赖关系比较简单,charts 直接依赖其它几个子包,子包之间相互独立,这也意味着你可以在项目中直接使用子包,而不需要导入整个 @ant-design/charts。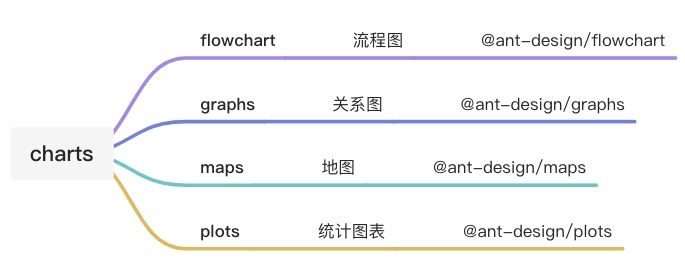
辅助工具
如果你 clone Ant Deisgn Charts 的话,你会发现,除了上面介绍的一些目录结构外,还有一些其它目录,这些是干嘛用的呢?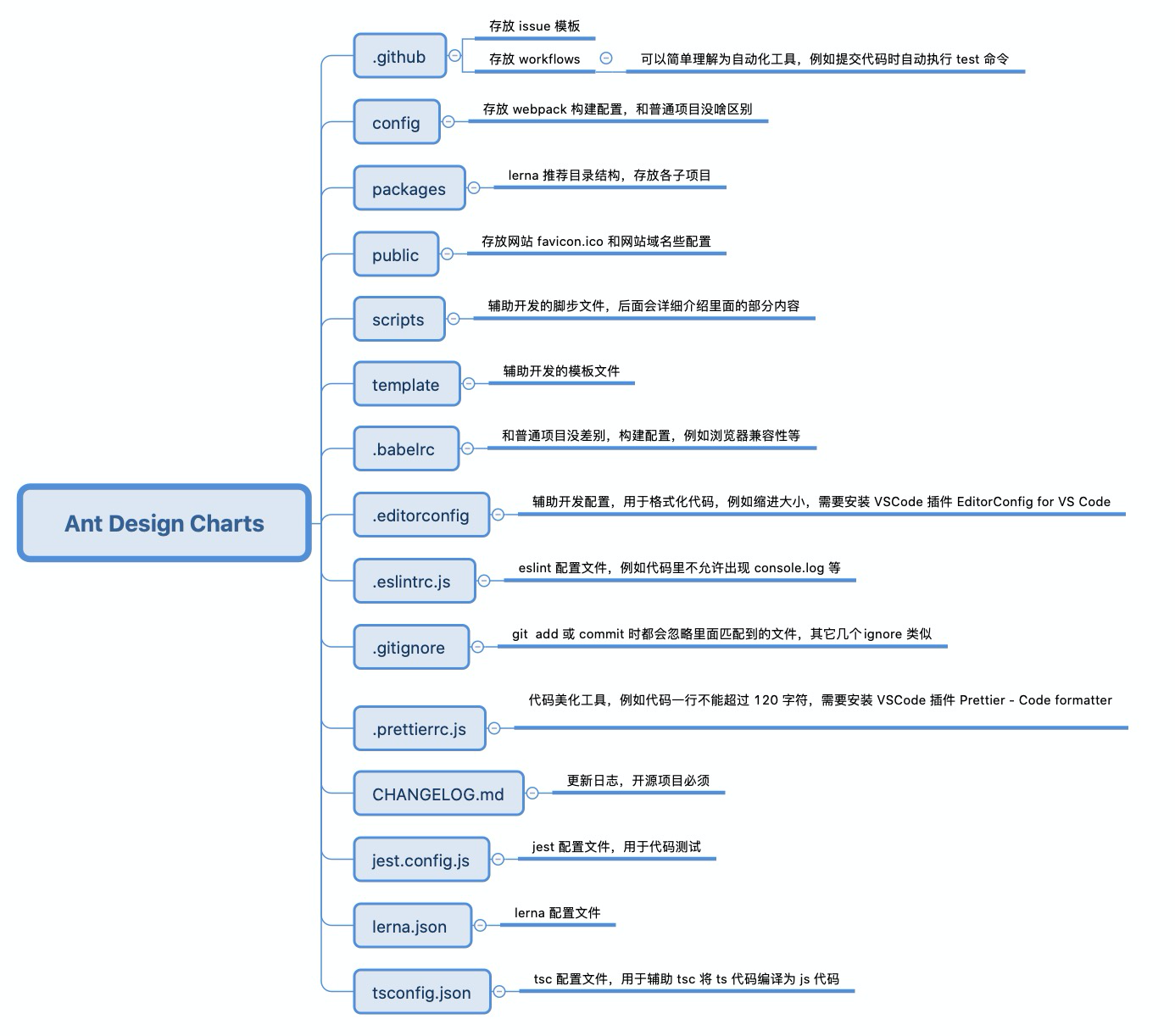
抽2个讲讲:
1、.prettierrc:代码格式化用的,可以看一个比较简单的配置
module.exports = {printWidth: 120,};
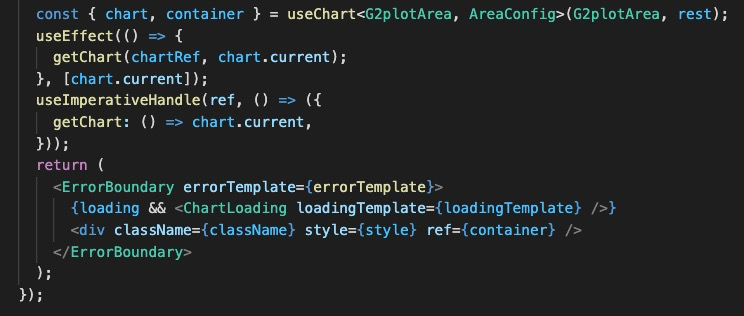
这意味着我们代码一行不能超过 120 个,如果调整为 80 会有什么差异呢?
| 120 | 80 |
|---|---|
 |
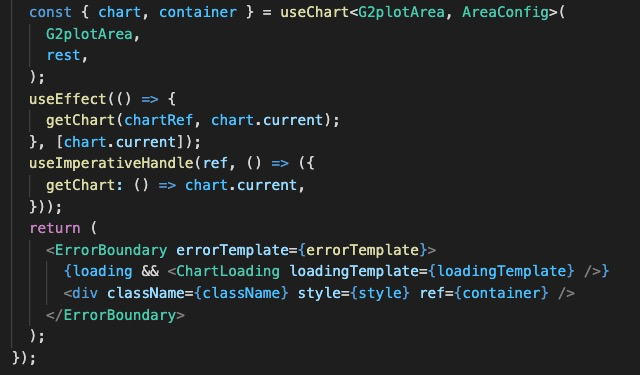 |
可以看出,设置为 80 的时候,代码行数瞬间增加了不少,突然感觉月入百万行代码不再困难!
正如上文所述,这个是需要配合 Prettier - Code formatter 插件使用的,非 VSCode 的同学可以搜寻一下相关插件。
同时需要在设置里面做一些相关配置,确保我们 ctrl+s 的时候可以对代码进行格式化。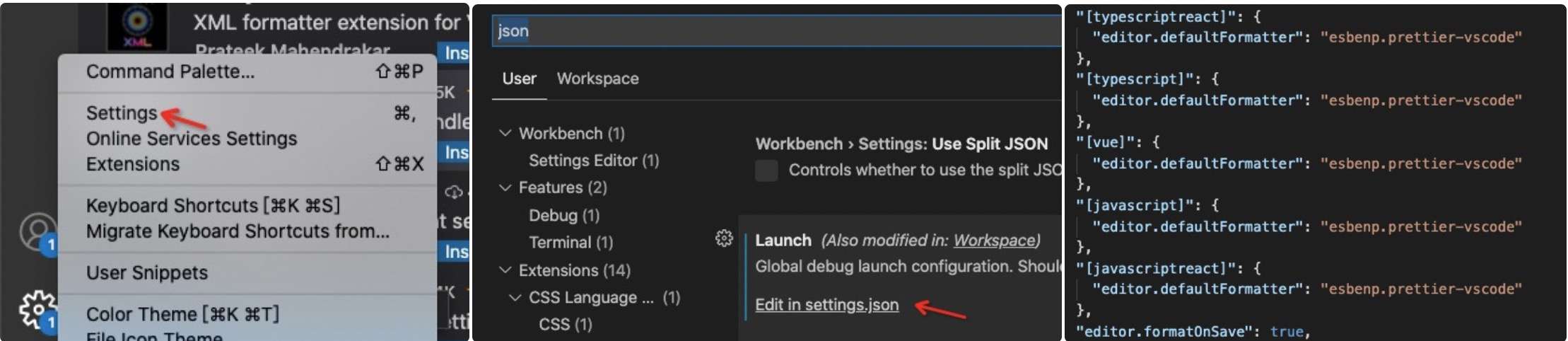
2、.eslintrc: 代码检测工具,假如我们有如下配置,我们限定了代码里面出现 console 语句时会出现错误,当我们在代码例如输入 console.log 语句时,会接收到 eslint 的错误提示。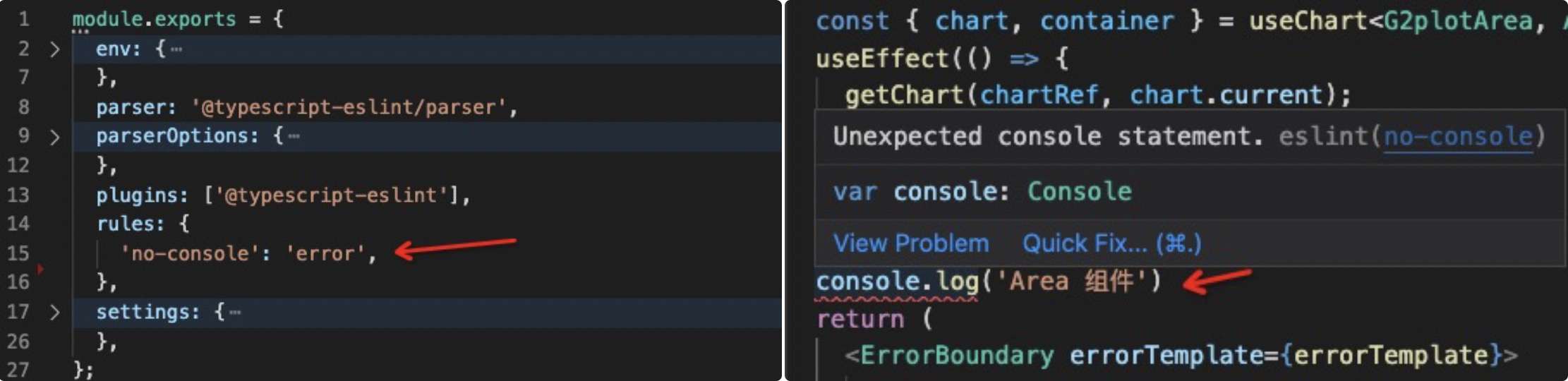
根目录这么多的配置,packages 里面是不是都需要实现复制一份呢?其实不是的,大部分配置是整个项目共享的,而像 eslint、tsconfig 其实是可以使用继承的,我们看一下 packages/plots 的配置,由于不需要特殊逻辑,完全继承即可,遵循 DRY 原则。
{"extends": "../../tsconfig.json","include": ["src"]}
总结
Ant Design Charts 简单却又不简单,该如何选择呢?如果项目需要特别炫,高大上的那种感觉,不推荐使用 Charts ,因为你用 D3 也不一定能满足业务需求,其它情况可以选择,因为 Charts 在保证易用性的同时,灵活度并没有丢失,甚至可以直接引入 G2 这种底层库。
import { G2 } from '@ant-design/charts';const data = [{ time: '9:00-10:00', value: 30 },{ time: '10:00-11:00', value: 90 },{ time: '11:00-12:00', value: 50 },{ time: '12:00-13:00', value: 30 },{ time: '13:00-14:00', value: 70 }];const chart = new G2.Chart({container: 'container',autoFit: true,height: 500,});chart.data(data);chart.tooltip({showMarkers: false});chart.interaction('active-region');chart.interval().position('time*value');chart.render();
蚂蚁体验技术部正在如饥似渴的寻找会玩的同学,如果您正在看机会或者想挑战一下自己,也让自己快速成长,欢迎您发送简历至我的邮箱:liufu.lf@antgroup.com,十分期待你的来信。

若有收获,就点个赞吧
0 人点赞
