最初,JavaScript 只能在 Web 浏览器中运行,但是随着 Node 的出现,现在 JavaScript 也可以在服务端运行。虽然我们可能知道应该在何时何地去使用它, 但是我们真的了解这些脚本执行的背后发生了什么吗?
如果您觉得自己对 JavaScript 引擎有了一些了解的话,可以先给自己鼓个掌,但不要急着关掉本文,我相信阅读完成后您仍然可以从中学到一些东西。
JavaScript 是一门高级语言,但是最终计算机能理解只有0和1。那么我们编写的代码是如何被计算机理解的呢?掌握所学编程语言的基础知识将让您能编写出更好的代码。在本文中,我们仅探讨一个问题:JavaScript 是如何工作的?
JavaScript 引擎
这是本文将要探索的主要内容,它负责使计算机理解我们编写的 JS 代码。JavaScript 引擎是一种用于将我们的代码转换为机器可读语言的引擎。如果没有 JavaScript 引擎,您编写的代码对计算机来说简直是一堆“胡言乱语”。不仅仅是 JavaScript ,其他所有编程语言都需要一个类似的引擎,来将这些“胡言乱语”转换成对计算机有意义的语言。
目前有多种 JavaScript 引擎在可供使用。您可以在 Wikipedia 上查阅所有可用的 JavaScript 引擎。它们也被称为 ECMAScript 引擎,这样叫的具体原因会在下文中提及。下面是一些我们日常可能会用到的 JavaScript 引擎:
- Chakra, Microsoft IE/Edge
- SpiderMonkey, FireFox
- V8, Chrome
除此之外的其它引擎,可以自行搜索了解。接下来,我们将深入研究这些引擎,以了解它们是如何翻译 JavaScript 文件的。
JavaScript 引擎的内里
我们已经知道了引擎是必须的,由此可能不禁会想:
是谁发明了 JavaScript 引擎?
答案是,任何人都可以。它只是分析我们的代码并将其翻译的另一种语言的工具。V8 是最受欢迎的 JavaScript 引擎之一,也是 Chrome 和 NodeJS 使用的引擎。它是用 C++(一种底层语言)编写的。但是如果每个人都创造一个引擎,那场面就不是可控范围内的了。
因此,为了给这些引擎确立一个规范,ECMA(European Computer Manufacturers Association)的标准诞生了,该标准主要提供如何编写引擎和 JavaScript 所有功能的规范。这就是新功能能在 ECMAScript 6、7、8 上实现的原因。同时,引擎也进行了更新以支持这些新功能。于是,我们便可以在开发过程中检查了浏览器中 JS 高级功能的可用性。
下面我们对 V8 引擎进行进一步的探索,因为基本概念在所有引擎中是一致的。
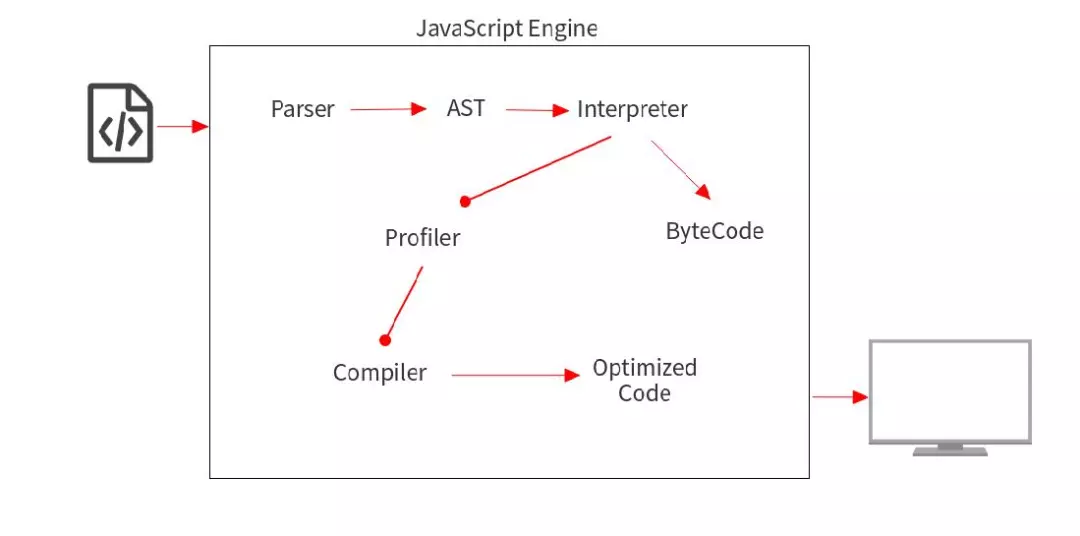
JavaScript V8 Engine
上图就是 JS Engine 内部的工作流程。我们输入的代码将通过以下阶段,
- Parser
- AST(抽象语法树)
- Interpreter 生成 ByteCode
- Profiler
- Compiler 生成优化后的代码
别被上面的流程给唬住了,在几分钟后您将了解它们是协同运作的。
在进一步深入这些阶段之前,您需要先了解 Interpreter 和 Compiler 的区别。
Interpreter VS Compiler
通常,将代码转换成机器可读语言的方法有两种。我们将要讨论的概念不仅适用于 JavaScript ,而且适用于大多数编程语言,例如 Python,Java 等。
- Interpreter 逐行读取代码并立即执行。
- Compiler 读取您的整个代码,进行一些优化,然后生成优化后的代码。
让我们来看下面这个例子。
function add(a, b){return a + b;}for( let i = 0; i < 1000; i += 1 ){add(1 + 1);}
上面的示例循环调用了 add 函数1000次,该函数将两个数字相加并返回总和。
Interpreter 接收上面的代码后,它将逐行读取并立即执行代码,直到循环结束。它的工作仅仅是实时地将代码转换为我们的计算机可以理解的内容。
如果这段代码接受者是 Compiler,它会先完整地读取整个程序,对我们要执行的代码进行分析,并生成电脑可以读懂的机器语言。过程如同获取 X(我们的JS文件)并生成 Y(机器语言)一样。如果我们使用 Interpreter 执行 Y,则会获得与执行 X 相同的结果。
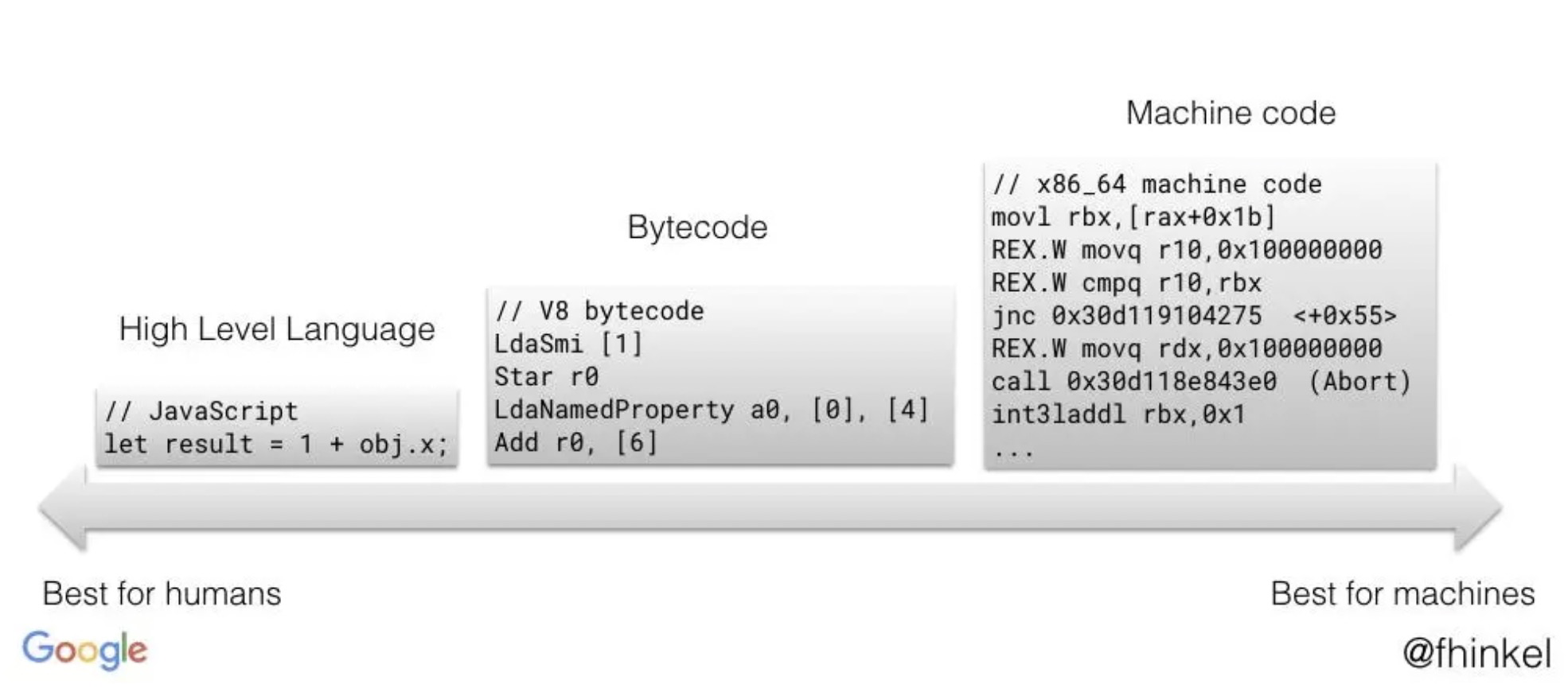
从上图中可以看出,ByteCode 只是中间码,计算机仍需要对其进行翻译才能执行。但是 Interpreter 和 Compiler 都将源代码转换为机器语言,它们唯一的区别在于转换的过程不尽相同。
- Interpreter 逐行将源代码转换为等效的机器代码。
- Compiler 在一开始就将所有源代码转换为机器代码。
如果你想了解更多它们之前的区别,推荐阅读这篇文章。
当您阅读完上面的推荐文章后,您可能已经了解到 Babel 实际上是一个 JS Compiler ,它可以接收您编写的新版本 JS 代码并向下编译为与浏览器兼容的 JS 代码(旧版本的 JS 代码)。
Interpreter 和 Compiler 的优缺点
Interpreter 的优点是无需等待编译即可立即执行代码。这对在浏览器中运行 JS 提供了极大的便利,因为所有用户都不想浪费时间在等待代码编译这件事上。但是,当有大量的 JS 代码需要执行时会运行地比较慢。还记得上面例子中的那一小段代码吗?代码中执行了1000次函数调用。函数 add 被调用了1000次,但他的输出保持不变。但是 Interpreter 还是逐行执行,会显得比较慢。
在同样的情况下,Compiler 可以通过用2代替循环(因为 add 函数每次都是执行1 + 1)来进行一些优化。Compiler 最终给出的优化代码可以在更短的时间内执行完成。
综上所述,Interpreter 可以立即开始执行代码,但不会进行优化。Compiler 虽然需要花费一些时间来编译代码,但是会生成对执行时更优的代码。
好的,Interpreter 和 Compiler 必要知识我们已经了解了。现在让我们回到主题——JS 引擎。
因此,考虑到编译器和解释器的优缺点,如果我们同时利用两者的优点,该怎么办?这就是 JIT(Just In Time) Compiler 的用武之地。它是 Interpreter 和 Compiler 的结合,现在大多数浏览器都在更快,更高效地实现此功能。同时 V8 引擎也使用此功能。
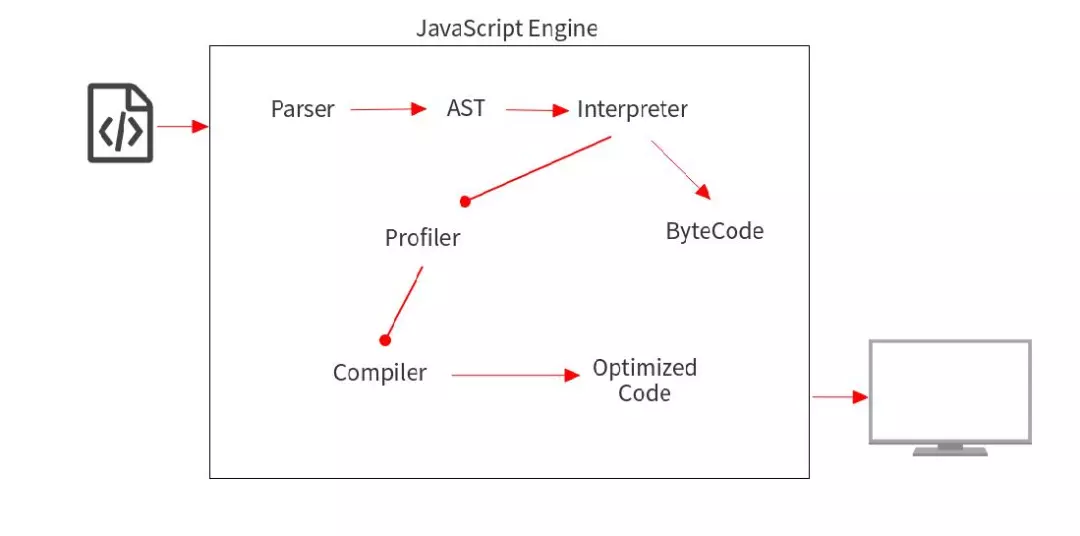
JavaScript V8 Engine
在这个过程中,
Parser 是一种通过各种 JavaScript 关键字来识别,分析和分类程序各个部分的解析器。它可以区分代码是一个方法还是一个变量。
然后,AST(抽象语法树) 基于 Parser 的分类构造树状结构。您可以使用 AST Explorer 查看该树的结构。
随后将 AST 提供给 Interpreter 生成 ByteCode。如上文所述,ByteCode 不是最底层的代码,但可以被执行。在此阶段,浏览器借助 V8 引擎执行 ByteCode 进行工作,因此用户无需等待。
同时,Profiler 将查找可以被优化的代码,然后将它们传递给 Compiler。Compiler 生成优化代码的同时,浏览器暂时用 ByteCode 执行操作。并且,一旦 Compiler 生成了优化代码,优化代码则将完全替换掉临时的 ByteCode。
通过这种方式,我们可以充分利用 Interpreter 和 Compiler 的优点。Interpreter 执行代码的同时,Profiler 寻找可以被优化的代码,Compiler 则创建优化的代码。然后,将 ByteCode 码替换为优化后的较为底层的代码,例如机器代码。
这仅意味着性能将在逐渐提高,同时不会有阻塞执行的时间。
关于 ByteCode
作为机器代码,ByteCode 不能被所有计算机理解及执行。它仍然需要像虚拟机或像 Javascript V8 引擎这样的中间件才能将其转换为机器可读的语言。这就是为什么我们的浏览器可以在上述5个阶段中借助 JavaScript 引擎在 Interpreter 中执行 ByteCode 的原因。
所以您可以会有另一个问题,
JavaScript 是一门解释型语言吗?
JavaScript 是,但不完全是一门解释型语言。Brendan Eich 最初是在 JavaScript 的早期阶段创建 JavaScript 引擎 “ SpiderMonkey” 的。该引擎有一个 Interpreter 来告诉浏览器该怎么执行代码。但是现在我们的引擎不仅包括了 Interpreter,还有 Compiler。我们的代码不仅可以被转换成 ByteCode,还可以被编译输出优化后的代码。因此,从技术上讲,这完全取决于引擎是如何实现的。
JavaScript 引擎的整体工作原理就是这样。相信您无需学习 JavaScript 也可以理解。当然,您甚至可以在不知道 JavaScript 如何工作的情况下编写代码。但是,如果我们了解一些幕后的知识,或许能让我们编写出更好的代码。

若有收获,就点个赞吧
0 人点赞
