如果不同的系统或是同一个系统的不同主机之间共享了一个或一组资源,那么访问这些资源的时候,往往需要互斥来防止彼此干扰来保证一致性,在这种情况下,便需要使用到分布式锁
计费问题,进入号码池
分布式锁的实现方式总共有三种:
- 基于数据库实现分布式锁
- 基于缓存(Redis)实现分布式锁
- 基于Zookeeper实现分布式锁
基于数据库实现分布式锁(不推荐)
CREATE TABLE `t_ms_lock` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',`name` varchar(64) NOT NULL DEFAULT '' COMMENT '锁定的方法名',`desc` varchar(1024) NOT NULL DEFAULT '描述',`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '保存数据时间',PRIMARY KEY (`id`),UNIQUE KEY `uidx_name` (`name `) USING BTREE) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='锁定中的方法';
1. 唯一索引
因为我们对name做了唯一性约束,这里如果有多个请求同时提交到数据库的话,数据库会保证只有一个操作可以成功,那么我们就可以认为操作成功的那个线程获得了该方法的锁,可以执行方法体内容。
- 每隔一定时间把数据库中的超时数据清理一遍
2. 基于排他锁
在查询语句后面增加forupdate,数据库会在查询过程中给数据库表增加排他锁。当某条记录被加上排他锁之后,其他线程无法再在该行记录上增加排他锁。(这里再多提一句,InnoDB引擎在加锁的时候,只有通过索引进行检索的时候才会使用行级锁,否则会使用表级锁。这里我们希望使用行级锁,就要给method_name添加索引但是: MySql会对查询进行优化,即便在条件中使用了索引字段,但是否使用索引来检索数据是由MySQL 通过判断不同执行计划的代价来决定的,如果 MySQL 认为全表扫效率更高,比如对一些很小的表,它就不会使用索引,这种情况下 InnoDB 将使用表锁,而不是行锁。如果发生这种情况就悲剧了。。。 还有一个问题,就是我们要使用排他锁来进行分布式锁的lock,那么一个排他锁长时间不提交,就会占用数据库连接。一旦类似的连接变得多了,就可能把数据库连接池撑爆。
3. 基于乐观锁
reids实现分布式锁有三种方式
1、基于redis的 SETNX 实现分布式锁
//生成keyString lock = "order_"+orderId;// 生成valueString driverId = UUID.randomUUID().toString();// 1. 加超时时间: 防止锁没有释放// 2. 超时时间应该一次加,不应该分2行代码boolean lockStatus = stringRedisTemplate.opsForValue().setIfAbsent(lock.intern(), driverId, 10L, TimeUnit.SECONDS);if(!lockStatus) {return null;}try {System.out.println("用户:"+driverId+" 执行抢单逻辑");boolean b = orderService.grab(orderId, driverId);if(b) {System.out.println("用户:"+driverId+" 抢单成功");}else {System.out.println("用户:"+driverId+" 抢单失败");}} finally {// 3.下面代码避免释放别人的锁if((driverId).equals(stringRedisTemplate.opsForValue().get(lock.intern()))) {stringRedisTemplate.delete(lock.intern());}}
如果业务的执行时间超过了锁释放的时间,会怎么办呢?我们可以使用守护线程,只要我们当前线程还持有这个锁,到了10S的时候,守护线程会自动对该线程进行加时操作,会续上30S的过期时间,直到把锁释放,就不会在进行续约了,开启一个子线程,原来时间是N,每隔N/3,在去续上N
2、Redisson实现分布式锁
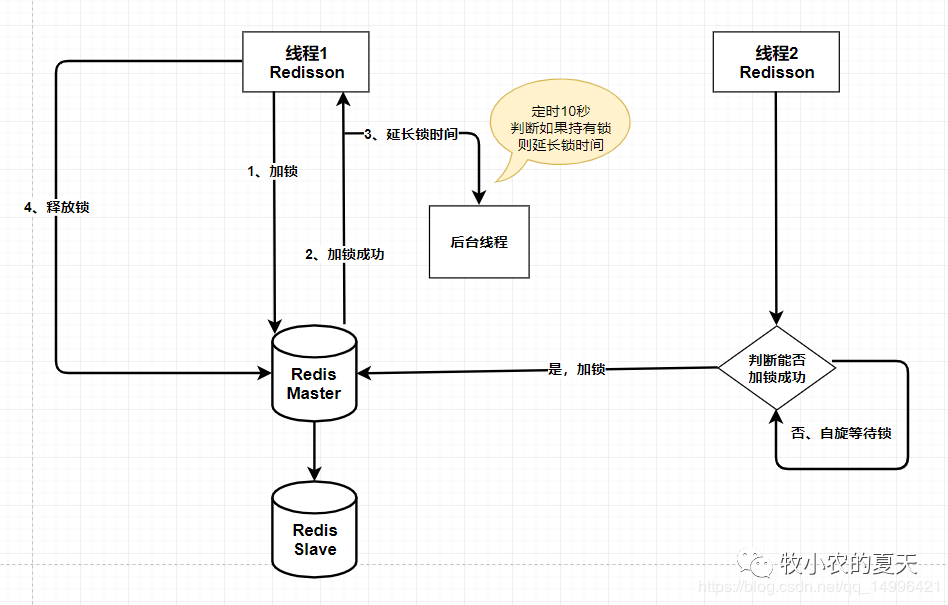
@Service("grabRedisRedissonService")public class GrabRedisRedissonServiceImpl implements GrabService {@AutowiredRedissonClient redissonClient;@AutowiredOrderService orderService;@Overridepublic ResponseResult grabOrder(int orderId , int driverId){//生成keyString lock = "order_"+(orderId+"");RLock rlock = redissonClient.getLock(lock.intern());try {// 此代码默认 设置key 超时时间30秒,过10秒,再延时rlock.lock();System.out.println("用户:"+driverId+" 执行抢单逻辑");boolean b = orderService.grab(orderId, driverId);if(b) {System.out.println("用户:"+driverId+" 抢单成功");}else {System.out.println("用户:"+driverId+" 抢单失败");}} finally {rlock.unlock();}return null;}}
锁的有效时间(lock validity time),设置成多少合适?
应该设置稍微短一些,如果线程持有锁,开启线程自动延长有效期
3、使用redLock实现分布式锁
Redis官方对于实现分布式锁的指导规范。Redlock的算法描述就放在Redis的官网上:https://redis.io/topics/distlock
事实上这类琐最大的缺点就是它加锁时只作用在一个Redis节点上,即使Redis通过sentinel保证高可用,如果这个master节点由于某些原因发生了主从切换,那么就会出现锁丢失的情况:
- 在Redis的master节点上拿到了锁;
- 但是这个加锁的key还没有同步到slave节点;
- master故障,发生故障转移,slave节点升级为master节点;
- 导致锁丢失。
在分布式版本的算法里我们假设我们有N个Redis master节点,这些节点都是完全独立的,我们不用任何复制或者其他隐含的分布式协调算法。我们已经描述了如何在单节点环境下安全地获取和释放锁。因此我们理所当然地应当用这个方法在每个单节点里来获取和释放锁。在我们的例子里面我们把N设成5,这个数字是一个相对比较合理的数值,因此我们需要在不同的计算机或者虚拟机上运行5个master节点来保证他们大多数情况下都不会同时宕机。一个客户端需要做如下操作来获取锁:
- 获取当前Unix时间,以毫秒为单位。
- 依次尝试从5个实例,使用相同的key和具有唯一性的value(例如UUID)获取锁。当向Redis请求获取锁时,客户端应该设置一个网络连接和响应超时时间,这个超时时间应该小于锁的失效时间。例如你的锁自动失效时间为10秒,则超时时间应该在5-50毫秒之间。这样可以避免服务器端Redis已经挂掉的情况下,客户端还在死死地等待响应结果。如果服务器端没有在规定时间内响应,客户端应该尽快尝试去另外一个Redis实例请求获取锁。
- 客户端使用当前时间减去开始获取锁时间(步骤1记录的时间)就得到获取锁使用的时间。当且仅当从大多数(N/2+1,这里是3个节点)的Redis节点都取到锁,并且使用的时间小于锁失效时间时,锁才算获取成功。
- 如果取到了锁,key的真正有效时间等于有效时间减去获取锁使用的时间(步骤3计算的结果)。
- 如果因为某些原因,获取锁失败(没有在至少N/2+1个Redis实例取到锁或者取锁时间已经超过了有效时间),客户端应该在所有的Redis实例上进行解锁(即便某些Redis实例根本就没有加锁成功,防止某些节点获取到锁但是客户端没有得到响应而导致接下来的一段时间不能被重新获取锁)。

若有收获,就点个赞吧
0 人点赞
