原理上有三种实现方式
- 要么消息共享(共用同一块磁盘)
- 要么消息同步(镜像集群)
- 要么元数据共享(普通集群)
普通集群
就是在多个联通的服务器上安装不同的RabbitMQ的服务,这些服务器上的RabbitMQ服务组成一个个节点,通过RabbitMQ内部提供的命令或者配置来构建集群,形成了RabbitMQ的普通集群模式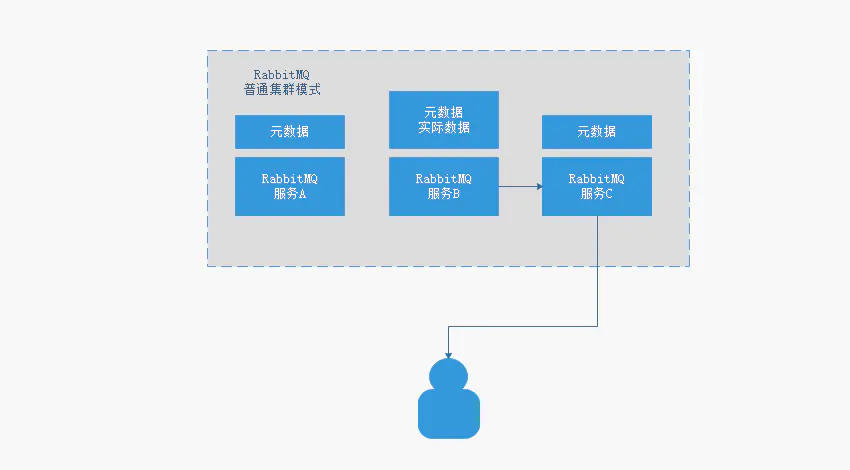
- 当用户向服务注册一个队列,该队列会随机保存到某一个服务节点上,然后将对应的元数据同步到各个不同的服务节点上,每个RabbitMQ都保存有相同的元数据
- 用户只需要链接到任意一个服务节点中,就可以监听消费到对应队列上的消息数据
- 但是RabbitMQ的实际数据却不是保存在每个RabbitMQ的服务节点中,这就意味着用户可能联系的是节点C,但是C上并没有对应的实际数据,也就是说节点C并不能提供消息供用户来消费,节点C会根据元数据,向服务节点B(该服务节点上有实际数据可供消费)请求实际数据,然后提供给用户进行消费
缺点:
- 请求可能会在RabbitMQ内部服务节点之间进行频繁的进行数据交互,这样的交互比较耗费资源
- 当其中一个RabbitMQ的服务节点宕机了,那么该节点上的实际数据就会丢失,用户再次请求时,就会请求不到数据,系统的功能就会出现异常
镜像集群
为了解决上面普通模式的两个显著的缺点,RabbitMQ官方提供另外一种集群模式:镜像集群模式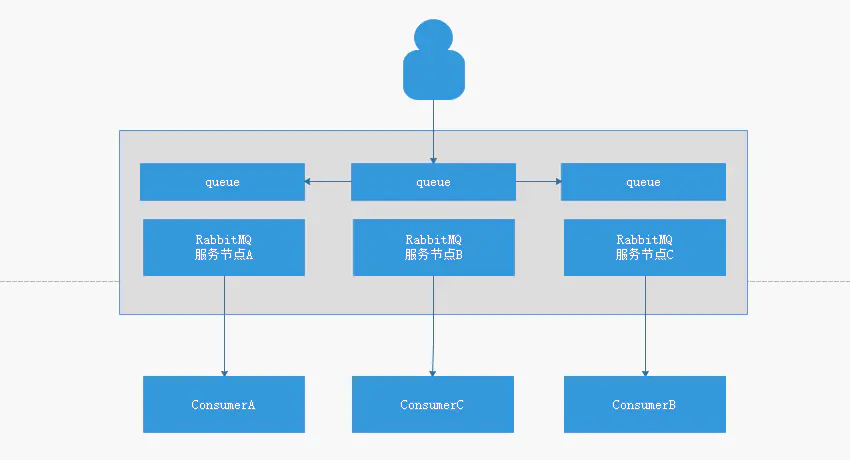
镜像集群模式和普通集群模式大体是一样的,不一样的是:
- 生产者向任一服务节点注册队列,该队列相关信息会同步到其他节点上
- 任一消费者向任一节点请求消费,可以直接获取到消费的消息,因为每个节点上都有相同的实际数据
- 任一节点宕机,不影响消息在其他节点上进行消费
缺点:
- 性能开销非常大,因为要同步消息到对应的节点,这个会造成网络之间的数据量的频繁交互,对于网络带宽的消耗和压力都是比较重的
- 没有扩展可言,rabbitMQ是集群,不是分布式的,所以当某个Queue负载过重,我们并不能通过新增节点来缓解压力,因为所以节点上的数据都是相同的,这样就没办法进行扩展了

若有收获,就点个赞吧
0 人点赞
