缓存的更新
缓存的数据一般都是有生命时间的,过了一段时间之后就会失效,再次访问时需要重新加载。缓存的失效是为了保证与数据源真实的数据保证一致性和缓存空间的有效利用性。下面将从使用场景、数据一致性、开发运维维护成本三个方面来介绍几种缓存的更新策略。
1、LRU/LFU/FIFO
这三种算法都是属于当缓存不够用时采用的更新算法。只是选出的淘汰元素的规则不一样:LRU淘汰最久没有被访问过的,LFU淘汰访问次数最少的,FIFO先进先出。
一致性:要清理哪些数据是由具体的算法定的,开发人员只能选择其中的一种,一致性差。
开发维护成本:算法不需要开发人员维护,只需要配置最大可使用内存即可,然后选择淘汰算法即可,故成本低。
使用场景:适合内存空间有限,数据长期不变动,基本不存在数据一不致性业务。比如一些一经确定就不允许变更的信息。
2、超时剔除
给缓存数据手动设置一个过期时间,比如Redis expire命令。当超过时间后,再次访问时从数据源重新加载并设回缓存。
一致性:主要处决于缓存的生命时间窗口,这点由开发人员控制。但仍不能保证实时一致性,估一致性一般。
开发维护成本:成本不是很高,很多缓存系统都自带过期时间API。比如Redis expire
使用场景:适合于能够容忍一定时间内数据不一致性的业务,比如促销活动的描述文案。
3、主动更新
如果数据源的数据有更新,则主动更新缓存。
一致性:三者当中一致性最高,只要能确定正确更新,一致性就能有保证。
开发维护成本:这个相对来说就高了,业务数据更新与缓存更新藕合了一起。需要处理业务数据更新成功,而缓存更新失败的情景,为了解耦一般用来消息队列的方式更新。不过为了提高容错性,一般会结合超时剔除方案,避免缓存更新失败,缓存得不到更新的场景。
使用场景:对于数据的一致性要求很高,比如交易系统,优惠劵的总张数。
所以总的来说缓存更新的最佳实践是:
低一致性业务:可以选择第一并结合第二种策略。
高一致性业务:二、三策略结合。
无底洞优化
- 什么是缓存无底洞问题:
Facebook的工作人员反应2010年已达到3000个memcached节点,储存数千G的缓存。他们发现一个问题–memcached的连接效率下降了,于是添加memcached节点,添加完之后,并没有好转。称为“无底洞”现象
2. 缓存无底洞产生的原因:
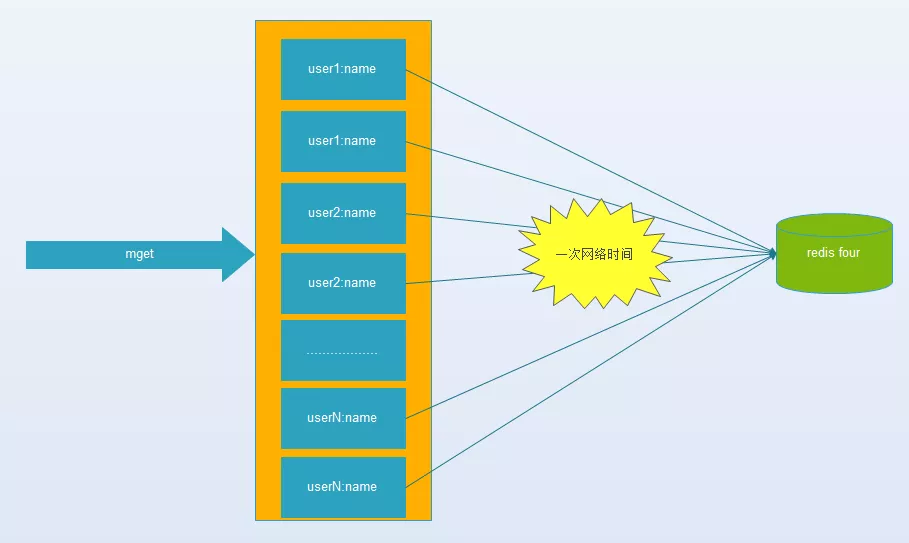
键值数据库或者缓存系统,由于通常采用hash函数将key映射到对应的实例,造成key的分布与业务无关,但是由于数据量、访问量的需求,需要使用分布式后(无论是客户端一致性哈性、redis-cluster、codis),批量操作比如批量获取多个key(例如redis的mget操作),通常需要从不同实例获取key值,相比于单机批量操作只涉及到一次网络操作,分布式批量操作会涉及到多次网络io。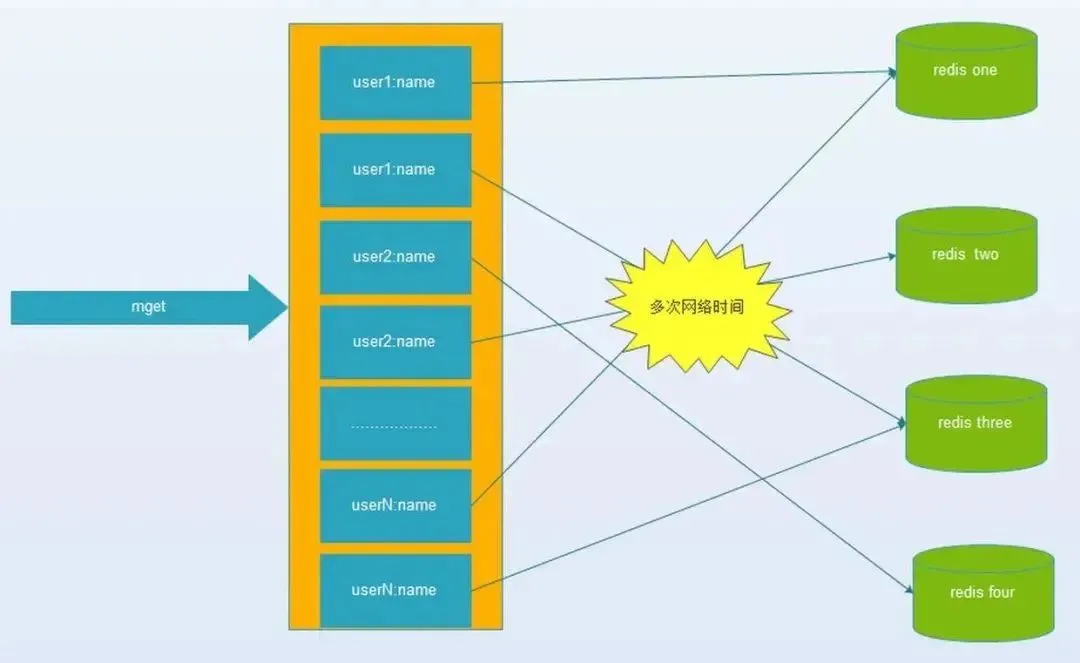
3. 无底洞问题带来的危害:
(1) 客户端一次批量操作会涉及多次网络操作,也就意味着批量操作会随着实例的增多,耗时会不断增大。
(2) 服务端网络连接次数变多,对实例的性能也有一定影响。
所以无底洞似乎是一个无解的问题。实际上我们只要了解无底洞产生原因在业务前期规划好就可以减轻甚至避免无底洞的产生。
1、首先如果你的业务查询没有,像mget这种批量操作,恭喜你,无底洞将远离你。
2、将集群以项目组做隔离,这样每组业务的redis/memcache集群就不会太大。
3、如果你公司的最大峰值流量远不及FB,可能也不需要担心这个问题。
那技术上有没有一些优先点?解决思路如下:
1. IO的优化思路:
(1) 命令本身的效率:例如sql优化,命令优化。
(2) 网络次数:减少通信次数。
(3) 降低接入成本:长连/连接池,NIO等。
(4) IO访问合并:O(n)到O(1)过程:批量接口(mget)。
(1)、(3)、(4)通常是由缓存系统的设计开发者来决定的,作为使用者我们可以从(2)减少通信次数上做优化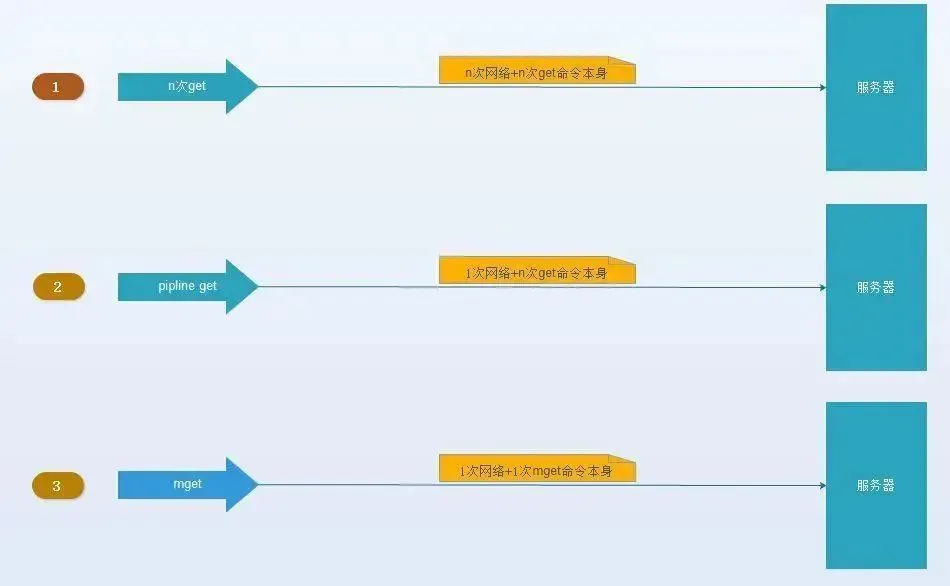
以mget来说有四种方案:
(1).串行mget
将mget操作(n个key)拆分为逐次执行N次get操作, 很明显这种操作时间复杂度较高,它的操作时间=n次网络时间+n次命令时间,网络次数是n,很显然这种方案不是最优的,但是足够简单。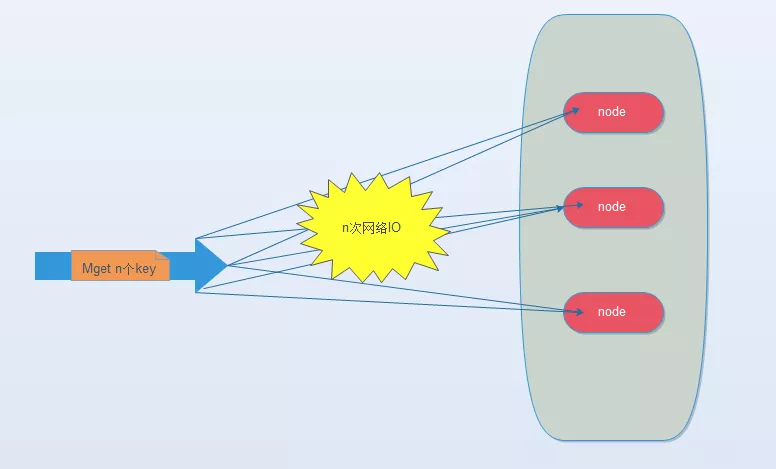
(2). 串行IO
将mget操作(n个key),利用已知的hash函数算出key对应的节点,这样就可以得到一个这样的关系:Map,也就是每个节点对应的一些keys
它的操作时间=node次网络时间+n次命令时间,网络次数是node的个数,很明显这种方案比第一种要好很多,但是如果节点数足够多,还是有一定的性能问题。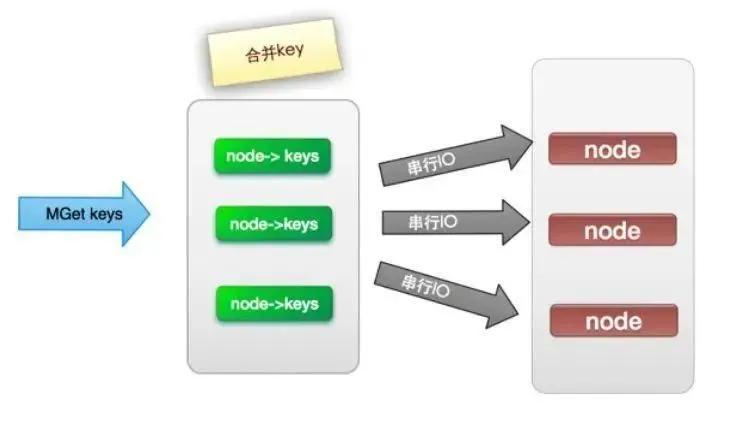
(3). 并行IO
此方案是将方案(2)中的最后一步,改为多线程执行,网络次数虽然还是nodes.size(),但网络时间变为o(1),但是这种方案会增加编程的复杂度。
它的操作时间=1次网络时间+n次命令时间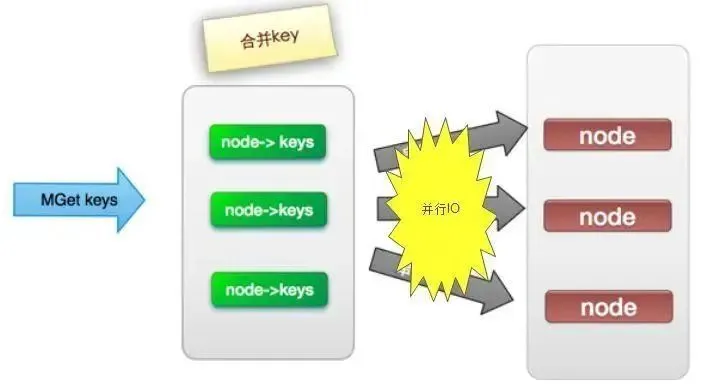
(4). hash-tag实现。
由于hash函数会造成key随机分配到各个节点,那么有没有一种方法能够强制一些key到指定节点到指定的节点呢?
redis提供了这样的功能,叫做hash-tag。什么意思呢?假如我们现在使用的是redis-cluster(10个redis节点组成),我们现在有1000个k-v,那么按照hash函数(crc16)规则,这1000个key会被打散到10个节点上,那么时间复杂度还是上述(1)~(3)
那么我们能不能像使用单机redis一样,一次IO将所有的key取出来呢?hash-tag提供了这样的功能,如果将上述的key改为如下,也就是用大括号括起来相同的内容,那么这些key就会到指定的一个节点上。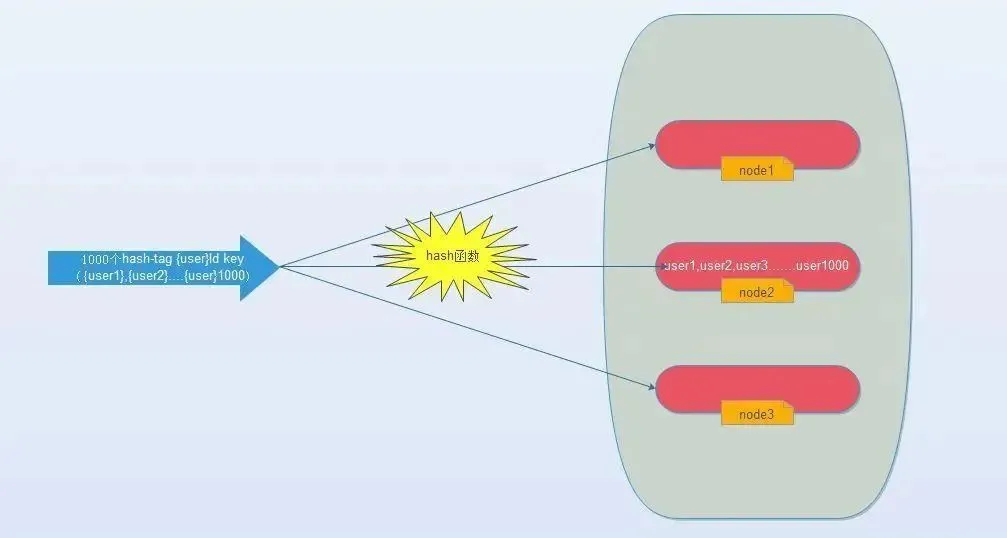
它的操作时间=1次网络时间+n次命令时间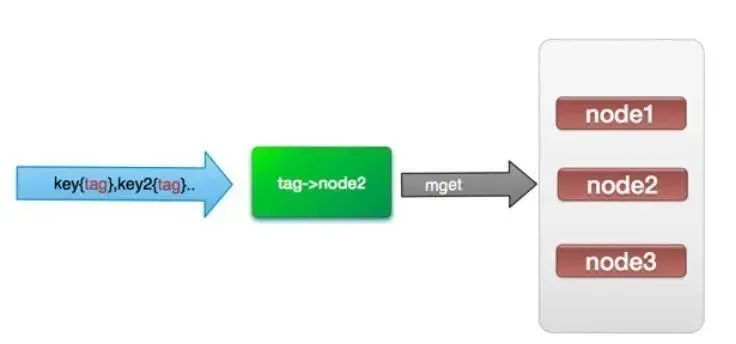
3. 四种批量操作解决方案对比: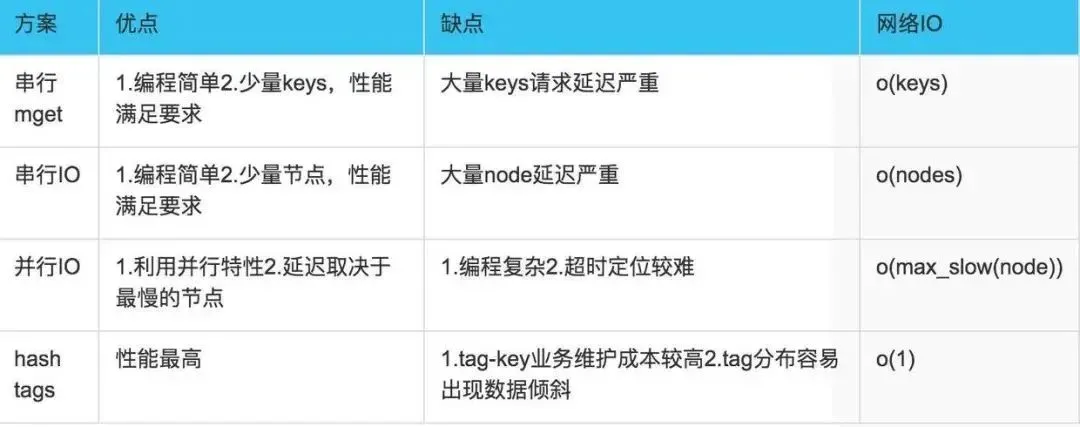
关于无底洞优化这块的内容,详细可参考并发编程网上面的一篇文章。
提一下,生产中串行IO和并行IO的方案,我都有用过,其实效果还好。毕竟结点都是有限,不是FB、BAT这种流量那么多。并行IO如果你是用java,并且JDK8或以上,只要开启labmda并行流就可以实现并行IO了,很方便的,编程起来并不复杂,超时定位的话,可以加多些日志。

若有收获,就点个赞吧
0 人点赞
