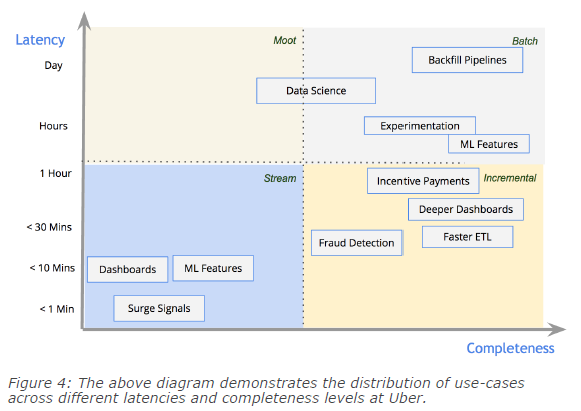
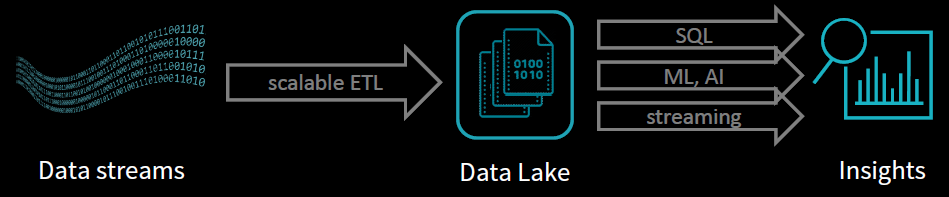
背景
数据存储作为数据挖掘流程(集成、处理、分析)的底层服务,对上层数据处理的功能(读写)、性能(查询)有较大的影响;随着技术的发展,大数据处理(Spark)相对成熟,而大数据存储(Spark-sql\Cassandra)、数据应用(LinkIs\Zeppelin)相对薄弱;其中特别是数据存储对数据处理的影响较大,往往面临如下问题:
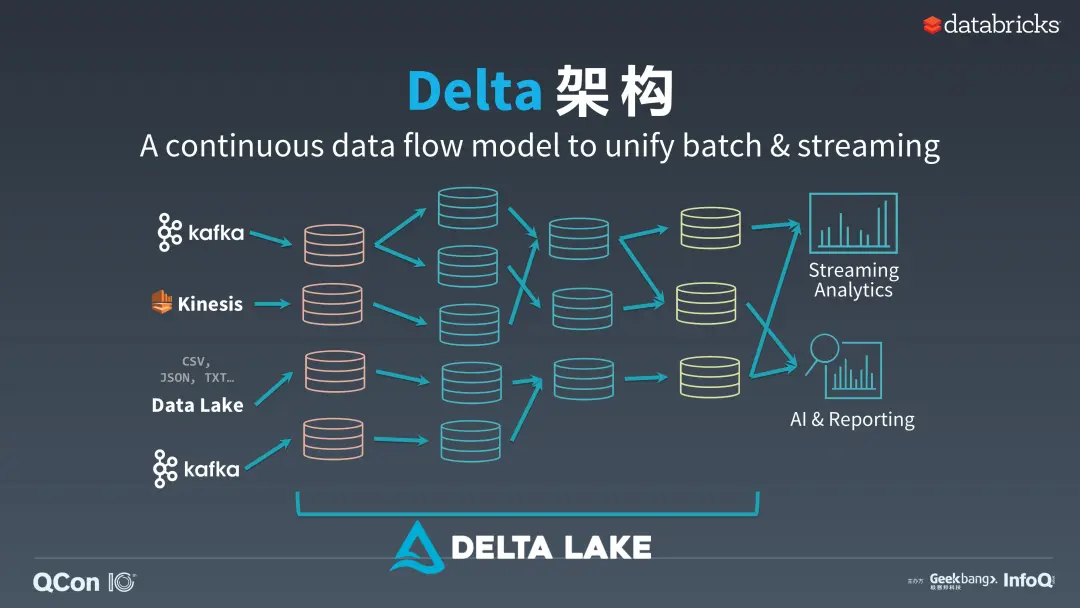
数据架构如何批、流统一(小文件问题)
高效写与分析读如何同时支持
- ACID、Upsert、Delete语义支持(并发读写、有限更新支持)
- 海量元数据(hive partition)
- 数据存储与计算分离
同时需要继承及优化原有数据仓库的能力:
- SQL(DDL、DML)能力
- 支持计算引擎CBO
思考总结
总结
- 如果从应用且当前的角度(目前我们这边是spark为主要计算引擎,目前满足我们的使用需求及需要解决的问题)出发,建议数据湖以Delta lake为方案
- thrift server查询
- DDL、DML
- ACID
- 如果从设计及发展的角度出发(当前仅支持file粒度的remove、add语义),建议数据湖以Iceberg为方案
- table format
- 存储计算分离
- roadmap,通过spark3.0的DataSourceV2及multi Catalog支持DDL、DML
- 如果从后端大数据的角度出发【整合hbase(写)和parquet(读)的优点;功能深度有绝对优势】,建议数据湖以HUDI为方案
- index
- merge on read
- realtime view
- hive sync(external table)【select】
- compact
目前的数据湖方案是为了解决之前相应的问题;
- HUDI,融合HBASE写及parquet读的有点(与KUDU目标有重合),以实现upsert及increase为首要目标
- 2种存储模式、3个读取视图
- Delta Lake,解决批流的当前架构的问题;提出及实现Delta架构
- Lambda:两个不同的 pipeline,它需要维护两套分别跑在批处理和实时计算系统上面的代码;
- Kappa:通过控制Streaming的Window为方案
- 用Kafka或者类似的分布式队列系统保存数据,你需要几天的数据量就保存几天。
- 当需要全量重新计算时,重新起一个流计算实例,从头开始读取数据进行处理,并输出到一个新的结果存储中。
- 当新的实例做完后,停止老的流计算实例,并把老的一些结果删除。
- Delta:见附件(delta架构001-3)
- Iceberg,复用hive table的事实标准,同时优化其ACID方案及问题;另外尽量做到存储与计算分离
- 对于这三者之间总结性质的区别和看法,我引用邵赛赛的一段话,我觉得他总结的足够好了:
- Iceberg 的设计初衷更倾向于定义一个标准、开放且通用的数据组织格式,同时屏蔽底层数据存储格式上的差异,向上提供统一的操作 API,使得不同的引擎可以通过其提供的 API 接入;
- Hudi 的设计初衷更像是为了解决流式数据的快速落地,并能够通过 upsert 语义进行延迟数据修正;
- Delta Lake 作为 Databricks 开源的项目,更侧重于在 Spark 层面上解决 Parquet、ORC 等存储格式的固有问题,并带来更多的能力提升。
- 他们都提供了 ACID 的能力,都基于乐观锁实现了冲突解决和提供线性一致性,同时相应地提供了 time travel 的功能。
如果用一个比喻来说明Delta、Iceberg、Hudi、Hive-ACID四者差异的话,可以把四个项目比做建房子。由于开源的Delta是Databricks闭源Delta的一个简化版本,它主要为用户提供一个table format的技术标准,闭源版本的Delta基于这个标准实现了诸多优化,这里我们主要用闭源的Delta来做对比。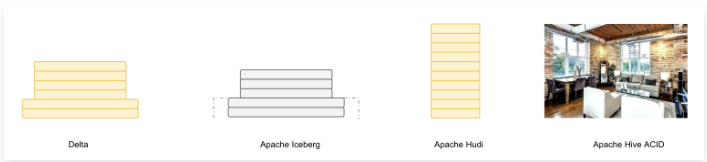
Delta的房子底座相对结实,功能楼层也建得相对比较高,但这个房子其实可以说是Databricks的,本质上是为了更好的壮大Spark生态,在Delta上其他的计算引擎难以替换Spark的位置,尤其是写入路径层面;Iceberg的建筑基础非常扎实,扩展到新的计算引擎或者文件系统都非常的方便,但是现在功能楼层相对低一点,目前最缺的功能就是upsert和compaction两个,Iceberg社区正在以最高优先级推动这两个功能的实现;Hudi的情况要相对不一样,它的建筑基础设计不如iceberg结实,举个例子,如果要接入Flink作为Sink的话,需要把整个房子从底向上翻一遍,把接口抽象出来,同时还要考虑不影响其他功能,当然Hudi的功能楼层还是比较完善的,提供的upsert和compaction功能直接命中广大群众的痛点。Hive的房子,看起来是一栋豪宅,绝大部分功能都有,把它做为数据湖有点像靠着豪宅的一堵墙建房子,显得相对重量级一点,另外正如Netflix上述的分析,细看这个豪宅的墙面是其实是有一些问题的。
| · | Delta | Hudi | Iceberg |
|---|---|---|---|
| Incremental Ingestion | Spark | Spark | Spark |
| ACID updates | HDFS, S3 (Databricks), OSS | HDFS | HDFS, S3 |
| Upserts/Delete/Merge/Update | Delete/Merge/Update | Upserts/Delete | No |
| Streaming sink | Yes | Yes | Yes(not ready?) |
| Streaming source | Yes | No | No |
| FileFormats | Parquet | Avro,Parquet | Parquet, ORC |
| Data Skipping | File-Level Max-Min stats + Z-Ordering (Databricks) | File-Level Max-Min stats + Bloom Filter | File-Level Max-Min Filtering |
| Concurrency control | Optimistic | Optimistic | Optimistic |
| Data Validation | Yes (Databricks) | No | Yes |
| Merge on read | No | Yes | No |
| Schema Evolution | Yes | Yes | Yes |
| File I/O Cache | Yes (Databricks) | No | No |
| Cleanup | Manual | Automatic | No |
| Compaction | Manual | Automatic | No |
抽象候选技术方案
MVCC(Multi-Version Concurrency Control)(Optimistic)
- snapshot
- Key idea: track all files in a table over time
- A snapshot is a complete list of files in a table
- Each write produces and commits a new snapshot
- Snapshot isolation without locking
- Readers use a current snapshot
- Writers produce new snapshots in isolation, then commit

- Any change to the file list is an atomic operation
- Append data across partitions
- Merge or rewrite files
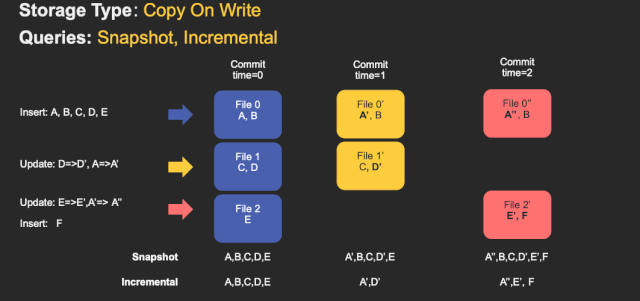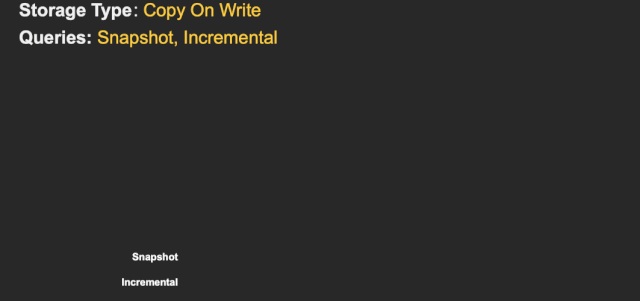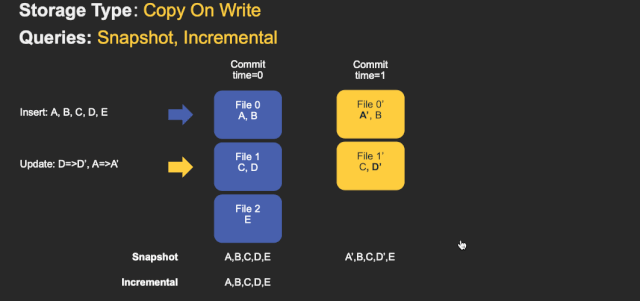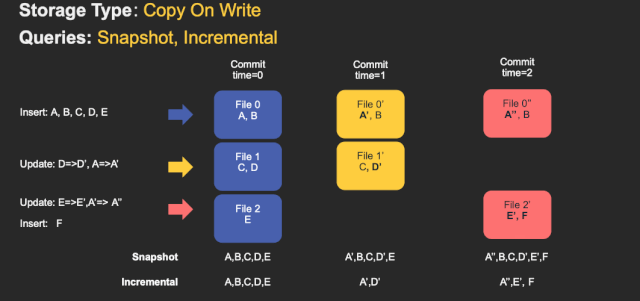
CopyOnWrite&MergeOnRead
- merge on read
- copy on write

Upsert merge(Join&keyIndex)
- Join
- keyIndex(bloomfilter)
Compaction(bin-packing)
- 有N(N > 100)个小文件(大小分布在[0, M]),现在希望尽可能的将这些小文件compact成接近且小于M的文件;
- 本质上,与文件的大小分布很相关
- 装箱问题(一维,二维,三维)
- 一维装箱
- 【延申】有大文件如何进行切分并重新进行组合,使得文件大小均接近且小于M
DataSkipping(CBO)
- Z-ordering
- File-Level Max-Min stats
- Bloom Filter
数据架构之我见
- 我理解的数据架构应该具备如下核心方面:
- 服务
- 集成
- 处理
- 计算与存储分离(Connector)
- 存储
- 批流统一(集成、处理)
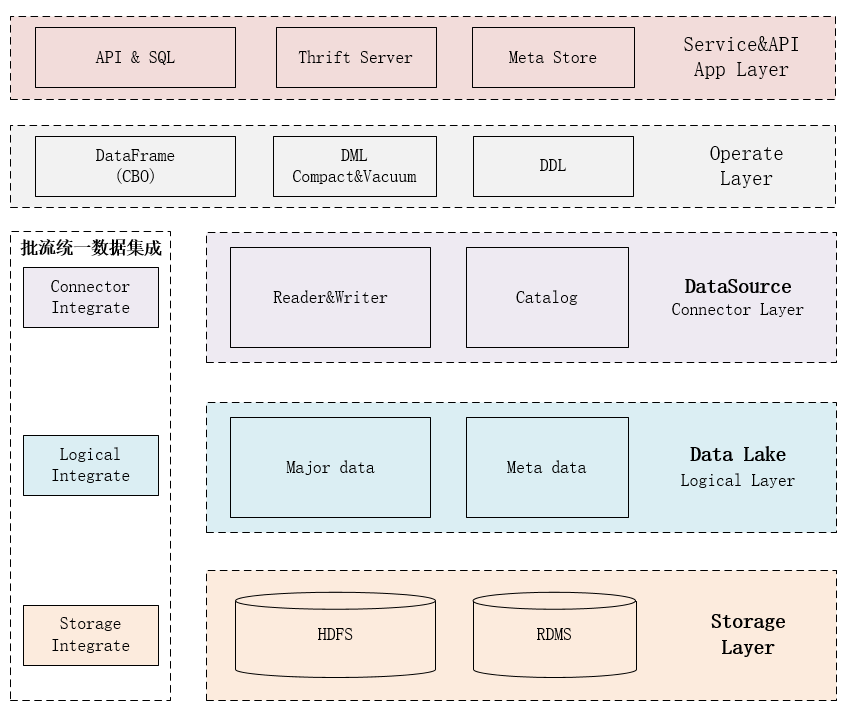
- App Layer(应用服务层)
- JDBC Thrift Server
- 支持SQL(DDL、DML)执行
- 长Yarn Spark任务
- JDBC MetaStore Thrift Server
- 元数据表达,支持元数据实体各种操作
- API & SQL
- 支持通过操作层使用连接层作用在数据逻辑层(表)
- JDBC Thrift Server
- Operate Layer(操作层)【批流统一】
- DataFrame
- 逻辑数据表及操作抽象表达
- DML
- Compact
- bin-packing
- Vacuum
- cleaner
- Select
- CBO
- Upsert
- COW
- join
- bloomfilter + key
- MOR
- COW
- Delete
- COW
- join
- bloomfilter + key
- MOR
- COW
- Insert
- Compact
- DDL
- Create
- Drop
- Alter
- DataFrame
- Connector Layer(连接层)【读取Prune、写入优化】【批流统一】
- Reader & Writer
- 将逻辑层数据表读取为操作层的DataFrame,并将操作层的相关谓语(where\limit)结合Catalog进行应用,达到最小、全(IO)读取数据的目的(宗旨:只读取需要的数据)
- Catalog
- 元数据抽象表达,支持各种prune
- Reader & Writer
- Logical Layer(逻辑数据层(数据湖))【API】
- Storage Layer(数据存储层)
- 数据集成
- Connector
- 一般支持批流统一
- Logical
- api
- Storage
- 底层文件+关联
- Connector
技术发展推演
如上数据架构的主要方面进行发展推演
- 核心主数据处理【成熟阶段0.9】
- 已经相对完善,特别是spark3.0支持如下特性:
- DPP(Dynamic Partition Pruning)
- AQE(Adaptive Query Execution)
- Join Hint
- 已经相对完善,特别是spark3.0支持如下特性:
- 数据Connector层【发展阶段0.6】
- 当前的DataSourceV2 元数据及操作相对功能支持不是很友好,有如下方面:
- Catalog仅仅支持一份Hive Meta【spark3.0会支持多个及自定义】
- 当前只考虑到Hive建(内、外)表逻辑,受限较多
- 建表操作过于复杂,我理解应该可以自定义实现CreateTableCommand【LogicalPlan】的处理逻辑
- 比如相关数据湖的建表逻辑【理论上应该像sparksql建表一样自然、简洁】
- Catalog仅仅支持一份Hive Meta【spark3.0会支持多个及自定义】
- SQL DML(Vacuum、Compact、Alter)等接口没有提供
- prune过于简单【受限于底层数据存储(统计信息不丰富)】
- 当前的DataSourceV2 元数据及操作相对功能支持不是很友好,有如下方面:
- 数据存储层【发展阶段0.4】
- 当前存储能提供的功能较为单一
- parquet
- sparksql table
- 后续发展的data lake相关技术就是为了解决当前面临的问题
- 当前存储能提供的功能较为单一
Delta Lake
Architect

Design
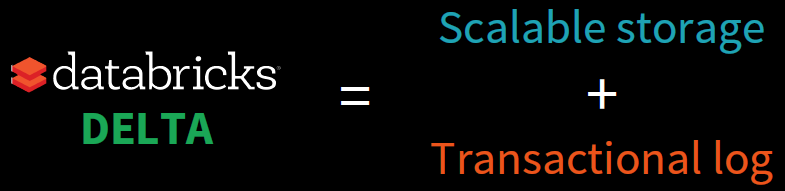

- Changes to the table are stored as ordered, atomic commits
- Each commit is a set of actions file in directory _delta_log
- Readers read the log in atomic units thus reading consistent snapshots
- Concurrent writers need to agree on the order of changes
- New commit files must be created mutually exclusively【互相排斥】
Concurrent



Challenge
- Challenges solved: Reliability
- Problem: Failed production jobs leave data in corrupt state requiring tedious recovery
- Solution: Failed write jobs do not update the commit log, hence partial / corrupt files not DELTA visible to readers
- Challenge: Lack of consistency makes it almost impossible to mix appends, deletes, upserts and get consistent reads
- Solution: All reads have full snapshot consistency, All successful writes are consistent; In practice, most writes don’t conflict, Tunable isolation levels (serializability by default)
- Challenge: Lack of schema enforcement creates, inconsistent and low quality data
- Solution: Schema recorded in the log, Fails attempts to commit data with incorrect schema, Allows explicit schema evolution, Allows invariant and constraint checks (high data quality)
- Problem: Failed production jobs leave data in corrupt state requiring tedious recovery
- Challenges solved: Performance
- Challenge: Too many small files increase resource usage significantly
- Solution: Transactionally performed compaction using OPTIMIZE
- Challenge: Partitioning breaks down with many dimensions and/or high cardinality columns
- Solution: Optimize using multi-dimensional clustering(ZORDER) on multiple columns
- Challenge: Too many small files increase resource usage significantly
Feature
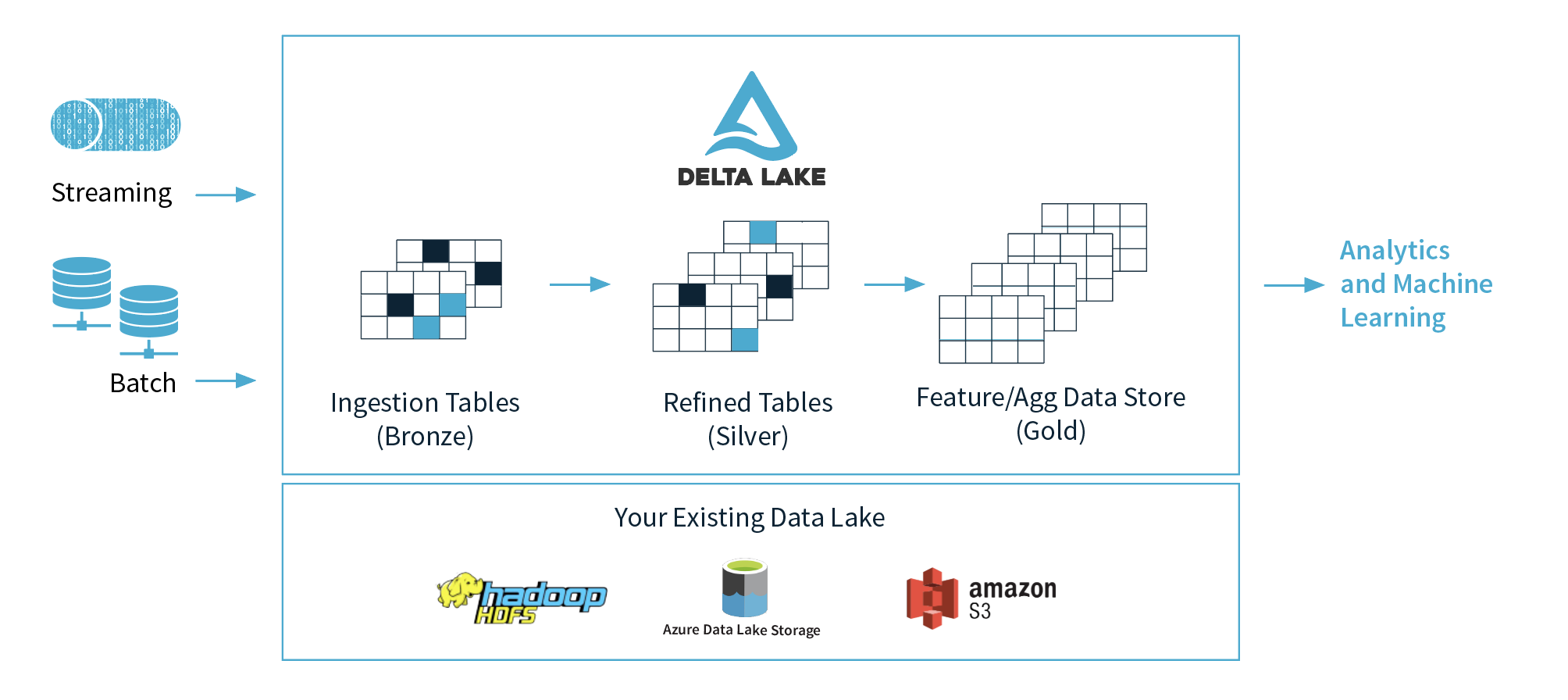
Delta Lake is an open-source storage layer that brings ACID transactions to Apache Spark™ and big data workloads.
- ACID Transactions: Data lakes typically have multiple data pipelines reading and writing data concurrently, and data engineers have to go through a tedious process to ensure data integrity, due to the lack of transactions. Delta Lake brings ACID transactions to your data lakes. It provides serializability, the strongest level of isolation level.
- Scalable Metadata Handling: In big data, even the metadata itself can be “big data”. Delta Lake treats metadata just like data, leveraging Spark’s distributed processing power to handle all its metadata. As a result, Delta Lake can handle petabyte-scale tables with billions of partitions and files at ease.
- Time Travel (data versioning): Delta Lake provides snapshots of data enabling developers to access and revert to earlier versions of data for audits, rollbacks or to reproduce experiments.
- Open Format: All data in Delta Lake is stored in Apache Parquet format enabling Delta Lake to leverage the efficient compression and encoding schemes that are native to Parquet.
- Unified Batch and Streaming Source and Sink: A table in Delta Lake is both a batch table, as well as a streaming source and sink. Streaming data ingest, batch historic backfill, and interactive queries all just work out of the box.
- Schema Enforcement: Delta Lake provides the ability to specify your schema and enforce it. This helps ensure that the data types are correct and required columns are present, preventing bad data from causing data corruption.
- Schema Evolution: Big data is continuously changing. Delta Lake enables you to make changes to a table schema that can be applied automatically, without the need for cumbersome DDL.
- 100% Compatible with Apache Spark API: Developers can use Delta Lake with their existing data pipelines with minimal change as it is fully compatible with Spark, the commonly used big data processing engine.
- Audit History: Delta Lake transaction log records details about every change made to data providing a full audit trail of the changes.
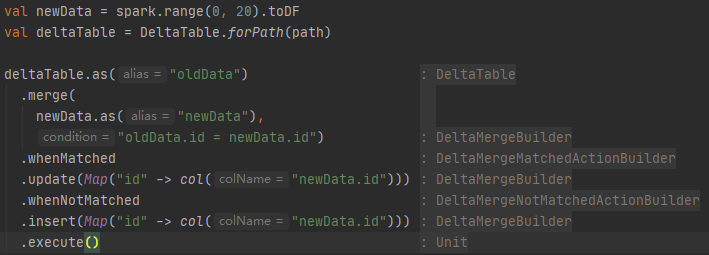
- Full DML Support: Delta Lake supports standard DML including UPDATE, DELETE and MERGE INTO providing developers more controls to manage their big datasets.
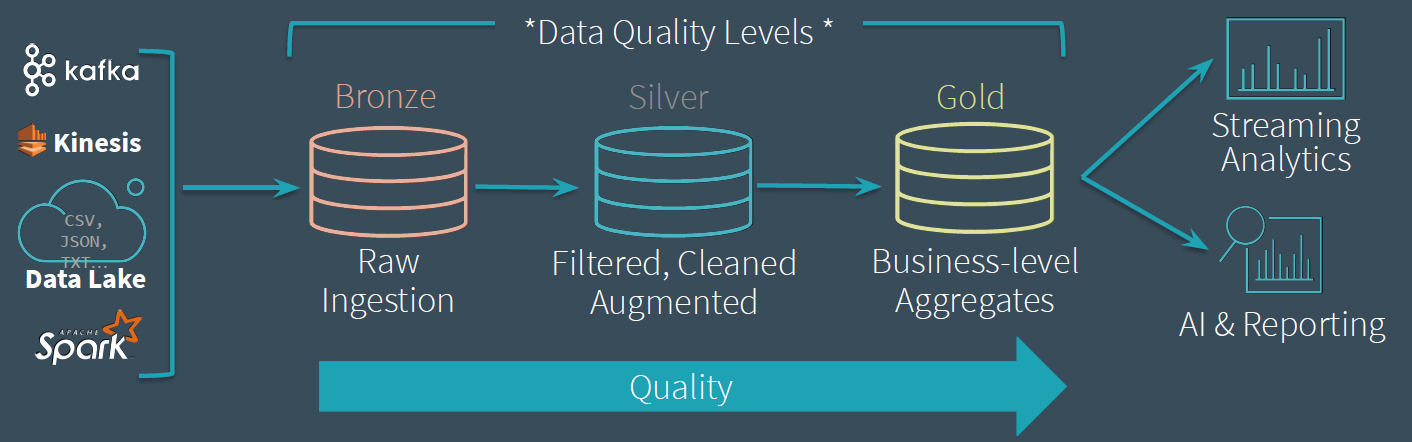
Delta Lake allows you to incrementally improve the quality of your data until it is ready for consumption.
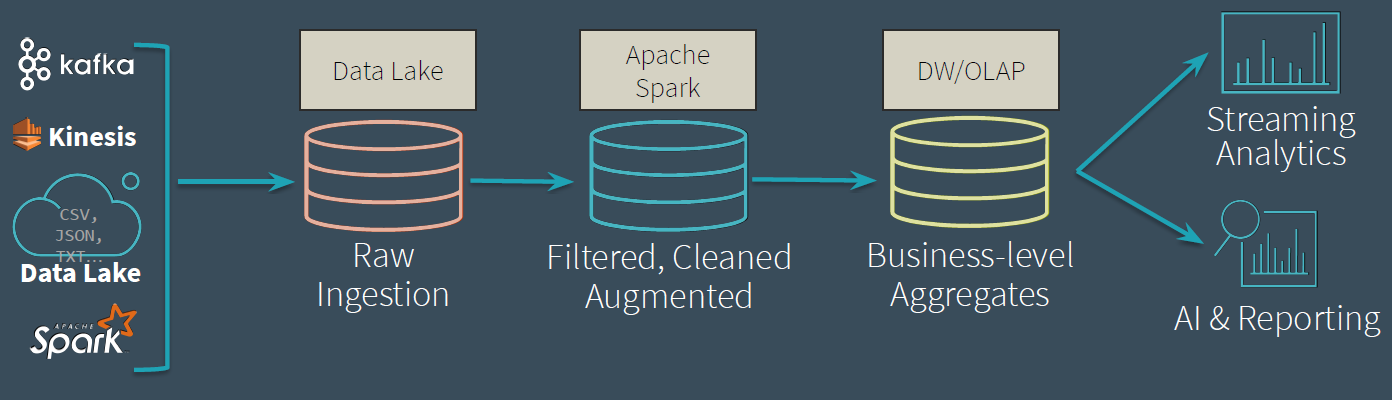
The Data Lifecycle
Transitioning from the Data Lifecycle to the Delta Lake Lifecycle
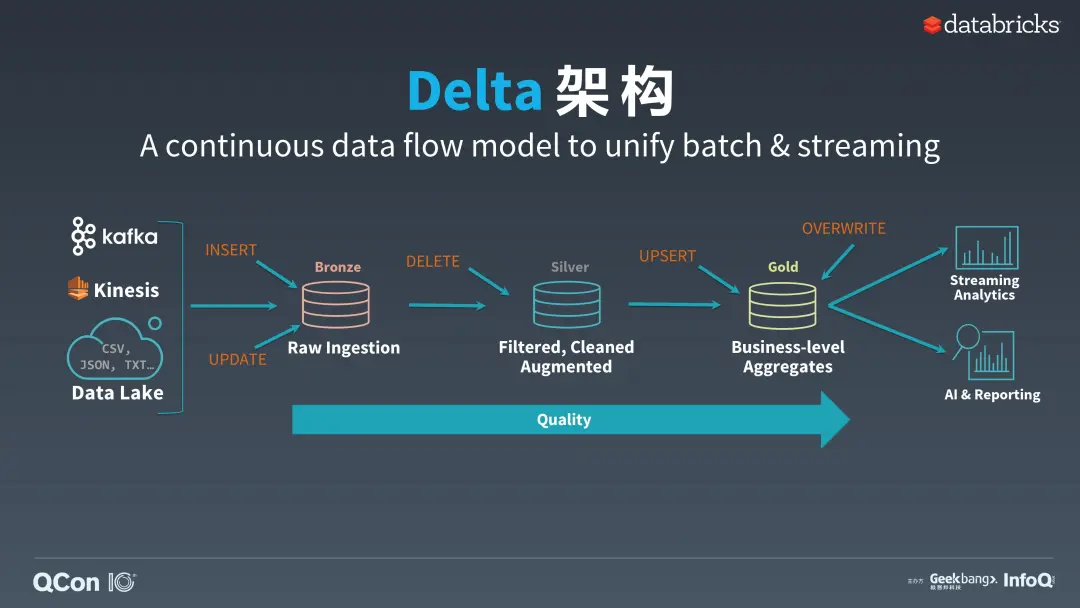
- Raw Ingestion
- Dumping ground for raw data
- Often with long retention (years)
- Avoid error-prone【容易出错】 parsing
- Filtered, Cleaned, Augmented【增强型】{fusion\delete}
- Intermediate data with some cleanup applied.
- Queryable for easy debugging!
- Business-level Aggregates
- Clean data, ready for consumption.
- Read with Spark or Presto*
Streams move data through the Delta Lake
- Low-latency or manually triggered
- Eliminates management of schedules and jobs
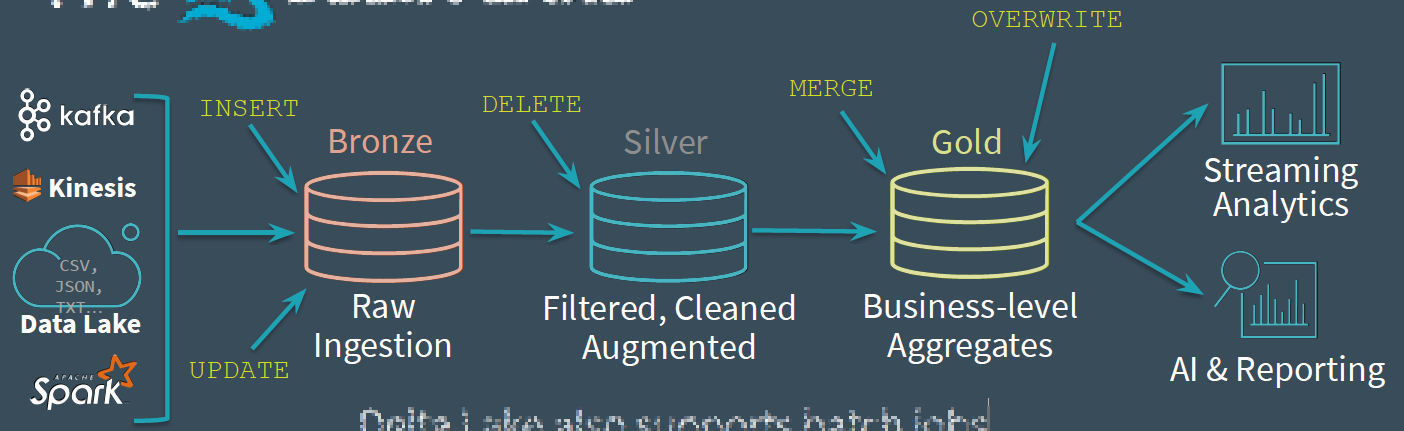
Delta Lake also supports batch jobs and standard DML
- GDPR, CCPA
- Upserts
Easy to recompute when business logic changes:
- Clear tables
- Restart streams
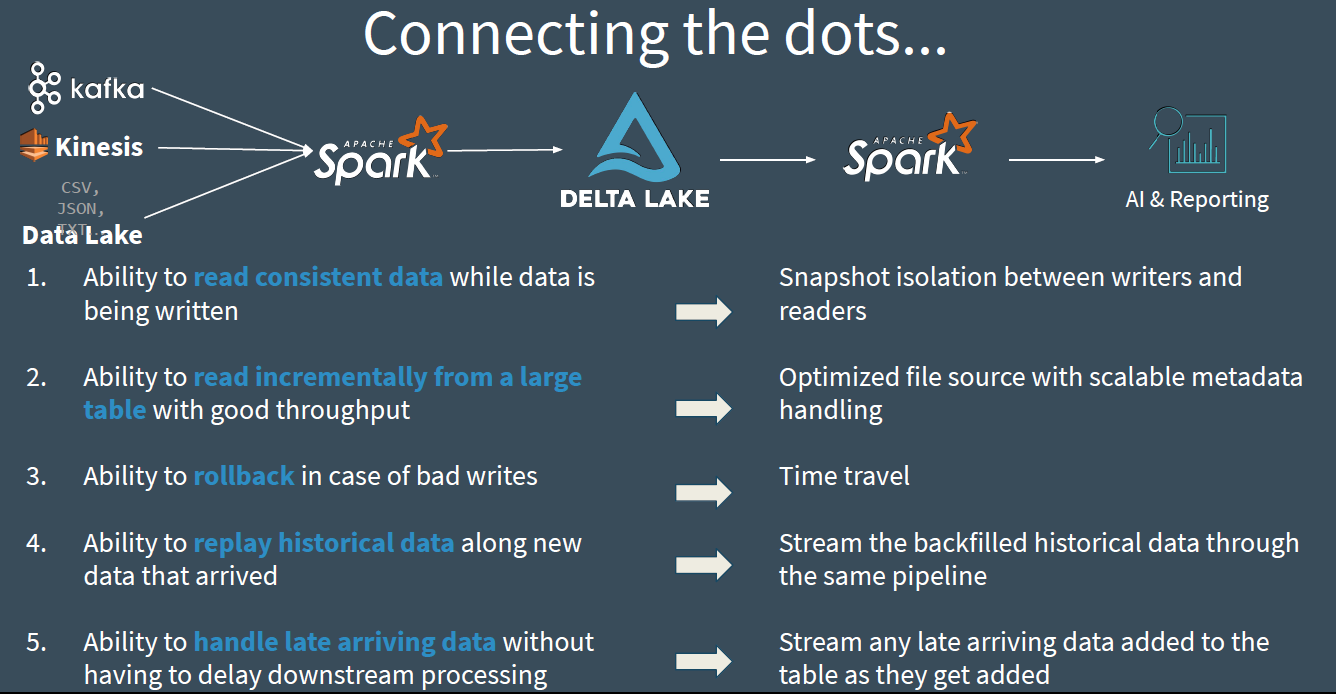
Solution
- 创建关联外部表(指定Delta Lake Location)
- Delta Lake 表实现存在
- Delta Lake 表数据
- insert
- upsert
- delete
- SparkSQL 读取第一步创建的外部表
- spark.read.table
- jdbc thrift server; select
- spark-sql命令行; select
- Databricks 对他们引以为傲的 Data Skipping 技术做了保留。
- primary key + BloomFilter
- upsert
- hidden partition
- partition prune
- column statistics
- primary key + BloomFilter
- Delta 的一大优点就是与 Spark 的整合能力(虽然目前仍不是很完善,但 Spark-3.0 之后会好很多),尤其是其流批一体的设计,配合 multi-hop 的 data pipeline,可以支持分析、Machine learning、CDC 等多种场景。使用灵活、场景支持完善是它相比 Hudi 和 Iceberg 的最大优点。
另外,Delta 号称是 Lambda 架构、Kappa 架构的改进版,无需关心流批,无需关心架构。这一点上 Hudi 和 Iceberg 是力所不及的。
Compaction的核心点是,在做compaction的过程不能影响读写。
- upsert在发生upsert的时候会动态调整控制文件的数目,所以他相当于自动具备了自己的compaction机制。而只有append操作的表,他的文件是一个一直增长的过程,所以需要我们手动进行compaction操作。
- org.apache.spark.sql.delta.commands.CompactTableInDelta
https://github.com/allwefantasy/delta-plus.git
Delta compaction过程读取某个版本之前的数据
- 将涉及到标记删除的文件真实物理删除
- 将标记为add的文件按分区(如果有分区)进行合并操作产生新的文件,然后标记删除这些文件。物理删除这些文件。
- 获取事务并且尝试提交。
In Action
- streaming 写入
- 测试atomic
- batch 写入
- 测试atomic
- org.apache.spark.sql.delta.storage.LogStore#write
- org.apache.spark.sql.delta.OptimisticTransactionImpl#checkAndRetry
- 测试atomic
- 分区测试
- writer.partitionBy(col)
- 创建关联外部表(指定Delta Lake Location)
- spark sql table读取
- vacuum
- compact
Get Started with Delta using Spark APIs
- Add Spark Package
- pyspark —packages io.delta:delta-core_2.11:0.1.0
- bin/spark-shell —packages io.delta:delta-core_2.11:0.1.0
Maven
<dependency><groupId>io.delta</groupId><artifactId>delta-core_2.11</artifactId><version>0.1.0</version></dependency>
Instead of parquet… | … simply say delta
dataframe.write.format("parquet").save("/data")dataframe.write.format("delta").save("/data")
val table = DeltaTable.convertToDelta(spark, s"parquet.`${path}`")
Hudi
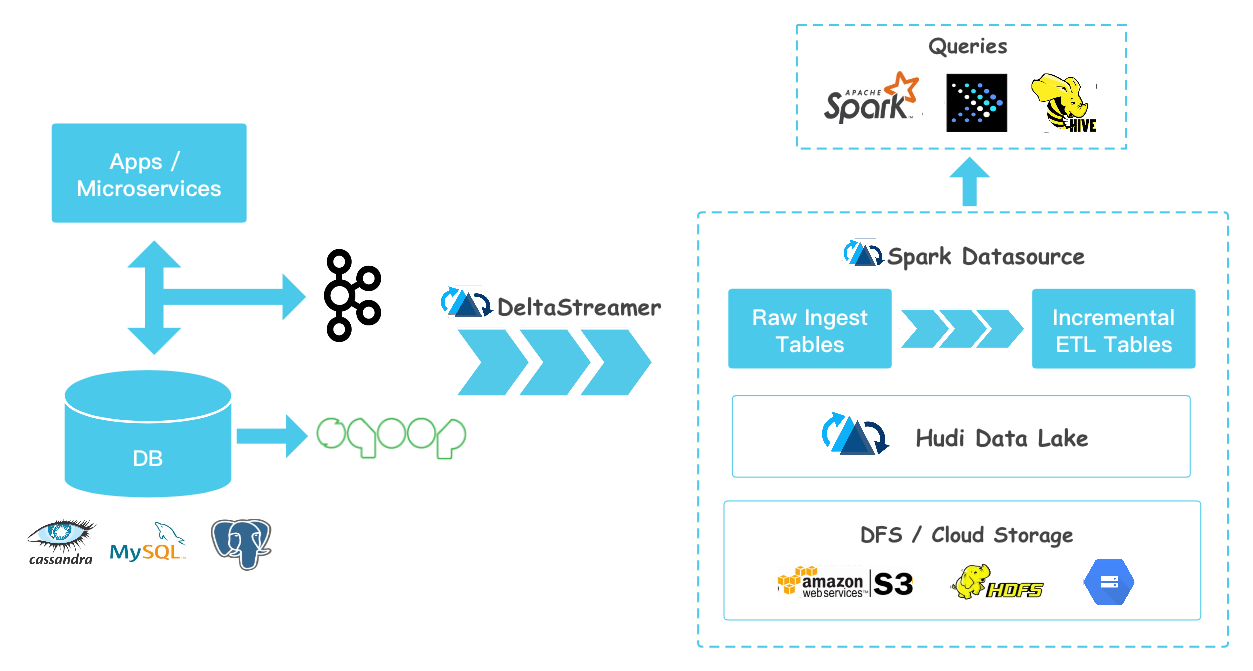
Summary: Hudi brings stream processing to big data, providing fresh data while being an order of magnitude efficient over traditional batch processing.
Hudi (pronounced “Hoodie”) ingests & manages storage of large analytical datasets over DFS (HDFS or cloud stores) and provides three logical views for query access.
- Read Optimized View - Provides excellent query performance on pure columnar storage, much like plain Parquet tables.
- Incremental View - Provides a change stream out of the dataset to feed downstream jobs/ETLs.
- Near-Real time Table - Provides queries on real-time data, using a combination of columnar & row based storage (e.g Parquet + Avro)
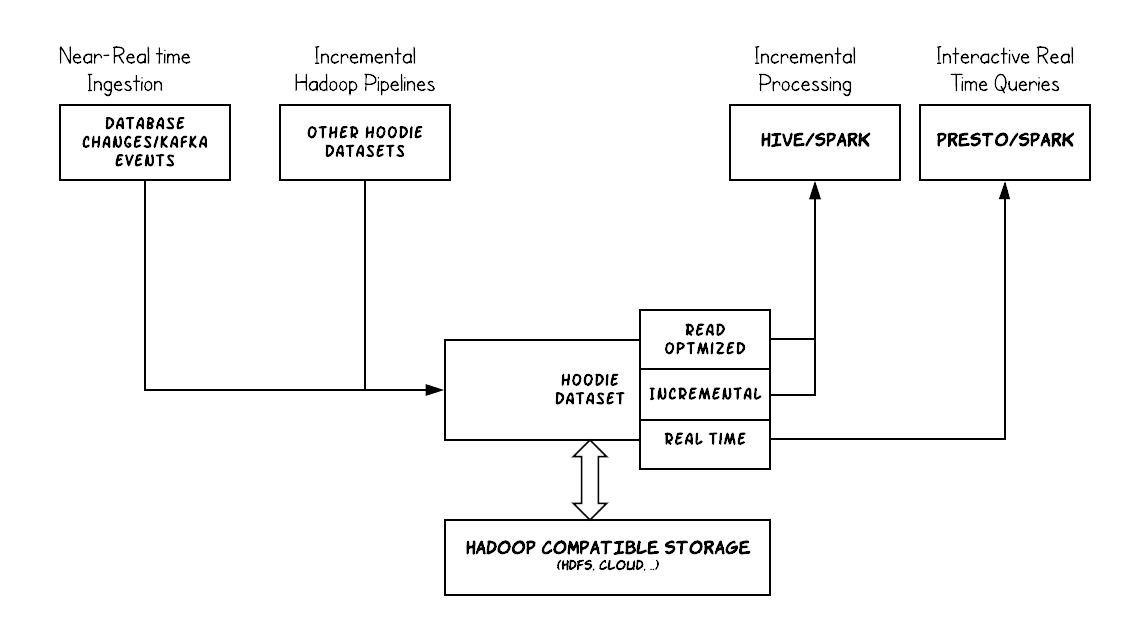
- Hadoop Upserts Deletes and Incrementals
- 其典型用法是将上游数据通过 Kafka 或者 Sqoop,经由 DeltaStreamer 写入 Hudi。DeltaStreamer 是一个常驻服务,不断地从上游拉取数据,并写入 hudi。写入是分批次的,并且可以设置批次之间的调度间隔。默认间隔为 0,类似于 Spark Streaming 的 As-soon-as-possible 策略。随着数据不断写入,会有小文件产生。对于这些小文件,DeltaStreamer 可以自动地触发小文件合并的任务。
- 在查询方面,Hudi 支持 Hive、Spark、Presto。
- 在性能方面,Hudi 设计了 HoodieKey,一个类似于主键的东西。HoodieKey有 Min/Max 统计,BloomFilter,用于快速定位 Record 所在的文件。
- 在具体做 Upserts 时,如果 HoodieKey 不存在于 BloomFilter,则执行插入,
- 否则,确认 HoodieKey 是否真正存在,如果真正存在,则执行 update。
- 这种基于 HoodieKey + BloomFilter 的 upserts 方法是比较高效的,否则,需要做全表的 Join 才能实现 upserts。
- 对于查询性能,一般需求是根据查询谓词生成过滤条件下推至 datasource。Hudi 这方面没怎么做工作,其性能完全基于引擎自带的谓词下推和 partition prune 功能。
- Hudi 的另一大特色是支持 Copy On Write 和 Merge On Read。
- 前者在写入时做数据的 merge,写入性能略差,但是读性能更高一些。
- 后者读的时候做 merge,读性能查,但是写入数据会比较及时,因而后者可以提供近实时的数据分析能力。
- 最后,Hudi 提供了一个名为 run_sync_tool 的脚本同步数据的 schema 到 Hive 表。Hudi 还提供了一个命令行工具用于管理 Hudi 表。
Write
Write Operations
Before that, it may be helpful to understand the 3 different write operations provided by Hudi datasource or the delta streamer tool and how best to leverage them. These operations can be chosen/changed across each commit/deltacommit issued against the table.
- UPSERT : This is the default operation where the input records are first tagged as inserts or updates by looking up the index and the records are ultimately written after heuristics【启发式】 are run to determine how best to pack them on storage to optimize for things like file sizing. This operation is recommended for use-cases like database change capture where the input almost certainly contains updates.
- INSERT : This operation is very similar to upsert in terms of heuristics/file sizing but completely skips the index lookup step. Thus, it can be a lot faster than upserts for use-cases like log de-duplication (in conjunction with options to filter duplicates mentioned below). This is also suitable for use-cases where the table can tolerate duplicates, but just need the transactional writes/incremental pull/storage management capabilities of Hudi.
- BULK_INSERT : Both upsert and insert operations keep input records in memory to speed up storage heuristics computations faster (among other things) and thus can be cumbersome【麻烦的】 for initial loading/bootstrapping a Hudi table at first. Bulk insert provides the same semantics as insert, while implementing a sort-based data writing algorithm, which can scale very well for several hundred TBs of initial load. However, this just does a best-effort job at sizing files vs guaranteeing file sizes like inserts/upserts do.
DeltaStreamer
The HoodieDeltaStreamer utility (part of hudi-utilities-bundle) provides the way to ingest from different sources such as DFS or Kafka, with the following capabilities.
- Exactly once ingestion of new events from Kafka, incremental imports from Sqoop or output of
HiveIncrementalPulleror files under a DFS folder - Support json, avro or a custom record types for the incoming data
- Manage checkpoints, rollback & recovery
- Leverage Avro schemas from DFS or Confluent schema registry.
- Support for plugging in transformations
Datasource Writer
The hudi-spark module offers the DataSource API to write (and also read) any data frame into a Hudi table. Following is how we can upsert a dataframe, while specifying the field names that need to be used for recordKey => _row_key, partitionPath => partition and precombineKey => timestamp
Syncing to Hive
Both tools above support syncing of the table’s latest schema to Hive metastore, such that queries can pick up new columns and partitions. In case, its preferable to run this from commandline or in an independent jvm, Hudi provides a HiveSyncTool, which can be invoked as below, once you have built the hudi-hive module. Following is how we sync the above Datasource Writer written table to Hive metastore.
Deletes
Hudi supports implementing two types of deletes on data stored in Hudi tables, by enabling the user to specify a different record payload implementation. For more info refer to Delete support in Hudi.
- Soft Deletes : With soft deletes, user wants to retain the key but just null out the values for all other fields. This can be simply achieved by ensuring the appropriate fields are nullable in the table schema and simply upserting the table after setting these fields to null.
- Hard Deletes : A stronger form of delete is to physically remove any trace of the record from the table. This can be achieved by issuing an upsert with a custom payload implementation via either DataSource or DeltaStreamer which always returns Optional.Empty as the combined value. Hudi ships with a built-in
org.apache.hudi.EmptyHoodieRecordPayloadclass that does exactly this.
Read
Conceptually, Hudi stores data physically once on DFS, while providing 3 different ways of querying, as explained before. Once the table is synced to the Hive metastore, it provides external Hive tables backed by Hudi’s custom inputformats. Once the proper hudi bundle has been installed, the table can be queried by popular query engines like Hive, Spark SQL, Spark Datasource API and Presto.
Specifically, following Hive tables are registered based off table name and table type configs passed during write.
If table name = hudi_trips and table type = COPY_ON_WRITE, then we get:
hudi_tripssupports snapshot query and incremental query on the table backed byHoodieParquetInputFormat, exposing purely columnar data.
If table name = hudi_trips and table type = MERGE_ON_READ, then we get:
hudi_trips_rtsupports snapshot query and incremental query (providing near-real time data) on the table backed byHoodieParquetRealtimeInputFormat, exposing merged view of base and log data.hudi_trips_rosupports read optimized query on the table backed byHoodieParquetInputFormat, exposing purely columnar data stored in base files.
As discussed in the concepts section, the one key capability needed for incrementally processing, is obtaining a change stream/log from a table. Hudi tables can be queried incrementally, which means you can get ALL and ONLY the updated & new rows since a specified instant time. This, together with upserts, is particularly useful for building data pipelines where 1 or more source Hudi tables are incrementally queried (streams/facts), joined with other tables (tables/dimensions), to write out deltas to a target Hudi table. Incremental queries are realized by querying one of the tables above, with special configurations that indicates to query planning that only incremental data needs to be fetched out of the table.
Compare with Kudu
Apache Kudu is a storage system that has similar goals as Hudi, which is to bring real-time analytics on petabytes of data via first class support for upserts. A key differentiator is that Kudu also attempts to serve as a datastore for OLTP workloads, something that Hudi does not aspire to be. Consequently, Kudu does not support incremental pulling (as of early 2017), something Hudi does to enable incremental processing use cases.
Kudu diverges from a distributed file system abstraction and HDFS altogether, with its own set of storage servers talking to each other via RAFT. Hudi, on the other hand, is designed to work with an underlying Hadoop compatible filesystem (HDFS,S3 or Ceph) and does not have its own fleet of storage servers, instead relying on Apache Spark to do the heavy-lifting. Thus, Hudi can be scaled easily, just like other Spark jobs, while Kudu would require hardware & operational support, typical to datastores like HBase or Vertica. We have not at this point, done any head to head benchmarks against Kudu (given RTTable is WIP). But, if we were to go with results shared by CERN , we expect Hudi to positioned at something that ingests parquet with superior performance.
In Action
总结
- 近实时摄取
- 更有效的方法使得摄取速度【parquet】与较频繁的更新【hbase】数据量相匹配。
- 小文件【Streaming】
- 近实时分析
- merge on read
- 简单
- 增量处理管道
- process time
- event time
- index
- DFS上数据分发
- 增量读取
Iceberg
Overview
Apache Iceberg is an open table format for huge analytic datasets. Iceberg adds tables to Presto and Spark that use a high-performance format that works just like a SQL table.
User experience
Iceberg avoids unpleasant surprises. Schema evolution works and won’t inadvertently【不经意的】 un-delete data. Users don’t need to know about partitioning to get fast queries.
- Schema evolution supports add, drop, update, or rename, and has no side-effects
- Hidden partitioning prevents user mistakes that cause silently incorrect results or extremely slow queries
- Partition layout evolution can update the layout of a table as data volume or query patterns change
- Time travel enables reproducible【可复制的】 queries that use exactly the same table snapshot, or lets users easily examine changes
Version rollback allows users to quickly correct problems by resetting tables to a good state
Reliability and performance
Iceberg was built for huge tables. Iceberg is used in production where a single table can contain tens of petabytes of data and even these huge tables can be read without a distributed SQL engine.
Scan planning is fast – a distributed SQL engine isn’t needed to read a table or find files
- Advanced filtering – data files are pruned with partition and column-level stats, using table metadata
Iceberg was designed to solve correctness problems in eventually-consistent cloud object stores.
- Works with any cloud store and reduces NN congestion when in HDFS, by avoiding listing and renames
- Serializable isolation – table changes are atomic and readers never see partial or uncommitted changes
- Multiple concurrent writers use optimistic concurrency and will retry to ensure that compatible updates succeed, even when writes conflict
Roadmap
Design
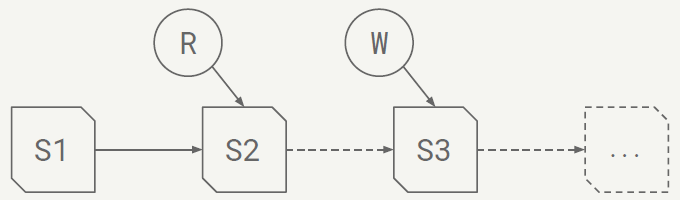
- Key idea: track all files in a table over time
- A snapshot is a complete list of files in a table
- Each write produces and commits a new snapshot

Snapshot Design Benefits
- Snapshot isolation without locking
- Readers use a current snapshot
- Writers produce new snapshots in isolation, then commit
- Any change to the file list is an atomic operation
- Append data across partitions
- Merge or rewrite files
Iceberg Metadata
- Implements snapshot-based tracking
- Adds table schema, partition layout, string properties
- Tracks old snapshots for eventual garbage collection

- Each metadata file is immutable
- Metadata always moves forward, history is linear
- The current snapshot (pointer) can be rolled back
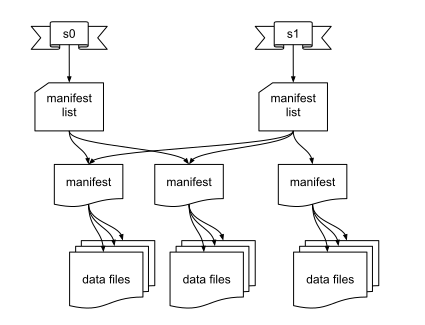
Manifest File
- Snapshots are split across one or more manifest files
- A manifest stores files across many partitions
- A partition data tuple is stored for each data file
- Reused to avoid high write volume
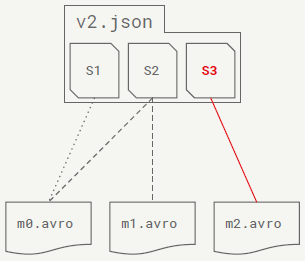
Manifest File Contents
- Basic data file info:
- File location and format
- Iceberg tracking data
- Values to filter files for a scan:
- Partition data values
- Per-column lower and upper bounds
- Metrics for cost-based optimization:
- File-level: row count, size
- Column-level: value count, null count, size
Commit
- To commit, a writer must:
- Note the current metadata version – the base version
- Create new metadata and manifest files
- Atomically swap the base version for the new version
- This atomic swap ensures a linear history
- Atomic swap is implemented by:
- A custom metastore implementation
- Atomic rename for HDFS or local tables
Commits: Conflict Resolution
- Writers optimistically write new versions:
- Assume that no other writer is operating
- On conflict, retry based on the latest metadata
- To support retry, operations are structured as:
- Assumptions【假设条件】 about the current table state
- Pending changes to the current table state
- Changes are safe if the assumptions are all true
Design Benefits
- Reads and writes are isolated and all changes are atomic
- No expensive or eventually-consistent FS operations:
- No directory or prefix listing
- No rename: data files written in place
- Faster scan planning
- O(1) manifest reads, not O(n) partition list calls
- Without listing, partition granularity can be higher
- Upper and lower bounds used to eliminate files
Other Improvements
- Full schema evolution: add, drop, rename, reorder columns
- Reliable support for types
- date, time, timestamp, and decimal
- struct, list, map, and mixed nesting
- Hidden partitioning
- Partition filters derived from data filters
- Supports evolving table partitioning
- Mixed file format support, reliable CBO metrics, etc.
总结
- 没有主键,做 update/delete/merge 等操作就要通过 Join 来实现,而 Join 需要有一个类似 SQL 的执行引擎。
- Hidden partition 意思是说,对于用户输入的数据,用户可以选取其中某些列做适当的变换(Transform)形成一个新的列作为 partition 列。这个 partition 列仅仅为了将数据进行分区,并不直接体现在表的 schema 中。
- 例如,用户有 timestamp 列,那么可以通过 hour(timestamp) 生成一个 timestamp_hour 的新分区列。timestamp_hour 对用户不可见,仅仅用于组织数据。
- Partition 列有 partition 列的统计,如该 partition 包含的数据范围。当用户查询时,可以根据 partition 的统计信息做 partition prune。
- Iceberg 也对普通的 column 列做了信息收集。这些统计信息非常全,包括列的 size,列的 value count,null value count,以及列的最大最小值等等。这些信息都可以用来在查询时过滤数据。
- Iceberg 提供了建表的 API,用户可以使用该 API 指定表明、schema、partition 信息等,然后在 Hive catalog 中完成建表。
- 构建在ACID能力上的行级update/delete语义。Hudi提供了基于copy on write和merge on read的行级更新能力,而Delta Lake提供了copy on write的行级更新能力。但是现在在Iceberg社区仍然缺乏一个统一的语义来实现这个功能。其中copy on write相对简单,利用Iceberg现有的API可以构建出这样的能力,这在我们内部也实现了。但是基于merge on read的能力需要涉及到格式的定义等一些列工作,这也是现在社区推动中的工作。
- 更多上游引擎的适配。上文也提到Iceberg现在对于Spark的支持度比较完善,同时也支持Presto,Pig。但是对于其他主流引擎如Flink,Hive的支持仍然缺失,这也限制了Iceberg作为一个通用表格式的推广使用,这一块能力需要亟待加强。
- 统一的索引层来加速数据的检索。Iceberg现在有丰富的文件级别的metrics来进行更好的条件过滤,但是这依赖于底层存储格式所提供的能力,同时由于涉及到snapshot->manifest->datafile的多级查询,在效率上有一定的损耗,一层统一的索引层来加速数据的检索非常必要。
In Action
Hadoop Table
- table_location
- data
- metadata
- snap.avro
- matedata.json
Hive Table
- hive metadata
- hdfs
- data
- metadata
Performance
Historical Atlas data:
- Time-series metrics from Netflix runtime systems
- 1 month: 2.7 million files in 2,688 partitions
- Problem: cannot process more than a few days of data
Historical Queries
- Hive table – with Parquet filters:
- 400k+ splits, not combined
- EXPLAIN query: 9.6 min (planning wall time)
- Iceberg table – partition data filtering:
- 15,218 splits, combined
- 13 min (wall time) / 61.5 hr (task time) / 10 sec (planning)
- Iceberg table – partition and min/max filtering:
- 412 splits
- 42 sec (wall time) / 22 min (task time) / 25 sec (planning)
- Hive table – with Parquet filters:
What is a Table Format?
- How to track what files store the table’s data.
- Files in the table are in Avro, Parquet, ORC, etc.
- Often overlooked【被忽视】, but determines:
- What guarantees are possible (like correctness)
- How hard it is to write fast queries
- How the table can change over time
- Job performance
- Should be specified: must be documented and portable【可移植的】
- Should support expected database table behavior:
- Atomic changes that commit all rows or nothing
- Schema evolution without unintended consequences
- Efficient access like predicate or projection pushdown
- Bonus features:
- Hidden layout: no need to know the table structure
- Layout evolution: change the table structure over time
功能需求测试
并发写表
两个客户端并发
Delta Lake
- 并发异常【乐观锁,表数据正常】
org.apache.spark.sql.delta.ConcurrentAppendException
- 并发异常【乐观锁,表数据正常】
Iceberg
append
- warn
20/05/12 11:52:31 WARN Tasks: Retrying task after failure: Version 2 already exists: file:/H:/tmp/iceberg/hadoop/demo11/metadata/v2.metadata.jsonorg.apache.iceberg.exceptions.CommitFailedException: Version 2 already exists: file:/H:/tmp/iceberg/hadoop/demo11/metadata/v2.metadata.json
- warn
overwrite
- 通过
- HUDI
- 并发异常
78407 [main] INFO org.apache.hudi.common.table.timeline.HoodieActiveTimeline - Checking for file exists ?file:/H:/tmp/hudi/hudi_trips_cow0512/.hoodie/20200512113934.commit.requestedException in thread "main" org.apache.hudi.exception.HoodieUpsertException: Failed to upsert for commit time 20200512113934
- 并发异常
JDBC Thrift Query
Delta Lake
- 正常
- 建立外部表
CREATE TABLE dev_lk.events_123 USING DELTA LOCATION '/deltalake/db/table';-- location对应实际delta lake表的存储位置
Iceberg
- 2.x 不支持
- 3.x 支持
- HUDI
- 支持(通过hive-sync读取hudi meta在hive中建立外部表进行实现)
create table hudi_demo(`driver` STRING, `ts` DOUBLE, `uuid` STRING, `partitionpath` STRING) using hudi location "/user/dev_lk/warehouse/hudi/hudi_trips_cow";
- 支持(通过hive-sync读取hudi meta在hive中建立外部表进行实现)
批流统一
- Delta Lake
- Spark Structure Streaming
- Spark DataSource
- Iceberg
- HUDI
- DeltaStreamer
- Datasource Writer
SourceCode Analysis
功能抽象封装
- Iceberg
- org.apache.iceberg.Table
- org.apache.iceberg.TableMetadata
- org.apache.iceberg.Snapshot
- org.apache.iceberg.ManifestFile
- org.apache.iceberg.DataFile
- Delta Lake
- io.delta.tables.DeltaTable
- HUDI
- org.apache.hudi.table.HoodieTable
- org.apache.hudi.table.HoodieMergeOnReadTable
- insert
- new file
- update
- append changes to a rolling log file, compact merges the log file
- insert
- org.apache.hudi.table.HoodieCopyOnWriteTable
- insert
- new file
- update
- new version of the file
- insert
- org.apache.hudi.client.HoodieWriteClient
val table = DeltaTable.convertToDelta(spark, s"parquet.`${path}`")
Reference
Key
001Hudi Unifying storage and serving for batch and near-real-time analytics Presentation.pptx001Apache Hudi (Incubating) The Past, Present and Future Of Efficient Data Lake Architectures.pptx001_Delta Lake让你从复杂的Lambda架构中解放出来.pdf001_Delta Lake Making Cloud Data Lakes Transactional and Scalable.pdf
001Introducing Iceberg Tables designed for object stores Presentation.pdf
Other
- Iceberg A modern table format for big data
- Apache iceberg:Netflix 数据仓库的基石
Iceberg Table Spec【设计关键抽象】
- 利用Delta Lake使Spark SQL支持跨表CRUD操作
- Delta Lake 平台化实践
- Data Lake 三剑客——Delta、Hudi、Iceberg 对比分析
- 深度对比Delta、Iceberg和Hudi三大开源数据湖方案
- 数据湖(Data Lake) 总结
- Iceberg 在基于 Flink 的流式数据入库场景中的应用
- http://www.whitewood.me/2020/03/30/Flink-流批一体的实践与探索/
- Flink 新场景:OLAP 引擎性能优化及应用案例
- Delta Lake如何自己实现更新操作加速(布隆过滤器)
- 解决小文件问题
- Spark 小文件合并优化实践
- Delta lake Concurrency Control
- Optimize performance with file management【data skipping【bin-package、z-ordering】】
- Apache Spark Delta Lake 事务日志实现源码分析
- 阿里资深技术专家胡月军:大数据十年,我看到的技术变化和趋势
- Querying Hudi Tables
- HUDI Concept
- Apache Hudi 设计与架构最强解读
- Apache Hudi典型应用场景知多少?
附录
| Trade-off | CopyOnWrite | MergeOnRead |
|---|---|---|
| Data Latency | Higher | Lower |
| Update cost (I/O) | Higher (rewrite entire parquet) | Lower (append to delta log) |
| Parquet File Size | Smaller (high update(I/0) cost) | Larger (low update cost) |
| Write Amplification【放大】 | Higher | Lower (depending on compaction strategy) |
Hive MetaStore
- download
- change config; ${HIVE_META_STORE_HOME}/conf/metastore-site.xml
- init schema
- ${HIVE_META_STORE_HOME}/bin/schematool -initSchema -dbType mysql
- start server
- ${HIVE_META_STORE_HOME}/bin/start-metastore
Hive Design
Hive Tables
- Design Key idea: organize data in a directory tree
- Partition columns become a directory level with values
- Filter by directories as columns
Hive Metastore
- HMS keeps metadata in SQL database
- Tracks information about partitions
- Tracks schema information
- Tracks table statistics
- Allows filtering by partition values
- Filters only pushed to DB for string types
- Uses external SQL database
- Metastore is often the bottleneck for query planning
- Only file system tracks the files in each partition…
- No per-file statistics
Hive ACID layout
- Provides snapshot isolation and atomic updates
- Transaction state is stored in the metastore
- Uses the same partition/directory layout
- Creates new directory structure inside partitions
Design Problems
- Table state is stored in two places
- Partitions in the Hive Metastore
- Files in a file system
- Bucketing is defined by Hive’s (Java) hash implementation.
- Non-ACID layout’s only atomic operation is add partition
- Requires atomic move of objects in file system
- Still requires directory listing to plan jobs
- O(n) listing calls, n = # matching partitions
- Eventual consistency breaks correctness
Less Obvious Problems
- Partition values are stored as strings
- Requires character escaping【转义】
- null stored as HIVE_DEFAULT_PARTITION
- HMS table statistics become stale
- Statistics have to be regenerated【再生的】 manually
- A lot of undocumented layout variants【变体】
- Bucket definition tied to Java and Hive
Other Annoyances【烦恼】
- Users must know and use a table’s physical layout
- ts > X ⇒ full table scan!
- Did you mean this?
- ts > X and (d > day(X) or (d = day(X) and hr >= hour(X))
- Schema evolution rules are dependent on file format
- CSV – by position; Avro & ORC – by name
- Unreliable: type support varies across formats
- Which formats support decimal?
- Does CSV support maps with struct keys?

若有收获,就点个赞吧
0 人点赞
