keyword: create table without location
- 认识 Delta Lake
- Parquet文件 + Meta 文件 + 一组操作的API = Delta Lake.
- ???和Hive如何整合
- 应用层
- LinkIs
- 计算层
- Spark
- 存储层
- Delta Lake
- Hive Data WareHouse
- 小文件
- ACID
- 并发读写
- 有限更新支持
- 海量metadata(partition)
- Delta Presto Integration & Manifests 机制
- 使用 GENERATE 命令会在/path/to/deltaTable/_symlink_format_manifest/ 目录下 生成一个 manifest 文件,其中包含了所有存活的文件路径。
- 定义 Hive Metastore 外部表读取相应文件
- Presto and Athena to Delta Lake integration
- Delta Lake 平台化实践(离线篇)
- 使用 spark sql extension 以插件化的方式扩展 sql parser ,增加 DML 语法的支持。在 spark 推出 sql extension 功能前,也可以用通过 aspectj 通过拦截 sql 的方式实现增加自定义语法的功能。
- Frequently asked questions (FAQ)
- Delta Lake Documentation
- EMR-Delta简介
背景假设
delta lake 写入空的dataframe(schema正确)
val df = spark.createDataFrame(spark.sparkContext.emptyRDD[Row].setName("empty"), StructType(Array(new StructField("id", IntegerType))))df.coalesce(1).write.format("delta").save("/deltalake/db/table")
spark-sql创建delta lake的表
CREATE TABLE dev_lk.events_123 USING DELTA LOCATION '/deltalake/db/table';
- show tables 正常显示
- select * from dev_lk.event_123 limit 3; 实际查询delta对应path(‘/deltalake/db/table’)的数据;实际数据仓库表存储路劲(/user/hive/datawarehouse/dev_lk.db/events_123)不存在
当前delta lake不允许创建没有数据的表;(执行如下SQL会报错)
CREATE TABLE events (date DATE,eventId STRING,eventType STRING,data STRING)USING DELTA
报错信息如下:
20/04/13 11:38:00 ERROR SparkSQLDriver: Failed in [CREATE TABLE dev_lk.events124 (date DATE, eventId STRING, eventType STRING, data STRING) USING DELTA]java.lang.IllegalArgumentException: 'path' is not specifiedat org.apache.spark.sql.delta.DeltaErrors$.pathNotSpecifiedException(DeltaErrors.scala:249)at org.apache.spark.sql.delta.sources.DeltaDataSource$$anonfun$9.apply(DeltaDataSource.scala:142)at org.apache.spark.sql.delta.sources.DeltaDataSource$$anonfun$9.apply(DeltaDataSource.scala:142)
对应的源码信息如下:
override def createRelation(sqlContext: SQLContext,parameters: Map[String, String]): BaseRelation = {val maybePath = parameters.getOrElse("path", {throw DeltaErrors.pathNotSpecifiedException})// Log any invalid options that are being passed inDeltaOptions.verifyOptions(CaseInsensitiveMap(parameters))
假设方案
- 实现建表语句获取schema并生成delta lake的org.apache.spark.sql.delta.actions.SingleAction对象,将该对象的json保存到hdfs上面 /deltalake/db/table_empty/_delta_log/00000000000000000000.json
在spark-sql中执行建表语句:
CREATE TABLE dev_lk.empty_123 USING DELTA LOCATION '/deltalake/db/table_empty';-- 执行如下SQL进行验证select * from dev_lk.empty_123;desc table dev_lk.empty_123;use dev_lk;show tables;
分析求证
branch: delta lake元数据分析
/deltalake/db/table_empty/_delta_log/00000000000000000000.json 内容如下:
{"commitInfo":{"timestamp":1586747587139,"operation":"WRITE","operationParameters":{"mode":"ErrorIfExists","partitionBy":"[]"},"isBlindAppend":true}}{"protocol":{"minReaderVersion":1,"minWriterVersion":2}}{"metaData":{"id":"55e8108f-dbd1-43ae-92a3-88415df4fd65","format":{"provider":"parquet","options":{}},"schemaString":"{\"type\":\"struct\",\"fields\":[{\"name\":\"id\",\"type\":\"long\",\"nullable\":true,\"metadata\":{}}]}","partitionColumns":[],"configuration":{},"createdTime":1586747586641}}{"add":{"path":"part-00000-3c08ffeb-d0a3-4e54-bd26-2877d3f5b859-c000.snappy.parquet","partitionValues":{},"size":429,"modificationTime":1586747587107,"dataChange":true}}...
分析:
- line1, commitInfo【每次action均会有】
- line2, protocol(版本兼容信息)
- line3, 元数据信息(表结构)【关键信息】
- line4, 主数据文件信息
执行如下代码,
val newData = spark.range(0, 20).toDFval deltaTable = DeltaTable.forPath("/deltalake/db/table_empty")deltaTable.as("oldData").merge(newData.as("newData"), "oldData.id = newData.id").whenMatched.update(Map("id" -> col("newData.id"))).whenNotMatched.insert(Map("id" -> col("newData.id"))).execute()
/deltalake/db/table_empty/_delta_log/00000000000000000001.json 内容如下:
{"commitInfo":{"timestamp":1586764332473,"operation":"MERGE","operationParameters":{"predicate":"(oldData.`id` = newData.`id`)"},"readVersion":0,"isBlindAppend":false}}{"add":{"path":"part-00000-3a499fcf-3bff-4c82-9b6a-76299dfb55f3-c000.snappy.parquet","partitionValues":{},"size":262,"modificationTime":1586764332113,"dataChange":true}}...
分析:
- line1, commitInfo
- line2+, 主数据文件信息
备注:
- sparksql对应表的数据查询已得到更新
json对应class: org.apache.spark.sql.delta.actions.SingleAction
object Action {/** The maximum version of the protocol that this version of Delta understands. */val readerVersion = 1val writerVersion = 2val protocolVersion: Protocol = Protocol(readerVersion, writerVersion)def fromJson(json: String): Action = {JsonUtils.mapper.readValue[SingleAction](json).unwrap}lazy val logSchema = ExpressionEncoder[SingleAction].schema}/*** Represents a single change to the state of a Delta table. An order sequence* of actions can be replayed using [[InMemoryLogReplay]] to derive the state* of the table at a given point in time.*/sealed trait Action {def wrap: SingleActiondef json: String = JsonUtils.toJson(wrap)}/*** Used to block older clients from reading or writing the log when backwards* incompatible changes are made to the protocol. Readers and writers are* responsible for checking that they meet the minimum versions before performing* any other operations.** Since this action allows us to explicitly block older clients in the case of a* breaking change to the protocol, clients should be tolerant of messages and* fields that they do not understand.*/// 版本兼容信息case class Protocol(minReaderVersion: Int = Action.readerVersion,minWriterVersion: Int = Action.writerVersion) extends Action {override def wrap: SingleAction = SingleAction(protocol = this)@JsonIgnoredef simpleString: String = s"($minReaderVersion,$minWriterVersion)"}/*** Sets the committed version for a given application. Used to make operations* like streaming append idempotent[幂等].*/// 批处理, json未看见该部分内容case class SetTransaction(appId: String,version: Long,@JsonDeserialize(contentAs = classOf[java.lang.Long])lastUpdated: Option[Long]) extends Action {override def wrap: SingleAction = SingleAction(txn = this)}/** Actions pertaining to the addition and removal of files. */sealed trait FileAction extends Action {val path: Stringval dataChange: Boolean@JsonIgnorelazy val pathAsUri: URI = new URI(path)}/*** Adds a new file to the table. When multiple [[AddFile]] file actions* are seen with the same `path` only the metadata from the last one is* kept.*/case class AddFile(path: String,@JsonInclude(JsonInclude.Include.ALWAYS)partitionValues: Map[String, String],size: Long,modificationTime: Long,dataChange: Boolean,@JsonRawValuestats: String = null,tags: Map[String, String] = null) extends FileAction {require(path.nonEmpty)override def wrap: SingleAction = SingleAction(add = this)def remove: RemoveFile = removeWithTimestamp()def removeWithTimestamp(timestamp: Long = System.currentTimeMillis(),dataChange: Boolean = true): RemoveFile = {// scalastyle:offRemoveFile(path, Some(timestamp), dataChange)// scalastyle:on}}object AddFile {/*** Misc file-level metadata.** The convention is that clients may safely ignore any/all of these tags and this should never* have an impact on correctness.** Otherwise, the information should go as a field of the AddFile action itself and the Delta* protocol version should be bumped.*/object Tags {sealed abstract class KeyType(val name: String)/** [[ZCUBE_ID]]: identifier of the OPTIMIZE ZORDER BY job that this file was produced by */object ZCUBE_ID extends AddFile.Tags.KeyType("ZCUBE_ID")/** [[ZCUBE_ZORDER_BY]]: ZOrdering of the corresponding ZCube */object ZCUBE_ZORDER_BY extends AddFile.Tags.KeyType("ZCUBE_ZORDER_BY")}/** Convert a [[Tags.KeyType]] to a string to be used in the AddMap.tags Map[String, String]. */def tag(tagKey: Tags.KeyType): String = tagKey.name}/*** Logical removal of a given file from the reservoir. Acts as a tombstone before a file is* deleted permanently.*/// scalastyle:offcase class RemoveFile(path: String,@JsonDeserialize(contentAs = classOf[java.lang.Long])deletionTimestamp: Option[Long],dataChange: Boolean = true) extends FileAction {override def wrap: SingleAction = SingleAction(remove = this)@JsonIgnoreval delTimestamp: Long = deletionTimestamp.getOrElse(0L)}// 被metadata使用case class Format(provider: String = "parquet",options: Map[String, String] = Map.empty)/*** Updates the metadata of the table. Only the last update to the [[Metadata]]* of a table is kept. It is the responsibility of the writer to ensure that* any data already present in the table is still valid after any change.*/case class Metadata(id: String = java.util.UUID.randomUUID().toString,name: String = null,description: String = null,format: Format = Format(),schemaString: String = null, // 构建schema: StructType, DataType.fromJson(s).asInstanceOf[StructType]partitionColumns: Seq[String] = Nil, // 分区字段configuration: Map[String, String] = Map.empty,@JsonDeserialize(contentAs = classOf[java.lang.Long])createdTime: Option[Long] = Some(System.currentTimeMillis())) extends Action {// The `schema` and `partitionSchema` methods should be vals or lazy vals, NOT// defs, because parsing StructTypes from JSON is extremely expensive and has// caused perf. problems here in the past:/** Returns the schema as a [[StructType]] */@JsonIgnorelazy val schema: StructType =Option(schemaString).map { s =>DataType.fromJson(s).asInstanceOf[StructType]}.getOrElse(StructType.apply(Nil))/** Returns the partitionSchema as a [[StructType]] */@JsonIgnorelazy val partitionSchema: StructType =new StructType(partitionColumns.map(c => schema(c)).toArray)/** Columns written out to files. */@JsonIgnorelazy val dataSchema: StructType = {val partitions = partitionColumns.toSetStructType(schema.filterNot(f => partitions.contains(f.name)))}// 仅仅这个被json序列化override def wrap: SingleAction = SingleAction(metaData = this)}/*** Holds provenance information about changes to the table. This [[Action]]* is not stored in the checkpoint and has reduced compatibility guarantees.* Information stored in it is best effort (i.e. can be falsified[伪造] by the writer).*/case class CommitInfo(// The commit version should be left unfilled during commit(). When reading a delta file, we can// infer the commit version from the file name and fill in this field then.@JsonDeserialize(contentAs = classOf[java.lang.Long])version: Option[Long],timestamp: Timestamp,userId: Option[String],userName: Option[String],operation: String,@JsonSerialize(using = classOf[JsonMapSerializer])operationParameters: Map[String, String],job: Option[JobInfo],notebook: Option[NotebookInfo],clusterId: Option[String],@JsonDeserialize(contentAs = classOf[java.lang.Long])readVersion: Option[Long],isolationLevel: Option[String],/** Whether this commit has blindly appended without caring about existing files */isBlindAppend: Option[Boolean]) extends Action with CommitMarker {override def wrap: SingleAction = SingleAction(commitInfo = this)override def withTimestamp(timestamp: Long): CommitInfo = {this.copy(timestamp = new Timestamp(timestamp))}override def getTimestamp: Long = timestamp.getTime@JsonIgnoreoverride def getVersion: Long = version.get}/** A serialization helper to create a common action envelope. */case class SingleAction(txn: SetTransaction = null,add: AddFile = null,remove: RemoveFile = null,metaData: Metadata = null,protocol: Protocol = null,commitInfo: CommitInfo = null) {def unwrap: Action = {if (add != null) {add} else if (remove != null) {remove} else if (metaData != null) {metaData} else if (txn != null) {txn} else if (protocol != null) {protocol} else if (commitInfo != null) {commitInfo} else {null}}}/** A serialization helper to create a common action envelope. */case class SingleAction(txn: SetTransaction = null,add: AddFile = null,remove: RemoveFile = null,metaData: Metadata = null,protocol: Protocol = null,commitInfo: CommitInfo = null) {def unwrap: Action = {if (add != null) {add} else if (remove != null) {remove} else if (metaData != null) {metaData} else if (txn != null) {txn} else if (protocol != null) {protocol} else if (commitInfo != null) {commitInfo} else {null}}}
相关class reference:
- org.apache.spark.sql.delta.storage.LogStore#write
- org.apache.spark.sql.delta.storage.HDFSLogStore#write
- org.apache.spark.sql.delta.DeltaLog // 【核心】
- org.apache.spark.sql.delta.OptimisticTransaction
- org.apache.spark.sql.delta.Checkpoints#checkpoint
实践回归验证
创建delta lake空表
import java.sql.Timestampimport com.fasterxml.jackson.annotation.JsonInclude.Includeimport com.fasterxml.jackson.databind.{DeserializationFeature, ObjectMapper}import com.fasterxml.jackson.module.scala.DefaultScalaModuleimport com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapperimport org.apache.hadoop.conf.Configurationimport org.apache.hadoop.fs.Pathimport org.apache.spark.SparkConfimport org.apache.spark.sql.delta.actions.{CommitInfo, Metadata, SingleAction}import org.apache.spark.sql.delta.storage.HDFSLogStoreobject DeltaLogDemo {val hadoopConfHome = "H:\\tmp\\124hadoopConf"val conf = new Configuration()conf.addResource(new Path(String.format("file:///%s/hdfs-site.xml", hadoopConfHome)))conf.addResource(new Path(String.format("file:///%s/core-site.xml", hadoopConfHome)))val sparkConf = new SparkConf(false)// 本来可以直接调用org.apache.spark.sql.delta.util.JsonUtils#toJson, 当前出现init异常;val mapper = new ObjectMapper with ScalaObjectMappermapper.setSerializationInclusion(Include.NON_ABSENT)mapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false)mapper.registerModule(DefaultScalaModule)def main(args: Array[String]): Unit = {run()}def run(): Unit = {val commitInfo = CommitInfo(version = None,timestamp = new Timestamp(System.currentTimeMillis()),userId = None,userName = None,operation = "WRITE",operationParameters = Map("mode" -> "ErrorIfExists", "partitionBy" -> "[]"),job = None,notebook = None,clusterId = None,readVersion = None,isolationLevel = None,isBlindAppend = Some(true))val metadata = Metadata(schemaString = "{\"type\":\"struct\",\"fields\":[{\"name\":\"id\",\"type\":\"long\",\"nullable\":true,\"metadata\":{}}]}")val commitAction = SingleAction(commitInfo = commitInfo)val metadataAction = SingleAction(metaData = metadata)val actionIterator = Iterable(commitAction, metadataAction).iterator.map(mapper.writeValueAsString(_))val logStore = new HDFSLogStore(sparkConf, conf)val path = new Path("/tmp/delta-table/by_code/_delta_log/00000000000000000000.json")logStore.write(path, actionIterator, true)}}
从delta lake 表创建数据仓库表
CREATE TABLE dev_lk.by_code USING DELTA LOCATION '/tmp/delta-table/by_code';
desc table dev_lk.by_code;
select * from dev_lk.by_code limit 3;
更新插入数据
println("Upsert new data")
val newData = spark.range(0, 200).toDF
val deltaTable = DeltaTable.forPath("/tmp/delta-table/by_code")
deltaTable.as("oldData").merge(newData.as("newData"), "oldData.id = newData.id")
.whenMatched.update(Map("id" -> col("newData.id")))
.whenNotMatched.insert(Map("id" -> col("newData.id"))).execute()
// 执行SQL查询数据: select * from dev_lk.by_code limit 3;
Next Step TODO
- 通过sparksql extension 或 DeltaDataSource 实现sparksql创建empty 数据仓库delta lake表
sparksql create delta lake
org.apache.spark.sql.execution.command.CreateDataSourceTableCommand#run
/** * A command used to create a data source table. * * Note: This is different from [[CreateTableCommand]]. Please check the syntax for difference. * This is not intended for temporary tables. * * The syntax of using this command in SQL is: * {{{ * CREATE TABLE [IF NOT EXISTS] [db_name.]table_name * [(col1 data_type [COMMENT col_comment], ...)] * USING format OPTIONS ([option1_name "option1_value", option2_name "option2_value", ...]) * }}} */ case class CreateDataSourceTableCommand(table: CatalogTable, ignoreIfExists: Boolean) extends RunnableCommand { override def run(sparkSession: SparkSession): Seq[Row] = { assert(table.tableType != CatalogTableType.VIEW) assert(table.provider.isDefined) val sessionState = sparkSession.sessionState if (sessionState.catalog.tableExists(table.identifier)) { if (ignoreIfExists) { return Seq.empty[Row] } else { throw new AnalysisException(s"Table ${table.identifier.unquotedString} already exists.") } } // Create the relation to validate the arguments before writing the metadata to the metastore, // and infer the table schema and partition if users didn't specify schema in CREATE TABLE. val pathOption = table.storage.locationUri.map("path" -> CatalogUtils.URIToString(_)) // Fill in some default table options from the session conf val tableWithDefaultOptions = table.copy( identifier = table.identifier.copy( database = Some( table.identifier.database.getOrElse(sessionState.catalog.getCurrentDatabase))), tracksPartitionsInCatalog = sessionState.conf.manageFilesourcePartitions) val dataSource: BaseRelation = DataSource( sparkSession = sparkSession, userSpecifiedSchema = if (table.schema.isEmpty) None else Some(table.schema), partitionColumns = table.partitionColumnNames, className = table.provider.get, bucketSpec = table.bucketSpec, options = table.storage.properties ++ pathOption, // As discussed in SPARK-19583, we don't check if the location is existed catalogTable = Some(tableWithDefaultOptions)).resolveRelation(checkFilesExist = false) val partitionColumnNames = if (table.schema.nonEmpty) { table.partitionColumnNames } else { // This is guaranteed in `PreprocessDDL`. assert(table.partitionColumnNames.isEmpty) dataSource match { case r: HadoopFsRelation => r.partitionSchema.fieldNames.toSeq case _ => Nil } } val newTable = dataSource match { // Since Spark 2.1, we store the inferred schema of data source in metastore, to avoid // inferring the schema again at read path. However if the data source has overlapped columns // between data and partition schema, we can't store it in metastore as it breaks the // assumption of table schema. Here we fallback to the behavior of Spark prior to 2.1, store // empty schema in metastore and infer it at runtime. Note that this also means the new // scalable partitioning handling feature(introduced at Spark 2.1) is disabled in this case. case r: HadoopFsRelation if r.overlappedPartCols.nonEmpty => logWarning("It is not recommended to create a table with overlapped data and partition " + "columns, as Spark cannot store a valid table schema and has to infer it at runtime, " + "which hurts performance. Please check your data files and remove the partition " + "columns in it.") table.copy(schema = new StructType(), partitionColumnNames = Nil) case _ => table.copy( schema = dataSource.schema, partitionColumnNames = partitionColumnNames, // If metastore partition management for file source tables is enabled, we start off with // partition provider hive, but no partitions in the metastore. The user has to call // `msck repair table` to populate the table partitions. tracksPartitionsInCatalog = partitionColumnNames.nonEmpty && sessionState.conf.manageFilesourcePartitions) } // We will return Nil or throw exception at the beginning if the table already exists, so when // we reach here, the table should not exist and we should set `ignoreIfExists` to false. sessionState.catalog.createTable(newTable, ignoreIfExists = false) Seq.empty[Row] } }org.apache.spark.sql.execution.datasources.DataSource#resolveRelation
sparksql create table
org.apache.spark.sql.hive.HiveAnalysis#apply
/** * Replaces generic operations with specific variants that are designed to work with Hive. * * Note that, this rule must be run after `PreprocessTableCreation` and * `PreprocessTableInsertion`. */ object HiveAnalysis extends Rule[LogicalPlan] { override def apply(plan: LogicalPlan): LogicalPlan = plan resolveOperators { case InsertIntoStatement(r: HiveTableRelation, partSpec, query, overwrite, ifPartitionNotExists) if DDLUtils.isHiveTable(r.tableMeta) => InsertIntoHiveTable(r.tableMeta, partSpec, query, overwrite, ifPartitionNotExists, query.output.map(_.name)) case CreateTable(tableDesc, mode, None) if DDLUtils.isHiveTable(tableDesc) => CreateTableCommand(tableDesc, ignoreIfExists = mode == SaveMode.Ignore) case CreateTable(tableDesc, mode, Some(query)) if DDLUtils.isHiveTable(tableDesc) && query.resolved => CreateHiveTableAsSelectCommand(tableDesc, query, query.output.map(_.name), mode) case InsertIntoDir(isLocal, storage, provider, child, overwrite) if DDLUtils.isHiveTable(provider) && child.resolved => val outputPath = new Path(storage.locationUri.get) if (overwrite) DDLUtils.verifyNotReadPath(child, outputPath) InsertIntoHiveDirCommand(isLocal, storage, child, overwrite, child.output.map(_.name)) } }org.apache.spark.sql.execution.command.CreateTableCommand#run ```scala // TODO: move the rest of the table commands from ddl.scala to this file
/**
- A command to create a table. *
- Note: This is currently used only for creating Hive tables.
- This is not intended for temporary tables. *
- The syntax of using this command in SQL is:
- {{{
- CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
- [(col1 data_type [COMMENT col_comment], …)]
- [COMMENT table_comment]
- [PARTITIONED BY (col3 data_type [COMMENT col_comment], …)]
- [CLUSTERED BY (col1, …) [SORTED BY (col1 [ASC|DESC], …)] INTO num_buckets BUCKETS]
- [SKEWED BY (col1, col2, …) ON ((col_value, col_value, …), …)
- [STORED AS DIRECTORIES]
- [ROW FORMAT row_format]
- [STORED AS file_format | STORED BY storage_handler_class [WITH SERDEPROPERTIES (…)]]
- [LOCATION path]
- [TBLPROPERTIES (property_name=property_value, …)]
- [AS select_statement];
}}} */ case class CreateTableCommand( table: CatalogTable, ignoreIfExists: Boolean) extends RunnableCommand {
override def run(sparkSession: SparkSession): Seq[Row] = { sparkSession.sessionState.catalog.createTable(table, ignoreIfExists) Seq.empty[Row] } } ```
org.apache.spark.sql.catalyst.catalog.SessionCatalog#createTable
// ---------------------------------------------------------------------------- // Tables // ---------------------------------------------------------------------------- // There are two kinds of tables, temporary views and metastore tables. // Temporary views are isolated across sessions and do not belong to any // particular database. Metastore tables can be used across multiple // sessions as their metadata is persisted in the underlying catalog. // ---------------------------------------------------------------------------- // ---------------------------------------------------- // | Methods that interact with metastore tables only | // ---------------------------------------------------- /** * Create a metastore table in the database specified in `tableDefinition`. * If no such database is specified, create it in the current database. */ def createTable( tableDefinition: CatalogTable, ignoreIfExists: Boolean, validateLocation: Boolean = true): Unit = { val db = formatDatabaseName(tableDefinition.identifier.database.getOrElse(getCurrentDatabase)) val table = formatTableName(tableDefinition.identifier.table) val tableIdentifier = TableIdentifier(table, Some(db)) validateName(table) val newTableDefinition = if (tableDefinition.storage.locationUri.isDefined && !tableDefinition.storage.locationUri.get.isAbsolute) { // make the location of the table qualified. val qualifiedTableLocation = makeQualifiedPath(tableDefinition.storage.locationUri.get) tableDefinition.copy( storage = tableDefinition.storage.copy(locationUri = Some(qualifiedTableLocation)), identifier = tableIdentifier) } else { tableDefinition.copy(identifier = tableIdentifier) } requireDbExists(db) if (tableExists(newTableDefinition.identifier)) { if (!ignoreIfExists) { throw new TableAlreadyExistsException(db = db, table = table) } } else if (validateLocation) { validateTableLocation(newTableDefinition) } externalCatalog.createTable(newTableDefinition, ignoreIfExists) }org.apache.spark.sql.hive.HiveExternalCatalog#createTable
override def createTable( tableDefinition: CatalogTable, ignoreIfExists: Boolean): Unit = withClient { assert(tableDefinition.identifier.database.isDefined) val db = tableDefinition.identifier.database.get val table = tableDefinition.identifier.table requireDbExists(db) verifyTableProperties(tableDefinition) verifyDataSchema( tableDefinition.identifier, tableDefinition.tableType, tableDefinition.dataSchema) if (tableExists(db, table) && !ignoreIfExists) { throw new TableAlreadyExistsException(db = db, table = table) } // Ideally we should not create a managed table with location, but Hive serde table can // specify location for managed table. And in [[CreateDataSourceTableAsSelectCommand]] we have // to create the table directory and write out data before we create this table, to avoid // exposing a partial written table. val needDefaultTableLocation = tableDefinition.tableType == MANAGED && tableDefinition.storage.locationUri.isEmpty val tableLocation = if (needDefaultTableLocation) { Some(CatalogUtils.stringToURI(defaultTablePath(tableDefinition.identifier))) } else { tableDefinition.storage.locationUri } if (DDLUtils.isDatasourceTable(tableDefinition)) { createDataSourceTable( tableDefinition.withNewStorage(locationUri = tableLocation), ignoreIfExists) } else { val tableWithDataSourceProps = tableDefinition.copy( // We can't leave `locationUri` empty and count on Hive metastore to set a default table // location, because Hive metastore uses hive.metastore.warehouse.dir to generate default // table location for tables in default database, while we expect to use the location of // default database. storage = tableDefinition.storage.copy(locationUri = tableLocation), // Here we follow data source tables and put table metadata like table schema, partition // columns etc. in table properties, so that we can work around the Hive metastore issue // about not case preserving and make Hive serde table and view support mixed-case column // names. properties = tableDefinition.properties ++ tableMetaToTableProps(tableDefinition)) client.createTable(tableWithDataSourceProps, ignoreIfExists) } }org.apache.spark.sql.hive.client.HiveClientImpl#createTable
override def createTable(table: CatalogTable, ignoreIfExists: Boolean): Unit = withHiveState { verifyColumnDataType(table.dataSchema) client.createTable(toHiveTable(table, Some(userName)), ignoreIfExists) }org.apache.hadoop.hive.ql.metadata.Hive#createTable(org.apache.hadoop.hive.ql.metadata.Table, boolean)
/** * Creates the table with the give objects * * @param tbl * a table object * @param ifNotExists * if true, ignore AlreadyExistsException * @throws HiveException */ public void createTable(Table tbl, boolean ifNotExists) throws HiveException { try { if (tbl.getDbName() == null || "".equals(tbl.getDbName().trim())) { tbl.setDbName(SessionState.get().getCurrentDatabase()); } if (tbl.getCols().size() == 0 || tbl.getSd().getColsSize() == 0) { tbl.setFields(MetaStoreUtils.getFieldsFromDeserializer(tbl.getTableName(), tbl.getDeserializer())); } tbl.checkValidity(); if (tbl.getParameters() != null) { tbl.getParameters().remove(hive_metastoreConstants.DDL_TIME); } org.apache.hadoop.hive.metastore.api.Table tTbl = tbl.getTTable(); PrincipalPrivilegeSet principalPrivs = new PrincipalPrivilegeSet(); SessionState ss = SessionState.get(); if (ss != null) { CreateTableAutomaticGrant grants = ss.getCreateTableGrants(); if (grants != null) { principalPrivs.setUserPrivileges(grants.getUserGrants()); principalPrivs.setGroupPrivileges(grants.getGroupGrants()); principalPrivs.setRolePrivileges(grants.getRoleGrants()); tTbl.setPrivileges(principalPrivs); } } getMSC().createTable(tTbl); } catch (AlreadyExistsException e) { if (!ifNotExists) { throw new HiveException(e); } } catch (Exception e) { throw new HiveException(e); } }org.apache.hadoop.hive.metastore.HiveMetaStoreClient#createTable(org.apache.hadoop.hive.metastore.api.Table)
org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore.Client#create_table_with_environment_context
- org.apache.spark.sql.execution.command.CreateDataSourceTableCommand
- org.apache.spark.sql.catalyst.parser.AbstractSqlParser#parse
org.apache.spark.sql.catalyst.parser.AbstractSqlParser#parsePlan
org.apache.spark.sql.catalyst.parser.SqlBaseParser
- org.apache.spark.sql.catalyst.parser.AbstractSqlParser#parsePlan
- org.apache.spark.sql.catalyst.analysis.Analyzer#executeAndCheck
- org.apache.spark.sql.catalyst.analysis.Analyzer#execute
- org.apache.spark.sql.Dataset#ofRows
- org.apache.spark.sql.execution.QueryExecution
- org.apache.spark.sql.execution.QueryExecution#analyzed
- java.util.ServiceLoader#reload
- org.apache.spark.util.Utils#getSparkClassLoader
- org.apache.spark.sql.execution.command.DDLUtils
org.apache.spark.sql.execution.datasources.DataSourceAnalysis#apply
org.apache.spark.sql.execution.command.CreateDataSourceTableCommand#run
- org.apache.spark.sql.execution.datasources.DataSource#providingClass
- org.apache.spark.sql.execution.datasources.DataSource#resolveRelation
- delta lake sbt源码转maven工程
- antlr生成的java源码
- pom文件
org.apache.spark.sql.connector.catalog
org.apache.spark.sql.delta.sources.DeltaDataSource
class DeltaDataSource
extends RelationProvider
with SchemaRelationProvider
with StreamSourceProvider
with StreamSinkProvider
with CreatableRelationProvider
with DataSourceRegister
with DeltaLogging {
override def createRelation(sqlContext: SQLContext,
parameters: Map[String, String],
schema: StructType): BaseRelation = {
val path = parameters.getOrElse("path", {
s"/tmp/delta-table/${System.currentTimeMillis()}"
})
val commitInfo = CommitInfo(
time = System.currentTimeMillis(),
operation = "WRITE",
operationParameters = Map("mode" -> "ErrorIfExists"
, "partitionBy" -> "[]"
),
commandContext = Map.empty[String, String],
None,
None,
None,
None
)
val metadata = Metadata(schemaString = schema.json)
val commitAction = SingleAction(commitInfo = commitInfo)
val metadataAction = SingleAction(metaData = metadata)
val actionIterator = Iterable(commitAction, metadataAction).iterator.map(JsonUtils.toJson(_))
/**
* dataPath, 构造元素(root_dir/db_dir/table_dir)
*/
val logStore = DeltaLog.forTable(sqlContext.sparkSession, path)
if (!logStore.fs.exists(logStore.logPath)) logStore.fs.mkdirs(logStore.logPath)
logStore.store.write(FileNames.deltaFile(logStore.logPath, 0L), actionIterator, true)
createRelation(sqlContext, parameters ++ Map("path" -> path))
}
- org.apache.spark.sql.Dataset#logicalPlan
- org.apache.spark.sql.types.UDTRegistration#register
- org.apache.spark.sql.types.SQLUserDefinedType
- org.apache.spark.sql.SparkSessionExtensions ```scala package org.apache.spark.sql
import scala.collection.mutable
import org.apache.spark.annotation.{DeveloperApi, Experimental, Unstable} import org.apache.spark.sql.catalyst.FunctionIdentifier import org.apache.spark.sql.catalyst.analysis.FunctionRegistry import org.apache.spark.sql.catalyst.analysis.FunctionRegistry.FunctionBuilder import org.apache.spark.sql.catalyst.expressions.ExpressionInfo import org.apache.spark.sql.catalyst.parser.ParserInterface import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan import org.apache.spark.sql.catalyst.rules.Rule import org.apache.spark.sql.execution.ColumnarRule
/**
- :: Experimental ::
- Holder for injection points to the [[SparkSession]]. We make NO guarantee about the stability
- regarding binary compatibility and source compatibility of methods here. *
- This current provides the following extension points: *
- Analyzer Rules.
- Check Analysis Rules.
- Optimizer Rules.
- Planning Strategies.
- Customized Parser.
- (External) Catalog listeners.
- Columnar Rules.
- The extensions can be used by calling
withExtensionson the [[SparkSession.Builder]], for - example:
- {{{
- SparkSession.builder()
- .master(“…”)
- .config(“…”, true)
- .withExtensions { extensions =>
- extensions.injectResolutionRule { session =>
- …
- }
- extensions.injectParser { (session, parser) =>
- …
- }
- }
- .getOrCreate()
- }}} *
- The extensions can also be used by setting the Spark SQL configuration property
spark.sql.extensions. Multiple extensions can be set using a comma-separated list. For example:- {{{
- SparkSession.builder()
- .master(“…”)
- .config(“spark.sql.extensions”, “org.example.MyExtensions”)
- .getOrCreate() *
- class MyExtensions extends Function1[SparkSessionExtensions, Unit] {
- override def apply(extensions: SparkSessionExtensions): Unit = {
- extensions.injectResolutionRule { session =>
- …
- }
- extensions.injectParser { (session, parser) =>
- …
- }
- }
- }
- }}} *
- Note that none of the injected builders should assume that the [[SparkSession]] is fully
initialized and should not touch the session’s internals (e.g. the SessionState). */ @DeveloperApi @Experimental @Unstable class SparkSessionExtensions { type RuleBuilder = SparkSession => Rule[LogicalPlan] type CheckRuleBuilder = SparkSession => LogicalPlan => Unit type StrategyBuilder = SparkSession => Strategy type ParserBuilder = (SparkSession, ParserInterface) => ParserInterface type FunctionDescription = (FunctionIdentifier, ExpressionInfo, FunctionBuilder) type ColumnarRuleBuilder = SparkSession => ColumnarRule
private[this] val columnarRuleBuilders = mutable.Buffer.empty[ColumnarRuleBuilder]
/**
- Build the override rules for columnar execution. */ private[sql] def buildColumnarRules(session: SparkSession): Seq[ColumnarRule] = { columnarRuleBuilders.map(_.apply(session)) }
/**
- Inject a rule that can override the columnar execution of an executor. */ def injectColumnar(builder: ColumnarRuleBuilder): Unit = { columnarRuleBuilders += builder }
private[this] val resolutionRuleBuilders = mutable.Buffer.empty[RuleBuilder]
/**
- Build the analyzer resolution
Rules using the given [[SparkSession]]. */ private[sql] def buildResolutionRules(session: SparkSession): Seq[Rule[LogicalPlan]] = { resolutionRuleBuilders.map(_.apply(session)) }
/**
- Inject an analyzer resolution
Rulebuilder into the [[SparkSession]]. These analyzer - rules will be executed as part of the resolution phase of analysis. */ def injectResolutionRule(builder: RuleBuilder): Unit = { resolutionRuleBuilders += builder }
private[this] val postHocResolutionRuleBuilders = mutable.Buffer.empty[RuleBuilder]
/**
- Build the analyzer post-hoc resolution
Rules using the given [[SparkSession]]. */ private[sql] def buildPostHocResolutionRules(session: SparkSession): Seq[Rule[LogicalPlan]] = { postHocResolutionRuleBuilders.map(_.apply(session)) }
/**
- Inject an analyzer
Rulebuilder into the [[SparkSession]]. These analyzer - rules will be executed after resolution. */ def injectPostHocResolutionRule(builder: RuleBuilder): Unit = { postHocResolutionRuleBuilders += builder }
private[this] val checkRuleBuilders = mutable.Buffer.empty[CheckRuleBuilder]
/**
- Build the check analysis
Rules using the given [[SparkSession]]. */ private[sql] def buildCheckRules(session: SparkSession): Seq[LogicalPlan => Unit] = { checkRuleBuilders.map(_.apply(session)) }
/**
- Inject an check analysis
Rulebuilder into the [[SparkSession]]. The injected rules will - be executed after the analysis phase. A check analysis rule is used to detect problems with a
- LogicalPlan and should throw an exception when a problem is found. */ def injectCheckRule(builder: CheckRuleBuilder): Unit = { checkRuleBuilders += builder }
private[this] val optimizerRules = mutable.Buffer.empty[RuleBuilder]
private[sql] def buildOptimizerRules(session: SparkSession): Seq[Rule[LogicalPlan]] = { optimizerRules.map(_.apply(session)) }
/**
- Inject an optimizer
Rulebuilder into the [[SparkSession]]. The injected rules will be - executed during the operator optimization batch. An optimizer rule is used to improve the
- quality of an analyzed logical plan; these rules should never modify the result of the
- LogicalPlan. */ def injectOptimizerRule(builder: RuleBuilder): Unit = { optimizerRules += builder }
private[this] val plannerStrategyBuilders = mutable.Buffer.empty[StrategyBuilder]
private[sql] def buildPlannerStrategies(session: SparkSession): Seq[Strategy] = { plannerStrategyBuilders.map(_.apply(session)) }
/**
- Inject a planner
Strategybuilder into the [[SparkSession]]. The injected strategy will - be used to convert a
LogicalPlaninto a executable - [[org.apache.spark.sql.execution.SparkPlan]]. */ def injectPlannerStrategy(builder: StrategyBuilder): Unit = { plannerStrategyBuilders += builder }
private[this] val parserBuilders = mutable.Buffer.empty[ParserBuilder]
private[sql] def buildParser( session: SparkSession, initial: ParserInterface): ParserInterface = { parserBuilders.foldLeft(initial) { (parser, builder) => builder(session, parser) } }
/**
- Inject a custom parser into the [[SparkSession]]. Note that the builder is passed a session
- and an initial parser. The latter allows for a user to create a partial parser and to delegate
- to the underlying parser for completeness. If a user injects more parsers, then the parsers
- are stacked on top of each other. */ def injectParser(builder: ParserBuilder): Unit = { parserBuilders += builder }
private[this] val injectedFunctions = mutable.Buffer.empty[FunctionDescription]
private[sql] def registerFunctions(functionRegistry: FunctionRegistry) = { for ((name, expressionInfo, function) <- injectedFunctions) { functionRegistry.registerFunction(name, expressionInfo, function) } functionRegistry }
/**
- Injects a custom function into the [[org.apache.spark.sql.catalyst.analysis.FunctionRegistry]]
- at runtime for all sessions. */ def injectFunction(functionDescription: FunctionDescription): Unit = { injectedFunctions += functionDescription } } ```
- org.apache.spark.sql.Dataset#ofRows
- org.apache.spark.sql.Dataset#logicalPlan
- org.apache.spark.sql.catalyst.plans.logical.LocalRelation
/**
* Create a resolved [[BaseRelation]] that can be used to read data from or write data into this
* [[DataSource]]
*
* @param checkFilesExist Whether to confirm that the files exist when generating the
* non-streaming file based datasource. StructuredStreaming jobs already
* list file existence, and when generating incremental jobs, the batch
* is considered as a non-streaming file based data source. Since we know
* that files already exist, we don't need to check them again.
*/
def resolveRelation(checkFilesExist: Boolean = true): BaseRelation = {
val relation = (providingInstance(), userSpecifiedSchema) match {
// TODO: Throw when too much is given.
case (dataSource: SchemaRelationProvider, Some(schema)) =>
dataSource.createRelation(sparkSession.sqlContext, caseInsensitiveOptions, schema)
case (dataSource: RelationProvider, None) =>
dataSource.createRelation(sparkSession.sqlContext, caseInsensitiveOptions)
case (_: SchemaRelationProvider, None) =>
throw new AnalysisException(s"A schema needs to be specified when using $className.")
case (dataSource: RelationProvider, Some(schema)) =>
val baseRelation =
dataSource.createRelation(sparkSession.sqlContext, caseInsensitiveOptions)
if (baseRelation.schema != schema) {
throw new AnalysisException(s"$className does not allow user-specified schemas.")
}
baseRelation
// We are reading from the results of a streaming query. Load files from the metadata log
// instead of listing them using HDFS APIs.
case (format: FileFormat, _)
if FileStreamSink.hasMetadata(
caseInsensitiveOptions.get("path").toSeq ++ paths,
sparkSession.sessionState.newHadoopConf(),
sparkSession.sessionState.conf) =>
val basePath = new Path((caseInsensitiveOptions.get("path").toSeq ++ paths).head)
val fileCatalog = new MetadataLogFileIndex(sparkSession, basePath,
caseInsensitiveOptions, userSpecifiedSchema)
val dataSchema = userSpecifiedSchema.orElse {
format.inferSchema(
sparkSession,
caseInsensitiveOptions,
fileCatalog.allFiles())
}.getOrElse {
throw new AnalysisException(
s"Unable to infer schema for $format at ${fileCatalog.allFiles().mkString(",")}. " +
"It must be specified manually")
}
HadoopFsRelation(
fileCatalog,
partitionSchema = fileCatalog.partitionSchema,
dataSchema = dataSchema,
bucketSpec = None,
format,
caseInsensitiveOptions)(sparkSession)
// This is a non-streaming file based datasource.
case (format: FileFormat, _) =>
val useCatalogFileIndex = sparkSession.sqlContext.conf.manageFilesourcePartitions &&
catalogTable.isDefined && catalogTable.get.tracksPartitionsInCatalog &&
catalogTable.get.partitionColumnNames.nonEmpty
val (fileCatalog, dataSchema, partitionSchema) = if (useCatalogFileIndex) {
val defaultTableSize = sparkSession.sessionState.conf.defaultSizeInBytes
val index = new CatalogFileIndex(
sparkSession,
catalogTable.get,
catalogTable.get.stats.map(_.sizeInBytes.toLong).getOrElse(defaultTableSize))
(index, catalogTable.get.dataSchema, catalogTable.get.partitionSchema)
} else {
val globbedPaths = checkAndGlobPathIfNecessary(
checkEmptyGlobPath = true, checkFilesExist = checkFilesExist)
val index = createInMemoryFileIndex(globbedPaths)
val (resultDataSchema, resultPartitionSchema) =
getOrInferFileFormatSchema(format, () => index)
(index, resultDataSchema, resultPartitionSchema)
}
HadoopFsRelation(
fileCatalog,
partitionSchema = partitionSchema,
dataSchema = dataSchema.asNullable,
bucketSpec = bucketSpec,
format,
caseInsensitiveOptions)(sparkSession)
case _ =>
throw new AnalysisException(
s"$className is not a valid Spark SQL Data Source.")
}
relation match {
case hs: HadoopFsRelation =>
SchemaUtils.checkColumnNameDuplication(
hs.dataSchema.map(_.name),
"in the data schema",
equality)
SchemaUtils.checkColumnNameDuplication(
hs.partitionSchema.map(_.name),
"in the partition schema",
equality)
DataSourceUtils.verifySchema(hs.fileFormat, hs.dataSchema)
case _ =>
SchemaUtils.checkColumnNameDuplication(
relation.schema.map(_.name),
"in the data schema",
equality)
}
relation
}
org.apache.spark.sql.execution.datasources.DataSource#resolveRelation ```scala /**
- Create a resolved [[BaseRelation]] that can be used to read data from or write data into this
- [[DataSource]] *
- @param checkFilesExist Whether to confirm that the files exist when generating the
- non-streaming file based datasource. StructuredStreaming jobs already
- list file existence, and when generating incremental jobs, the batch
- is considered as a non-streaming file based data source. Since we know
that files already exist, we don’t need to check them again. */ def resolveRelation(checkFilesExist: Boolean = true): BaseRelation = { val catalogTableMap = if (catalogTable.isDefined) Map(“table” -> catalogTable.get.identifier.table, “database” -> catalogTable.get.database) else Map.empty[String, String]
val relation = (providingClass.newInstance(), userSpecifiedSchema) match { // TODO: Throw when too much is given. case (dataSource: SchemaRelationProvider, Some(schema)) => dataSource.createRelation(sparkSession.sqlContext, caseInsensitiveOptions ++ catalogTableMap, schema) case (dataSource: RelationProvider, None) => dataSource.createRelation(sparkSession.sqlContext, caseInsensitiveOptions)
- org.apache.spark.sql.delta.sources.DeltaDataSource#createRelation
```scala
override def createRelation(sqlContext: SQLContext,
parameters: Map[String, String],
schema: StructType): BaseRelation = {
val db = parameters.get("database")
val tablename = parameters.get("table")
/**
* dataPath, 构造元素(root_dir/db_dir/table_dir)
*/
val path = parameters.getOrElse("path", {
s"/user/hive/warehouse/${db.get}.db/${tablename.get}"
})
val commitInfo = CommitInfo(
time = System.currentTimeMillis(),
operation = "WRITE",
operationParameters = Map("mode" -> "ErrorIfExists"
, "partitionBy" -> "[]"
),
commandContext = Map.empty[String, String],
None,
None,
None,
None
)
val metadata = Metadata(schemaString = schema.json)
val commitAction = SingleAction(commitInfo = commitInfo)
val metadataAction = SingleAction(metaData = metadata)
val actionIterator = Iterable(commitAction, metadataAction).iterator.map(JsonUtils.toJson(_))
val logStore = DeltaLog.forTable(sqlContext.sparkSession, path)
if (!logStore.fs.exists(logStore.logPath)) logStore.fs.mkdirs(logStore.logPath)
logStore.store.write(FileNames.deltaFile(logStore.logPath, 0L), actionIterator, true)
createRelation(sqlContext, parameters ++ Map("path" -> path))
}
Hudi
|— _hoodie_commit_time: string (nullable = true)
|— _hoodie_commit_seqno: string (nullable = true)
|— _hoodie_record_key: string (nullable = true)
|— _hoodie_partition_path: string (nullable = true)
|— _hoodie_file_name: string (nullable = true)
moot【模拟】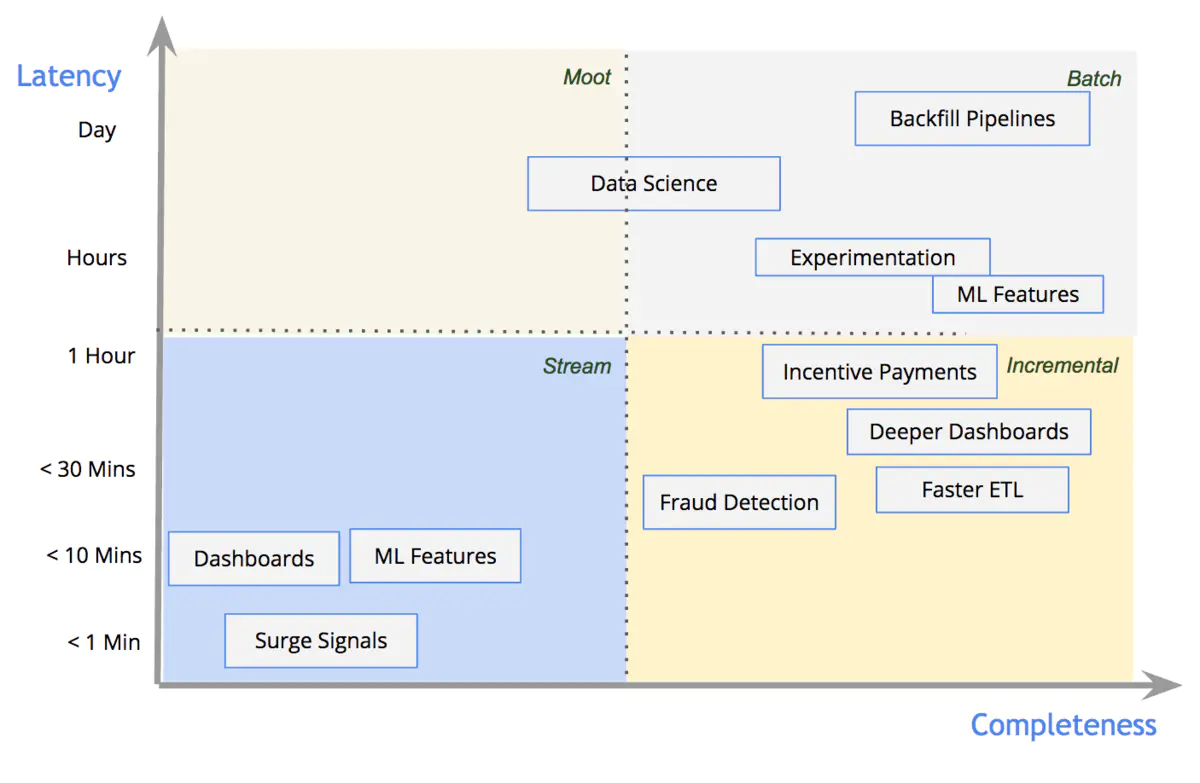
Iceberg
Apache Iceberg (incubating) is a new table format for storing large, slow-moving tabular data. It is designed to improve on the de-facto standard table layout built into Hive, Presto, and Spark.
The core Java library that tracks table snapshots and metadata is complete, but still evolving. Current work is focused on integrating Iceberg into Spark and Presto.
The Iceberg format specification is being actively updated and is open for comment. Until the specification is complete and released, it carries no compatibility guarantees. The spec is currently evolving as the Java reference implementation changes.
Iceberg is built using Gradle 5.4.1 with Java 1.8.
- To invoke a build and run tests:
./gradlew build - To skip tests:
./gradlew build -x test
Iceberg table support is organized in library modules:
iceberg-commoncontains utility classes used in other modulesiceberg-apicontains the public Iceberg APIiceberg-corecontains implementations of the Iceberg API and support for Avro data files, this is what processing engines should depend oniceberg-parquetis an optional module for working with tables backed by Parquet filesiceberg-orcis an optional module for working with tables backed by ORC files (experimental)iceberg-hiveis an implementation of iceberg tables backed by hive metastore thrift client
This project Iceberg also has modules for adding Iceberg support to processing engines:
iceberg-sparkis an implementation of Spark’s Datasource V2 API for Iceberg (use iceberg-runtime for a shaded version)iceberg-datais a client library used to read Iceberg tables from JVM applicationsiceberg-pigis an implementation of Pig’s LoadFunc API for Iceberg
Reference
- 数据湖方案:Hudi、Delta、Iceberg深度对比
- Hudi for Continuous Deep Analytics
- Uber’s case for incremental processing on Hadoop
A fast and simple framework for building and running distributed applications. Ray is packaged with RLlib, a scalable reinforcement learning library, and Tune, a scalable hyperparameter tuning library. https://ray.io

若有收获,就点个赞吧
0 人点赞
