背景
数据集成作为数据分析处理(数据建模、数据挖掘、机器学习 .etc)的第一步且是必要条件。数据集成在实际的项目应用过程中往往会面临如下比较棘手的难题:
- 多源异构数据源(RDMS、NoSQL、FileSystem .etc)
- 增量式数据集成(源头的数据改变如何高效率的集成到目的存储)
- 数据切分(高性能)(大表数据如何拆分为天然的数据筛选逻辑)
- 数据质量校验统计(schema consist validate)
- 够用的统计metrics(当前集成的状态)
- 流量控制
-
调研技术产品
在进行数据集成技术、产品的调研过程中,为了保证开源技术、产品被实际应用的可行性,制定如下筛选规则:
尽可能地开箱即用(部署简洁)
- 外部依赖较少或者被很好的内部封装屏蔽
- 实际应用可操作性不过于繁琐、复杂
- 友好、简洁的UI
- 清晰、格式化的配置
- 性能可以接受(1亿)
- 80%的非海量数据集成场景
- 20%的海量数据集成场景
- 可插拔式数据源集成插件(组件)并且接口抽象合理
- 提供业务接口便于产品调用封装
根据上述的筛选规则,有如下技术、产品初步通过筛选。
| 名称 | GitHub地址 | fork | star | contributor | commit | since |
|---|---|---|---|---|---|---|
| pentaho/pentaho-kettle | https://github.com/pentaho/pentaho-kettle | 2070 | 3400 | 175 | 21624 | 2013-10-08 |
| streamsets/datacollector | https://github.com/streamsets/datacollector | 455 | 860 | 76 | 9374 | 2015-09-09 |
| alibaba/DataX | https://github.com/alibaba/DataX | 1600 | 4200 | 7 | 64 | 2018-01-18 |
Pentaho Data Integration(Kettle)
Choose an end-to-end platform for all data integration challenges. This intuitive drag-and-drop graphical interface simplifies the creation of data pipelines. For data transformation, you can easily use push-down processing to scale out compute capabilities across on-premises and cloud environments.
- Easy To Use
- Inline and stepwise visualization of data in the pipeline and machine-learning model orchestration.
- Light-Weight Design
- Containerized architecture enables data ingestion, blending, preparation and visualization.
- Big Data Processing
- Seamlessly switch between our native engine and Apache Spark to process any data source at scale.
StreamSets Datacollector
Continuous big data and cloud platform ingest infrastructure
【持续性大数据和云平台摄取架构】
What is StreamSets Data Collector?
StreamSets Data Collector is an enterprise grade, open source, continuous big data ingestion infrastructure. It has an advanced and easy to use User Interface that lets data scientists, developers and data infrastructure teams easily create data pipelines in a fraction of the time typically required to create complex ingest scenarios. Out of the box, StreamSets Data Collector reads from and writes to a large number of end-points, including S3, JDBC, Hadoop, Kafka, Cassandra and many others. You can use Python, Javascript and Java Expression Language in addition to a large number of pre-built stages to transform and process the data on the fly. For fault tolerance and scale out, you can setup data pipelines in cluster mode and perform fine grained monitoring at every stage of the pipeline.
【
- 企业级、开源、持续性(流式)数据摄取
- 友好的操作用户界面
- 支持大量的(输入、输出)数据源
- 很好的状态监控
- 提供丰富的数据处理方法封装
】
The DataOps Architectural Advantage
The StreamSets DataOps Platform is architected on the principles of continuous design, continuous operations, and continuous data.
It helps enterprises build and maintain pipelines much faster, and keep pipelines running smoothly in the face of change.
- Developer Productivity
- Design “no code” pipeline templates.
- Leverage pre-built origins, destinations and transformations.
- Auto-generate new instances and schedule jobs.
- Reuse best practice pipeline logic.
- Operational Efficiency
- Dataflow sensors monitor data and pipeline performance.
- Visualize interconnected pipelines on topology map with drill down.
- Set Data SLAs plus automated actions and alerts.
- Architectural Agility
- Add and upgrade data systems without pipeline downtime.
- Detect data drift and auto-sync changed fields to downstream platforms.
- Compare pipeline performance across versions.
Alibaba DataX
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
- 设计理念
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。 - 当前使用现状
DataX在阿里巴巴集团内被广泛使用,承担了所有大数据的离线同步业务,并已持续稳定运行了6年之久。目前每天完成同步8w多道作业,每日传输数据量超过300TB。
此前已经开源DataX1.0版本,此次介绍为阿里云开源全新版本DataX3.0,有了更多更强大的功能和更好的使用体验。Github主页地址:https://github.com/alibaba/DataX
DataX3.0框架设计

DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
DataX3.0核心架构
DataX 3.0 开源版本支持单机多线程模式完成同步作业运行,本小节按一个DataX作业生命周期的时序图,从整体架构设计非常简要说明DataX各个模块相互关系。
核心模块介绍:
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
DataX调度流程:
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
DataXJob根据分库分表切分成了100个Task。
- 根据20个并发,DataX计算共需要分配4个TaskGroup。
- 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
DataX 3.0六大核心优势
- 可靠的数据质量监控
- 丰富的数据转换功能
- 精准的速度控制
- 强劲的同步性能
- 健壮的容错机制DataX作业是极易受外部因素的干扰,网络闪断、数据源不稳定等因素很容易让同步到一半的作业报错停止。因此稳定性是DataX的基本要求,在DataX 3.0的设计中,重点完善了框架和插件的稳定性。目前DataX3.0可以做到线程级别、进程级别(暂时未开放)、作业级别多层次局部/全局的重试,保证用户的作业稳定运行。
- 极简的使用体验
试用实践
背景
数据表从oracle采集到hdfs上,表数据量:18828550
**
DataX
基于job任务配置文件进行数据采集输出存储。
{"job": {"setting": {"speed": {"byte": 1048576},"errorLimit": {"record": 0,"percentage": 0.02}},"content": [{"reader": {"name": "oraclereader","parameter": {"username": "HBQ_DATA","password": "******","where": "","connection": [{"querySql": ["SELECTCX_UUID, // 其他字段省略FROM ZSTP_VEHICLE_XUNLIAN"],"jdbcUrl": ["jdbc:oracle:thin:@10.3.71.126:1521:orcl"]}]}},"writer": {"name": "hdfswriter","parameter": {"defaultFS": "hdfs://10.3.71.124:8020","fileType": "orc","path": "/tmp","fileName": "oracle_test","column": [{"name": "CX_UUID","type": "string"}// ... 其他字段省略],"writeMode": "append","fieldDelimiter": "\t","compress": "NONE"}}}]}}
执行命令:python ${DATAX_HOME}/bin/datax.py ${DATAX_HOME}/lk_job/oracle2hdfs.json
结果
任务启动时刻 : 2019-11-29 13:58:04任务结束时刻 : 2019-11-29 14:53:27任务总计耗时 : 3322s任务平均流量 : 8.58MB/s记录写入速度 : 5671rec/s读出记录总数 : 18828550读写失败总数 : 0
结果文件格式:ORC;文件大小:3.39G;时长:0.92h
Kettle
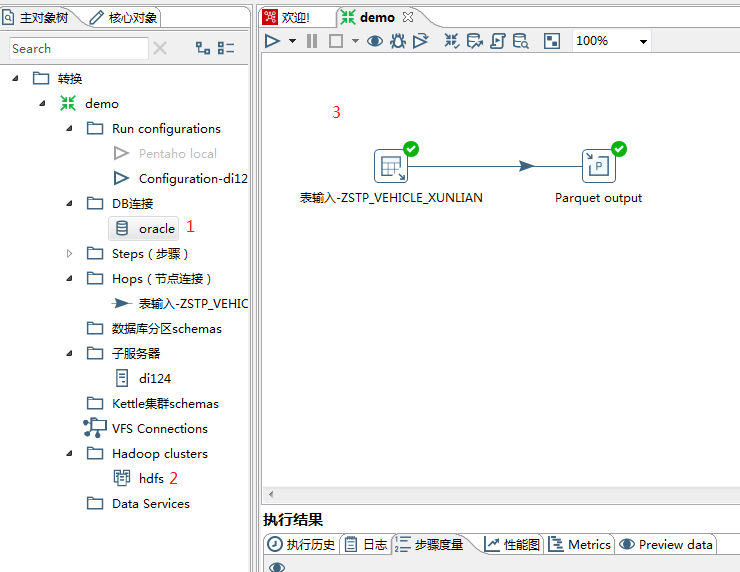
结果
速度:2320 record per second;结果文件格式:parquet;文件大小:41.5G;时长:2h15min
Streamsets DataColloctor
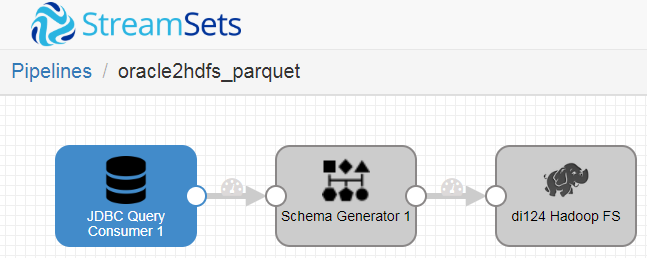
结果
速度:2050 record per second;结果文件格式:avro;文件大小:8.67G;时长:2.55h
思考总结
优点
- DataX
- 性能高,速度快
- 监控优良
- 自定义可插拔插件
- Kettle
- 操作简洁
- 速度可接受
- 输出格式多
- 自定义可插拔插件
Streamsets DC
DataX
- 基于json进行job构建,配置出错提示不清晰
- hdfs输出类型支持过少(text、orc)
- 字段配置本可以技术自动获取,但是却需要用户配置;
- Kettle
- 配置相对复杂
- Streamsets DC
- 强制增量相关配置

若有收获,就点个赞吧
0 人点赞
