MapReduce的Shuffle
在shuffle的时候,需要将各个节点里面的相同的key拉取到同一个节点进行task处理,例如join 、group by,如果某个key对应的数据量非常大,那么必然这个key对应的数据进行处理的时候就会产生数据倾斜。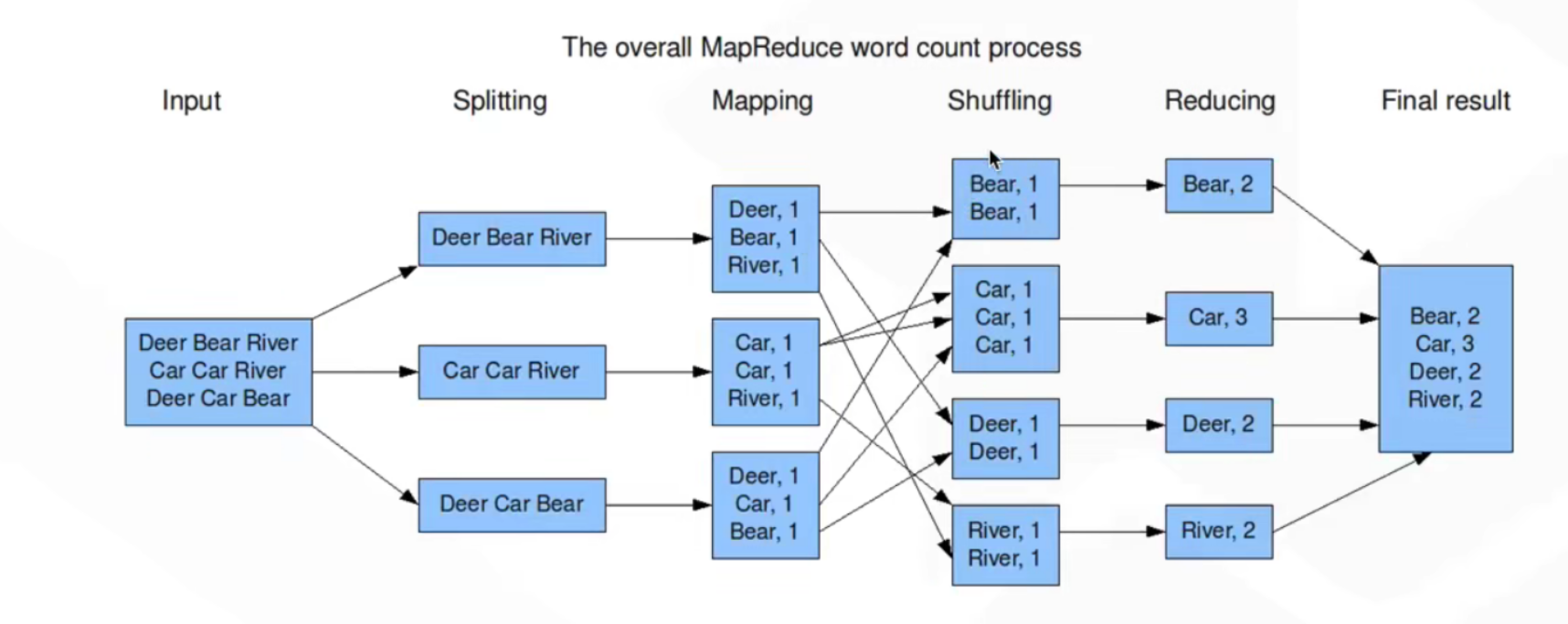
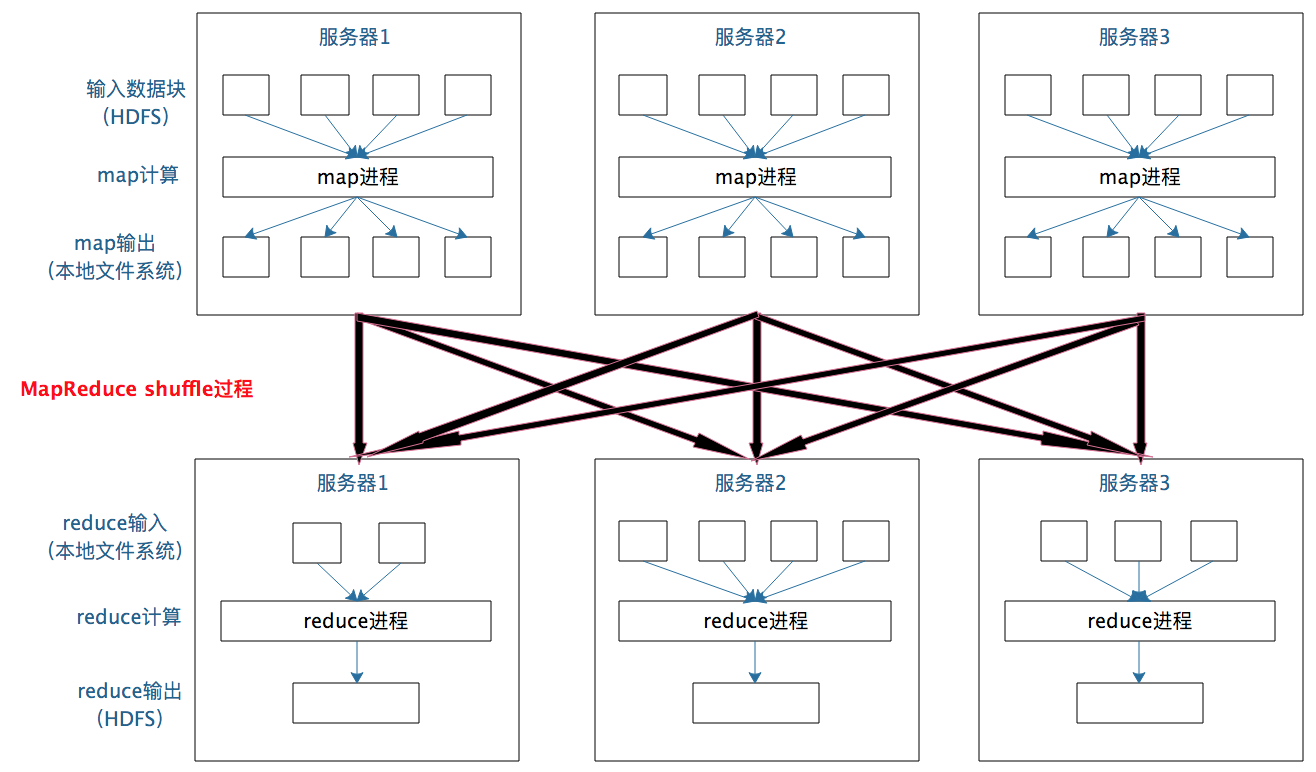
每个 Map 任务的计算结果都会写入到本地文件系统,等 Map 任务快要计算完成的时候,MapReduce 计算框架会启动 shuffle 过程,在 Map 任务进程调用一个 Partitioner 接口,对 Map 产生的每个
Reduce 任务进程对收到的
map 输出的
/** Use {@link Object#hashCode()} to partition. */public int getPartition(K2 key, V2 value, int numReduceTasks) {return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;}
对 shuffle 的理解,只需要记住这一点:分布式计算需要将不同服务器上的相关数据合并到一起进行下一步计算,这就是 shuffle。
Spark中的Shuffle


若有收获,就点个赞吧
0 人点赞
