HBase是基于HDFS作为存储系统。是分布式数据库,原型是BigTable
HBase物理存储是map结构
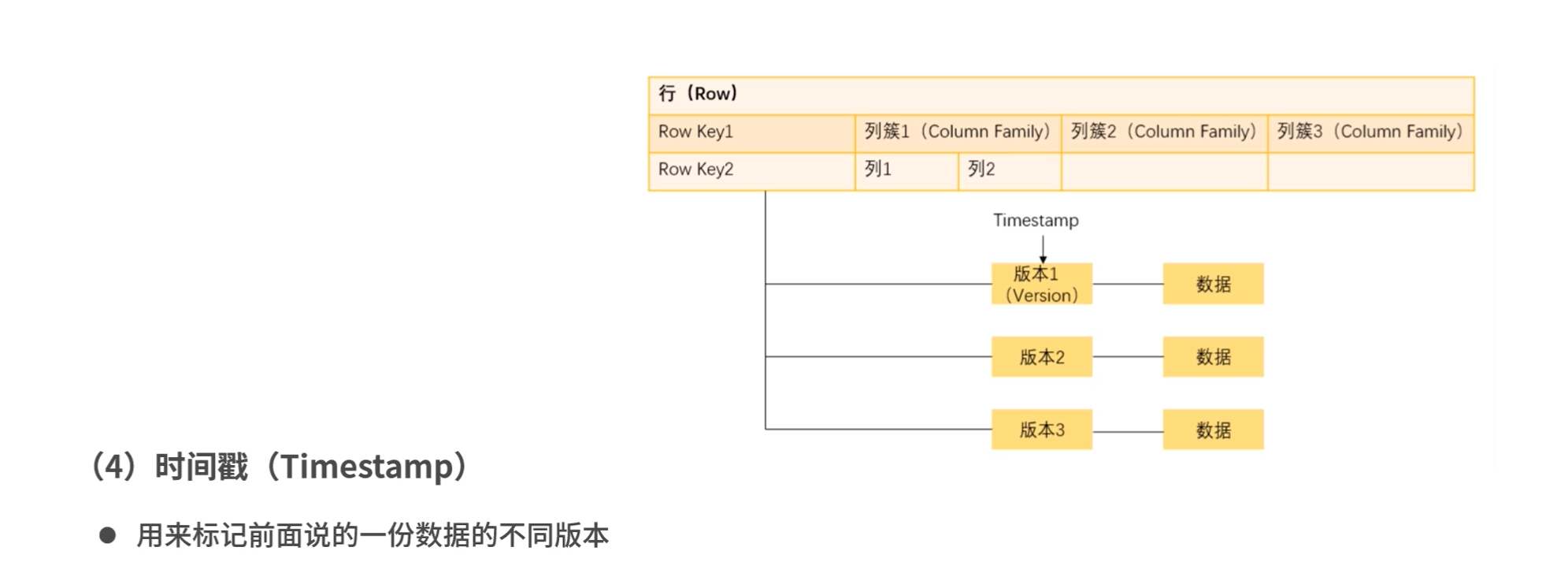
HBase中Map的key是一个复合键,由rowkey、column family、qualifier、type以及timestamp组成,value即为cell的值
HBase适合写入,多写,相对HDFS来说。单条数据读取不如Redis,批读还行。
HBase的特点
稀疏的、分布式的、持久性的、多维的以及排序的。
传统的数据库通讯开销大,可用性不高,可扩充性差
分布式数据库扩展能力强,成本优势。
多维
HBase中的Map与普通Map最大的不同在于,key是一个复合数据结构,由多维元素构成,包括rowkey、column family、qualif ier、type以及timestamp。
稀疏
很多裂都是空值
对于HBase,空值不需要任何填充,因为HBase的列在理论上是允许无限扩展的,对于成百万列的表来说,通常都会存在大量的空值,如果使用填充nu ll的策略,势必会造成大量空间的浪费。因此稀疏性是HBase的列可以无限扩展的一个重要条件。
有序
构成HBase的KV在同一个文件中都是有序的,但规则并不是仅仅按照rowkey排序,而是按照KV中的key进行排序
先比较rowkey,rowkey小的排在前面;
如果rowkey相同,再比较column,即column family:qualif ier,column小的排在前面;
如果column还相同,再比较时间戳timestamp,即版本信息,timestamp大的排在前面。
这样的多维元素排序规则对于提升HBase的读取性能至关重要。
分布式
很容易理解,构成HBase的所有Map并不集中在某台机器上,而是分布在整个集群中。

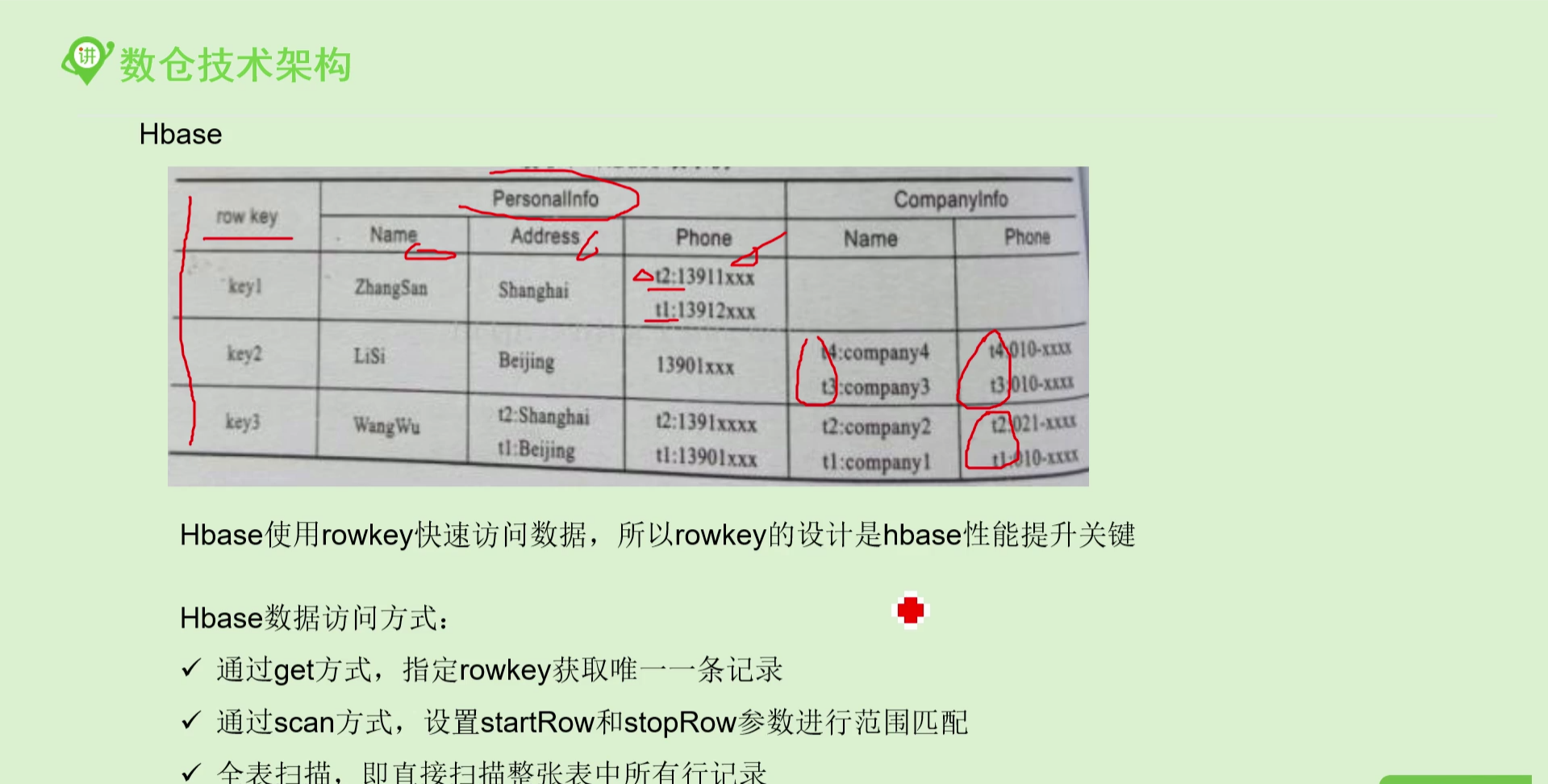
数据模型/逻辑视图
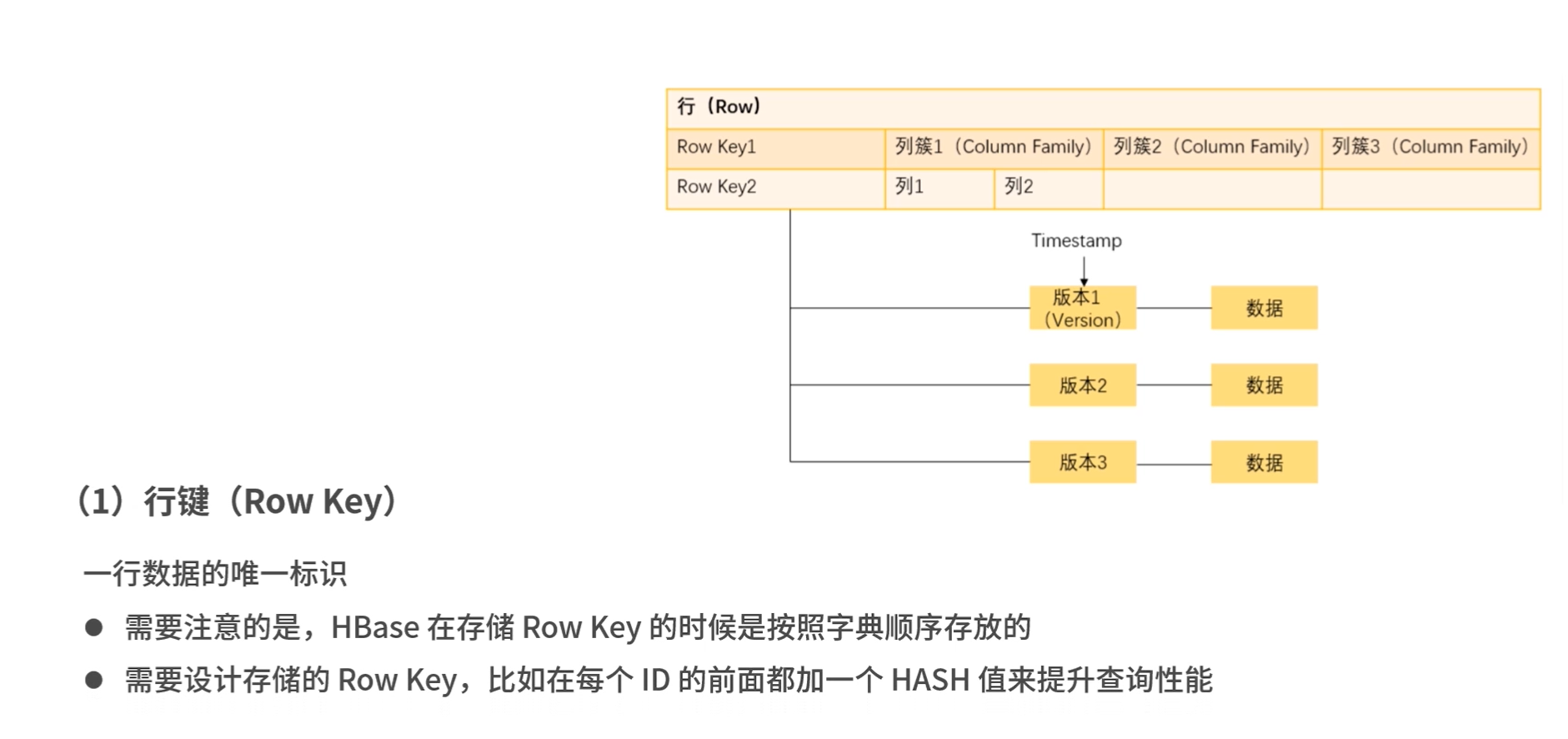
rowkey 行关键字
行的主键,用于检索记录,任意字符串,最大程度64kb
太顺序的话,同一时间对同一范围数据高并发读写,可能会产生锁
因为HBase存储Row Key是按照字典顺序存放,如果大量Row key集中则会导致数据集中。
访问HBase表有三种方式,通过单个row key(get),通过row key的range,全表扫描(scan)。
二级索引
二级索引相当于又建了一个表,二级索引去找rowkey,然后根据rowkey找数据,不同二级索引可能对相同的rowkey。

列簇 column family
一组列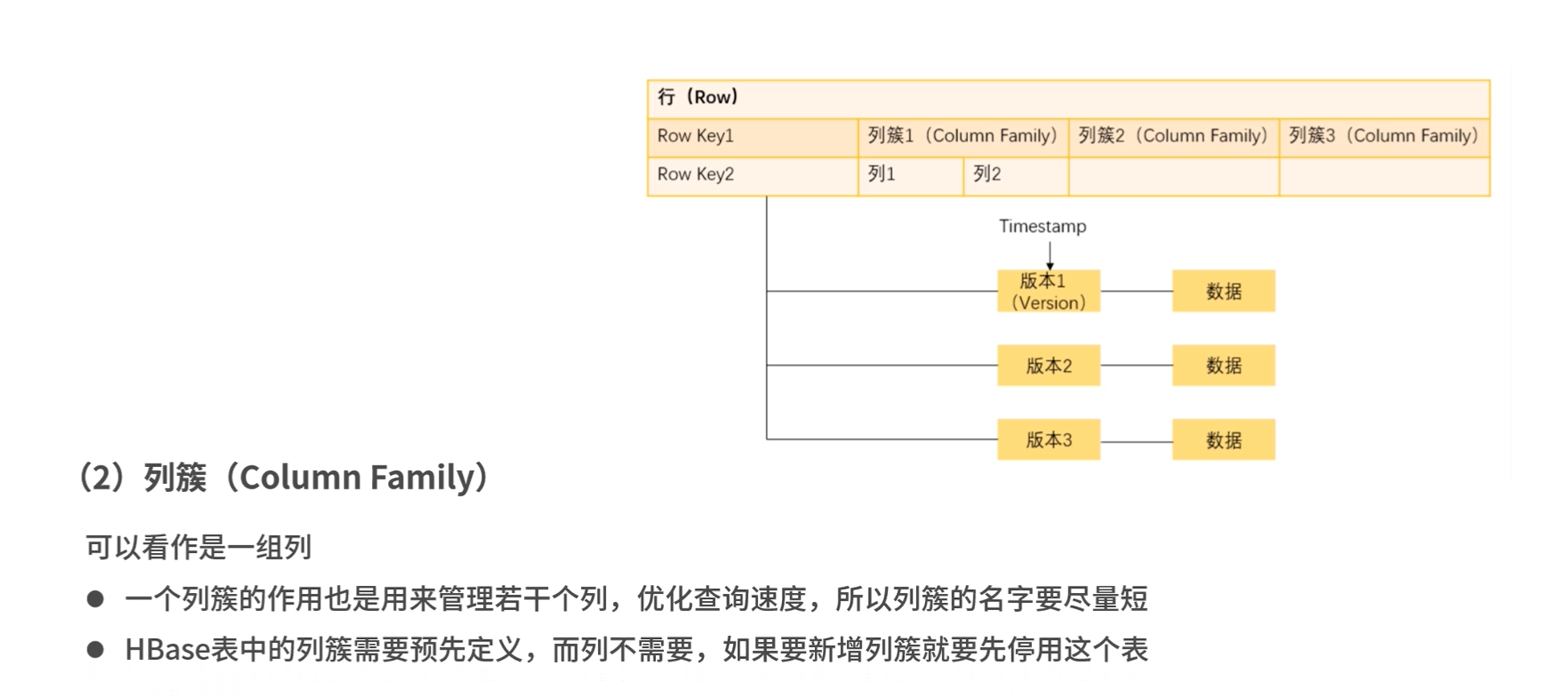
单元

时间戳
区域Region
一个region可以看作多行数据的集合。
可以按照行存储在不同的region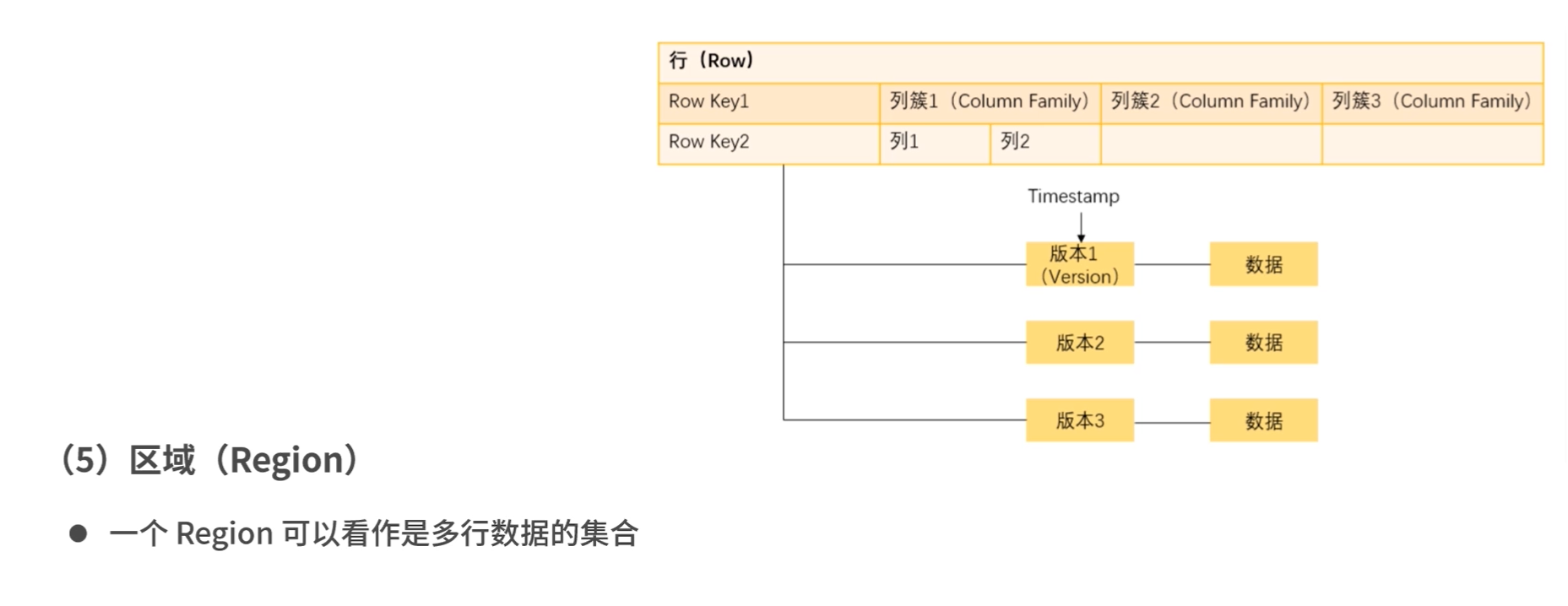
物理模型
key-value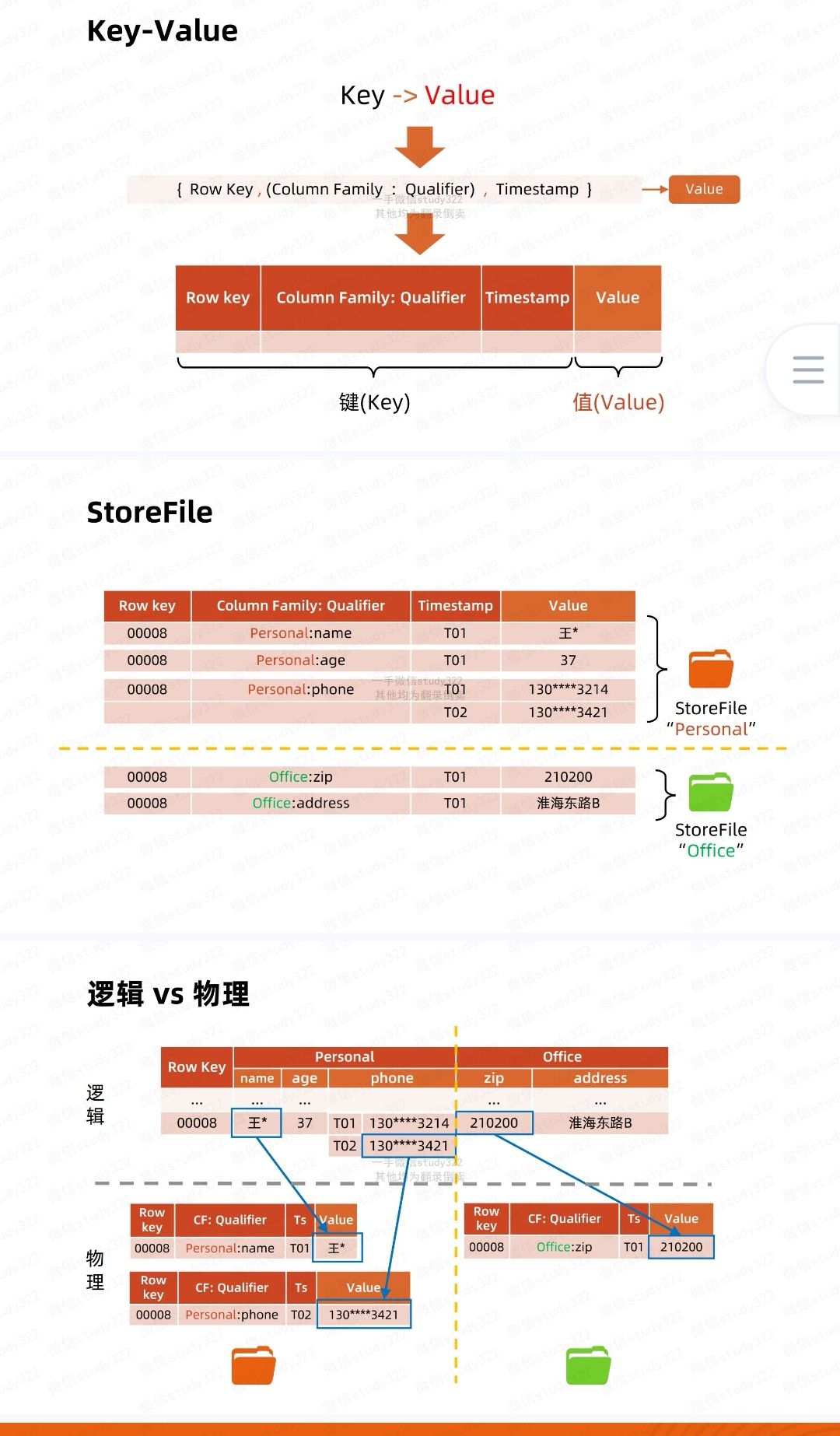

若有收获,就点个赞吧
0 人点赞
