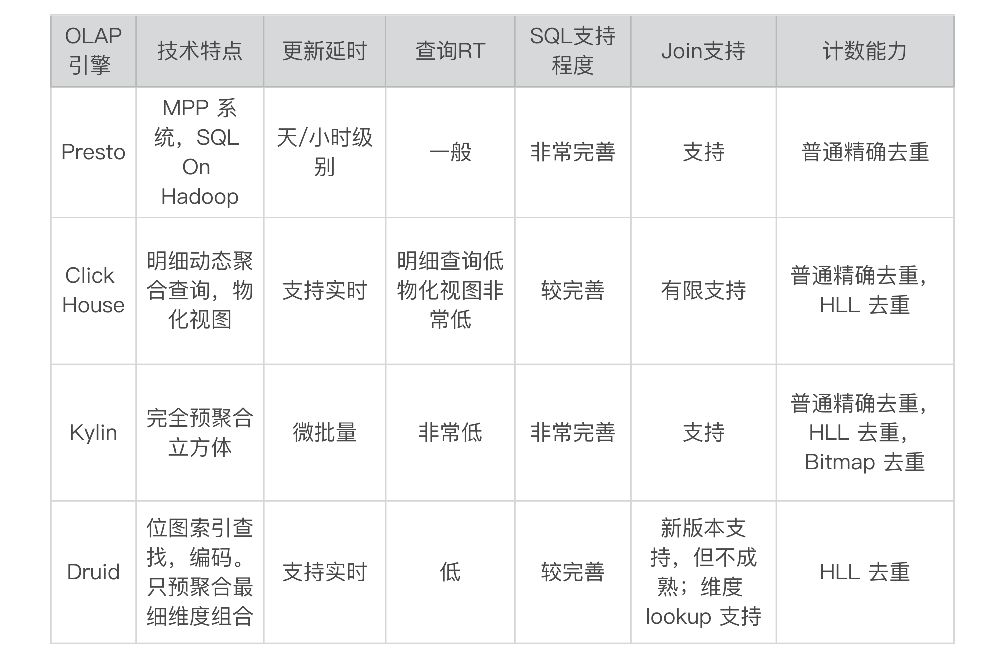
各类型对比
| 名称 | 描述 | 细节数据存储位置 | 聚合后的数据存储位置 |
|---|---|---|---|
| ROLAP(Relational OLAP) | 基于关系数据库的OLAP实现 | 关系型数据库 | 关系型数据库 |
| MOLAP(Multidimensional OLAP) | 基于多维数据组织的OLAP实现 | 数据立方体 | 数据立方体 |
| HOLAP(Hybrid OLAP) | 基于混合数据组织的OLAP实现 | 关系型数据库 | 数据立方体 |

ROLAP基于关系,它的OLAP引擎就是将用户的OLAP操作,如上钻下钻过滤合并等,转换成SQL语句提交到数据库中执行,并且提供聚集导航功能,根据用户操作的维度和度量将SQL查询定位到最粗粒度的事实表上去。
MOLAP事先将汇总数据计算好,存放在自己特定的多维数据库中,用户的OLAP操作可以直接映射到多维数据库的访问,不通过SQL访问。
下面这句话应该是有问题的。
ROLAP提供了更大的灵活度,MOLAP提供提供了更加快速的响应速度。但是带来的问题是,数据装载的效率非常低,但是带来的问题是,数据装载的效率非常低,因为其实就是将多维的数据预先填好,但是随着数据量过大维度成本越高,容易引起“数据爆炸”

ROLAP 关系型
关系型,从明细数据直接聚合
主要有维度表和事实表。
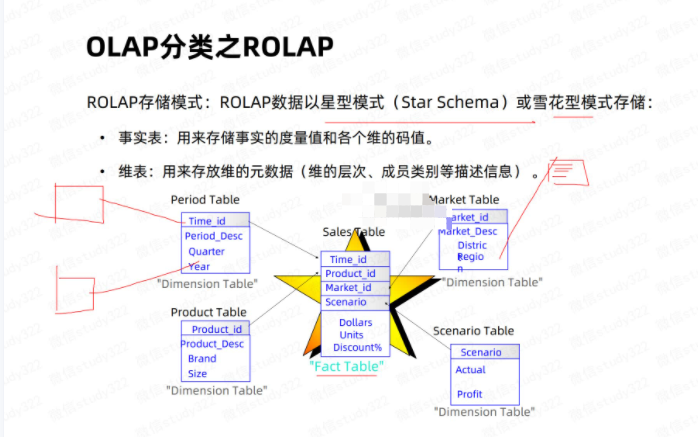
关系型OLAP,通过对原始明细数据实时聚合计算的方式来进行数据查询,比如Presto、clickhouse等OLAP引擎。
例如Presto,clickhouse
ROLAP架构
计算还是在数据库中,大数据场景中这里可以把左侧的数据库看作hive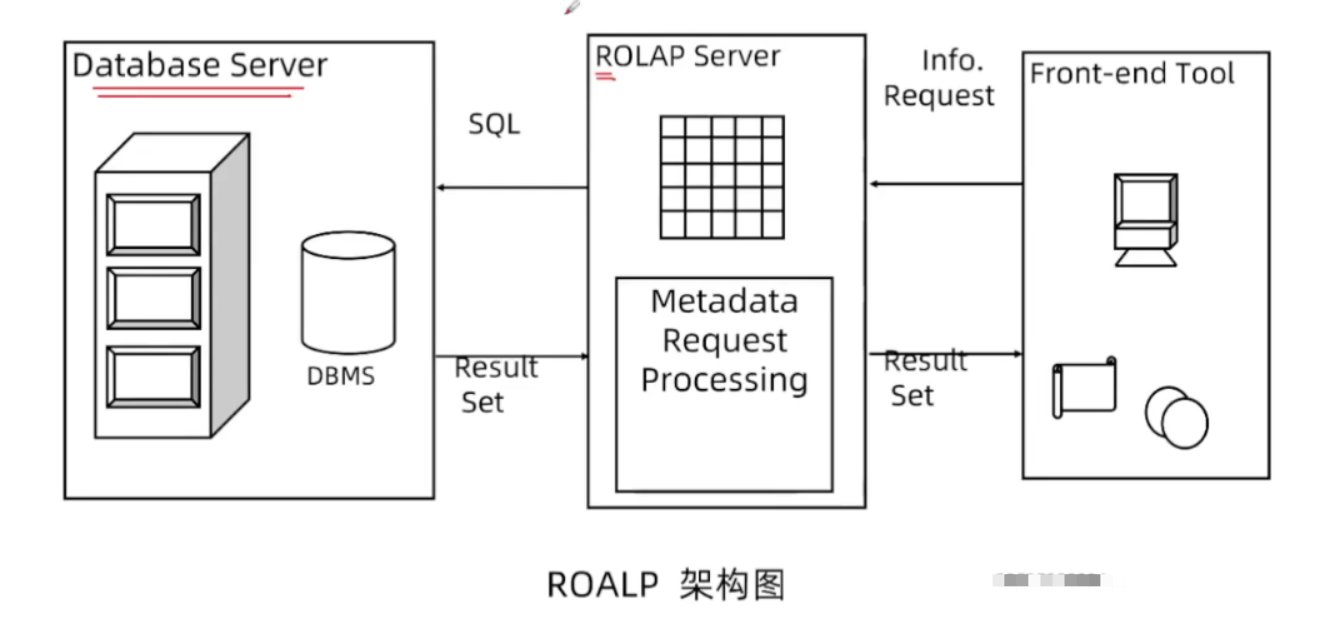
相关产品
presto
presto通过全内存计算、pipeline、动态代码生成机制
定位交互查询
clickhouse
clickhouse使用列式存储,代码编译
存储采用merge tree
主键不是唯一的
定位维度较低的实时查询
Doris
MOLAP 多维
多维型,预计算
例如kylin,druid
multi-dimensional
多维型OLAP,通过摄入数据时对原始明细数据进行预聚合加工处理,然后通过预聚合数据进行数据查询,比如kylin、druid等OLAP引擎。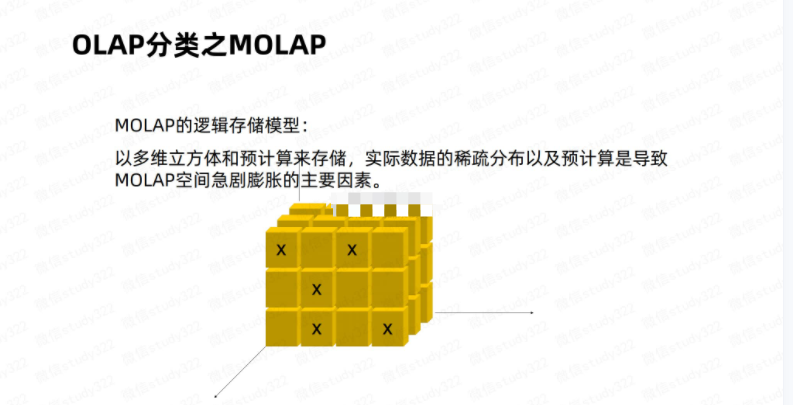
MOLAP架构
数据直接加载到olap server中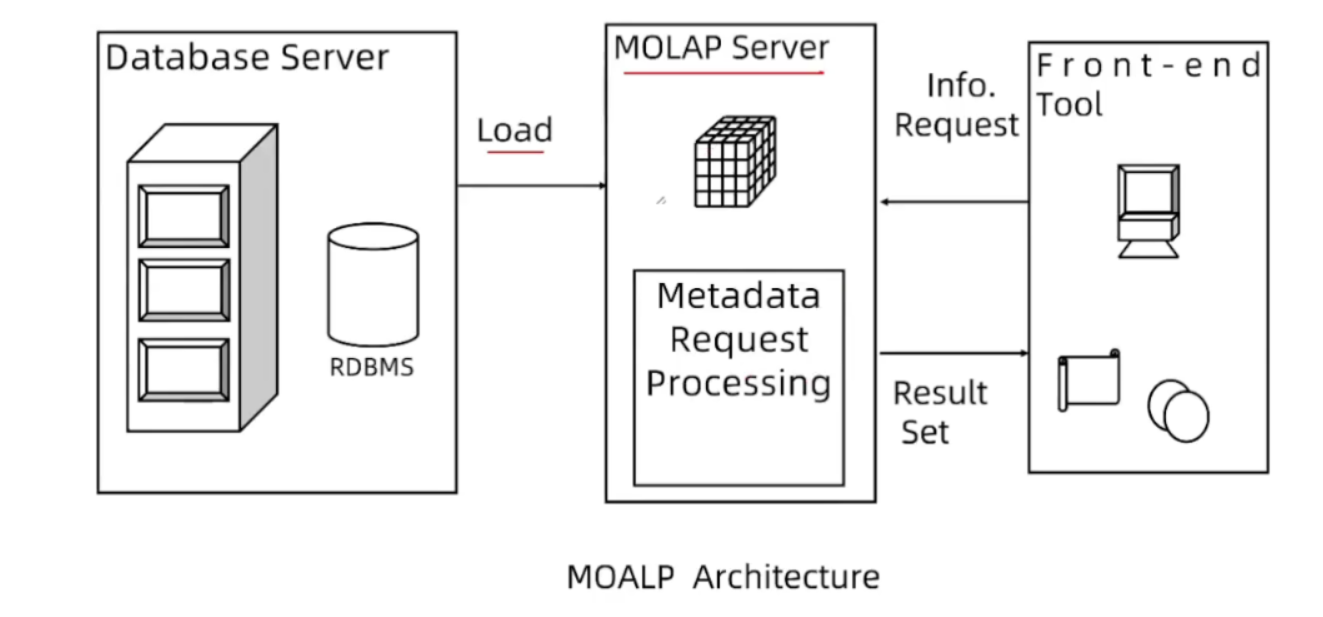
典型的产品
kylin
支持kafka、hive、rdbms查询
将完全命中的cube聚合查询转化为简单的select操作。底层存储配合HBase但高吞吐和低延时,可以达到毫秒级的查询性能。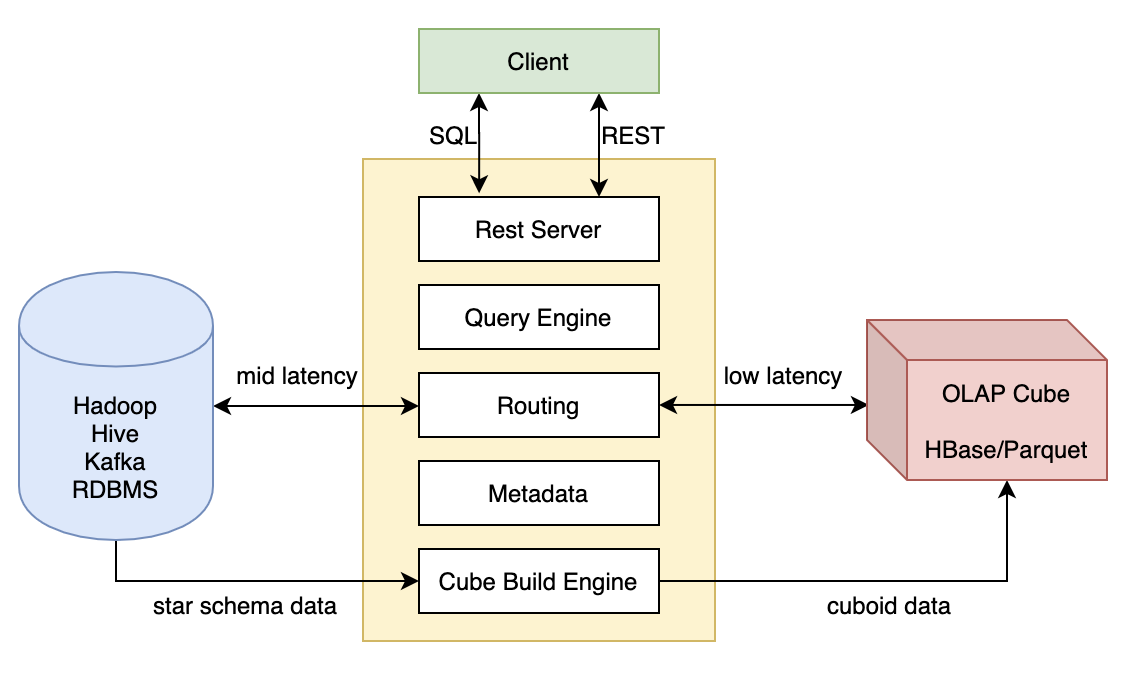
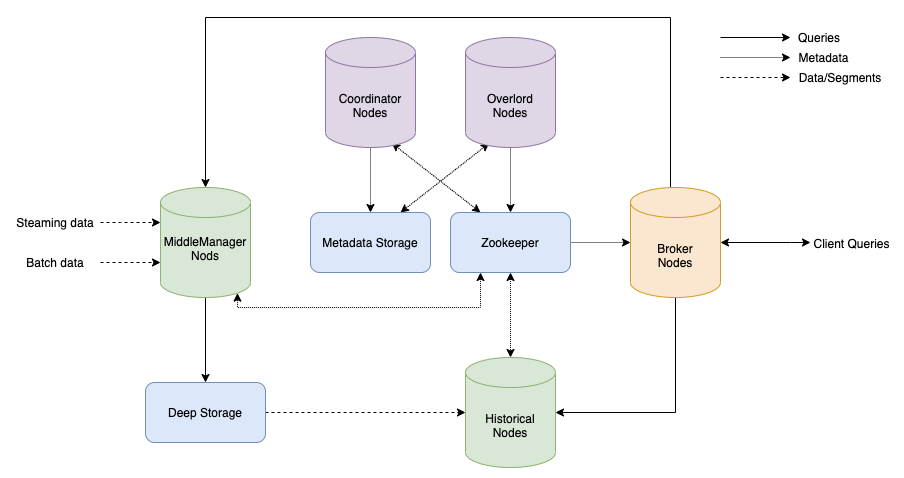
druid
通过位图索引、字典编码、预聚合计算实现的
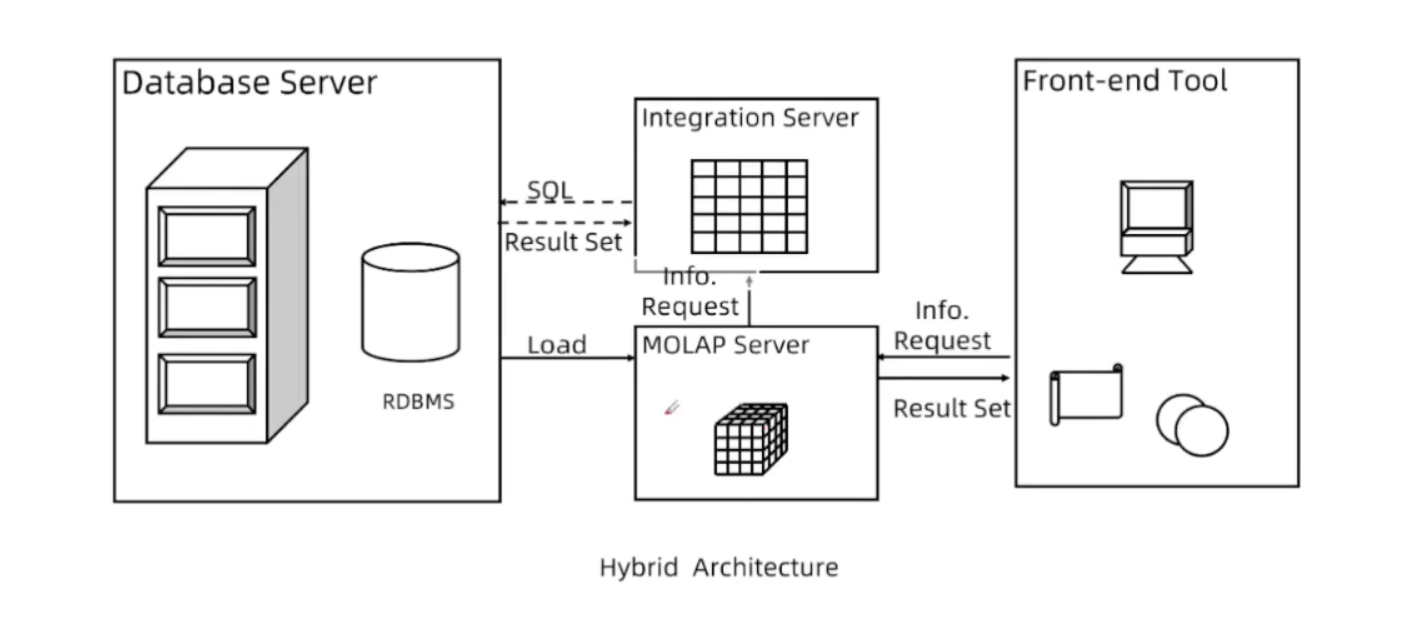
HOLAP 混合型
即混合型的,细节数据以ROLAP存放,聚合数据以MOLAP存放,相对灵活和高效ciao
HOLAP架构
结合了ROLAP和MOLAP的优点。

若有收获,就点个赞吧
0 人点赞
