当程序的数据量太大,一台计算机无法进行存储的情况下,就需要使用分布式文件系统。
程序本身拥有大量数据或者程序每天不断产生大量数据。

分布式文件系统可以将多个文件系统通过网络连接起来,组成一个文件系统网络。可以支持超大文件、提高容错性能、提高文件的访问效率。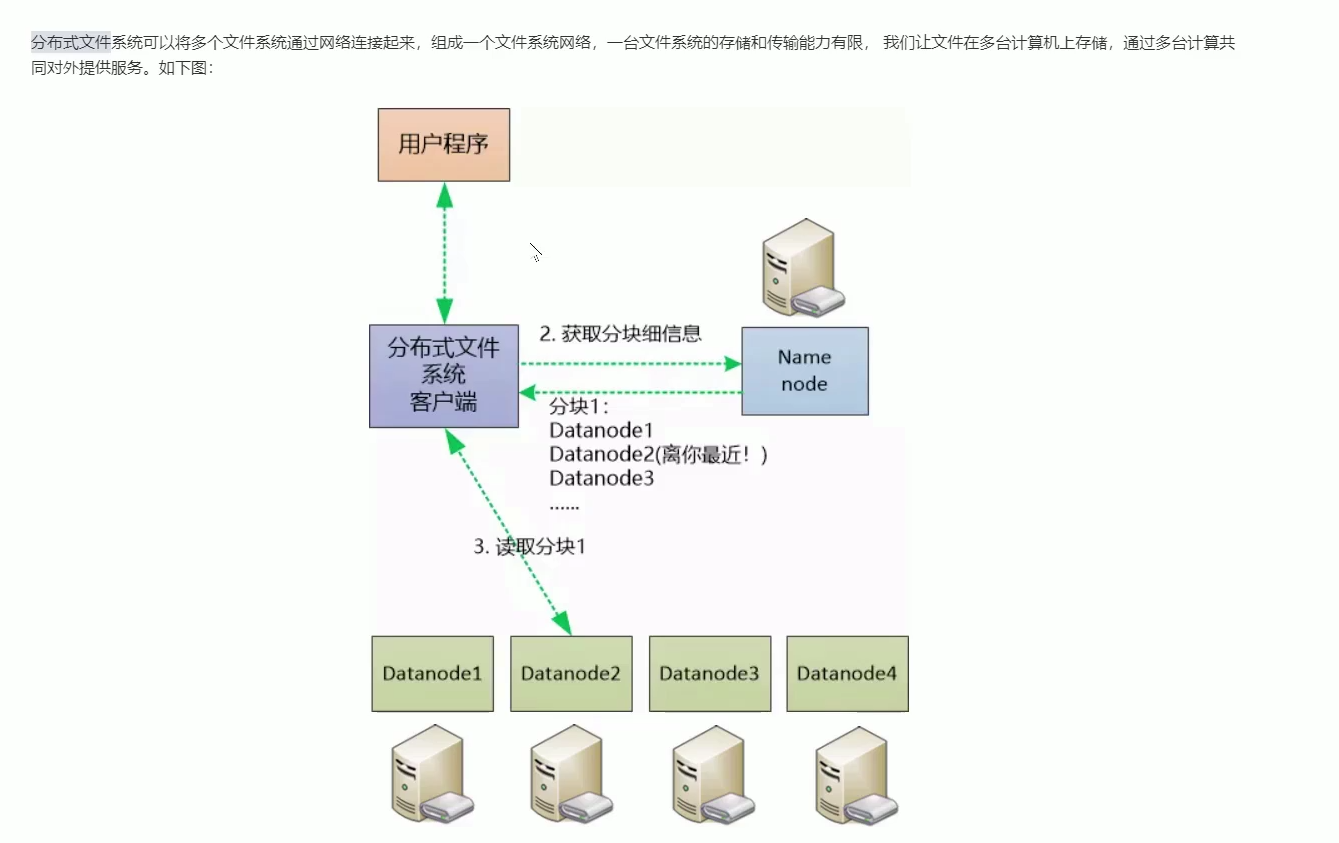
元数据
对于没有元数据中心的分布式文件系统,使用的哈希取模的方法。
文件a目录上存储一个拓展信息,当时存a的N值,N好像是代表在哪个节点;
一致性哈希,数据变多了之后,数据不均衡,有热点问题。需要把数据搬移到附近节点上去,然后把N值删除。
常见分布式文件系统
GFS
Google FIle System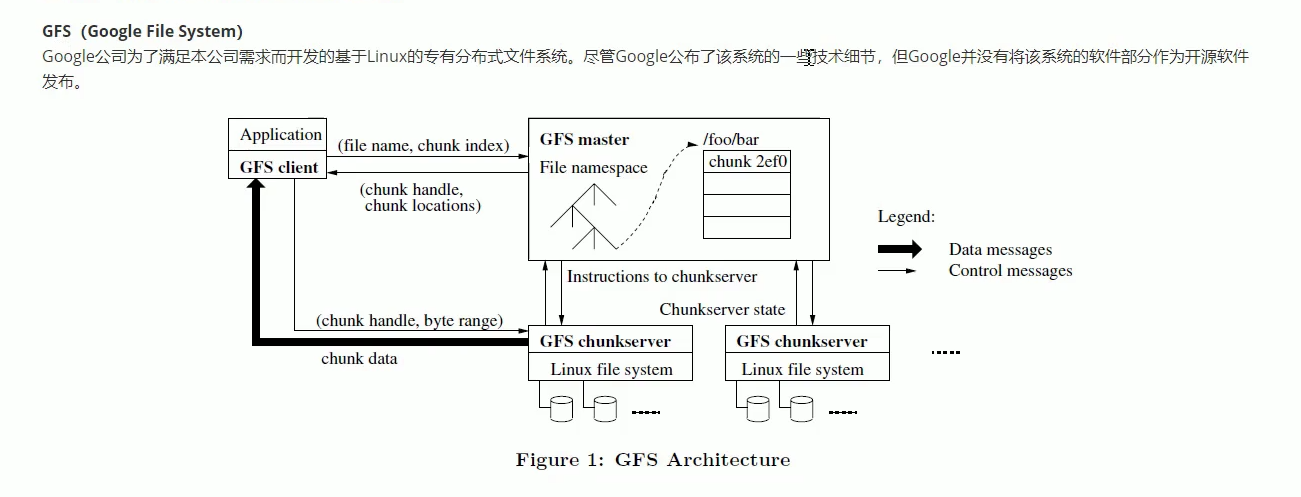
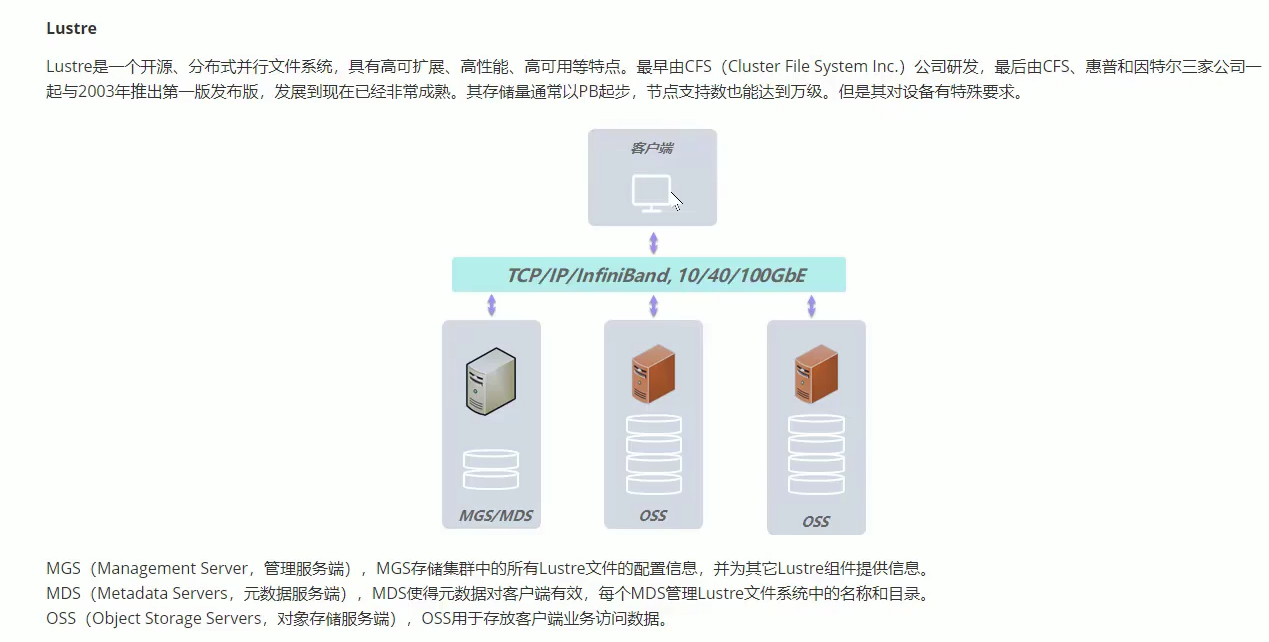
Lusture
FastDFS
C语言开发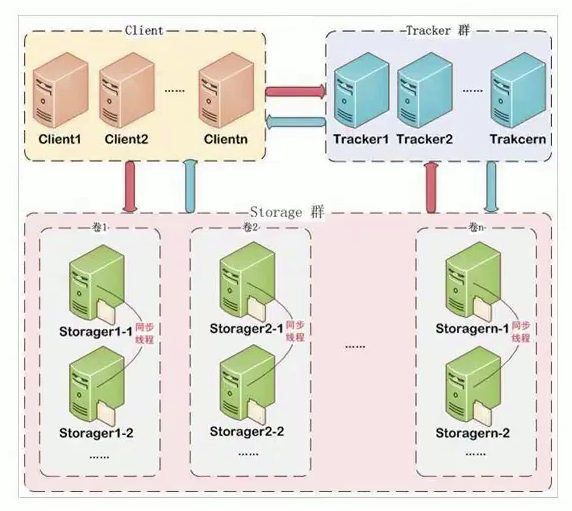
文件系统发展史
网络文件系统(80年代) — >共享SAN —> 对象存储
分布式系统的问题
CAP理论
一致性 Consistency
可用性 Avaliability
分区容错性 Partition tolerance
CA
优先保证一致性和可用性,放弃分区容错,这也意味着系统的扩展性,系统不再是分布式的,有违设计的初衷。
CP
优先保证一致性和分区容错性,放弃可用性。
在数据一致性要求比较高的场合(例如zookeeper),
AP
有限保证可用性和分区容错性,放弃一致性。NoSQL中的Cassandra就是这种架构,和CP一样,放弃一致性不是不保证一致性,而是最终一致,逐渐变得一致。

若有收获,就点个赞吧
0 人点赞
