Google的三篇论文
GFS,MapReduce,BigTable,号称三驾马车。
SOSP2003:The Google File System;
ODSI2004:MapReduce: Simplifed Data Processing on Large Clusters;
ODSI2006:Bigtable: A Distributed Storage System for Structured Data。
GFS
分为master和trunk server,其中master有同步复制的节点backup master和异步复制的节点shadow master。
backup master会和master保持一致,checkpoint写也一致,只有master和backup master都写完才算写成功。如果master挂掉backup master可以转正,但是在转正的期间服务不可用,此时shadow master就可以提供读服务,虽然会有很低概率的读旧数据,shadow master不可以转正。
对海量数据进行数据分析处理,得到有价值的信息。
处理流程:获取数据、处理数据、展示结果。
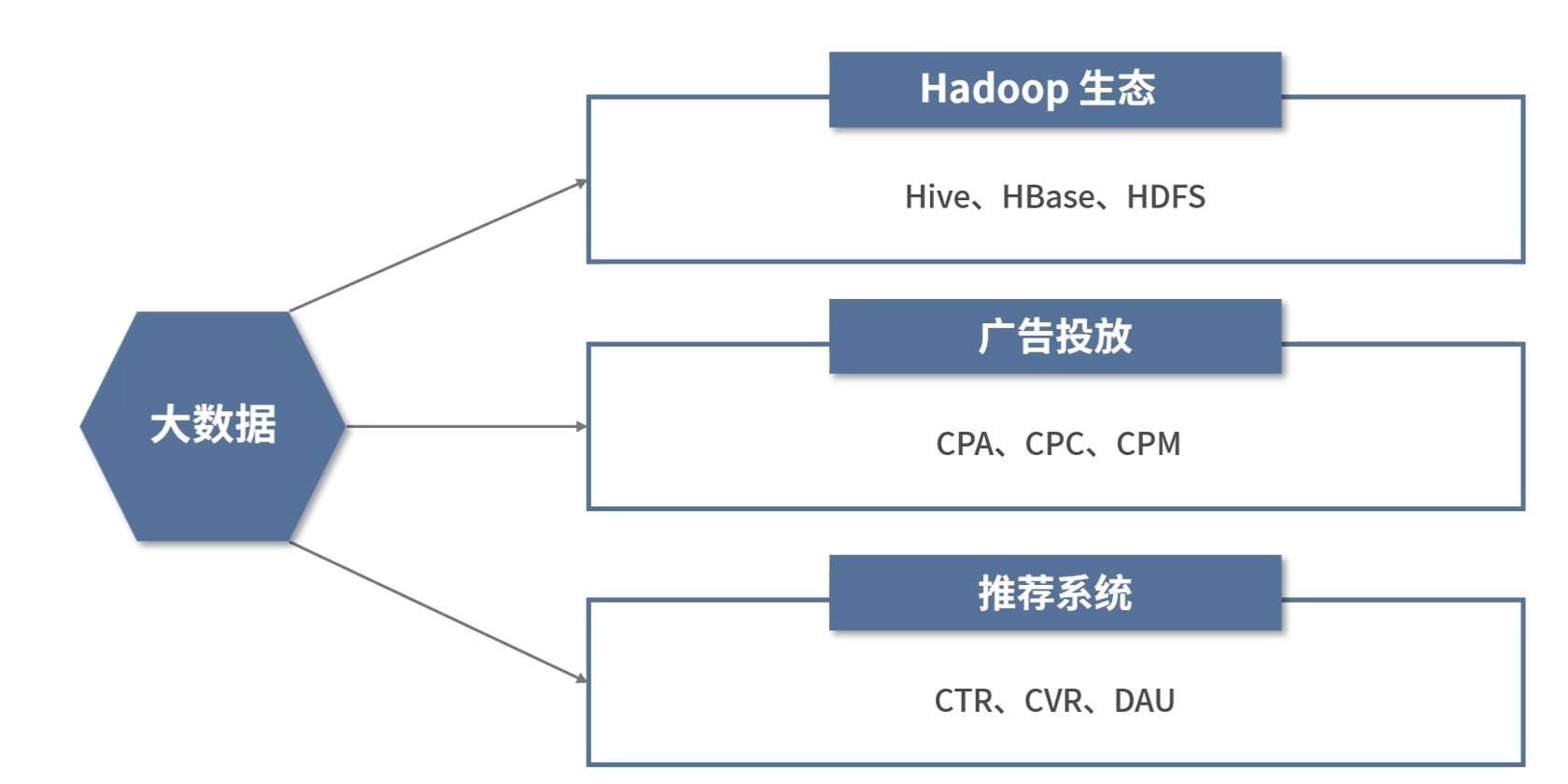
大数据 != Hadoop
严格意义上说,如果一个组织的大数据架构基础越薄弱,对于大数据工程师的需求就会越大,但是当这个组织的大数据架构愈加趋于完善与成熟,对于数据分析师的需求就会变大。
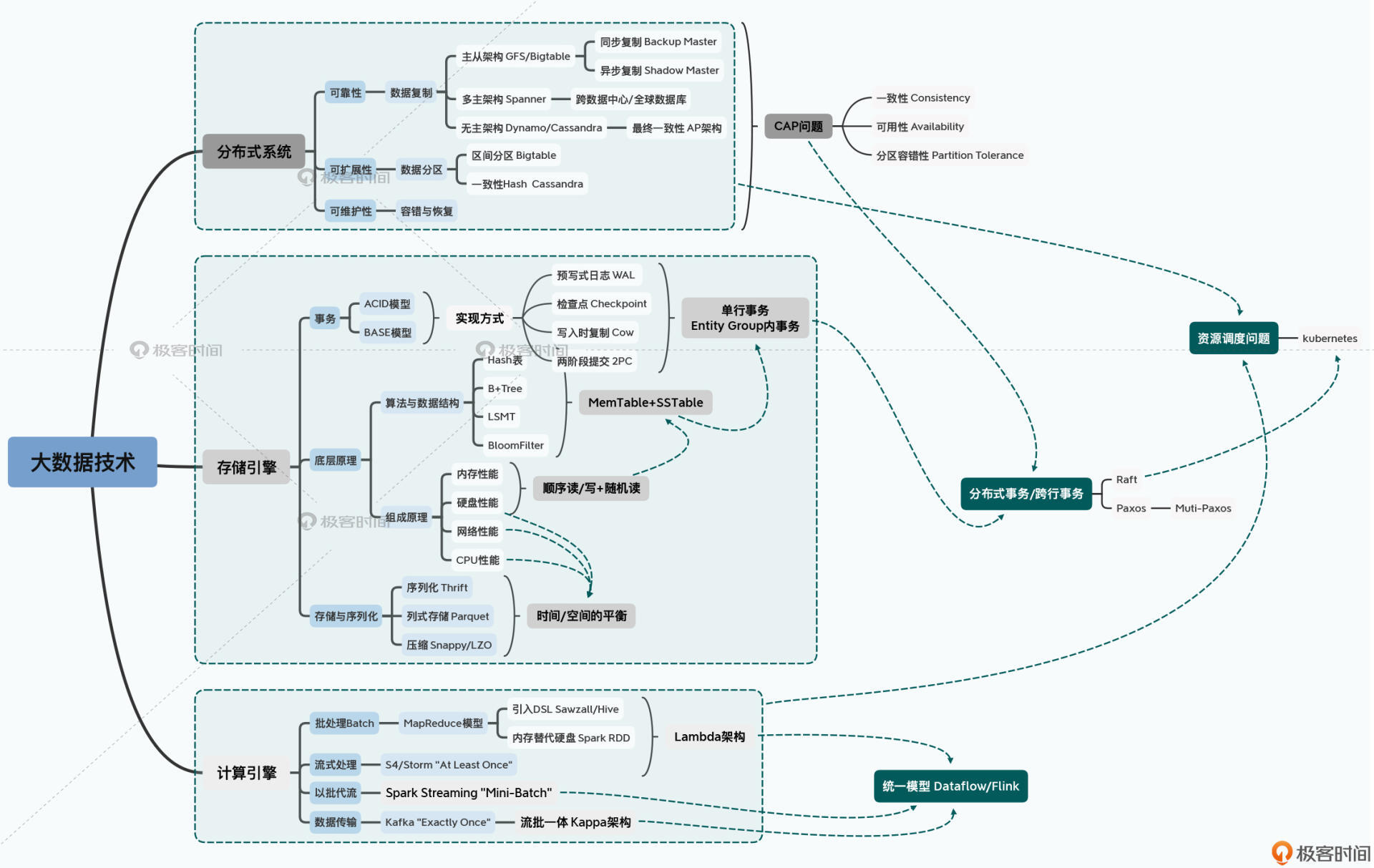
分布式存储
HDFS
分布式计算
MapReduce 编程模型,主要实现有Hadoop的MapReduce计算框架,即MapReduce即是模型也是具体实现
对于spark基于rdd的计算,Hadoop像是面向过程,spark是面向对象。
调度
yarn框架
离线计算架构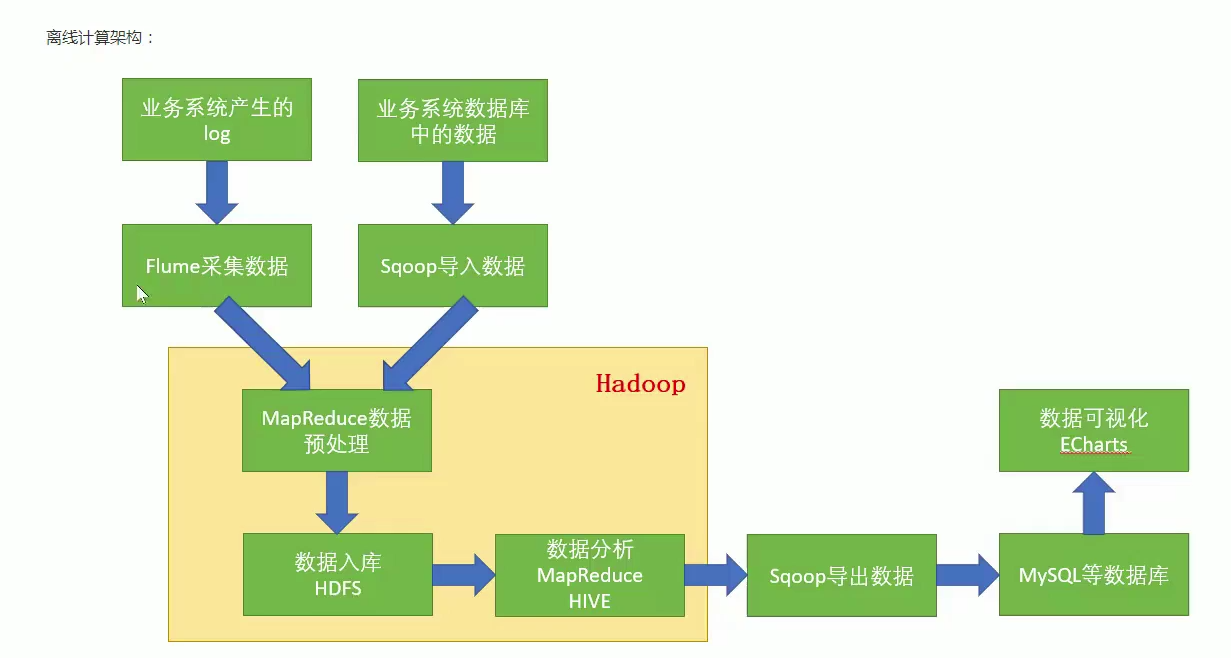
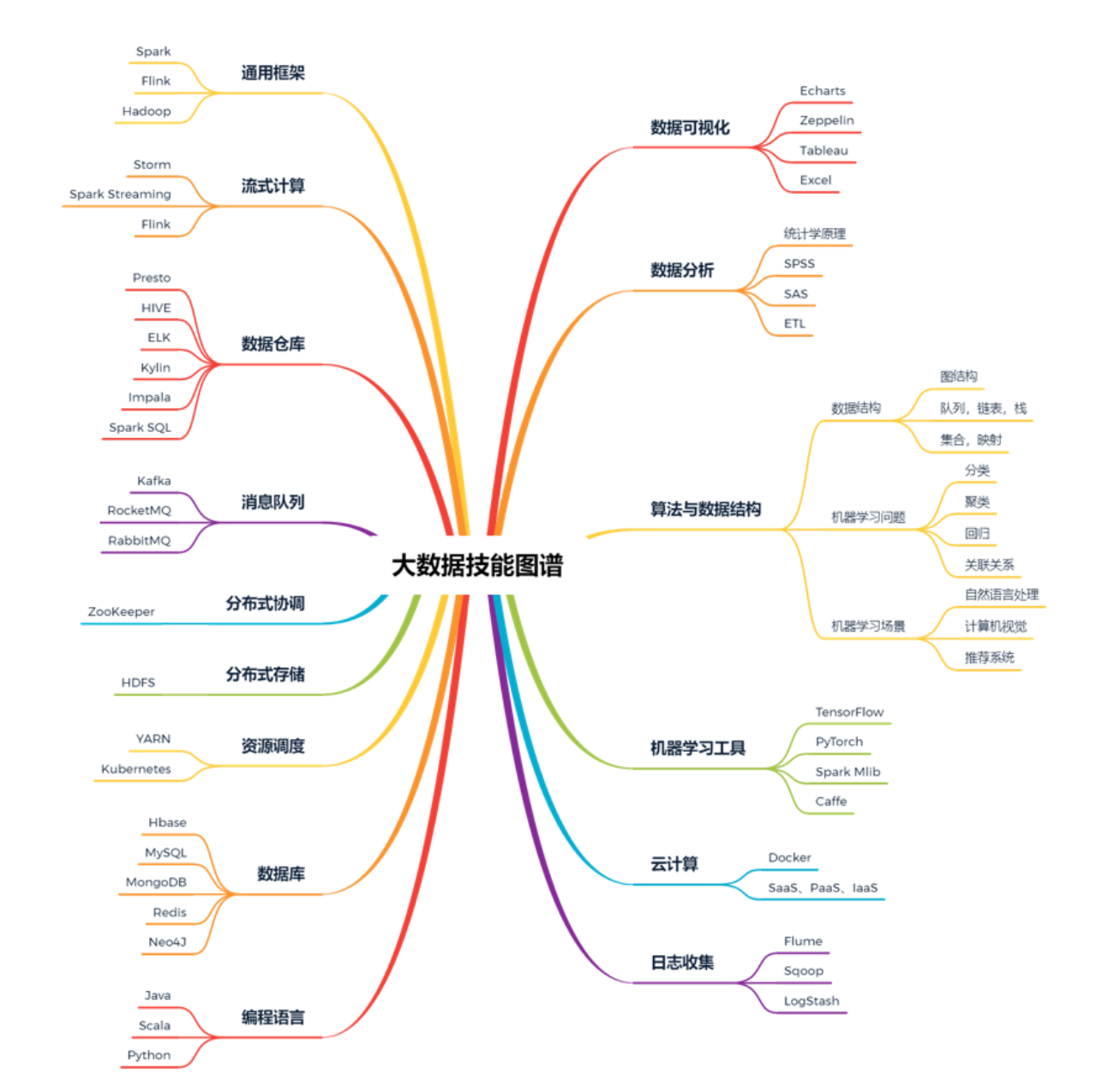
知识图谱
工作方向
架构方向

开发方向
熟悉工具的用法

数据挖掘与分析方向


若有收获,就点个赞吧
0 人点赞
