以上传功能为例做的一次分享,目标在于帮助团队小伙伴能提升一下写工具模块的能力 19年做的一次团队分享草稿,一直忘了整理。。。汗。。
背景
前段时间上传问题报的很多,百三的错误率,开始搞备用域名,重试cdn策略,然后腾讯云这边有给很大优惠,需要支持多服务商,像是阿里云 + 腾讯云 + else,产品这边又提出优化用户体验,解决弹窗说明文字英文的问题,总进度条….
其他的其实都还好解决,上传在去年重构过一次,扩展性还不错,但是进度条这个问题太难了,微信api不具备管理器的模式, 如下: 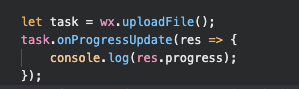
没办法做统一管理,如果在原来的基础上包个盒子(manager)重试逻辑有比较复杂,既然存在这么多问题不如从新给出一套解决方案
在解决该问题的过程发现一些共性的问题,在这里进行一些杂乱整理
梳理功能
如果你要开始写模块,我个人推荐不要第一时间进行coding,而是想这个模块到底要解决哪些问题,为了解决这个问题需要什么功能,并且尽可能罗列出风险和可能会遇到的挑战
先要想清楚,这样我们根据需求去拆解具体函数的时候,整个流程是非常顺的,避免不必要的返工,尤其在设计核心代码的时候,
以上传为例,支持并发控制的代码和顺序执行的代码在设计之初因为需要压缩开发成本整体架构会大相径庭,如同画人像,头骨结构画的不扎实,后续再怎么修改,上色都如同”贴肉“一般,毫无美感可言,最后唯一能做的只有调整心态后重新拉一张白纸进行构图
核心功能
面向接口编程
设计sdk的时候,首先要看给谁用,怎么用,怎么好用 ?
给谁用?
当前case自然是给我们团队内部来跑,我们很长一段时间都在使用wx.$upload,所以这个api会尽量贴合该形态,不至于太过标新立异(非必要情况下), 尽量避免造成额外的学习成本
所以我这边首先给出了大概这样的一个调用形式,只对外提供一个upload方法:
/** 获取基础配置传入参数 */type TInitOpts = {/** 文件队列 */files: TFiles,/** 云服务类型 */cloudType?: TCloudType,/** 业务类型 */businessType?: TBusiness,/** 最大并发数 */maxLimitAsync?: number,/** 监听进度更新 */onProgressUpdate?: TOnProgressUpdate,}/** 新的上传函数 */let [err, result] = await upload({files: [],cloudType: '',onProgressUpdat(res) {console.log(res);}});
对比旧版:
let [err, result] = await wx.$upload({src: path,type,cloudType: this.data.cloudType});
在使用层面上没有明显差异,而且有着typescript的类型提示,可以比较平滑的过度 
怎么用?
需要考虑你这个库到底需要哪些功能,例如我们有进度监听自然需要回调事件,有上传能力就需要获取资源地址,资源类型
怎么好用?
再怎么用的环节,我们知道需要有哪些功能,那么这些需要使用者和库之间是靠api连接的,我们就需要考虑怎么用更友好的方式提供api给使用者,

// 使用原生跳转的时候,不可避免的会进行字符串拼接,如果携带参数特别多的情况下就非常难。。wx.navigateTo({url: '/pages/habit_detail/habit_detail?name=' + this.data.name + '&sex=' + this.data.sex})// 优化后wx.$href({url: '/pages/habit_detail/habit_detail'data: {name: this.data.name,sex: this.data.sex}});
构建项目结构
已知只对外开放一个upload接口,那么剩下就可以寻找出生地,个人习惯而言文件夹下会有个入口文index.ts,用来导出对外接口,然后单独拉一个core文件夹放核心代码,创建runtime.ts文件作为启动文件,在runtime.ts中导出api “upload” ,之后所有的coding就可以在runtime.ts中进行即可(有点类似于koa的app.js 文件)
目录结构: 
文件代码:
/** index.ts */export {upload} from "./core/runtime"/** core/runtime.ts */export async function upload(opts: TInitOpts) {// anything}
除了core存放核心代码外,自然还有其他文件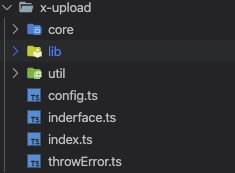
core 核心代码
lib 扩展库
util 工具函数
config.ts 配置文件
interface.ts 接口文件
index.ts 入口文件
throwError.ts 错误日志模块
梳理功能流程
整个上传大概分为四个大的部分,输入,信息加载,上传,输出,
可以看下图大概成一个树状结构,根据不同的模块,还可以细拆,例如信息加载,里面有用户信息,文件信息,时间信息…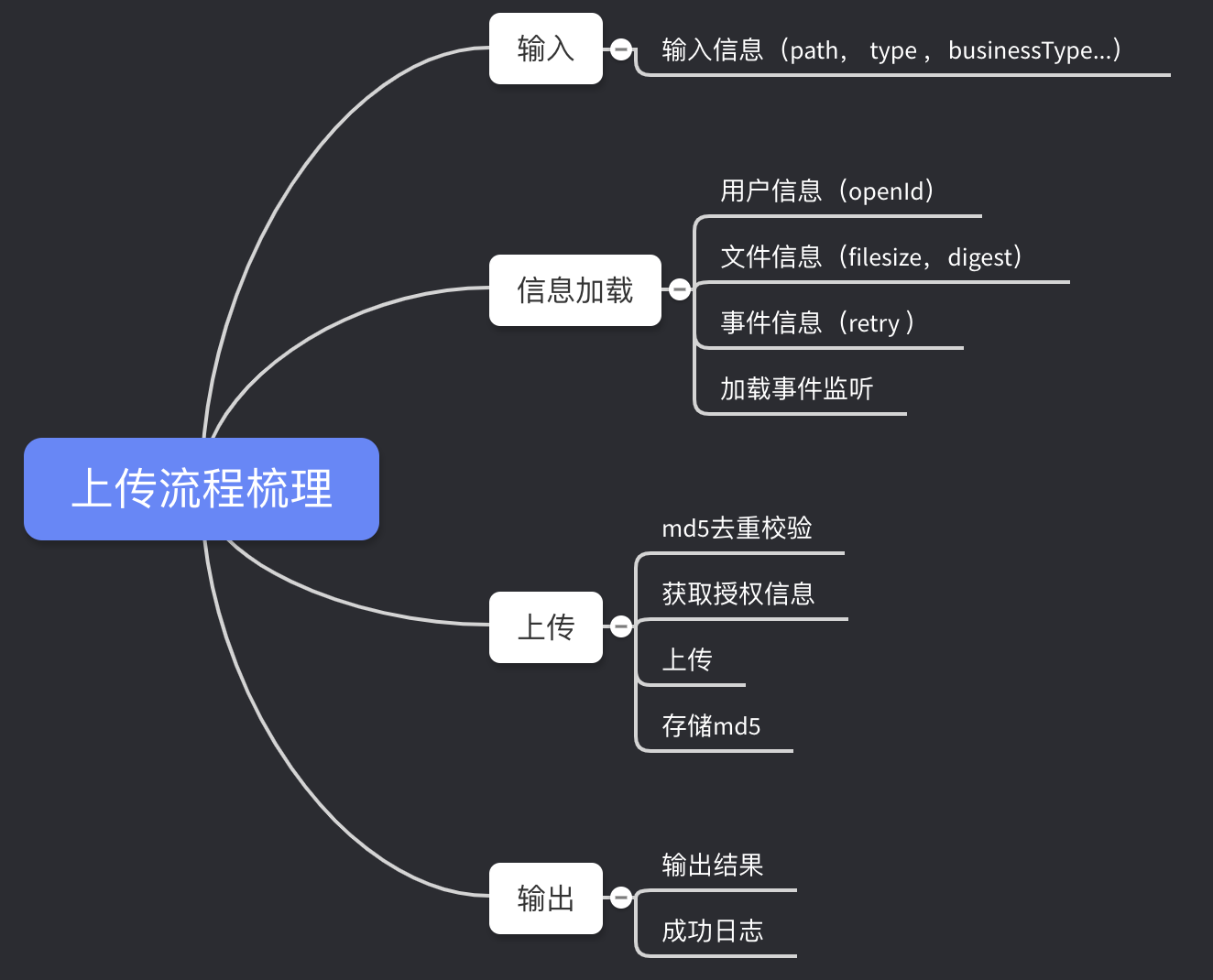
知道了要执行的模块,那就可以先根据模块定义函数了,如下,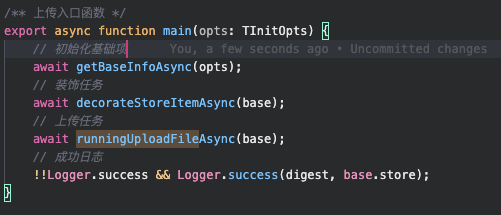
剩下的事情不过是进行函数填充罢了(即怎么让函数达成想要的预期),实现的过程五花八门,是自己撸,还是第三方库,里面用了什么写法本质上并不在设计范围内,只需要关注输入和输出
ps:虽然不关注具体实现,但是coding的时候必须要遵循一定原则
梳理易变逻辑
这里的易变逻辑,指的是容易产生变动/扩展/修改的逻辑,把这些逻辑单独抽象,可以有效避免进行修改时对核心逻辑进行变动,缩小影响范围
在x-upload里因为一些原因的问题,上传模块处于时刻变动(cdn,重试,埋点…)状态,没办法确定当前上传模块的状态,所以按照”开闭原则”, 我将上传模块单独抽象成一个模块,在core核心代码目录仅保持依赖调用
这样,我只需要修改Lib抽象,而不需要再去管runningUploadFileAsync函数内是否需要变更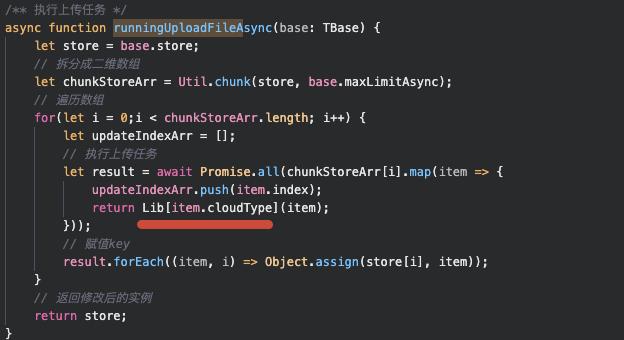
函数该怎么写
设计函数之单一性原则
函数设计的过程中,应秉承单一性原则,一个函数永远只做一件事,
我认为可以把功能认为是一个树状结构,函数为节点,一个大的功能项是由多个函数,多个层级函数组合而成,
以上传模块为例,首先有三个子函数,去重,签名,上传,再看签名校验函数,同样有三个子函数,当然实际开发中大部分情况下不会有太多的包含关系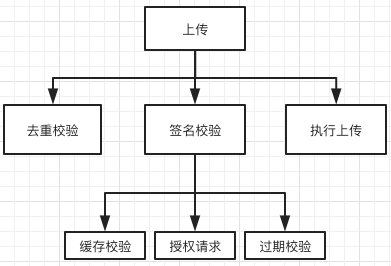
但是秉承单一性原则,无论是后期维护/修改,还是避免二义性在后续项目维护中会有很大的帮助
设计函数之副作用
在计算机科学中,函数副作用指当调用函数时,除了返回函数值之外,还对主调用函数产生附加的影响。 例如修改全局变量(函数外的变量),修改参数或改变外部存储
本质上在设计功能的过程中应该避免函数副作用,在函数中操作全局变量等危险操作,因为没有统一的输入输出,会导致数据流会乱,出现一些预料外的问题,对维护来说有很大的阻碍。
那么怎么修改全局变量呢?尽量的解耦,我这边把函数分为两类,
- 纯函数,只关注输入输出,对外部没有修改行为,保持行为可预测
- 功能函数,关注功能实现,且可以外部行为进行修改
功能函数除了需要单独包装外,
还有一条守则就是功能函数必须为顶层函数(如果按树状结构来解释的话),功能函数只能依赖纯函数,纯函数不能依赖功能函数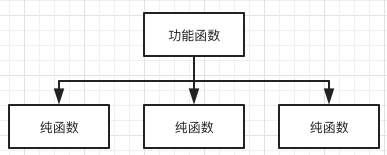
容易遇到的问题:
// 函数的参数传递其实是传递的指针,最终都会指向person这个对象,在editName里修改实参的属性// 等同于直接对person做修改(产生了副作用)let person = {name: 'dan'}function editName(opts) {opts.name = 'ming';}editName(person); // {name: 'ming'}
设计函数之命名规范
这个的话仁者见仁,智者见智,我这边陈述我自己的命名规则
函数驼峰命名,构造函数首字母大写 + 驼峰
function getBaseInfoAsync() {}
函数名尽量完整描述功能,
普通函数动词 + 名次,如果是构造函数/模块,函数名要基于该模块,例如:
import request from './vendor/x-request';// x-point为埋点模块,track翻译为跟踪,算比较贴切request.get();// 如果是纯函数的化会变成完整函数名requestMethodGet();
回调、钩子函数用「介词」开头,或用「动词的现在完成时态」
let person = {beforeDie(){},afterDie(){},// 或者willDie(){}}let component = {beforeCreate(){},created(){},beforeMount(){},mounted(){},beforeUpdate(){}}button.addEventListener('click', onButtonClick)
还有及物动词和不及物动词的区分
run() {} // 不给物动词drinkWater() {} // 及物动词eat(foo){} // 及物动词加参数(参数是名词)
如果是Promise函数,一定要给Async后缀标明是异步函数,例如:
async function getBaseInfoAsync() {}async function main() {await getBaseInfoAsync();}
设计函数之异步流程控制
虽然我们已经在用async/await来处理异步问题,使代码看上去是同步代码,
但是处理错误是一个大问题,像是promise的话会有一个catch函数去接链式调用中的错误,但是async/await只能用try/catch捕获,如果按照这样的写法,代码可能是这样的:
// 每个函数一个try/catch, 丑的不行...export async function main(opts) {let base = {}try{base = await getBaseInfoAsync(opts);} catch(e) {console.error(e);}try {base.store = await decorateStoreItemAsync(base);} catch(e) {console.error(e);}}
当然我们也可以放在一个try/catch中,但是我们需要去思考怎么在catch中区分不同的函数(虽然可以利用new Error() 拿到函数名进行判断,但毕竟是硬编码,有点难受)
export async function main(opts) {let base = {}try{base = await getBaseInfoAsync(opts);base.store = await decorateStoreItemAsync(base);} catch(e) {switch(e) {case 'getBaseInfoAsync': console.log(1);case 'getBaseInfoAsync': console.log(2);}}}
那么怎么去解决这个问题呢 ?
大概有两种方式,第一种通过to.js 进行封装,仿照go得写发做if判断,例如:
let err, result;[err, result] = await getBaseInfoAsync(opts);if(err) {return err;}[err, result] = await decorateStoreItemAsync(base);if(err) {return err;}
看上去很简洁,格式也很cool,但是也有点问题,一个是需要单独去做包装,另一个是if条件如果整个异步流程过长的情况下会非常啰嗦,但是如果不判断的话又会出现预期外的错误,很难受
我这边经过多种尝试,最终还是选定用try/catch做全局包装,但是为了避免上述的问题,决定对抛出错误进行统一格式处理,基于Typescript可以很好地补足格式难以统一的问题
这样的好处在于:
- 能够区分出到底是哪一步出现的错误
- 有预期内的错误处理
- 可以携带更多的数据信息
- 可以在流程中任意中断当前执行状态
```typescript
// 定义格式错误
export type TThrowError = {
code: ECode,
data?: TItemCtx,
errMsg: string
};
// 异步函数的时候使用Promise.reject抛出
function getBaseInfoAsync() {
}) } // 同步函数的时候使用throw抛出 function getBaseInfoSync() {// ....代码return Promise.reject(<TThrowError>{code: 0,data: {}errMsg: 'getBaseInfoAsync失败'
} }// ....代码throw <TThrowError>{code: 0,data: {}errMsg: 'getBaseInfoSync失败'
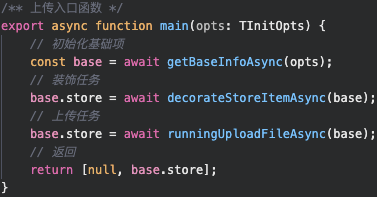
// 主函数
export async function main(opts) {
let base = {}
try{
base = await getBaseInfoAsync(opts);
base.store = await decorateStoreItemAsync(base);
} catch(e:TThrowError) {
logger.error(e);
}
}
```
常见问题解决套路
事件通知
观察者模式/订阅模式
函数限流/限速
当函数触发间隔太快怎么办(如页面滑动),节流函数/防抖
创建重复对象
工厂模式
防止实例被重复创建
单例模式
修改对象引用问题
深拷贝
并发控制
状态锁 + 缓存队列
解耦流程控制
职责链/命令模式
封装私有变量
闭包
分割业务控制和底层服务
代理模式
总结
对库的编写,个人认为大致为下面五个环节: 结构确定,功能拆解,函数拆解,功能点实现,逻辑整合
五个环节所对应的能力:
- 确定结构 -> 发掘/发现需求
- 拆解函数/拆解功能 -> 流程梳理 + 业务拆解
- 功能点实现 -> 解决具体问题的能力
- 逻辑整合 -> 架构能力
如果前面四点能做的很好,相信这会是一个能实现要求,且可读性非常高的库,已经达到了可用的标准。
逻辑整合这一步到底是干什么的呢?
它主要影响到代码的维护成本,这里的话就要看这个库的性质是什么样的了,如果是短平快要求短期内能解决部分问题,或者已确定后续不会在进行维护的话,我个人认为还是不要在这一步浪费更多的时间(避免过度设计)
在对于库的编写上,我认为是有固定套路和解法的,就像1 + 1 = 2,如果足够熟悉流程和各种解决套路,能够造成实现阻碍反而不在coding上,而是业务环境,实现成本之上。
虽然如此,但是不断丰富自身是声音外放的基石和保障,走好脚下路,愿余下时间与君共勉
扩展阅读
面向对象五大原则
“单一职责原则”:
一个类/方法,只有一个引起它变化的原因,且只做一件事
“开放封闭原则”:
对扩展开放,对修改封闭
“里氏替换原则”:
子类可以扩展父类的功能,但不能改变父类原有的功能
“依赖倒置原则”:
A.高层次的模块不应该依赖于低层次的模块,他们都应该依赖于抽象。
B.抽象不应该依赖于具体,具体应该依赖于抽象。
“接口分离原则”:
接口不是为特定的客户类服务,而服务了多个不同的客户类。胖接口使本应该被隔离的客户类之间产生了耦合
“最少知识原则”:
优点:遵守 Law of Demeter 将降低模块间的耦合,提升了软件的可维护性和可重用性。a.b.method()经历了两个点,为错误
缺点:应用 Law of Demeter 可能会导致不得不在类中设计出很多用于中转的包装方法(Wrapper Method),这会提升类设计的复杂度

若有收获,就点个赞吧
0 人点赞
