1.集合的概念
什么是集合
概念: 对象的容器,定义了对多个对象进行操作的常用方法,可以实现数组的常见操作。
和数组的区别
- 数组长度固定,集合长度不固定
- 数组可以存储基本类型和引用类型,集合只能存储引用类型
- 基本类型(8大),引用类型(除了8大类型以外)
- java.util.*下面
2.Collection接口
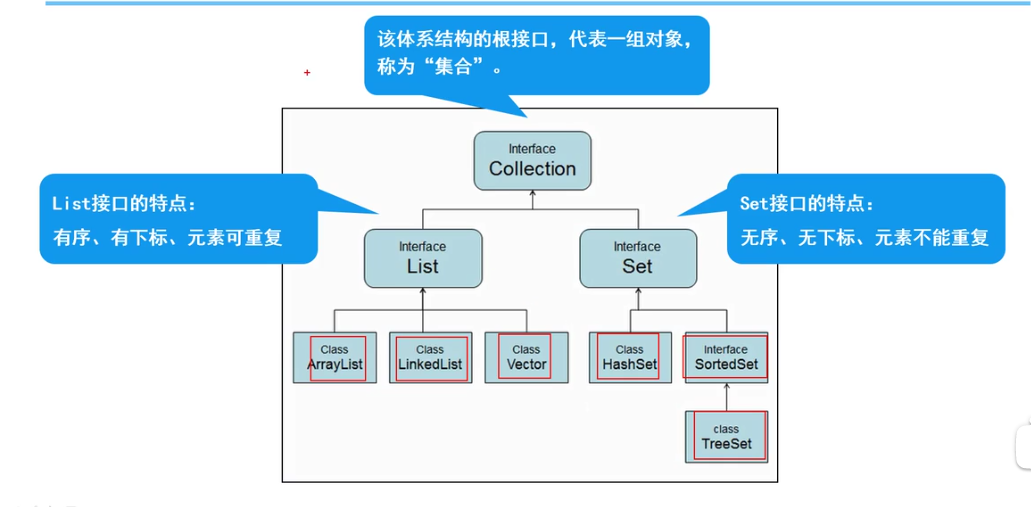
- Collection,List,Set都是接口需要下面的实现类进行实现之后才可调用。
- Collection 父接口:
- 特点:代表一组任意类型的对象,无序,无下标,不能重复
 ```java
/*
```java
/*- @Descripttion: 针对集合框架进行复习
- @version:
- @Author: Addicated
- @Date: 2020-11-03 21:46:41
- @LastEditors: Addicated
- @LastEditTime: 2020-11-03 22:10:00 */ package review.Day07;
- 特点:代表一组任意类型的对象,无序,无下标,不能重复
import java.util.ArrayList; import java.util.Collection; import java.util.Iterator;
public class CollectionTest {
public static void main(String[] args) {// 创建集合// 父类引用指向子类对象 arrayList--AbstractList--AbstractCollection--CollectionCollection collection = new ArrayList();// 添加元素collection.add("addicated");collection.add("xtzg123");collection.add("zhuoyi");collection.add("sb");System.out.println(collection.size());System.out.println(collection);// 删除元素collection.remove("addicated");System.out.println(collection);// 遍历元素 重点// 1,使用增强for循环进行遍历for (Object object : collection) {System.out.println(object);}// 2,使用迭代器进行遍历 专门用来遍历集合的一种方式Iterator it = collection.iterator();// hasNext() 有没有下一个元素// next() 获取下一个元素// remove() 删除一个元素while (it.hasNext()) {System.out.println(it.next());// collection 在遍历的时候是不允许修改元素的it.remove(); // 使用迭代器的删除方法可以执行}// 判断collection.contains(o); // 包含}
} ————-对象类型操作 /*
- @Descripttion: 针对集合框架进行复习
- @version:
- @Author: Addicated
- @Date: 2020-11-03 21:46:41
- @LastEditors: Addicated
- @LastEditTime: 2020-11-03 22:23:15 */ package review.Day07;
import java.util.ArrayList; import java.util.Collection; import java.util.Iterator;
public class CollectionTest {
public static void main(String[] args) {Collection collection = new ArrayList<>();// 添加学生数据Student s1 =new Student("阿迪",12);Student s2 =new Student("阿迪",12);Student s3 =new Student("阿迪",12);Student s4 =new Student("阿迪",12);// 1 添加元素到collectioncollection.add(s1);collection.add(s2);collection.add(s3);collection.add(s4);System.out.println(collection);// TODO 2 删除 ,使用remove方法collection.remove(s1);// 遍历,// 增强for,或者 迭代器 iterator()}
}
class Student{ int age; String name; public int getAge() { return age; } public void setAge(int age) { this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } @Override public String toString() { return “Student [age=” + age + “, name=” + name + “]”; } public Student( String name,int age) { this.age = age; this.name = name; }
}
<a name="3gisO"></a># 3.List接口与实现类<a name="i171B"></a>## List子接口- 特点:有序,有下标(可用for循环),元素可以重复- ```java/** @Descripttion:* @version:* @Author: Addicated* @Date: 2020-11-04 08:24:34* @LastEditors: Addicated* @LastEditTime: 2020-11-04 08:38:55*/package review.Day07;import java.util.ArrayList;import java.util.Iterator;import java.util.List;import java.util.ListIterator;// List子接口的使用// 有序有下标,元素可重复public class ListTest {// 创建public static void main(String[] args) {List list = new ArrayList<>();// 添加元素list.add("huawei");list.add(1);list.add("ali");list.add("niubi");System.out.println("元素个数" + list.size());System.out.println(list.toString());// 元素删除list.remove(1);System.out.println(list.toString());// 遍历 传统for循环可遍历for (int i = 0; i < list.size(); i++) {System.out.println(list.get(i));}// 增强for循环可遍历for (Object object : list) {System.out.println(object);}// 迭代器 同样可以Iterator it = list.iterator();while (it.hasNext()) {System.out.println(it.next());}// 使用列表迭代器// listIterator 可以向前或者向后遍历,添加删除元素ListIterator listIterator = list.listIterator();while (listIterator.hasNext()) {System.out.println(listIterator.nextIndex());System.out.println(listIterator.next());}// 从后向前进行遍历while (listIterator.hasPrevious()) {System.out.println(listIterator.previousIndex() + "+" + listIterator.previous());}// 判断list.contains("o");list.isEmpty();// 获取位置下标list.indexOf("huawei");}}// 往list添加数据的时候实际上是完成了一个自动装箱的操作// 删除元素List lsit = new ArrayList<>();list.add(20);list.remove(new Integer(20));// 转换为装箱之后的integer类型可以删除 可以使用new Integer的方式删除// 是因为整数缓冲 todo+1 后续调查 https://blog.csdn.net/w372426096/article/details/80660851list.remove((object)20); // 强制转换为obj类型// 补充方法subList 含头不含尾 返回为一个listlist.subList(1,3);
ArrayList(重点)
- 底层是数组结构实现,查询快,增删慢
- JDK1.2版本加入,运行效率快,线程不安全
原码分析
- DEFAULT_CAPACITY=10 默认容量为10 注意:如果没有向集合中添加任何元素时,容量为0,添加一个元素则通过原码中的一系列操作变为10
10之后每次扩容大小是1.5倍
/*** Constructs an empty list with an initial capacity of ten.这里是ArrayList的无参构造方法*/public ArrayList() {this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;}
elementData 用来存放元素的数组
- SIZE 实际的元素个数
add的原码分析 ```java /**
- Appends the specified element to the end of this list. *
- @param e element to be appended to this list
- @return true (as specified by {@link Collection#add}) */ public boolean add(E e) { ensureCapacityInternal(size + 1); // Increments modCount!! elementData[size++] = e; return true; } // 首先判断数组中数据是否为空,为空,返回 默认容量与最小容量中的max值 // 不为空则返回最小值 private static int calculateCapacity(Object[] elementData, int minCapacity) { // 恒成立, if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) { // 取default_capcity=10 而minCapacity=1 return Math.max(DEFAULT_CAPACITY, minCapacity); } return minCapacity; } // 调用上面的方法对数组内部数据量进行判断 private void ensureCapacityInternal(int minCapacity) { ensureExplicitCapacity(calculateCapacity(elementData, minCapacity)); // minCapacity=1传入 } // minCapacity =10 private void ensureExplicitCapacity(int minCapacity) { modCount++;
// overflow-conscious code if (minCapacity - elementData.length > 0)
grow(minCapacity);
} // add代码扩容数组容量的核心 /**
- Increases the capacity to ensure that it can hold at least the
- number of elements specified by the minimum capacity argument. *
- @param minCapacity the desired minimum capacity */ private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity); }
private static int hugeCapacity(int minCapacity) { if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :MAX_ARRAY_SIZE;
Vector
数组结构实现,查询快,增删慢
- JDK 1.0 运行效率慢,线程安全
- 遍历方法有些不同
其他方法如 firstElement,lastElement,elementAt()
LinkedList:(重点)
-
ArrayList 与LinkedList之间的区别
不同结构实现方式
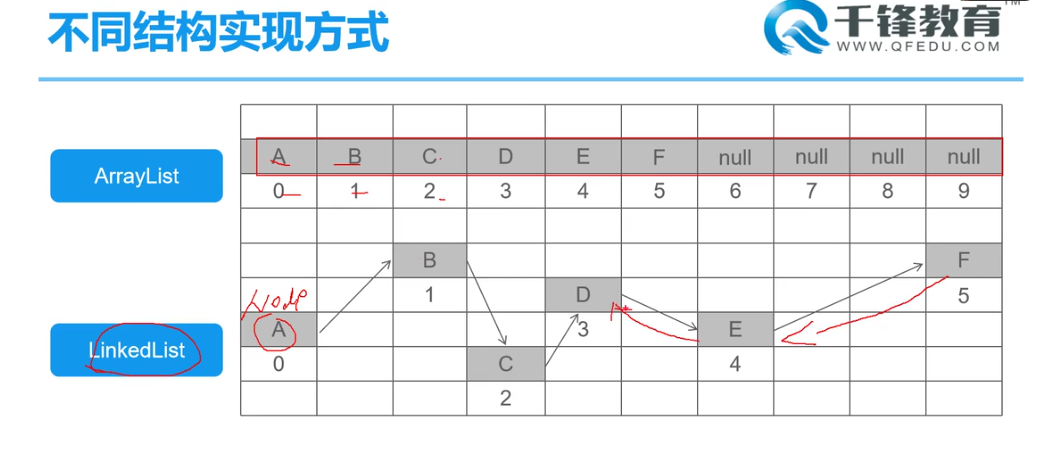
- ArrayList,必须开辟连续空间,查询快,增删慢
- LinkedList,无序开辟连续空间,查询慢,增删快。
4.泛型和工具类
- Java 泛型是JDK1.5 中引入的一个新特性,其本质是参数化类型,将类型作为参数传递
- 常见形式有 泛型类,泛型接口,泛型方法
- 语法
好处
概念:参数化类型,类型安全的集合,强制集合元素的类型必须一致。
- 特点:
- 编译时即可检查,而非运行时抛出异常
- 访问时,不必类型转换(拆箱)
- 不同泛型之间引用不能相互赋值,不存在多态
5.Set接口与实现类
- 特点:无序,无下标,元素不可重复
- 方法:全部继承自collection中的方法
- Set的实现类
- HashSet (重点)
- 基于hashCode实现元素不重复
- 当存入元素的哈希吗相同时,会调用equals进行确认,如结果为true,则拒绝后者存入
```java
/*
- @Descripttion: 泛型集合
- @version:
- @Author: Addicated
- @Date: 2020-11-04 12:35:03
- @LastEditors: Addicated
- @LastEditTime: 2020-11-04 15:56:55 */ package review.Day08;
- HashSet (重点)
import java.util.HashSet; import java.util.Set;
public class Demo1 {
public static void main(String[] args) {
// 创建集合 特点,无序,没有下标,不能重复
Set
// 遍历// 增强for 因为没有下标所以不能使用普通for循环// 迭代器进行迭代// 判断// contains()// isEmpty()}
}
/*
- @Descripttion:
- @version:
- @Author: Addicated
- @Date: 2020-11-04 16:10:05
- @LastEditors: Addicated
- @LastEditTime: 2020-11-04 16:17:28 */ package review.Day08;
import java.util.HashSet;
// hashSet的使用
// 存储结构为 hash表 (数组+链表+红黑树)
public class Demo2 {
public static void main(String[] args) {
// 新建集合
HashSet
hashSet.add("add");hashSet.add("22");hashSet.add("3");hashSet.add("4");System.out.println(hashSet.size());System.out.println(hashSet.toString());// 删除数据hashSet.remove("add");// 遍历// 增强for// 迭代器// 判断// contains,isEmpty}
}
- 存储过程- 存储结构 哈希表(数组 + 链表 + 红黑树)- 1,根据hashCode 计算保存的位置。如果此位置为空,则直接保存,如果不为空,则执行第二部- 2,再执行euqals方法,如果equals方法为true,则认为是重复,否则,形成链表- TreeSet---红黑树,二叉查找树- 基于排列顺序实现,元素不重复- 实现了SortedSet接口,对集合元素自动排序- 元素对象的类型必须实现Comparable接口,指定排序规则。- 通过CompareTo 方法确定是否为重复元素```java/** @Descripttion:* @version:* @Author: Addicated* @Date: 2020-11-04 18:01:31* @LastEditors: Addicated* @LastEditTime: 2020-11-04 18:04:17*/package review.Day08;import java.util.TreeSet;// 存储结构:红黑树public class Demo4 {public static void main(String[] args) {// 创建集合TreeSet<String> treeSet = new TreeSet<>();// 添加元素treeSet.add("addicated");treeSet.add("addicated2");treeSet.add("addicated3");treeSet.add("addicated");treeSet.add("addicated");System.out.println(treeSet.size());System.out.println(treeSet.toString());// 删除treeSet.remove("addicated");// 使用增强for// 使用迭代器// 判断// contains,isEmpty}}-------复杂类型添加/** @Descripttion:* @version:* @Author: Addicated* @Date: 2020-11-04 18:01:31* @LastEditors: Addicated* @LastEditTime: 2020-11-04 21:49:17*/package review.Day08;import java.util.TreeSet;// 存储结构:红黑树// 元素必须要实现Comparable 接口不然的话TreeSet内部无法对其进行比较,进而无法遍历// compareTo()方法返回值为0,认为是重复元素public class Demo4 {public static void main(String[] args) {// 创建集合TreeSet<Person> treeSet = new TreeSet<>();// 添加元素Person p1 = new Person(11, "adu");Person p2 = new Person(12, "adu1");Person p3 = new Person(13, "adu2");Person p4 = new Person(12, "adu5");treeSet.add(p1);treeSet.add(p2);treeSet.add(p3);treeSet.add(p4);System.out.println(treeSet.size());System.out.println(treeSet.toString());// 删除 remove// 遍历// 增强for循环// 迭代器// 判断// contains// isEmpty}}class Person implements Comparable<Person> {int age;String name;@Overridepublic int compareTo(Person o) {// 实现比较的规则// 先姓名比,后年龄比int n1 = this.getName().compareTo(o.getName());int n2 = this.age-o.getAge();return n1==0?n2:n1;}@Overridepublic String toString() {return "Person [age=" + age + ", name=" + name + "]";}public Person(int age, String name) {this.age = age;this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}}通过实现compartor接口,实现compare方法的方式来进行比较规则设定// TreeSet集合的使用// Comparator 实现定制比较(比较器)// comparable 可比较的,涉及到的实体类需要对其进行实现之后才可以进行正常的// TreeSet遍历public class Demo5 {public static void main(String[] args) {// 创建集合的时候调用接口并实现,指定比较规则TreeSet<Person> persons=new TreeSet<>(new Comparator<Person>(){@Overridepublic int compare(Person o1, Person o2) {int n1=o1.getAge()-o2.getAge();int n2=o1.getName().compareTo(o2.getName());return n1==0?n2:n1;}});}}
6.Map接口与实现类
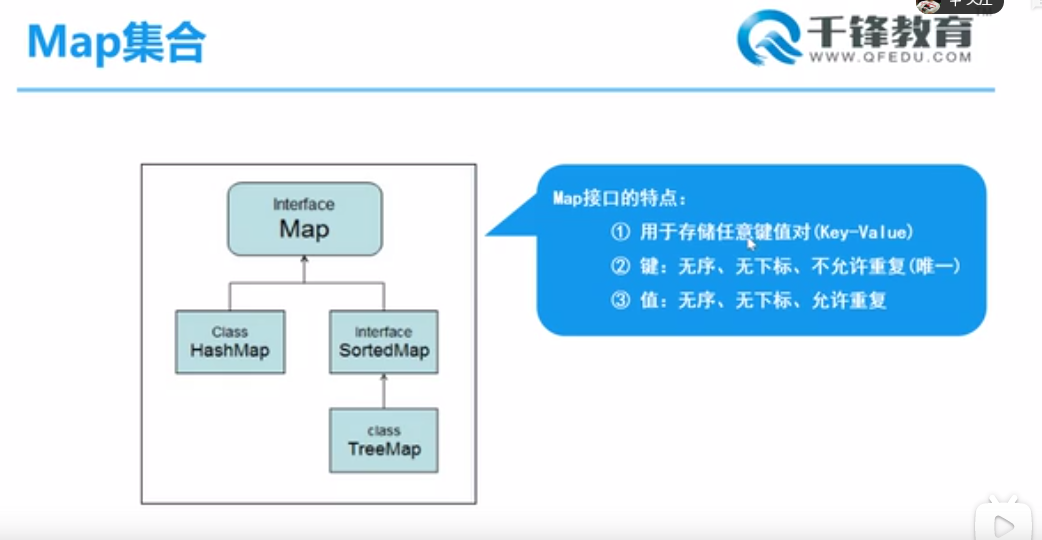
- Map父接口
- 特点:kv键值对进行存储,无序,无下标,键不可重复,值可以重复
- 方法
- V put(k,v) // 对象存入至集合中,关联键值key重复则覆盖原值
- Object get(object key) // 根据键获取对应的值
- Set
// 返回所有的key - Collection
values() // 返回包含所有值的collection集合 - Set
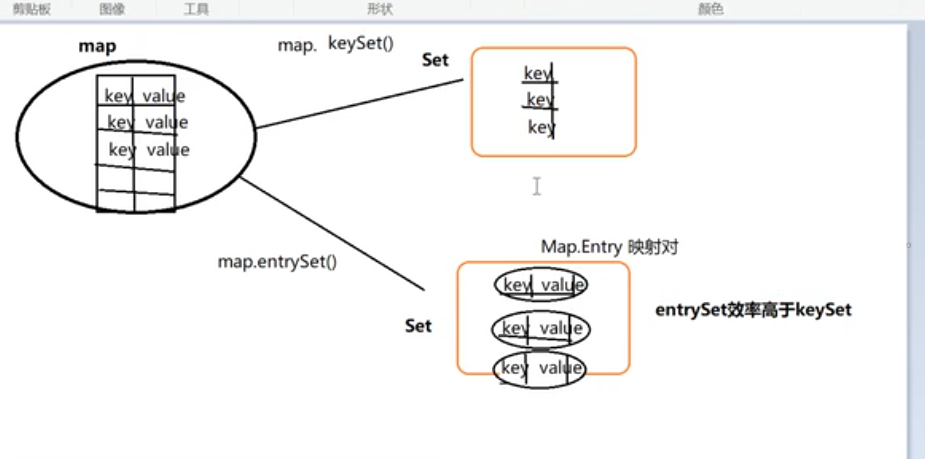
- keySet返回的是key的集合,entrySet()返回的是映射对儿,映射对儿本质还是map类型,
```java
/*
- @Descripttion: 针对Map接口开始学习
- @version:
- @Author: Addicated
- @Date: 2020-11-07 11:11:48
- @LastEditors: Addicated
- @LastEditTime: 2020-11-07 13:06:33 */ package review.Day08;
import java.util.HashMap; import java.util.Map; import java.util.Set;
// 存储键值对,键不可重复,值可重复,无序
public class Demo6 {
public static void main(String[] args) {
// 1 创建map集合
Map
// 2 添加元素map.put("cn", "china");// 键唯一,值可不唯一,后面在进行更新的时候会把第一次设定的值给覆盖掉map.put("cn", "china1");map.put("jp", "japan");map.put("us", "america ");System.out.println(map.size());System.out.println(map.toString());//3 删除元素内容map.remove("cn");System.out.println(map.toString());//4 map集合的遍历// 使用keySet() 进行遍历 拿到的事所有的键 方法返回的是key的Set集合// 通过这个原理来通过key去取对应的值Set<String> keySet = map.keySet();for (String string : keySet) {// for (String string : map.keySet()) {System.out.println(string + "-------- " + map.get(string));}// 使用entrySet()方法来进行遍历,返回的是Set<Map.Entry<String, String>> entries = map.entrySet();// for (Map.Entry<String,String> entry : entries) {// 可以直接替换成下面的写法for (Map.Entry<String,String> entry : map.entrySet()) {System.out.println(entry.getKey()+"---------"+entry.getValue());}// 4判断 containsmap.containsKey("cn");map.containsValue("cn");}
}
<a name="sRkzi"></a>## HashMap原码分析<a name="imR4Q"></a>### hashmap源码中的属性定义```java/*** The default initial capacity - MUST be a power of two.*/// 1<< 4,1左移4位,2的4次方// 位移的运算效率高,是为了运行效率考虑// DEFAULT_INITAL_CAPACITY 默认容器初始大小为16static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16/*** The maximum capacity, used if a higher value is implicitly specified* by either of the constructors with arguments.* MUST be a power of two <= 1<<30.*/// 容器的最大大小 2的30次方static final int MAXIMUM_CAPACITY = 1 << 30;/*** The load factor used when none specified in constructor.*/// 大于 75%的时候要对容易容量进行扩容// 假如当前容量为100 ,当添加元素到75个以上的时候就会对其进行扩容static final float DEFAULT_LOAD_FACTOR = 0.75f;/*** The bin count threshold for using a tree rather than list for a* bin. Bins are converted to trees when adding an element to a* bin with at least this many nodes. The value must be greater* than 2 and should be at least 8 to mesh with assumptions in* tree removal about conversion back to plain bins upon* shrinkage.*/// jdk1.8之后新增// 当链表长度大于8时,调整为红黑树static final int TREEIFY_THRESHOLD = 8;/*** The bin count threshold for untreeifying a (split) bin during a* resize operation. Should be less than TREEIFY_THRESHOLD, and at* most 6 to mesh with shrinkage detection under removal.*/// 链表长度小于6时,调整成链表static final int UNTREEIFY_THRESHOLD = 6;/*** The smallest table capacity for which bins may be treeified.* (Otherwise the table is resized if too many nodes in a bin.)* Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts* between resizing and treeification thresholds.*/// 当链表长度大于8时,并且集合元素个数大于等于64时,调整成红黑树static final int MIN_TREEIFY_CAPACITY = 64;、/*** The table, initialized on first use, and resized as* necessary. When allocated, length is always a power of two.* (We also tolerate length zero in some operations to allow* bootstrapping mechanics that are currently not needed.)*/// 哈希表中的数组transient Node<K,V>[] table;// 元素个数size;
hashmap源码中的方法定义
/*** Constructs an empty <tt>HashMap</tt> with the specified initial* capacity and the default load factor (0.75).** @param initialCapacity the initial capacity.* @throws IllegalArgumentException if the initial capacity is negative.*/public HashMap(int initialCapacity) {this(initialCapacity, DEFAULT_LOAD_FACTOR);}// 无参构造方法,初始化容器大小以及加载因子// 刚创建map的时候table是null,size是0,添加元素之后才是上面的16***put方法public V put(K key, V value) {return putVal(hash(key), key, value, false, true);}*/static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}/*** Implements Map.put and related methods** @param hash hash for key* @param key the key* @param value the value to put* @param onlyIfAbsent if true, don't change existing value* @param evict if false, the table is in creation mode.* @return previous value, or null if none*/final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {// 初始化声明变量,但不赋值Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;if (++size > threshold)resize();afterNodeInsertion(evict);return null;}
- 总结
- hashMap刚创建时,table是null,为了节省空间,当添加第一个元素时,table容量调整为16
- 当元素个数大于阈值 (16*0.75)时会进行扩容,扩容后大小为原来二倍,目的是减少调整元素的个数
- JDK1.8 当每个链表长度大于8,并且元素个数大于64时,会调整为红黑树,目的提高执行效率
- JDK1.8 当链表长度小于6时,调整成链表
- JDK1.8 以前,链表是头插入,1.8以后是尾插入
-
HashTable
HashMap JDK 1.2版本,线程不安全,运行效率快,允许用null 作为key或者是value
- HashTable JDK1.0版本,线程安全,运行效率慢,不允许null作为key或者
- Properties 作为HashTable 的子类,要求 key 和 value 都是String ,通常用于配置文件的读取
TreeMap
概念:结合工具类,定义除了存取以外的集合常用方法
- 方法
- public static void reverse(list<?> list) // 反转集合中元素的顺序
- public static void shuffle(list<?> list) // 随机重置集合元素的顺序
- public static void sort(List
list) //升序排序(元素类型必须实现Comparable接口) ```java /* - @Descripttion:
- @version:
- @Author: Addicated
- @Date: 2020-11-07 15:03:52
- @LastEditors: Addicated
- @LastEditTime: 2020-11-07 15:43:12 */ package review.Day08;
import java.util.ArrayList; import java.util.Arrays; import java.util.Collections; import java.util.List;
public class Demo9 {
public static void main(String[] args) {
List
// binarySearch 找到返回属元素的下标int i = Collections.binarySearch(list, 38);int i1 = Collections.binarySearch(list, 1503);System.out.println(i);// 查询不到返回的会是负数,而固定负数是几System.out.println(i1);// copy复制 但是目标需要与原数组的元素个数一致,否则会报错List<Integer> des = new ArrayList<>();for (int j = 0; j < 6; j++) {des.add(0);}Collections.copy(des, list);System.out.println(des.toString());// reverse 反转,交换位置Collections.reverse(list);System.out.println("反转" + list);// shuffle 打乱Collections.shuffle(list);System.out.println("打乱" + list);// 补充 list 转成数组Integer[] arr = list.toArray(new Integer[10]);System.out.println(arr.length);System.out.println(arr.toString());// 数组转成集合// 这样转换的事个受限制的集合String[] names = { "adi", "hantek", "addicated", "h" };List<String> list2 = Arrays.asList(names);System.out.println(list2);}
}
集合总结
集合的概念

若有收获,就点个赞吧
0 人点赞
