1. 字符与字符集
那么在计算机中是如何表示这些字符的呢?计算机中数据存储和传输都使用的是比特位 (bit),因此字符也是用计算机中的比特位来表示的。接下来的问题就是究竟用多少个比特位来表示一个字符呢?这其实就变成一个确定编码空间的问题了。要确定编码空间,我们就要知道在计算机中要使用的字符的总数是多少,而所有这些字符组成的集合就被称为 (计算机) 字符集。显然,不同国家地域、行业等使用的字符和字符总数会有不同,就会存在多种字符集,比如:
- 汉语中所有字符的集合构成汉语字符集;
- 英语中所有字符的集合构成英语字符集;
- 拉丁语中所有字符的集合构成拉丁语字符集;
- 日语中所有字符的集合构成日语字符集。
计算机字符集中的每个字符都有两个属性:码点 (code point) 和表示这个码点的内存编码 (位模式,表示这个字符码点的二进制比特串)。所谓码点 (这里借用了 Unicode 字符集中码点的概念)是指将字符集中所有字符 “排成一队”,字符在队伍中的唯一序号值称为其在该字符集中的码点。我们以 ASCII字符集中的字符为例,见下表:
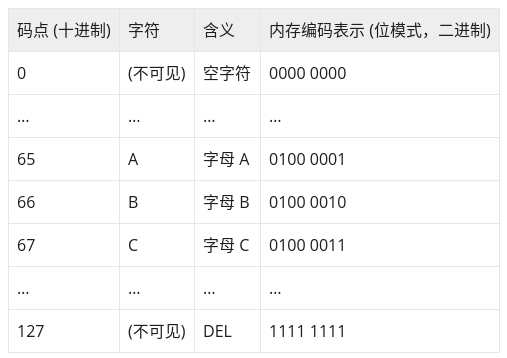
我们看到:ASCII 字符集中每个字符的码点与其内存编码表示是一致的,例如:ASCII 字符 A 在上面 ASCII 码表的码点 (序号) 为 65,其内存编码值也为 0100 0001(即十进制的 65)。
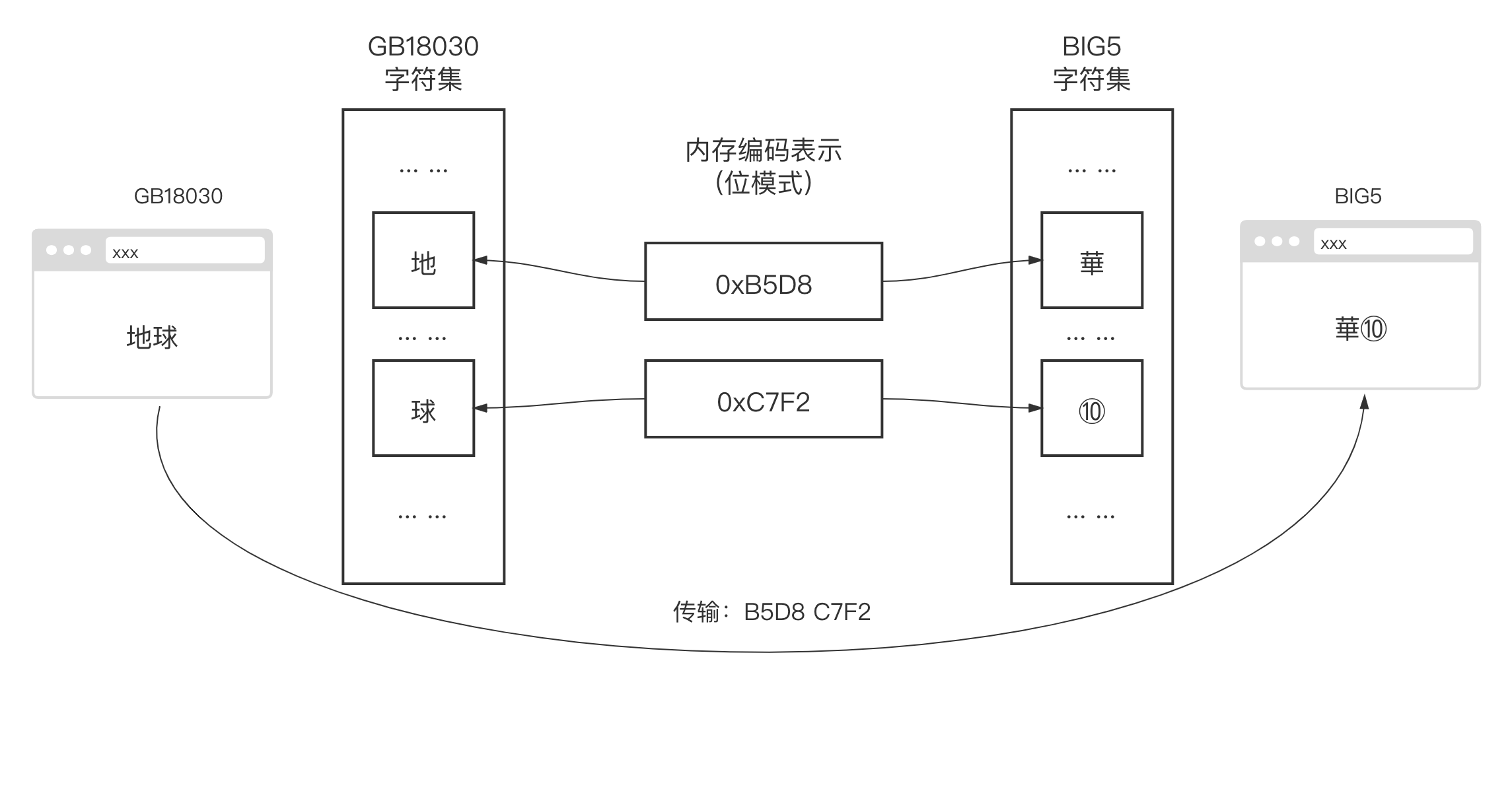
每个国家和地区都使用自己的字符集标准,如果仅限于国家和地区内部传播和使用,这当然是没有问题的。但当互联网飞速发展促进了全球化的交流后,数据开始在全球各个国家地区存储、传输交换和展示。当某一使用繁体汉字 BIG5 字符集标准的网友使用其浏览器浏览位于中国上海的一家使用简体汉字 GB18030字符集存储和传输数据的网站服务时,乱码问题便出现了!如果该网站某篇科普文章中包含 “地球” 两个简体汉字,该网站在存储和传输这两个汉字时使用的是 GB18030 字符集编码,其位模式分别为 “ 0xB5D8” 和 “0xC7F2”。当这四个字节的数据被传输并加载到一台使用 BIG5 字符集标准的浏览器中时,浏览器会根据 BIG5 字符集编码标准将 “0xB5D8” 和 “0xC7F2” 这两个位模式翻译为 “華” 和 “⑩”,这样这篇文章的语义就会被完全破坏掉了 (如下面示意图)。
2. Unicode 字符集的诞生与 UTF-8 编码方案
Unicode 字符集致力于为世界现存的每种语言中的每个字符分配一个统一并且唯一的字符编号,以满足跨语言、跨平台进行文本数据交换、处理、存储和显示的需求,使世界范围人们可以毫无障碍地通过计算机进行沟通。更直白地说,Unicode 字符集就是将世界上存在的绝大多数常用字符进行统一排队和编号。下面是 Unicode 字符集码点表的示意图:
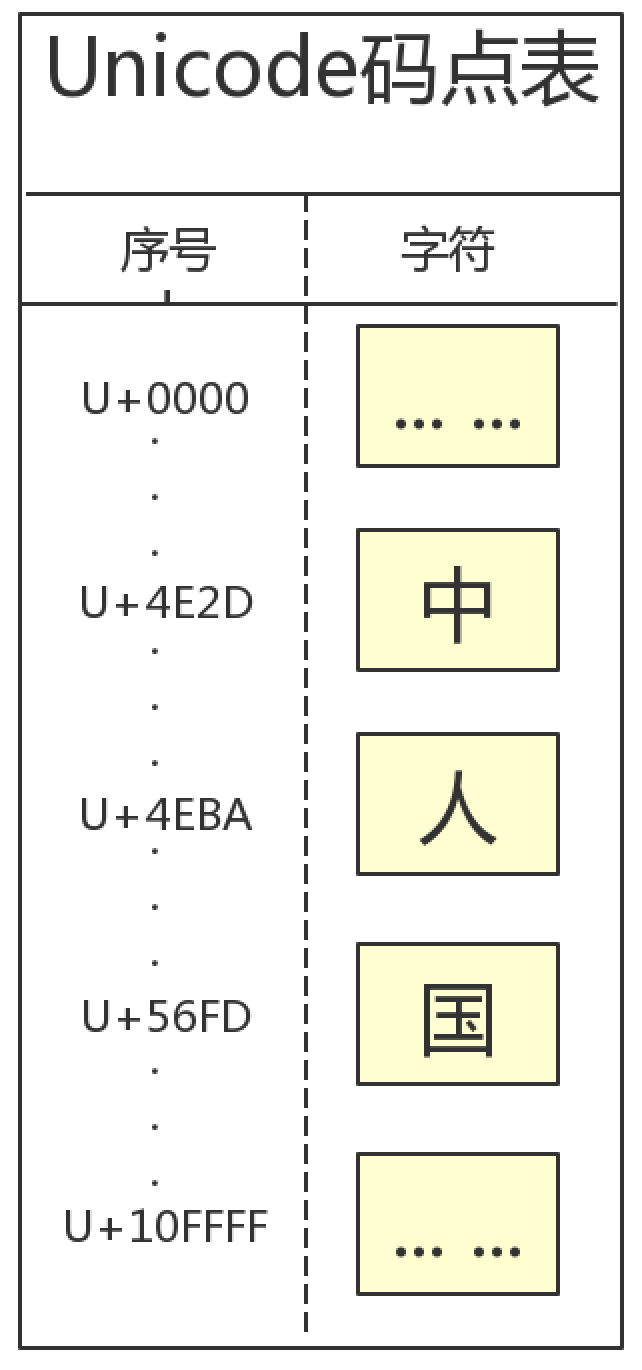
我们看到这个表中有两列:序号和字符。其中序号就是为全世界所有国家的所有语言文字的符号分配的一个唯一编号。序号的范围从 0x000000 到 0x10FFFF,一共可以容纳 110 多万个字符,这个序号也被称为 Unicode 码点 (code point)。第二列的字符就称为 “Unicode 字符”。考虑到与目前使用最多的也是最基础的 ASCII 字符集的码点兼容性,Unicode 的前 128 个码点与 ASCII 字符码点是一一对应的:

现在 Unicode 字符集的码点表有了,我们还需知道每个码点在计算机中的内存编码表示 (位模式)。我们知道 ASCII 字符集的内存编码表示 (位模式) 使用的是和其字符码点相同的数值,那么 Unicode 采用的是什么内存编码表示方案呢?答案是方案不唯一。目前较为常用的有三种:
- UTF-16
该方案使用 2 个字节或 4 个字节表示每个 Unicode 字符码点。它的优点是编解码简单,因为所有字符都用偶数个字节表示。但不足也很明显,比如:存在字节序问题、不兼容 ASCII 字符内存表示以及空间效率不高等。
- UTF-32
该方案固定使用 4 个字节表示每个 Unicode 字符码点。它的优点也是编解码简单,因为所有字符都用 4 个字节表示。但不足也和 UTF-16 一样明显,同样存在字节序问题、不兼容 ASCII 字符内存表示以及空间效率最差等。
- UTF-8
和上面两种方案不同,UTF-8 使用变长度字节对 Unicode 字符 (的码点) 进行编码。编码采用的字节数量与 Unicode 字符在码点表中的序号有关:表示序号 (码点) 小的字符使用的字节数量就少,表示序号 (码点) 大的字符使用的字节数量就多。
UTF-8 编码使用的字节数量从 1 个到 4 个不等。前 128 个与 ASCII 字符重合的码点 (U+0000~U+007F) 使用 1 个字节表示;带变音符号的拉丁文、希腊文、西里尔字母、阿拉伯文等使用 2 个字节来表示;而东亚文字(包括汉字) 使用 3 个字节表示;其他极少使用的语言的字符则使用 4 个字节表示。
这样的编码方案是兼容 ASCII 字符内存表示的,这意味着采用 UTF-8 方案在内存中表示 Unicode 字符时,已有的 ASCII 字符可以被直接当成 Unicode 字符进行存储和传输,无需做任何改变;
此外,UTF-8 的编码单元为一个字节(也就是一次编解码一个字节),所以在处理 UTF-8 方案表示的 Unicode 字符的时候就不需要像 UTF-16 和 UTF-32 那样考虑字节序问题了;相对于 UTF-16 和 UTF-32 方案,UTF-8 方案的空间利用率也是最高的。
汉字需要 3B, 为什么不用考虑字节序?
下面我们直观地看一下使用上述三种编码方案对 Unicode 字符 A 的编码结果:(LE:Little Endian (小端字节序), BE:Big Endian (大端字节序))
- 大端序: 符合人类从左到右的阅读顺序
- 小端序: 与人相反
- 理解字节序
Unicode字符:AUnicode码点(码点表中的序号):0x000041UTF-8编码:0x41UTF-16BE编码:0xFEFF0041UTF-16LE编码:0xFFFE4100UTF-32BE编码:0x0000FEFF00000041UTF-32LE编码:0xFFFE000041000000
字节序标记 (Byte Order Mark, BOM)
Unicode 规范中对字节序标记 (BOM) 的约定如下:
FF FE UTF-16 小端字节序(LE)FE FF UTF-16 大端字节序(BE)FF FE 00 00 UTF-32 小端字节序(LE)00 00 FE FF UTF-32 大端字节序(BE)EF BB BF UTF-8
如果没有提供字节序标记,则默认采用大端字节序解码。另外我们注意到 Unicode 规范为 UTF-8 也准备了一个字节序标记 EF BB BF,但由于 UTF-8 没有字节序问题,因此这个 BOM 只是用于表明该数据流采用的是 UTF-8 编码方案,算是一个编码方案类型标记了。
由于 UTF-8 编码方案的诸多优点,经过多年发展,UTF-8 已经成为 Unicode 字符在计算机中内存编码表示 (位模式) 方案的事实标准,Go 语言也顺应这一趋势,其源码文件的字符编码采用的也是 UTF-8 编码。
3. 字符编码方案间的转换
日常编码中,我们经常涉及在不同字符集的字符编码方案间进行转换,以满足字符在不同的字符编码环境下的解析、处理、呈现和存储的需求。这里我们以 UTF-8 字符编码环境与 GB18030 字符编码环境为例,看看如何使用 Go 实现这两个字符编码环境下的字符编码的转换。
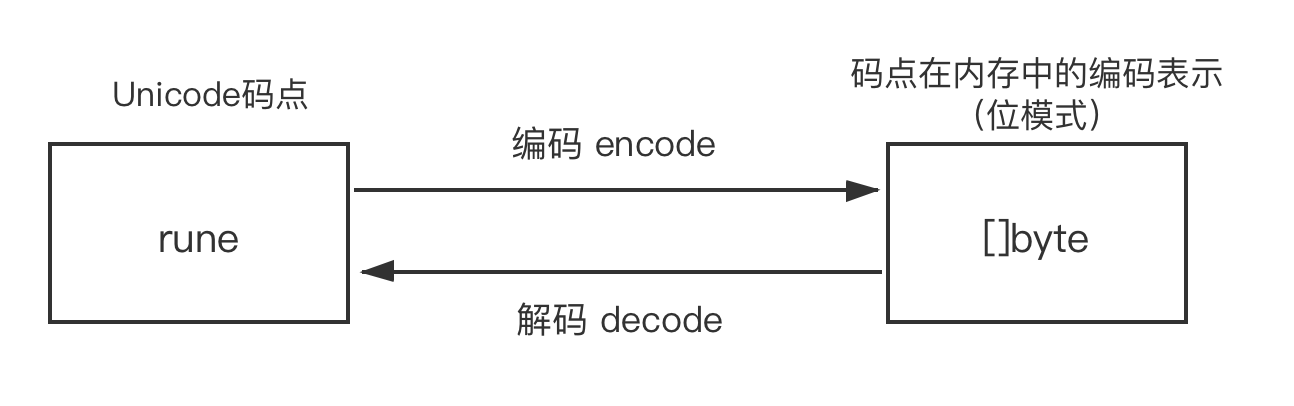
Go 语言默认源码文件中的字符是采用 UTF-8 编码方案的 Unicode 字符。在 Go 中,每个 rune 对应一个 Unicode 字符的码点,而 Unicode 字符在内存中的编码表示则是放在 []byte 类型中。从 rune 类型转换为 []byte 类型,称为 “编码 (encode)”,而反过来则称为 “解码 (decode)”:
我们可以通过标准库提供的 unicode/utf8 包对 rune 进行编解码操作,看下面示例:
// go-character-set-encoding/rune_encode_and_decode.gopackage mainimport ("fmt""unicode/utf8")// rune -> []bytefunc encodeRune() {var r rune = 0x4E2D // 0x4E2D为Unicode字符"中"的码点buf := make([]byte, 3)n := utf8.EncodeRune(buf, r)fmt.Printf("the byte slice after encoding rune 0x4E2D is ")fmt.Printf("[ ")for i := 0; i < n; i++ {fmt.Printf("0x%X ", buf[i])}fmt.Printf("]\n")fmt.Printf("the unicode charactor is %s\n", string(buf))}// []byte -> runefunc decodeRune() {var buf = []byte{0xE4, 0xB8, 0xAD}r, _ := utf8.DecodeRune(buf)fmt.Printf("the rune after decoding [0xE4, 0xB8, 0xAD] is 0x%X\n", r)}func main() {encodeRune()decodeRune()}
运行该示例:
$go run rune_encode_and_decode.gothe byte slice after encoding rune 0x4E2D is [ 0xE4 0xB8 0xAD ]the unicode character is 中the rune after decoding [0xE4, 0xB8, 0xAD] is 0x4E2D
我们再通过打印字符字面量底层的内存空间内容来验证示例输出结果的正确性:
// go-character-set-encoding/dump_utf8_encoding_of_string.gopackage mainimport "fmt"func main() {var s = "中"fmt.Printf("Unicode字符:%s => 其UTF-8内存编码表示为: ", s)for _, v := range []byte(s) {fmt.Printf("0x%X ", v)}fmt.Printf("\n")}
运行该实例,我们看到 Unicode 字符 “中” 底层的内存空间内容与其 UTF-8 编码后的切片中的内容是一样的:
$go run dump_utf8_encoding_of_string.goUnicode字符:中 => 其UTF-8内存编码表示为: 0xE4 0xB8 0xAD
是 Go 的内存表示使用的 utf8 吧, 源码文件 *.go 或者说任意文本文件的编码与操作系统有关.
接下来,我们就来将 UTF-8 编码环境下的 “中国人” 三个字转换成 GB18030 编码环境中的编码表示(位模式),并验证转换后的结果在 GB18030 下是否能正确被解析和呈现。下面这幅示意图可以更直观地说明这个转换过程:

注意: GB18030 的码点与内存编码是一样的.
Go 标准库没有直接提供简体中文编码与 UTF-8 编码之间的转换实现,但 Go 标准库依赖的 golang.org/x/text 模块 (module) 中提供了相关转换实现。golang.org/x/text 同样是 Go 团队维护的工具包,我认为我们同样可以将该模块下面的包当做标准库来看待,只是 Go1 兼容性并不保证这些包对外提供的 API 的稳定性。下面是转换的实现代码:
// go-character-set-encoding/convert_utf8_to_gb18030.gopackage mainimport ("bytes""errors""fmt""io/ioutil""os""unicode/utf8""golang.org/x/text/encoding/simplifiedchinese""golang.org/x/text/transform")func dumpToFile(in []byte, filename string) error {f, err := os.OpenFile(filename, os.O_CREATE|os.O_TRUNC|os.O_RDWR, 0666)if err != nil {return err}defer f.Close()_, err = f.Write(in)if err != nil {return err}return nil}func utf8ToGB18030(in []byte) ([]byte, error) {if !utf8.Valid(in) {return nil, errors.New("invalid utf-8 runes")}r := bytes.NewReader(in)t := transform.NewReader(r, simplifiedchinese.GB18030.NewEncoder())out, err := ioutil.ReadAll(t)if err != nil {return nil, err}return out, nil}func main() {var src = "中国人" // <=> "\u4E2D\u56FD\u4EBA"var dst []bytefor i, v := range src {fmt.Printf("Unicode字符: %s <=> 码点(rune): %X <=> UTF8编码内存表示: ", string(v), v)s := src[i : i+3]for _, v := range []byte(s) {fmt.Printf("0x%X ", v)}t, _ := utf8ToGB18030([]byte(s))fmt.Printf("<=> GB18030编码内存表示: ")for _, v := range t {fmt.Printf("0x%X ", v)}fmt.Printf("\n")dst = append(dst, t...)}dumpToFile(dst, "gb18030.txt")}
我们运行上述代码:
$go run convert_utf8_to_gb18030.goUnicode字符: 中 <=> 码点(rune): 4E2D <=> UTF8编码内存表示: 0xE4 0xB8 0xAD <=> GB18030编码内存表示: 0xD6 0xD0Unicode字符: 国 <=> 码点(rune): 56FD <=> UTF8编码内存表示: 0xE5 0x9B 0xBD <=> GB18030编码内存表示: 0xB9 0xFAUnicode字符: 人 <=> 码点(rune): 4EBA <=> UTF8编码内存表示: 0xE4 0xBA 0xBA <=> GB18030编码内存表示: 0xC8 0xCB
该示例代码除了输出上面信息之外,还将转换后的 GB18030 编码数据写入了 gb18030.txt 文件,我们才 UTF-8 编码环境下输出该文件的内容:
$cat gb18030.txt?й???%
我们看到输出的内容为乱码。在 MacOS 环境下,我们将自带 “终端 (Terminal)” 的文本编码设置为 GB18030,然后在新标签窗口中再次输出 gb18030.txt 文件的内容:
$localeLANG="zh_CN.GB18030"LC_COLLATE="zh_CN.GB18030"LC_CTYPE="zh_CN.GB18030"LC_MESSAGES="zh_CN.GB18030"LC_MONETARY="zh_CN.GB18030"LC_NUMERIC="zh_CN.GB18030"LC_TIME="zh_CN.GB18030"LC_ALL=$cat gb18030.txt中国人
使用 Go 标准库以及其依赖库 golang.org/x/text 下的包,我们不仅可以实现 Go 默认字符编码 UTF-8 与其他字符集编码的互转,我们还可以实现任意字符集编码之间的相互转换。下面我们再来看一个将 GB18030 编码数据转换为 UTF-16 和 UTF-32 的示例 (我们利用上面示例生成的 gb18030.txt 作为输入数据源):
// go-character-set-encoding/convert_gb18030_to_utf16_and_utf32.go... ...func catFile(filename string) ([]byte, error) {f, err := os.Open(filename)if err != nil {return nil, err}defer f.Close()return ioutil.ReadAll(f)}func gb18030ToUtf16BE(in []byte) ([]byte, error) {r := bytes.NewReader(in) //gb18030// to rune(the utf8 representation of code point)s := transform.NewReader(r, simplifiedchinese.GB18030.NewDecoder())d := transform.NewReader(s,unicode.UTF16(unicode.BigEndian, unicode.IgnoreBOM).NewEncoder()) // to utf16BE, no bomout, err := ioutil.ReadAll(d)if err != nil {return nil, err}return out, nil}func gb18030ToUtf32BE(in []byte) ([]byte, error) {r := bytes.NewReader(in) //gb18030// to rune(the utf8 representation of code point)s := transform.NewReader(r, simplifiedchinese.GB18030.NewDecoder())d := transform.NewReader(s,utf32.UTF32(utf32.BigEndian, utf32.IgnoreBOM).NewEncoder()) // to utf32BE, no bomout, err := ioutil.ReadAll(d)if err != nil {return nil, err}return out, nil}func main() {src, err := catFile("gb18030.txt")if err != nil {fmt.Println("open file error:", err)return}// gb18030 to utf-16bedst, err := gb18030ToUtf16BE(src)if err != nil {fmt.Println("convert error:", err)return}fmt.Printf("UTF-16BE(no BOM)编码: ")for _, v := range dst {fmt.Printf("0x%X ", v)}fmt.Printf("\n")// gb18030 to utf-32bedst1, err := gb18030ToUtf32BE(src)if err != nil {fmt.Println("convert error:", err)return}fmt.Printf("UTF-32BE(no BOM)编码: ")for _, v := range dst1 {fmt.Printf("0x%X ", v)}fmt.Printf("\n")}
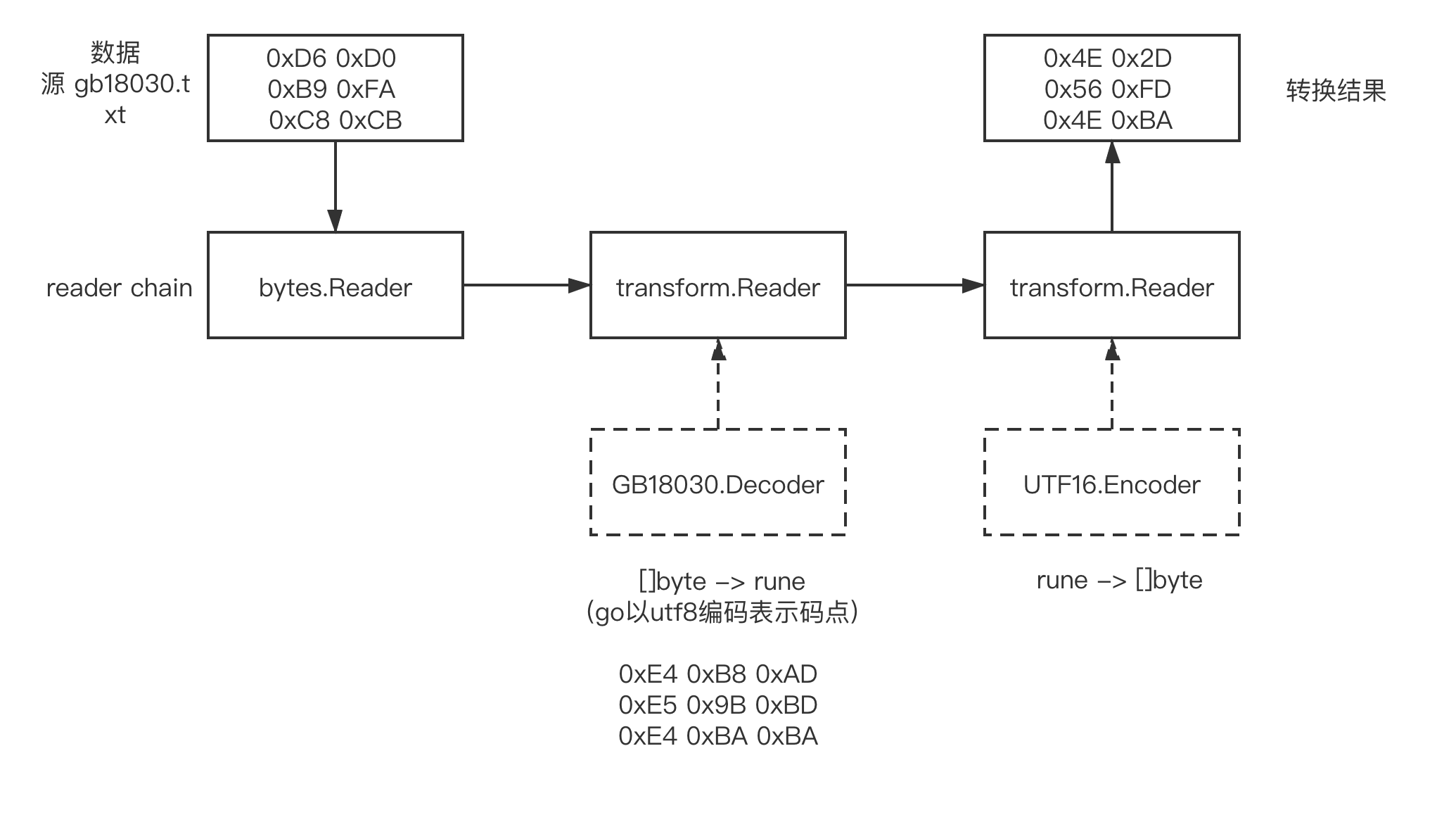
从图中我们看到:我们使用了一个惯用的 Reader Chain (链) 结构完成了数据从 gb18030 编码到 UTF-16 和 UTF-32 编码的转换。以 gb18030 到 UTF-16 的转换为例:第一个 transform.Reader 在 GB18030.Decoder 的帮助下,将 gb18030 编码的源数据 ([] byte) 转换为了 rune,即 unicode 码点,以 Go 默认的 UTF-8 编码格式保存在内存中;而第二个 transform.Reader 则在 UTF16.Encoder 的帮助下,将 rune (即 Unicode 码点,以 Go 默认的 UTF-8 编码格式保存在内存中) 再编码转换为最终数据 ([] byte)。
有个中间态.
下面是该示例的运行结果:
$go run convert_gb18030_to_utf16_and_utf32.goUTF-16BE(no BOM)编码: 0x4E 0x2D 0x56 0xFD 0x4E 0xBAUTF-32BE(no BOM)编码: 0x0 0x0 0x4E 0x2D 0x0 0x0 0x56 0xFD 0x0 0x0 0x4E 0xBA

若有收获,就点个赞吧
0 人点赞
