1. Go 的 panic 不是 Java 的“checked exception”
1) checked exception实质是“错误”,而 panic 是“异常”
而 panic 又是什么呢?Go 官方博客上的一篇文章《Defer, Panic, and Recover》是这么介绍引发panic的 panic 函数的:
panic 是一个 Go 内置函数,它用来停止当前常规控制流并启动panicking过程。当函数 F 调用 panic 函数时,函数 F 的执行停止,函数 F 中已进行了求值的 defer 函数都将得到正常执行,然后函数 F 将控制权返还给其调用者。对于函数 F 的调用者而言,函数 F 之后的行为就如同调用者调用的函数是 panic 一样,该panicking过程将继续在栈上进行下去,直到当前 goroutine 中的所有函数都返回为止,此时程序将崩溃退出。panic可以通过直接调用 panic 函数来引发,它们也可能是由运行时错误引起,例如越界数组访问。
和 Java 中checked exception的“有意而为之”相反,在 Go 中,panic 则是“不得已而为之”,即所有引发 panic 的情形,无论是显式的(我们主动调用 panic 函数引发的),还是隐式的(Go 运行时检测到违法情况而引发的)都是我们不期望看到的。对这些引发的 panic,我们很少有“预案”应对,更多的是让程序快速崩溃掉。因此一旦发生 panic,就意味着我们的代码很大可能出现了 bug。因此,Go 中的 panic 更接近于 Java 的RuntimeException+Error,而不是checked exception。
2) API 调用者没有义务必须去处理 panic
前面提到过 Java 的checked exception是必须要被上层代码处理的,要么捕获处理,要么重新抛给更上层。但是在 Go 中,我们通常会导入大量第三方包,这些第三方包 API 中是否会引发panic是不知道的(目前也没有现成的工具去发现),因此上层代码,即 API 调用者根本不会去逐一了解 API 是否会引发panic,也没有义务去处理引发的 panic。一旦你像checked exception那样使用 panic 作为正常错误处理的手段在你编写的 API 中将引发的panic当作错误,那么你就会给你的 API 使用者带去大麻烦!
3) 未被 recover 的 panic 意味着“游戏结束”(Game Over)
如果 API 抛出checked exception,那么 Java 编译器将严格要求上层代码对这个checked exception进行处理。但一旦你在 Go API 中引发panic,就像上面提到的,API 的调用者并没有义务处理该 panic,因此该 panic 会就会沿着调用函数栈向下“蔓延”,直到所有函数都返回,调用该 API 的 goroutine 将携带着 panic 信息退出。但事情并没有就此打住,一旦 panic 没有被 recover,它导致的可不是一个 goroutine 的退出,而是整个 Go 程序的“游戏结束” - 崩溃退出!
**
2. panic的典型应用
1) 充当断言角色,提示潜在 bug
Go 语言标准库没有提供 assert(虽然可以自己实现一个),我们可以使用 panic 来部分模拟断言的潜在 bug 提示的功能。下面是标准库encoding/json包中关于 panic 消息的一段注释:
// $GOROOT/src/encoding/json/decode.go... ...//当一些本不该发生的事情导致我们结束处理是,phasePanicMsg将被用作panic消息//它可以指示JSON解码器中的bug,或者//在解码器执行时还有其他代码正在修改数据切片。const phasePanicMsg = "JSON decoder out of sync - data changing underfoot?"func (d *decodeState) init(data []byte) *decodeState {d.data = datad.off = 0d.savedError = nild.errorContext.Struct = nil// Reuse the allocated space for the FieldStack slice.d.errorContext.FieldStack = d.errorContext.FieldStack[:0]return d}
下面是 json 包中的函数/方法使用phasePanicMsg的代码:
// $GOROOT/src/encoding/json/decode.gofunc (d *decodeState) valueQuoted() interface{} {switch d.opcode {default:panic(phasePanicMsg)case scanBeginArray, scanBeginObject:d.skip()d.scanNext()case scanBeginLiteral:v := d.literalInterface()switch v.(type) {case nil, string:return v}}return unquotedValue{}}
同样,在 json 包的 encode.go 中也有 panic 做潜在 bug 提示的例子:
// $GOROOT/src/encoding/json/encode.gofunc (w *reflectWithString) resolve() error {if w.v.Kind() == reflect.String {w.s = w.v.String()return nil}if tm, ok := w.v.Interface().(encoding.TextMarshaler); ok {if w.v.Kind() == reflect.Ptr && w.v.IsNil() {return nil}buf, err := tm.MarshalText()w.s = string(buf)return err}switch w.v.Kind() {case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:w.s = strconv.FormatInt(w.v.Int(), 10)return nilcase reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr:w.s = strconv.FormatUint(w.v.Uint(), 10)return nil}panic("unexpected map key type") // ------------ 这里}
2) 用于简化错误处理控制结构
panic 的语义机制决定了它可以在函数栈间游走,直到被某函数栈上的 defer 函数中的 recover 捕获。因此在一定程度上可以用于简化错误处理的控制结构。在上一篇“优化反复出现的if err != nil”中,我们在介绍check/handle风格化这个方法时就利用了 panic 的这个特性,这里再回顾一下:
// go-if-error-check-optimize-2.gofunc check(err error) {if err != nil {panic(err) // ------------------- 不管啥错误都 panic}}func CopyFile(src, dst string) (err error) {var r, w *os.File// error handlerdefer func() {if r != nil {r.Close()}if w != nil {w.Close()}if e := recover(); e != nil {if w != nil {os.Remove(dst)}err = fmt.Errorf("copy %s %s: %v", src, dst, err)}}()r, err = os.Open(src)check(err)w, err = os.Create(dst)check(err)_, err = io.Copy(w, r)check(err)return nil}
在 Go 标准库中,我们也看到了这种利用 panic 辅助简化错误处理控制结构,减少if err != nil重复出现的例子。我们来看一下 fmt 包中的这个例子:
// $GOROOT/src/fmt/scan.go// scanError represents an error generated by the scanning software.// It's used as a unique signature to identify such errors when recovering.type scanError struct {err error}func (s *ss) error(err error) {panic(scanError{err})}func (s *ss) Token(skipSpace bool, f func(rune) bool) (tok []byte, err error) {defer func() {if e := recover(); e != nil {if se, ok := e.(scanError); ok {err = se.err} else {panic(e)}}}()if f == nil {f = notSpace}s.buf = s.buf[:0]tok = s.token(skipSpace, f)return}func (s *ss) token(skipSpace bool, f func(rune) bool) []byte {if skipSpace {s.SkipSpace()}// read until white space or newlinefor {r := s.getRune()if r == eof {break}if !f(r) {s.UnreadRune()break}s.buf.writeRune(r)}return s.buf}func (s *ss) getRune() (r rune) {r, _, err := s.ReadRune()if err != nil {if err == io.EOF {return eof}s.error(err)}return}
3) 使用 recover 捕获 panic,防止 goroutine 意外退出
前面提到了 panic 的“危害”:无论在哪个 goroutine 中发生未被 recover 的 panic,整个程序都将崩溃退出。在有些场景下我们必须抑制这种“危害”,保证程序的健壮性。在这方面,标准库中的 http server 就是一个典型的代表:
// $GOROOT/src/net/http/server.go// Serve a new connection.func (c *conn) serve(ctx context.Context) {c.remoteAddr = c.rwc.RemoteAddr().String()ctx = context.WithValue(ctx, LocalAddrContextKey, c.rwc.LocalAddr())defer func() {if err := recover(); err != nil && err != ErrAbortHandler {const size = 64 << 10buf := make([]byte, size)buf = buf[:runtime.Stack(buf, false)]c.server.logf("http: panic serving %v: %v\n%s", c.remoteAddr, err, buf)}if !c.hijacked() {c.close()c.setState(c.rwc, StateClosed)}}()... ...}
3. 理解 panic 的输出信息
下面是某程序 panic 时真实输出的 panic 信息摘录:
panic: runtime error: invalid memory address or nil pointer dereference[signal SIGSEGV: segmentation violation code=0x1 addr=0x0 pc=0x8ca449]goroutine 266900 [running]:pkg.tonybai.com/smspush/vendor/github.com/bigwhite/gocmpp.(*Client).Connect(0xc42040c7f0, 0xc4203d29c0, 0x11, 0xc420423256, 0x6, 0xc420423260, 0x8, 0x37e11d600, 0x0, 0x0)/root/.go/src/pkg.tonybai.com/smspush/vendor/github.com/bigwhite/gocmpp/client.go:79 +0x239pkg.tonybai.com/smspush/pkg/pushd/pusher.cmpp2Login(0xc4203d29c0, 0x11, 0xc420423256, 0x6, 0xc420423260, 0x8, 0x37e11d600, 0xc4203d29c0, 0x11, 0x73)/root/.go/src/pkg.tonybai.com/smspush/pkg/pushd/pusher/cmpp2_handler.go:25 +0x9apkg.tonybai.com/smspush/pkg/pushd/pusher.newCMPP2Loop(0xc42071f800, 0x4, 0xaaecd8)/root/.go/src/pkg.tonybai.com/smspush/pkg/pushd/pusher/cmpp2_handler.go:65 +0x226pkg.tonybai.com/smspush/pkg/pushd/pusher.(*tchanSession).Run(0xc42071f800, 0xaba7c3, 0x17)/root/.go/src/pkg.tonybai.com/smspush/pkg/pushd/pusher/session.go:52 +0x98pkg.tonybai.com/smspush/pkg/pushd/pusher.(*gateway).addSession.func1(0xc4200881a0, 0xc42071f800, 0xc42040c700)/root/.go/src/pkg.tonybai.com/smspush/pkg/pushd/pusher/gateway.go:61 +0x11ecreated by pkg.tonybai.com/smspush/pkg/pushd/pusher.(*gateway).addSession/root/.go/src/pkg.tonybai.com/smspush/pkg/pushd/pusher/gateway.go:58 +0x350
对于 panic 导致的程序崩溃,我们首先检查位于栈顶的栈跟踪信息,并定位到直接引发 panic 的那一行代码:
/root/.go/src/pkg.tonybai.com/smspush/vendor/github.com/bigwhite/gocmpp/client.go:79 +0x239
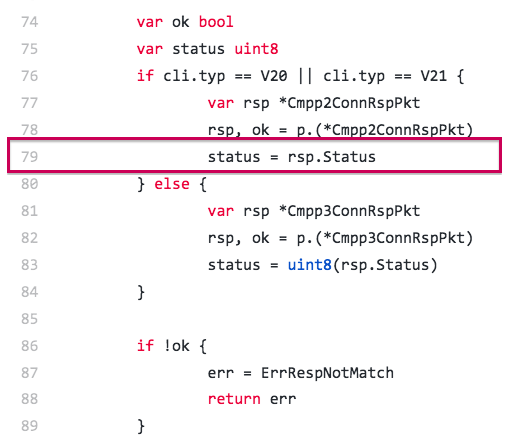
下面是 client.go 这个源文件第 79 行周围的代码片段:
如果没能做到,接下来,我们将继续调查一下 panic 输出的函数调用栈中参数是否正确。要想知道函数调用栈中参数传递是否有问题,我们就要知晓 panic 后输出的栈帧信息都是什么!比如下面 panic 信息中参数中的各种数值都代表什么!
gocmpp.(*Client).Connect(0xc42040c7f0, 0xc4203d29c0, 0x11, 0xc420423256, 0x6, 0xc420423260, 0x8, 0x37e11d600, 0x0, 0x0)pusher.cmpp2Login(0xc4203d29c0, 0x11, 0xc420423256, 0x6, 0xc420423260, 0x8, 0x37e11d600, 0xc4203d29c0, 0x11, 0x73)pusher.newCMPP2Loop(0xc42071f800, 0x4, 0xaaecd8)
关于 panic 后输出的栈跟踪信息(以下称 stack trace)的识别,总体可遵循以下几个要点:
- stack trace 中每个函数/方法后面的“参数数值”个数与函数/方法原型的参数个数不是一一对应的;
- stack trace 中每个函数/方法后面的“参数数值”是按照函数/方法原型参数列表中从左到右的参数类型的内存布局逐一展开的; 每个数值占用一个 word(64 位平台下面为 8 字节);
- 如果是方法(method),则第一个参数是 receiver 自身。如果 receiver 是指针类型,则第一个参数数值就是一个指针地址;如果是非指针的实例,则 stack trace 会按照其内存布局输出;
- 函数/方法返回值放在 stack trace 的“参数数值”列表的后面;如果有多个返回值,则同样按从左到右顺序,按照返回值类型的内存布局输出;
- 指针类型参数:占用 stack trace 的“参数数值”列表的 1 个位置;数值表示指针值,也是指针指向的对象的地址;
- string 类型参数:由于 string 在内存中由两个字(word)表示,第一个字是数据指针,第二个字是 string 的长度,因此在 stack trace 的“参数数值”列表中将占用两个位置;
- slice 类型参数:由于 slice 类型在内存中由三个字表示,第一个 word 是数据指针,第二个 word 是 len,第三个字是 cap,因此在 stack trace 的“参数数值”列表中将占用三个位置;
- 内建整型(int,rune,byte):由于按 word 逐个输出,对于类型长度不足一个 Word 的参数,会做合并处理;比如:一个函数有 5 个 int16 类型的参数,那么在 stack trace 的信息中,这 5 个参数将占用 stack trace 的“参数数值”列表中的两个位置;第一个位置是前 4 个参数的“合体”,第二个位置则是最后那个 int16 类型的参数值;
- struct 类型参数: 会按照 struct 中字段的内存布局顺序在 stack trace 中展开;
- interface 类型参数:由于 interface 类型在内存中由两部分组成,一部分是接口类型的参数指针,一部分是接口值的参数指针,因此 interface 类型参数将用 stack trace 的“参数数值”列表中的两个位置;
- stack trace 输出的信息是在函数调用过程中的“快照”信息,因此一些输出数值看似不合理,但是由于其并不是最终值,所以问题不一定发生在这些参数身上,比如:返回值参数。
合上面要点、函数/方法原型以及 stack trace 的输出,我们来“定位”一下上述 stack trace 输出的各个“参数”的含义:
cmpp2Login 和 Connect 的函数/方法原型以及调用关系如下:
func cmpp2Login(dstAddr, user, password string, connectTimeout time.Duration) (*cmpp.Client, error)func (cli *Client) Connect(servAddr, user, password string, timeout time.Duration) errorfunc cmpp2Login(dstAddr, user, password string, connectTimeout time.Duration) (*cmpp.Client, error) {c := cmpp.NewClient(cmpp.V21)return c, c.Connect(dstAddr, user, password, connectTimeout)}
将上述原型与 stack trace 的参数对照后,我们得出下面对应关系:
pusher.cmpp2Login(0xc4203d29c0, // dstAddr string的数据指针0x11, // dstAddr string的length0xc420423256, // user string的数据指针0x6, // user string的length0xc420423260, // password string的数据指针0x8, // password string的length0x37e11d600, // connectTimeout (64位整型)0xc4203d29c0, // 返回值:Client的指针0x11, // 返回值:error接口的类型指针0x73) // 返回值:error接口的数据指针gocmpp.(*Client).Connect(0xc42040c7f0, // cli的指针0xc4203d29c0, // servAddr string的数据指针0x11, // servAddr string的length0xc420423256, // user string的数据指针0x6, // user string的length0xc420423260, // password string的数据指针0x8, // password string的length0x37e11d600, // timeout0x0, // 返回值:error接口的类型指针0x0) // 返回值:error接口的数据指针
在这里,cmpp2Login 的 dstAddr、user、password、connectTimeout 这些输入参数值都非常正常;看起来不正常的两个返回值在栈帧中的值其实意义不大,因为 connect 没有返回,所以这些值处于“非最终态”;而 Connect 执行到第 79 行 panic,其返回值 error 的两个值也是处于“中间状态”。因此,在这个例子中虽然我们读懂了 panic 输出的 stack trace 信息,但这些信息并没有给与我们过多的解题提示。这是因为导致这个真实案例 panic 的真正元凶是上面图片中第 78 行。这行中我们使用了类型断言(type assertion),但却没有对类型断言返回的ok值进行有效性判断就使用了类型断言返回的rsp变量。由于类型断言失败,rsp 为 nil,这就是导致 panic 的真实原因。我们看到这次 panic 的位置对参数和返回值没有造成“污染”,这也是我们觉得 stack trace 信息都是正常的原因。
在Go 1.11及以后版本中,Go 编译器做了更深入的优化,很多“简单”的函数或方法会被自动 inline(内联)了。函数一旦内联化了,在 stack trace 中我们就无法看到栈帧信息了,栈帧信息都变成了省略号:
$go run go-panic-stacktrace.gopanic: panic in bazgoroutine 1 [running]:main.(*Y).baz(...)/Users/tonybai/.../go-panic-stacktrace.go:32main.main()/Users/tonybai/.../go-panic-stacktrace.go:51 +0x39exit status 2
我们可以使用-gcflags=”-l”来告诉编译器不要执行内联优化(inline),这样便可以看到 stacktrace 信息:
$ go run -gcflags="-l" go-panic-stacktrace.gopanic: panic in bazgoroutine 1 [running]:main.(*Y).baz(0xc00006cf30, 0xc00006cf28, 0x5, 0x10ccd43, 0x5, 0xc00006cf60, 0xe000d000c000b, 0xc00010000f, 0xc00006cf48, 0x103d29a)/Users/tonybai/.../go-panic-stacktrace.go:32 +0x39main.main()/Users/tonybai/.../go-panic-stacktrace.go:51 +0xffexit status 2

若有收获,就点个赞吧
0 人点赞
