1. Go 语言的字符串类型
Go 内置了 string 类型,统一了对“字符串”的抽象。这样无论是字符串常量、字符串变量或是代码中出现的字符串字面值,它们的类型都被统一设置为 string:
// sources/string_type.gopackage mainimport "fmt"const (s = "string constant")func main() {var s1 string = "string variable"fmt.Printf("%T\n", s) // stringfmt.Printf("%T\n", s1) // stringfmt.Printf("%T\n", "temporary string literal") // string}
Go string 类型具有如下功能特点:
- string 类型的数据是不可变的
- 零值可用
- 获取长度的时间复杂度是 O(1) 级别
- 支持通过+/+=操作符进行字符串连接
- 支持各种比较关系操作符:==、!= 、>=、<=、> 和 <
- 鉴于 Go string 是不可变的,因此如果两个字符串的 length 不相同,那么无需比较具体字符串数据,也可以断定两个字符串是不同的;如果 length 相同,则要进一步判断数据指针是否指向同一块底层存储数据。如果相同,则两个字符串是等价的,如果不同,则还需进一步去比对实际的数据内容。
- 对非 ASCII 字符提供原生支持
- 原生支持多行字符串
2. 字符串的内部表示
Go string 在运行时表示为下面结构:
// $GOROOT/src/runtime/string.gotype stringStruct struct {str unsafe.Pointerlen int}
下面是 runtime 包中实例化一个字符串对应的函数:
// $GOROOT/src/runtime/string.go// rawstring allocates storage for a new string. The returned// string and byte slice both refer to the same storage.// The storage is not zeroed. Callers should use// b to set the string contents and then drop b.func rawstring(size int) (s string, b []byte) {p := mallocgc(uintptr(size), nil, false)stringStructOf(&s).str = pstringStructOf(&s).len = size*(*slice)(unsafe.Pointer(&b)) = slice{p, size, size}return}
我们用下面示意图来表示 rawstring 调用后的一个 string 实例的状态:
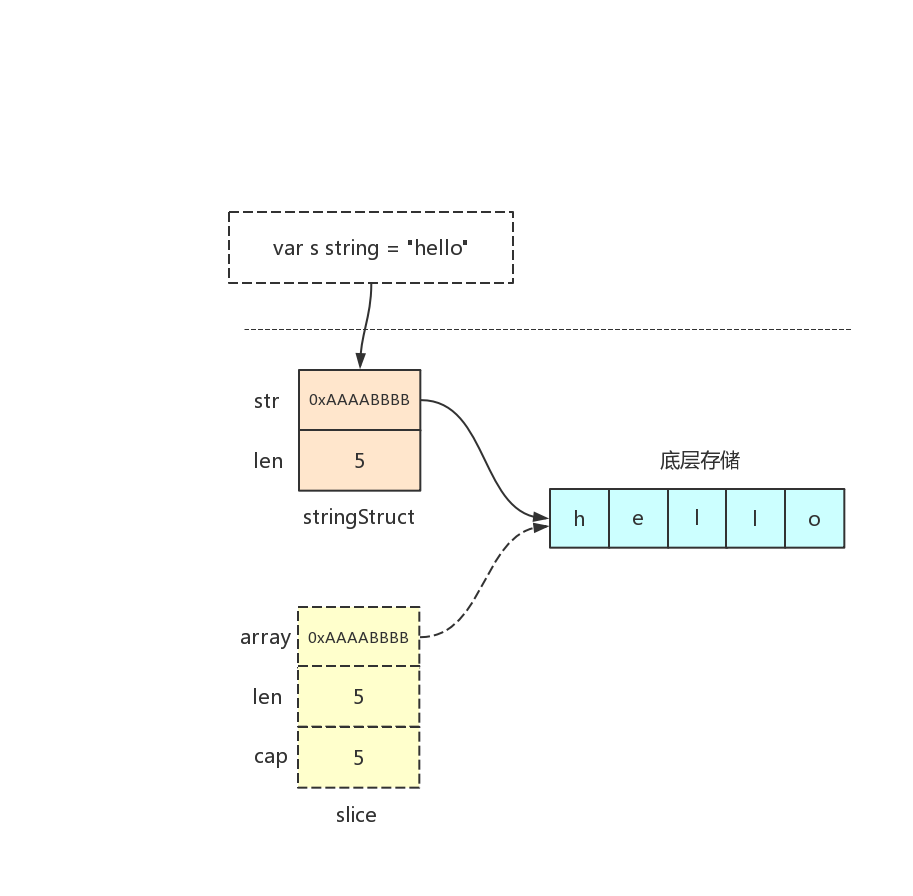
我们看到每个字符串类型变量/常量对应一个 stringStruct 实例,经过 rawstring 实例化后,stringStruct 中的 str 指针指向真正存储字符串数据的底层内存区域,len 字段存储的是字符串的长度(这里是 5);rawstring 同时还创建了一个临时的 slice,该 slice 的 array 指针也同样指向存储字符串数据的底层内存区域。注意 rawstring 调用后,新申请的内存区域还未被写入数据,该 slice 就是用于后续 runtime 层向其写入数据(“hello”)用的,写完数据后,该 slice 就可以被回收掉了,这也是上图中将 slice 结构以虚线框表示的原因。
通过 string 在运行时的表示我们可以得到这样一个结论,那就是我们直接将 string 类型通过函数/方法参数传入也不会有太多的损耗,因为传入的仅仅是一个“描述符”,而不是真正的字符串数据。我们可以通过一个简单的基准测试来验证一下:
// sources/string_as_param_benchmark_test.gopackage mainimport ("testing")var s string = `Go, also known as Golang, is a statically typed, compiled programming language designed at Google by Robert Griesemer, Rob Pike, and Ken Thompson. Go is syntactically similar to C, but with memory safety, garbage collection, structural typing, and communicating sequential processes (CSP)-style concurrency.`func handleString(s string) {_ = s + "hello"}func handlePtrToString(s *string) {_ = *s + "hello"}func BenchmarkHandleString(b *testing.B) {for n := 0; n < b.N; n++ {handleString(s)}}func BenchmarkHandlePtrToString(b *testing.B) {for n := 0; n < b.N; n++ {handlePtrToString(&s)}}
运行该基准测试:
$go test -bench . -benchmem string_as_param_benchmark_test.gogoos: darwingoarch: amd64BenchmarkHandleString-8 15668872 70.7 ns/op 320 B/op 1 allocs/opBenchmarkHandlePtrToString-8 15809401 71.8 ns/op 320 B/op 1 allocs/opPASSok command-line-arguments 2.407s
3. 字符串的高效构造
Go 还提供了其他一些构造字符串的方法,比如:
- 使用 fmt.Sprintf
- 使用 strings.Join
- 使用 strings.Builder
- 使用 bytes.Buffer
在这些方法中哪种方法更为高效呢?我们使用基准测试的数据来做参考:
// sources/string_concat_benchmark_test.gopackage mainimport ("bytes""fmt""strings""testing")var sl []string = []string{"Rob Pike ","Robert Griesemer ","Ken Thompson ",}func concatStringByOperator(sl []string) string {var s stringfor _, v := range sl {s += v}return s}func concatStringBySprintf(sl []string) string {var s stringfor _, v := range sl {s = fmt.Sprintf("%s%s", s, v)}return s}func concatStringByJoin(sl []string) string {return strings.Join(sl, "")}func concatStringByStringsBuilder(sl []string) string {var b strings.Builderfor _, v := range sl {b.WriteString(v)}return b.String()}func concatStringByStringsBuilderWithInitSize(sl []string) string {var b strings.Builderb.Grow(64)for _, v := range sl {b.WriteString(v)}return b.String()}func concatStringByBytesBuffer(sl []string) string {var b bytes.Bufferfor _, v := range sl {b.WriteString(v)}return b.String()}func concatStringByBytesBufferWithInitSize(sl []string) string {buf := make([]byte, 0, 64)b := bytes.NewBuffer(buf)for _, v := range sl {b.WriteString(v)}return b.String()}func BenchmarkConcatStringByOperator(b *testing.B) {for n := 0; n < b.N; n++ {concatStringByOperator(sl)}}func BenchmarkConcatStringBySprintf(b *testing.B) {for n := 0; n < b.N; n++ {concatStringBySprintf(sl)}}func BenchmarkConcatStringByJoin(b *testing.B) {for n := 0; n < b.N; n++ {concatStringByJoin(sl)}}func BenchmarkConcatStringByStringsBuilder(b *testing.B) {for n := 0; n < b.N; n++ {concatStringByStringsBuilder(sl)}}func BenchmarkConcatStringByStringsBuilderWithInitSize(b *testing.B) {for n := 0; n < b.N; n++ {concatStringByStringsBuilderWithInitSize(sl)}}func BenchmarkConcatStringByBytesBuffer(b *testing.B) {for n := 0; n < b.N; n++ {concatStringByBytesBuffer(sl)}}func BenchmarkConcatStringByBytesBufferWithInitSize(b *testing.B) {for n := 0; n < b.N; n++ {concatStringByBytesBufferWithInitSize(sl)}}
运行该基准测试:
$go test -bench=. -benchmem ./string_concat_benchmark_test.gogoos: darwingoarch: amd64BenchmarkConcatStringByOperator-8 11744653 89.1 ns/op 80 B/op 2 allocs/opBenchmarkConcatStringBySprintf-8 2792876 420 ns/op 176 B/op 8 allocs/opBenchmarkConcatStringByJoin-8 22923051 49.1 ns/op 48 B/op 1 allocs/opBenchmarkConcatStringByStringsBuilder-8 11347185 96.6 ns/op 112 B/op 3 allocs/opBenchmarkConcatStringByStringsBuilderWithInitSize-8 26315769 42.3 ns/op 64 B/op 1 allocs/opBenchmarkConcatStringByBytesBuffer-8 14265033 82.6 ns/op 112 B/op 2 allocs/opBenchmarkConcatStringByBytesBufferWithInitSize-8 24777525 48.1 ns/op 48 B/op 1 allocs/opPASSok command-line-arguments 8.816s
从基准测试的输出结果的第三列,即每操作耗时的数值来看:
- 做了预初始化的 strings.Builder 连接构建字符串效率最高;
- 带有预初始化的 bytes.Buffer 和 strings.Join 两种方法不相伯仲,分列二三位;
- 未预初始的 strings.Builder、bytes.Buffer 和操作符连接在第三档次;
- fmt.Sprintf性能最差,排在末尾。
结论:
- 在能预估出最终字符串长度的情况下,使用预初始化的 strings.Builder 连接构建字符串效率最高;
- strings.Join 连接构造字符串的平均性能最稳定,如果输入的多个字符串是以[]string 承载,那么 strings.Join 也是不错的选择;
- 使用操作符连接的方式最直观、最自然;如果在编译器可以知晓预连接的字符串个数,那么使用此种方式可以得到编译器的优化处理;
- fmt.Sprintf 虽然效率不高,但也不是一无是处;如果是由多种不同类型变量来构造特定格式的字符串,那么这种方式还是最适合的。
4. 字符串相关的高效转换
从[]rune 或[]byte 反向转换为 string 的例子:
// sources/string_slice_to_string.gopackage mainimport "fmt"func main() {rs := []rune{0x4E2D,0x56FD,0x6B22,0x8FCE,0x60A8,}s := string(rs)fmt.Println(s)sl := []byte{0xE4, 0xB8, 0xAD,0xE5, 0x9B, 0xBD,0xE6, 0xAC, 0xA2,0xE8, 0xBF, 0x8E,0xE6, 0x82, 0xA8,}s = string(sl)fmt.Println(s)}$go run string_slice_to_string.go中国欢迎您中国欢迎您
无论是 string 转 slice 还是 slice 转 string,转换都是要付出代价的,这些代价的根源在于 string 是不可变的,运行时要为转换后的类型分配新内存。我们以 byte slice 与 string 相互转换为例,看看转换过程的内存分配情况:
// sources/string_mallocs_in_convert.gopackage mainimport ("fmt""testing")func byteSliceToString() {sl := []byte{0xE4, 0xB8, 0xAD,0xE5, 0x9B, 0xBD,0xE6, 0xAC, 0xA2,0xE8, 0xBF, 0x8E,0xE6, 0x82, 0xA8,0xEF, 0xBC, 0x8C,0xE5, 0x8C, 0x97,0xE4, 0xBA, 0xAC,0xE6, 0xAC, 0xA2,0xE8, 0xBF, 0x8E,0xE6, 0x82, 0xA8,}_ = string(sl)}func stringToByteSlice() {s := "中国欢迎您,北京换欢您"_ = []byte(s)}func main() {fmt.Println(testing.AllocsPerRun(1, byteSliceToString))fmt.Println(testing.AllocsPerRun(1, stringToByteSlice))}
运行这个例子:
- 我们看到:针对”中国欢迎您,北京换欢您”这个长度的字符串,在 string 与 byte slice 互转的过程中都要有一次的内存分配操作。
$go run string_mallocs_in_convert.go11
在 Go 运行时层面,字符串与 rune slice、byte slice 相互转换对应的函数如下:
// $GOROOT/src/runtime/string.goslicebytetostring: []byte -> stringslicerunetostring: []rune -> stringstringtoslicebyte: string -> []bytestringtoslicerune: string -> []rune
我们以 byte slice 为例,看看 slicebytetostring 和 stringtoslicebyte 的实现:
// $GOROOT/src/runtime/string.go// The constant is known to the compiler.// There is no fundamental theory behind this number.const tmpStringBufSize = 32type tmpBuf [tmpStringBufSize]bytefunc stringtoslicebyte(buf *tmpBuf, s string) []byte {var b []byteif buf != nil && len(s) <= len(buf) {*buf = tmpBuf{}b = buf[:len(s)]} else {b = rawbyteslice(len(s))}copy(b, s)return b}func slicebytetostring(buf *tmpBuf, b []byte) (str string) {l := len(b)if l == 0 {// Turns out to be a relatively common case.// Consider that you want to parse out data between parens in "foo()bar",// you find the indices and convert the subslice to string.return ""}// ... ... 此处省略一些代码if l == 1 {stringStructOf(&str).str = unsafe.Pointer(&staticbytes[b[0]])stringStructOf(&str).len = 1return}var p unsafe.Pointerif buf != nil && len(b) <= len(buf) {p = unsafe.Pointer(buf)} else {p = mallocgc(uintptr(len(b)), nil, false)}stringStructOf(&str).str = pstringStructOf(&str).len = len(b)memmove(p, (*(*slice)(unsafe.Pointer(&b))).array, uintptr(len(b)))return}
欲要更高效地进行转换,唯一的方法就是减少和避免额外的内存分配操作。我们看到运行时实现转换的函数中已经加入了一些避免每种情况都要分配新内存操作的优化(比如:tmpBuf 的复用)。
slice 类型是不可比较的,而 string 类型是可比较的,因此在日常 Go 编码中,我们会经常遇到将 slice 临时转换为 string 的情况。Go 编译器为这样的场景提供了优化。在运行时中有一个名为 slicebytetostringtmp 的函数就是协助实现这一优化的:
// $GOROOT/src/runtime/string.gofunc slicebytetostringtmp(b []byte) string {if raceenabled && len(b) > 0 { // 竞态检测?racereadrangepc(unsafe.Pointer(&b[0]),uintptr(len(b)),getcallerpc(),funcPC(slicebytetostringtmp))}if msanenabled && len(b) > 0 {msanread(unsafe.Pointer(&b[0]), uintptr(len(b)))}return *(*string)(unsafe.Pointer(&b))}
该函数的“秘诀”就在于不为 string 新开辟一块内存,而是直接使用 slice 的底层存储。当然使用这个函数的前提是:在原 slice 被修改后,这个 string 不能再被使用了。因此这样的优化是针对特定场景的,包括:
- string(b)用在 map 类型的 key 中
b := []byte{'k', 'e', 'y'}m := make(map[string]string)m[string(b)] = "value"m[[3]string{string(b), "key1", "key2"}] = "value1" // 不知道是什么
- string(b)用在字符串连接语句中
b := []byte{'t', 'o', 'n', 'y'}s := "hello " + string(b) + "!"
- string(b)用于字符串比较中
s := "tom"b := []byte{'t', 'o', 'n', 'y'}if s < string(b) {... ...}
Go 编译器对用在 for-range 循环中的 string 到[]byte 的转换也有优化处理,Go 编译器不会为[]byte 做额外的内存分配,而是直接使用 string 的底层数据。我们看下面例子:
// sources/string_for_range_covert_optimize.gopackage mainimport ("fmt""testing")func convert() {s := "中国欢迎您,北京欢迎您"sl := []byte(s)for _, v := range sl {_ = v}}func convertWithOptimize() {s := "中国欢迎您,北京欢迎您"for _, v := range []byte(s) {_ = v}}func main() {fmt.Println(testing.AllocsPerRun(1, convert))fmt.Println(testing.AllocsPerRun(1, convertWithOptimize))}
运行这个例子程序:
$go run string_for_range_covert_optimize.go10
从结果我们看到,convertWithOptimize 函数将 string 到[]byte 的转换放在 for-range 循环中,Go 编译器对其进行了优化,节省了一次内存分配操作。

若有收获,就点个赞吧
0 人点赞
