https://juejin.im/post/5c9a67ac6fb9a070cb24bf34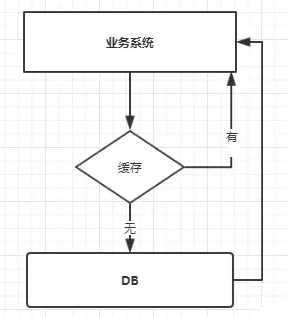
缓存穿透:不存在
查询一个数据库**不存在**的值,那么缓存必然也是不存在的,则每次查询都会经过一次缓存查询和数据库查询。
常见于黑客攻击
解决:
1、**缓存空值,并设置过期时间
如果某个 key 对应数据库中的值为 null,则把它放入 Redis 中,下次这个 key 再来查询的时候,就直接从 Redis 返回。
缺点:对于大量的、不相同的无效 key**,缓存每个无效的 key 会消耗 Redis 的内存。所以要设置过期时间
2、布隆过滤器 BloomFilter
类似于 HBase 的 Set,来判断某个元素是否存在与某个集合中。
大数据场景应用较多。
布隆过滤器可以先将无效 key 过滤掉: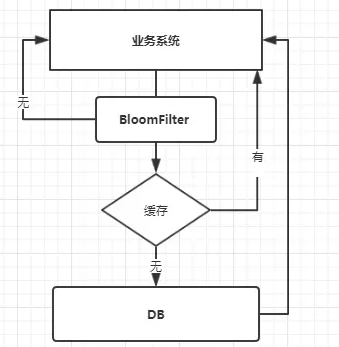
布隆过滤器的原理:https://zhuanlan.zhihu.com/p/43263751
1、对一个值 baidu 进行三个(多个)哈希算法,得到三个值,然后保存到位图中: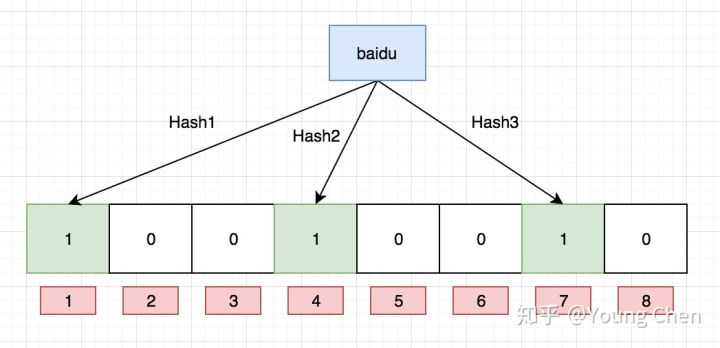
2、对 tencent 进行同样操作,会覆盖掉位图上各个位置的值: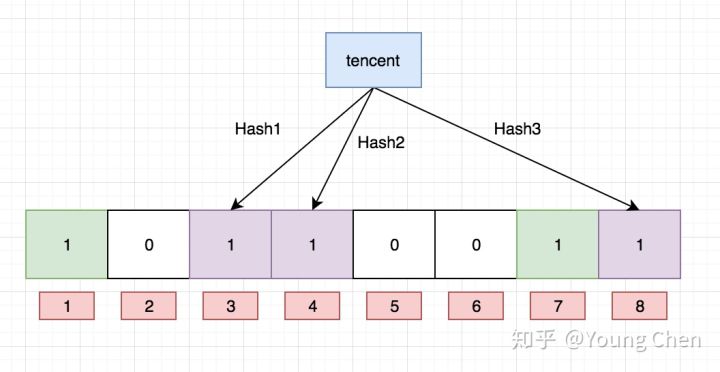
3、查询 dance,对它进行三次哈希算法,得到三个值,对应的三个位置如果都是 0,则说明一定不存在。
对应的三个位置只要存在一个 1,就可能存在,存在的 1 越多,存在的概率越大。
如果三个位置都是 1,这个元素也并不一定存在,因为有可能是其他元素的位。
缓存击穿:热点数据
背景:首先当被缓存的数据过期后,如果有查询请求来,则会去数据库查询,然后再更新缓存。
缓存击穿:一个或多个热点数据的缓存正常**过期。由于是热点数据,所以对于每个 key 的查询请求都是非常多的,从而导致这些查询落到数据库**。
解决:这是个多线程**查询数据库导致的问题,可以加入互斥锁,只允许一个线程来查询当前 key 对应的数据,其他线程等待。当查询完成并更新缓存后,其他线程需要再查询一次缓存(双重检测**)。此时缓存已经更新,便不会再去数据库查询了。
缓存雪崩:大面积失效
缓存**大面积**失效,从而导致查询全部落到数据库。一般是因为大量缓存都设置了相同的过期时间,或者是缓存服务宕机导致的。
解决:设置随机的缓存失效时间,在原有的失效时间上进行小范围的随机取值。
- 也可以考虑使用单线程去查询数据库更新缓存,其他线程必须等它更新成功后,才能从缓存中获取。这里和缓存击穿的场景类似,可以使用互斥锁。
其他:
缓存预热:
系统上线后,将数据加载到缓存系统,避免用户请求的时候,先查询数据库再设置缓存。
解决:
- 手工操作
- 数据量不大的话,项目启动自动加载
- 定时刷新
缓存更新:
Redis 自带的缓存淘汰策略。
业务策略:
- 定时去清理过期缓存,和更新
- 用户请求触发,检查是否过期,再去数据库查询然后更新
缓存降级:
使用缓存返回默认值,起到服务降级作用,保护后端服务和数据库。

若有收获,就点个赞吧
0 人点赞
