字符串常量:
字符串面试题:https://blog.csdn.net/u011541946/article/details/79865160
以下这种情况,则会将 “abc” 这个字符串常量放入字符串常量池,如果之后有其他变量使用相同的字符串,则会指向字符串常量池中的同一个字符串常量
String str = "abc";
而以下这种情况,会创建两个对象。一个是存在于堆中的 String 对象,一个是存在与字符串常量池的 “abc” 字符串常量,堆中 String 对象中存储的是字符串常量池中的拷贝,而不是引用
String str = new String("abc");
String.intern():获取对应的字符串常量超池中的字符串常量
String str1 = "abc";String str2 = new String("abc");// falseSystem.out.println(str1 == str2);// trueSystem.out.println(str1.equals(str2));// trueSystem.out.println(str1 == str2.intern());
String str1 = "abc";String str2 = "ab" + "c";// trueSystem.out.println(str1 == str2);
使用 “+” 进行字符串对象拼接时,编译器会创建一个空的 StringBuilder 对象,将字符串变量进行 append(),最后再调用 toString() 方法转换成 String 对象,那么这个 String 对象就必然存在于堆中。
String str1 = "abc";String str2 = "ab";// String str3 = new StringBuilder().append(str2).append("c").toString()String str3 = str2 + "c"// falseSystem.out.println(str1 == str3);// trueSystem.out.println(str1.equals(str3));
编译后的字节码: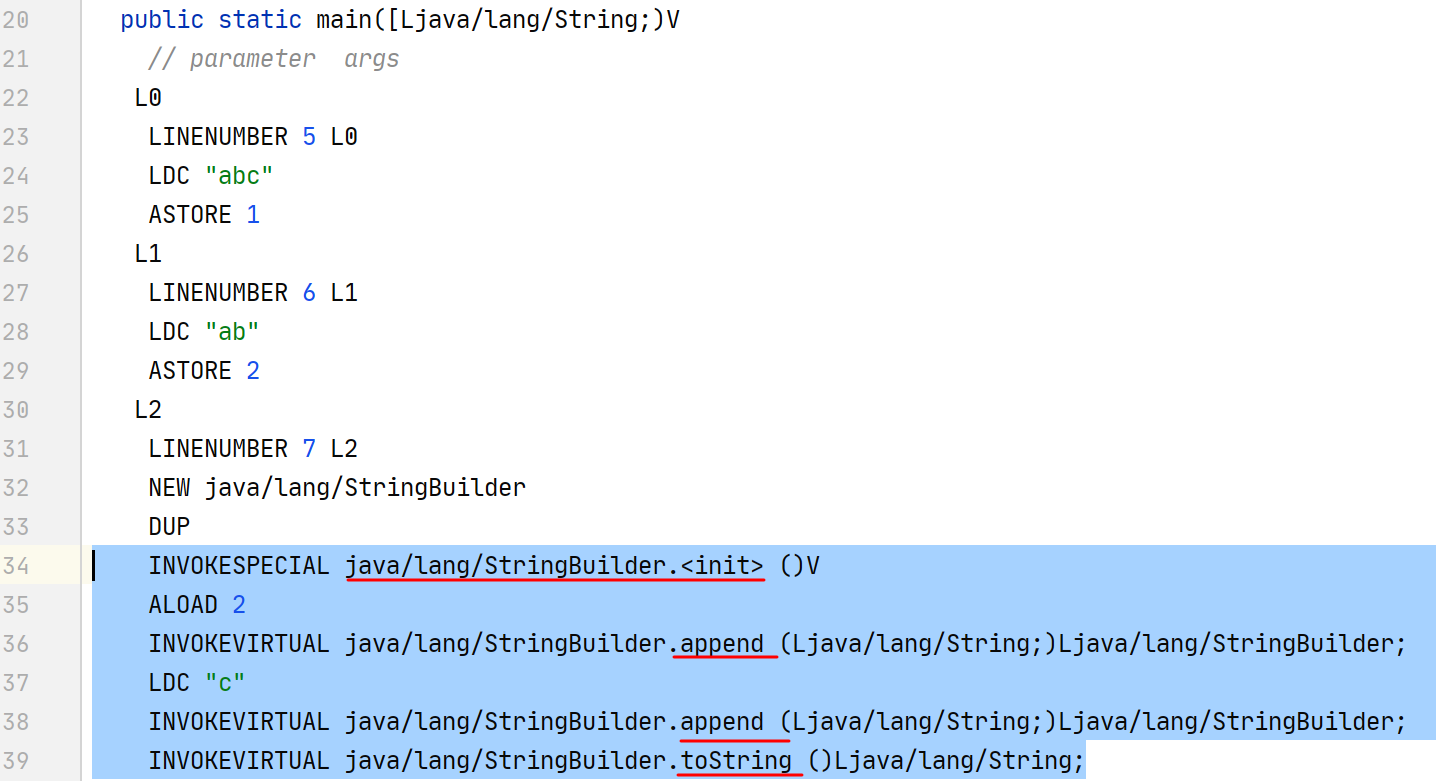
Unicode 和 UTF-8
参考文章:https://www.zhihu.com/question/23374078
Unicode 是字符集:
- 为每个字符都分配一个唯一 ID
- 在 Java 中, String 底层的 char 数组中,存储的就是这些字符集的 ID
UTF-8 是编码规则:
- 是一套以 8 位为一个编码单位的可变长编码
public static void main(String[] args) {// -26 -> 230 -> e6// -75 -> 181 -> b5// -117 -> 139 -> 8b// UTF-8: e6 b5 8b// 1110 0110 1011 0101 1000 1011String s1 = "测";byte[] bytes = s1.getBytes(StandardCharsets.UTF_8);System.out.println("UTF-8:");for (byte aByte : bytes) {int unsignedInt = Byte.toUnsignedInt(aByte);String hexString = Integer.toHexString(unsignedInt);System.out.printf("%s -> %s -> %s\n", aByte, unsignedInt, hexString);}System.out.println();// 测 -> 6d4b// Unicode: 6D4B// 110 1101 0100 1011char[] chars = s1.toCharArray();System.out.println("Unicode:");for (char aChar : chars) {String hexString = Integer.toHexString(aChar);System.out.printf("%s -> %s\n", aChar, hexString);}}
结果:
UTF-8:
-26 -> 230 -> e6
-75 -> 181 -> b5
-117 -> 139 -> 8b
Unicode:
测 -> 6d4b
注意:我在网上找到的大部分 UTF-8 编码工具,转换的结果都是 Unicode 字符集,而不是真的 UTF-8 编码后的结果。
final 类
String 类为什么设计成不可变的?
1、字符串常量的复用
2、String 对象保存 hashCode,不变的话就不需要考虑去更新
3、安全,String 对象作为方法入参,被很多 JDK 库使用,如果在方法中改变了内容,则容易发生问题
final char[] value
StringBuilder 类
底层存储:
char[] value
append:
- 如果数组容量不够,会使用复制数组的方法扩容
toString:
- new String(),会将数组再复制一遍用于创建 string 对象

若有收获,就点个赞吧
0 人点赞
