索引原则:https://my.oschina.net/u/3847203/blog/3096696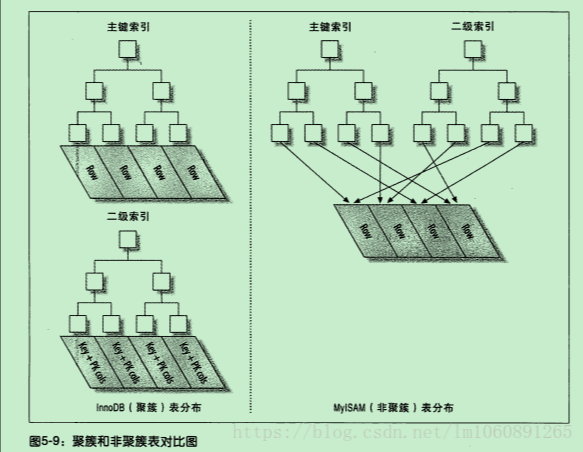
B+ 树详情:https://blog.csdn.net/qq_41999455/article/details/106138619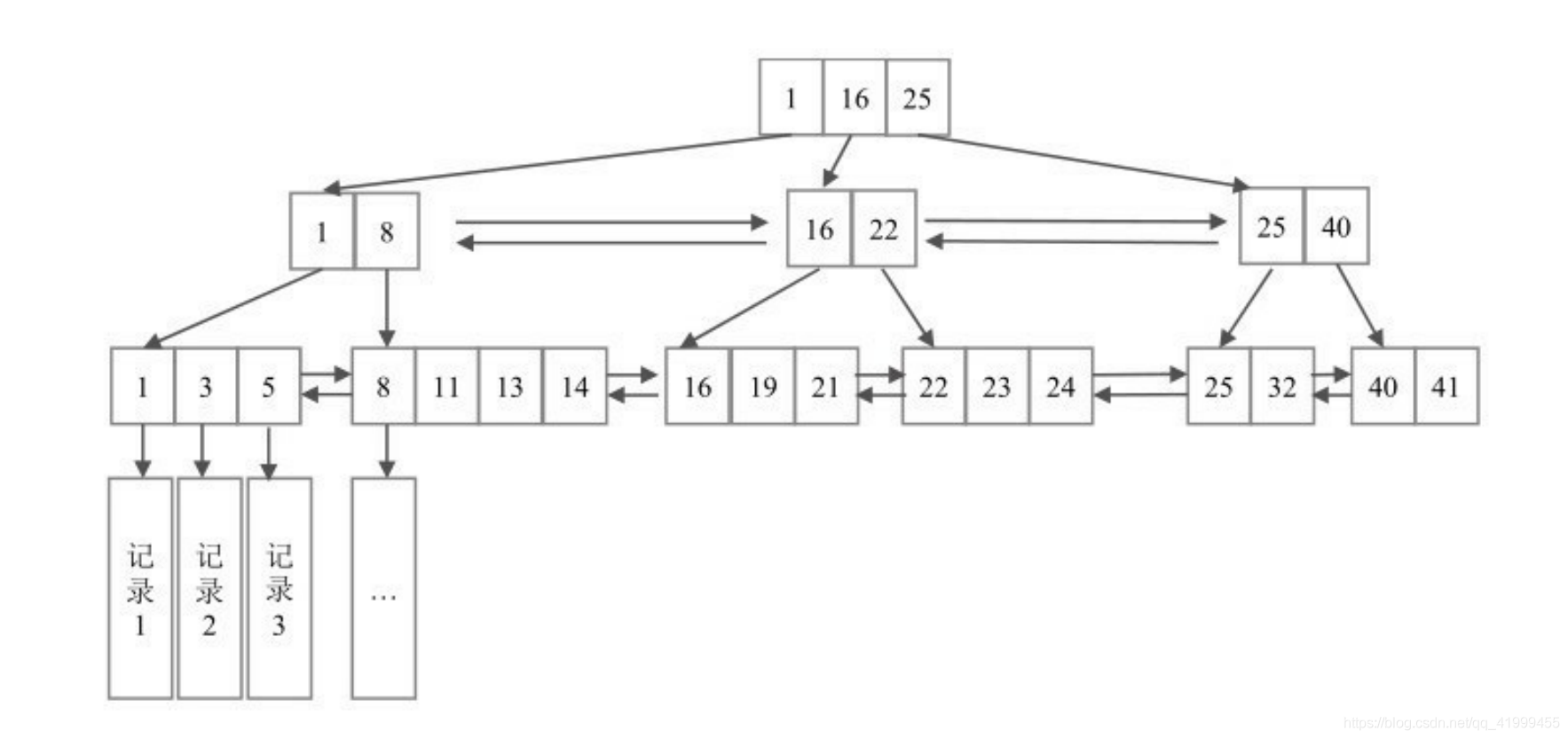
- 叶子节点的记录升序排列,并且形成双向链表
非叶子节点指向叶子节点中最小的那个 key,每一层都包含上一层的全部节点
范围查询:比如 [11, 23],先通过索引树分别找到 11 和 23 的位置,然后遍历
- 前缀匹配模糊查询:假设主键为字符串,where key like abc%,其实就是范围查找,找到 abbxxx 和 abcxxx 的分界点,然后向右遍历到 abcxxx 和 abdxxx 的分界点
- 但对于 %abc% 这样的中间匹配或者后缀则不行
- 排序和分页:叶子节点自然排序
like 前缀查询并不一定走索引:https://www.cnblogs.com/mqfs/p/13097229.html
- 占全表数据 30% 以上就会走全表扫描
select xxx where xxx limit 1000, 10:会扫描全表到 1000 这个位置,所以最好使用索引列(id > max_id)查询,再 limit
联合索引 in + order by 失效:https://www.cnblogs.com/tangyanbo/p/6378741.html
B+ 树高度:
https://blog.csdn.net/qq_41999455/article/details/104946754
1~3 层,约 2 千万行数据
InnoDB Page = 16K(16384),每个 B+ 树的叶子节点,存储的就是一页。
假设每条数据 1K,一页 16K/1K = 16 条
聚簇索引:
叶子节点存放数据(即行记录)。比如主键索引
InnoDB 中,每张表有且只有一个聚簇索引:
- 当有主键时,使用主键创建聚簇索引
- 当没有主键时,使用第一个不为 null 的列作为聚簇索引
- 如果都没有,则使用一个自增的序号标识每一行,并作为聚簇索引
非聚簇索引:
叶子节点只保存主键索引,还需要取查询主键的索引树
联合索引:
最左匹配原则:
- a,b,c,d,e -> index(b,c,d)
- 每一个索引想,都是包含联合索引 b,c,d 的数值.比如 4311d 行,对应的索引值为 311
- 322 索引会和 311 对比,发现 c 比 311 的大,所以放在右节点
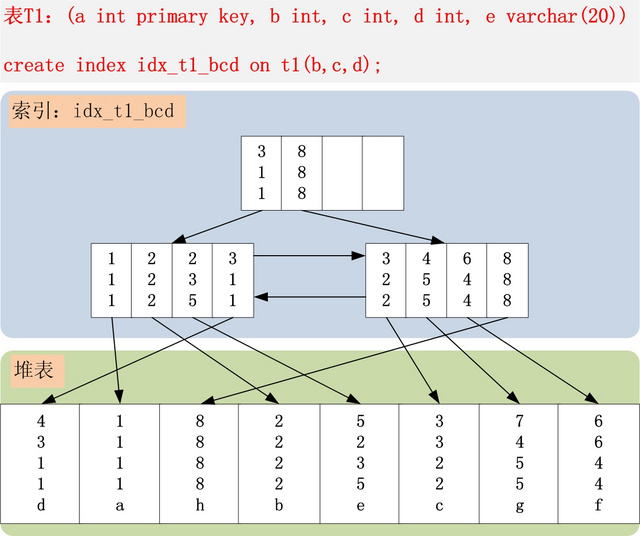
注意:这里是非聚簇索引,所以叶子节点是指向聚簇索引,而不是直接指向行记录。
例如:b <= 3 and c = 1 and d = 1
-
SQL 优化:
1、索引失效
避免在 where 中使用 != 或 <>
- 避免在 where 中使用 null 判断,select id from t where num is null。可以选择在保存的时候就使用默认值,查询的时候就可以指定默认值。
- 查询优化:首先应考虑在 where 及 order by 涉及的列上建立索引
- 避免在 where 中使用 or (或)来连接条件,否则会放弃索引。可以使用 union all 将两个条件的数据集合并
- like 查询时,前置% 会使索引失效,比如 where name like ‘%jay%’
- in 和 not in 也会导致全表扫描,对于连续的数值,可以使用 between:between 1 and 3(1, 2, 3)
- 避免在 where 子句中对字段进行表达式、函数操作
- 对于复合索引,使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,并且应尽可能的让字段顺序与索引顺序相一致
- 索引数量不是过多,会导致 insert 和 update 的时候更新索引耗时过长,降低效率
2、其他
- select 字段,而不是 select *
- 尽量使用数值型而不是字符型字段

若有收获,就点个赞吧
0 人点赞
