Google C++ 风格指南
Google C++ 风格指南
1. 头文件
头文件(.h)和源文件(.cc)一一对应。
1.1. Self-contained 头文件
头文件要有 1.2. #define 保护,包含了它所需要的其它头文件,用户和重构工具不需要为特别场合而包含额外的头文件。
用来插入文本的文件,并不是头文件,所以应以 .inc 结尾。
不允许分离出 -inl.h 头文件的做法.
1.2. #define 保护
所有头文件都应该使用#define 防止头文件被多重包含(multiple inclusion),命名格式当是:
为保证唯一性, 头文件的命名应该基于所在项目源代码树的全路径. 例如, 项目 foo 中的头文件 foo/src/bar/baz.h 可按如下方式保护:
1.3. 前置声明
避免使用前置声明。使用 #include 包含需要的头文件即可。
所谓「前置声明」(forward declaration)是类、函数和模板的纯粹声明,没伴随着其定义。
- 避免前置声明那些定义在其他项目中的实体.
- 函数:总是使用 #include.
- 类模板:优先使用 #include.
1.4. 内联函数
内联函数最好不要超过10行。内联函数的合理使用可提高代码执行效率;
包含循环或 switch 语句,或递归语句的不要声明为内联函数。
1.5. #include 的路径及顺序
使用标准的头文件包含顺序可增强可读性, 顺序: 相关头文件, C 库, C++ 库, 其他库的 .h, 本项目内的 .h。各类头文件之间可用
举例来说, google-awesome-project/src/foo/internal/fooserver.cc 的包含次序如下:
#include “foo/public/fooserver.h” // 优先位置
#include
#include
include
#include
#include
include “base/basictypes.h”
#include “base/commandlineflags.h”
#include “foo/public/bar.h”
2. 作用域
2.1. 命名空间
合理使用命名空间,可有效防止全局作用域的命名冲突。
鼓励在源文件内使用匿名命名空间或 static 声明。
使用具名的命名空间时,其名称可基于项目名或相对路径。
禁止使用 using 指示(using-directive)。
禁止使用内联命名空间(inline namespace),内联命名空间会自动把内部的标识符放到外层作用域。
不应该使用 using 指示 引入整个命名空间的标识符号。如using namespace foo;这样容易污染命名空间。
不要在头文件中使用 命名空间别名 除非显式标记内部命名空间使用。
命名空间使用小写表示。
在命名空间的最后注释出命名空间的名字。
用命名空间把文件包含, gflags 的声明/定义, 以及类的前置声明以外的整个源文件封装起来, 以区别于其它命名空间:
2.2. 匿名命名空间和静态变量
在源文件中定义一个不需要被外部引用的变量时,可以将它们放在匿名命名空间或声明为 static 。但是不要在头文件中这么做。
匿名命名空间的声明和具名的格式相同,在最后注释上 namespace :
2.3. 非成员函数、静态成员函数和全局函数
全局函数可用命名空间中的函数或类的静态成员函数代替,更推荐使用命名空间中的函数。
举例而言,对于头文件 myproject/foo_bar.h , 如下:
使用命名空间中的非成员函数比较好:
而非类的静态成员函数:
2.4. 局部变量
将函数变量尽可能置于最小作用域内,离第一次越近越好,在声明变量时将其初始化。
int j = g(); // 好——初始化时声明
vector
例外:如果变量是一个类的对象,且在一个循环体中调用,那么将该对象定义在循环体外更好。如:
//1.低效的实现
for (int i = 0; i < 1000000; ++i)
{
Foo f; // 构造函数和析构函数分别调用 1000000 次!
f.DoSomething(i);
}
//2.高效的实现
Foo f; // 构造函数和析构函数只调用 1 次
for (int i = 0; i < 1000000; ++i)
{
f.DoSomething(i);
}
2.5. 静态和全局变量
静态变量泛指静态生存周期的对象, 包括: 全局变量, 静态变量, 静态类成员变量, 以及函数静态变量,必须是原生数据类型 (POD : Plain Old Data),即 int, char 和 float, 以及 POD 类型的指针、数组和结构体。
允许使用POD 类型的全局变量,但禁止使用类类型的全局变量(全局变量的构造函数,析构函数及初始化操作的调用顺序每次生成有可能有变化,从而导致难以发现的bug)
禁止使用函数返回值来初始化全局变量,除非该函数(比如 getenv() 或 getpid() )不涉及任何全局变量。
对于全局的字符串常量,使用c风格的字符串,不要使用stl的字符串。const char kFrogSays[] = “ribbet” ;
总结:
1. .cc 中的不具名命名空间可避免命名冲突、限定作用域,避免直接使用 using 提示符污染命名空间;
2. 嵌套类符合局部使用原则,只是不能在其他头文件中前置声明,尽量不要 public ;
3. 尽量不用全局函数和全局变量,考虑作用域和命名空间限制,尽量单独形成编译单元;
4. 多线程中的全局变量(含静态成员变量)不要使用 class 类型(含 STL 容器),避免不明确行为导致的 bugs 。
作用域的使用,除了考虑名称污染、可读性之外,主要是为降低耦合度,提高编译、执行效率。
3. 类
3.1. 构造函数的职责
不要在构造函数中调用虚函数,
不要在无法报出错误时进行可能失败的初始化
不在构造函数中做太多逻辑相关的初始化
编译器提供的默认构造函数不会对变量进行初始化, 如果定义了其他构造函数, 编译器不再提供, 需要编码者自行提供默认构造函数
3.2. 隐式类型转换
不要定义隐式类型转换.。
对于转换运算符和单参数构造函数, 请使用 explicit 关键字,这样可以避免隐式转换。
3.3. 可拷贝类型和可移动类型
类型需要, 就让它们支持拷贝 / 移动(所有可拷贝对象也是可移动的,但反过来就不一定)。
如果让类型可拷贝, 要同时给出拷贝构造函数和赋值操作的定义。
如果让类型可移动 , 就同时定义移动构造函数和移动赋值操作。
不要为任何有可能有派生类的对象提供赋值操作或者拷贝 / 移动构造函数 (也不要继承有这样的成员函数的类).
如果基类需要可复制属性, 请提供一个 public virtual Clone() 和一个 protected 的拷贝构造函数以供派生类实现。
如果类不需要拷贝 / 移动操作, 请显式地通过在 public 域中使用 = delete 或其他手段禁用之(将其声明为 private 且无需实现).
// MyClass is neither copyable nor movable.
MyClass(const MyClass&) = delete;
MyClass& operator=(const MyClass&) = delete;
3.4. 结构体 VS 类
仅当只有数据成员时使用 struct, 其它一概使用 class.
3.5. 继承
组合(把基类的实例作为成员对象的方式 )比使用继承更合理。
尽量使用public继承的话
析构函数声明为 virtual. 如果你的类有虚函数, 则析构函数也应该为虚函数.
数据成员都是private
对于可能被子类访问的成员函数, 不要过度使用 protected 关键字
声明重载时用 override(推荐), final 或 virtual 的其中之一进行标记.
3.6. 多重继承
允许多重继承的情况: 最多只有一个基类是非抽象类; 其它基类都是以 Interface 为后缀的 纯接口类.
3.7. 接口
接口以 Interface 为后缀 (非强制):
当一个类满足以下要求时, 称之为纯接口:
- 只有纯虚函数 (“=0”) 和静态函数 (除了下文提到的析构函数).
- 没有非静态数据成员.
- 没有定义任何构造函数. 如果有, 也不能带有参数, 并且必须为 protected.
- 如果它是一个子类, 也只能从满足上述条件并以 Interface 为后缀的类继承.
3.8. 运算符重载
除少数特定环境外, 不要重载运算符. 也不要创建用户定义字面量.
3.9. 存取控制
所有数据成员为 private, 例外:static const 类型成员。
存取函数一般内联在头文件中,因为比较简单;
3.10. 声明顺序
将相似的声明放在一起。
一般应以 public: 开始, 后跟 protected:, 最后是 private:. 省略空部分.
在各个部分中, 建议将类似的声明放在一起, 并且建议以如下的顺序: 类型 (包括 typedef, using 和嵌套的结构体与类), 常量, 工厂函数, 构造函数, 赋值运算符, 析构函数, 其它函数, 数据成员.
4. 函数
4.1. 参数顺序
函数的参数顺序(非硬性规定): 输入参数, 输出参数.
输入参数通常是值参或 const 引用, 输出参数或输入/输出参数则一般为非 const 指针
4.2. 编写简短函数
建议编写简短, 凝练的函数.
4.3. 引用参数
Google Code 硬性约定: 输入参数是值参或 const 引用, 输出参数为指针.输入参数可以是 const 指针, 但决不能是非 const 的引用参数, 除非特殊要求, 比如 swap().
4.4. 函数重载
函数重载满足条件:调用一目了然,而不用花心思猜测调用的重载函数到底是哪一种. 这一规则也适用于构造函数.
如果打算重载一个函数, 可以试试改在函数名里加上参数信息. 例如, 用 AppendString() 和 AppendInt() 等, 而不是一口气重载多个 Append().
4.5. 缺省参数
只允许在非虚函数中使用缺省参数, 且必须保证缺省参数的值始终一致.
使用函数重载代替缺省参数的形式。
虚函数不能使用缺省参数, 因为在虚函数中缺省参数不一定能正常工作.
4.6. 函数返回类型后置语法
只有在常规写法 (返回类型前置) 不便于书写或不便于阅读时使用返回类型后置语法.
auto foo(int x) -> int;
5. 来自 Google 的奇技
5.1. 所有权与智能指针
动态分配出的对象最好有单一且固定的所有主, 并通过智能指针传递所有权.
std::unique_ptr 是 C++11 新推出的一种智能指针类型, 用来表示动态分配出的对象的独一无二的所有权; 当 std::unique_ptr 离开作用域时, 对象就会被销毁. std::unique_ptr 不能被复制, 但可以把它移动(move)给新所有主.
std::shared_ptr 同样表示动态分配对象的所有权, 但可以被共享, 也可以被复制; 对象的所有权由所有复制者共同拥有, 最后一个复制者被销毁时, 对象也会随着被销毁.
5.2. Cpplint
使用 cpplint.py 检查风格错误.
6. 其他 C++ 特性
6.1. 引用参数
所有按引用传递的参数必须加上 const.
Google Code 硬性约定: 输入参数是值参或 const 引用, 输出参数为指针. 输入参数可以是 const 指针, 但决不能是非 const 的引用参数,除非用于交换,比如 swap().
6.2. 右值引用
只在定义移动构造函数与移动赋值操作时使用右值引用. 不要使用 std::forward.
6.3. 函数重载
如果您打算重载一个函数, 可以试试改在函数名里加上参数信息。例如,用 AppendString() 和 AppendInt() 等, 而不是一口气重载多个 Append().
6.4. 缺省参数
宁愿使用函数重载,也不要使用缺省函数参数,少数极端情况除外。
6.5. 变长数组和 alloca()
我们不允许使用变长数组和 alloca().改用更安全的分配器(allocator),就像 std::vector 或 std::unique_ptr
6.6. 友元
我们允许合理的使用友元类及友元函数.
通常友元应该定义在同一文件内, 避免代码读者跑到其它文件查找使用该私有成员的类.
6.7. 异常
我们不使用 C++ 异常.
(YuleFox 注: 对于异常处理, 显然不是短短几句话能够说清楚的, 以构造函数为例, 很多 C++ 书籍上都提到当构造失败时只有异常可以处理, Google 禁止使用异常这一点, 仅仅是为了自身的方便, 说大了, 无非是基于软件管理成本上, 实际使用中还是自己决定)
6.8. 运行时类型识别
我们禁止使用 RTTI。(RTTI 允许程序员在运行时识别 C++ 类对象的类型. 它通过使用 typeid 或者 dynamic_cast 完成.)
6.9. 类型转换
使用 C++ 风格.
- 用 static_cast 替代 C 风格的值转换, 或某个类指针需要明确的向上转换为父类指针时.
- 用 const_cast 去掉 const 限定符.
- 用 reinterpret_cast 指针类型和整型或其它指针之间进行不安全的相互转换. 仅在你对所做一切了然于心时使用.
6.10. 流
不要使用流, 除非是日志接口需要. 使用 printf 之类的代替.
6.11. 前置自增和自减
对简单数值 (非对象), 两种都无所谓. 对迭代器和模板类型, 使用前置自增 (自减).
6.12. const 用法
在任何可能的情况下都要使用 const. 此外有时改用 C++11 推出的 constexpr 更好。
- 如果函数不会修改传你入的引用或指针类型参数, 该参数应声明为 const.
- 尽可能将函数声明为 const. 访问函数应该总是 const. 其他不会修改任何数据成员, 未调用非 const 函数, 不会返回数据成员非 const 指针或引用的函数也应该声明成 const.
- 如果数据成员在对象构造之后不再发生变化, 可将其定义为 const.
6.13. constexpr 用法
在 C++11 里,用 constexpr 来定义真正的常量,或实现常量初始化。
6.14. 整型
C++ 内建整型中, 仅使用 int. 如果程序中需要不同大小的变量, 可以使用
C++ 没有指定整型的大小. 通常人们假定 short 是 16 位, int 是 32 位, long 是 32 位, long long 是 64 位.
6.15. 64 位下的可移植性
代码应该对 64 位和 32 位系统友好. 处理打印, 比较, 结构体对齐时应切记: https://www.yuque.com/ixxw/it/64bit
6.16. 预处理宏
使用宏时要非常谨慎, 尽量以内联函数, 枚举和常量代替之.
下面给出的用法模式可以避免使用宏带来的问题; 如果你要宏, 尽可能遵守:
- 不要在 .h 文件中定义宏.
- 在马上要使用时才进行 #define, 使用后要立即 #undef.
- 不要只是对已经存在的宏使用#undef,选择一个不会冲突的名称;
- 不要试图使用展开后会导致 C++ 构造不稳定的宏, 不然也至少要附上文档说明其行为.
- 不要用 ## 处理函数,类和变量的名字。
6.17. 0, nullptr 和 NULL
整数用 0, 实数用 0.0, 指针用 nullptr 或 NULL, 字符 (串) 用 ‘\0’.
6.18. sizeof
尽可能用 sizeof(varname) 代替 sizeof(type).
6.19. auto
用 auto 绕过烦琐的类型名,只要可读性好就继续用
auto 只能用在局部变量里用。
6.20. 列表初始化
C++11 中,任何对象类型都可以被列表初始化。
// Vector 接收了一个初始化列表。
vector
// 不考虑细节上的微妙差别,大致上相同。// 您可以任选其一。
vector
// 可以配合 new 一起用。
auto p = new vector
// map 接收了一些 pair, 列表初始化大显神威。
map
// 初始化列表也可以用在返回类型上的隐式转换。
vector
// 初始化列表可迭代。
for (int i : {-1, -2, -3}) {}
// 在函数调用里用列表初始化。
void TestFunction2(vector
6.21. Lambda 表达式
适当使用 lambda 表达式。
别用默认 lambda 捕获,所有捕获都要显式写出来。
- 按 format 小用 lambda 表达式怡情。
- 禁用默认捕获,捕获都要显式写出来。打比方,比起 = {return x + n;}, 您该写成 n {return x + n;} 才对,这样读者也好一眼看出 n 是被捕获的值。
- 匿名函数始终要简短,如果函数体超过了五行,那么还不如起名(acgtyrant 注:即把 lambda 表达式赋值给对象),或改用函数。
- 如果可读性更好,就显式写出 lambd 的尾置返回类型,就像auto.
6.22. 模板编程
不要使用复杂的模板编程
5.23. Boost 库
只使用 Boost 中被认可的库,如:
- Call Traits : boost/call_traits.hpp
- Compressed Pair : boost/compressed_pair.hpp
- <The Boost Graph Library (BGL) : boost/graph, except serialization (adj_list_serialize.hpp) and parallel/distributed algorithms and data structures(boost/graph/parallel/ and boost/graph/distributed/)
- Property Map : boost/property_map.hpp
- The part of Iterator that deals with defining iterators: boost/iterator/iterator_adaptor.hpp, boost/iterator/iterator_facade.hpp, and boost/function_output_iterator.hpp
- The part of Polygon that deals with Voronoi diagram construction and doesn’t depend on the rest of Polygon: boost/polygon/voronoi_builder.hpp, boost/polygon/voronoi_diagram.hpp, and boost/polygon/voronoi_geometry_type.hpp
- Bimap : boost/bimap
- Statistical Distributions and Functions : boost/math/distributions
- Multi-index : boost/multi_index
- Heap : boost/heap
- The flat containers from Container: boost/container/flat_map, and boost/container/flat_set
5.24. C++11
适当用 C++11(前身是 C++0x)的库和语言扩展
用 C++11 特性前三思可移植性。
7. 命名约定
7.1. 通用命名规则
函数命名, 变量命名, 文件命名要有描述性, 少用缩写。
7.2. 文件命名
文件名要全部小写, 可以包含下划线 () 或连字符 (-), 依照项目的约定. 如果没有约定, 那么 “” 更好.
7.3. 类型命名
所有类型命名 —— 类, 结构体, 类型定义 (typedef), 枚举, 类型模板参数 —— 均使用相同约定, 即以大写字母开始, 每个单词首字母均大写, 不包含下划线.
// 类和结构体class UrlTable { …class UrlTableTester { …struct UrlTableProperties { …
// 类型定义
typedef hash_map
// using 别名
using PropertiesMap = hash_map
// 枚举
enum UrlTableErrors { …
7.4. 变量命名
变量 (包括函数参数) 和数据成员名一律小写, 单词之间用下划线连接. 类的成员变量以下划线结尾, 但结构体的就不用, 如: alocal_variable, a_struct_data_member, a_class_data_member.
7.5. 常量命名
声明为 constexpr 或 const 的变量, 或在程序运行期间其值始终保持不变的, 命名时以 “k” 开头, 大小写混合. 例如:
const int kDaysInAWeek = 7;
7.7. 函数命名
常规函数使用大小写混合, 取值和设值函数则要求与变量名匹配:
MyExcitingFunction(), MyExcitingMethod(), my_exciting_member_variable(), set_my_exciting_member_variable().
一般来说, 函数名的每个单词首字母大写 (即 “驼峰变量名” 或 “帕斯卡变量名”), 没有下划线. 对于首字母缩写的单词, 更倾向于将它们视作一个单词进行首字母大写 (例如, 写作 StartRpc() 而非 StartRPC()).
7.7. 命名空间命名
命名空间以小写字母命名.
最高级命名空间的名字取决于项目名称
不使用缩写作为名称
7.8. 枚举命名
单独的枚举值应该优先采用 常量 的命名方式(kEnumName ). 但 宏 方式的命名也可以接受(ENUM_NAME)
enum UrlTableErrors {
kOK = 0,
kErrorOutOfMemory,
kErrorMalformedInput,};
7.9. 宏命名
通常 不应该 使用宏. 如果不得不用, 其命名像枚举命名一样全部大写, 使用下划线:
#define ROUND(x) …#define PI_ROUNDED 3.0
7.10. 命名规则的特例
如果你命名的实体与已有 C/C++ 实体相似, 可参考现有命名策略.
bigopen(): 函数名, 参照 open() 的形式
uint: typedef
bigpos: struct 或 class, 参照 pos 的形式
sparse_hash_map: STL 型实体; 参照 STL 命名约定
LONGLONG_MAX: 常量, 如同 INT_MAX
小结:
Google 的命名约定很高明, 比如写了简单的类 QueryResult, 接着又可以直接定义一个变量 queryresult, 区分度很好; 再次, 类内变量以下划线结尾, 那么就可以直接传入同名的形参, 比如 TextQuery::TextQuery(std::string word) : word(word) {} , 其中 word_ 自然是类内私有成员.
8. 注释
8.1. 注释风格
// 或 / / 都可以; 但 // 更 常用. 要在如何注释及注释风格上确保统一.
8.2. 文件注释
在每一个文件开头加入版权公告.
每个文件都应该包含许可证引用. 为项目选择合适的许可证版本.(比如, Apache 2.0, BSD, LGPL, GPL)
如果你对原始作者的文件做了重大修改, 请考虑删除原作者信息.
如果一个 .h 文件声明了多个概念, 则文件注释应当对文件的内容做一个大致的说明, 同时说明各概念之间的联系.
不要在 .h 和 .cc 之间复制注释
8.3. 类注释
每个类的定义都要附带一份注释, 描述类的功能和用法, 除非它的功能相当明显.
// Iterates over the contents of a GargantuanTable.
// Example:
// GargantuanTableIterator* iter = table->NewIterator();
// for (iter->Seek(“foo”); !iter->done(); iter->Next()) {
// process(iter->key(), iter->value());
// }
// delete iter;
class GargantuanTableIterator {
…
};
8.4. 函数注释
函数声明处的注释描述函数功能; 定义处的注释描述函数实现.
8.5. 变量注释
通常变量名本身足以很好说明变量用途. 某些情况下, 也需要额外的注释说明.
每个类数据成员 (也叫实例变量或成员变量) 都应该用注释说明用途
全局变量也要注释说明含义及用途, 以及作为全局变量的原因.
8.6. 实现注释
对于代码中巧妙的, 晦涩的, 有趣的, 重要的地方加以注释.
巧妙或复杂的代码段前要加注释. 比如:
// Divide result by two, taking into account that x
// contains the carry from the add.
for (int i = 0; i < result->size(); i++) {
x = (x << 8) + (result)[i];
(result)[i] = x >> 1;
x &= 1;
}
比较隐晦的地方要在行尾加入注释. 在行尾空两格进行注释. 比如:<br />// If we have enough memory, mmap the data portion too.<br />mmap_budget = max<int64>(0, mmap_budget - index_->length());<br />if (mmap_budget >= data_size_ && !MmapData(mmap_chunk_bytes, mlock))<br /> return; // Error already logged.
8.7. 函数参数注释
如果函数参数的意义不明显, 考虑用下面的方式进行弥补:
- 如果参数是一个字面常量, 并且这一常量在多处函数调用中被使用, 用以推断它们一致, 你应当用一个常量名让这一约定变得更明显, 并且保证这一约定不会被打破.
- 考虑更改函数的签名, 让某个 bool 类型的参数变为 enum 类型, 这样可以让这个参数的值表达其意义.
- 如果某个函数有多个配置选项, 你可以考虑定义一个类或结构体以保存所有的选项, 并传入类或结构体的实例. 这样的方法有许多优点, 例如这样的选项可以在调用处用变量名引用, 这样就能清晰地表明其意义. 同时也减少了函数参数的数量, 使得函数调用更易读也易写. 除此之外, 以这样的方式, 如果你使用其他的选项, 就无需对调用点进行更改.
- 用具名变量代替大段而复杂的嵌套表达式.
- 万不得已时, 才考虑在调用点用注释阐明参数的意义.
8.8. 标点, 拼写和语法
注意标点, 拼写和语法; 写的好的注释比差的要易读的多.
8.9. TODO 注释
对那些临时的, 短期的解决方案, 或已经够好但仍不完美的代码使用 TODO 注释.
TODO 注释要使用全大写的字符串 TODO, 在随后的圆括号里写上你的名字, 邮件地址, bug ID, 或其它身份标识和与这一 TODO 相关的 issue. 主要目的是让添加注释的人 (也是可以请求提供更多细节的人) 可根据规范的 TODO 格式进行查找. 添加 TODO 注释并不意味着你要自己来修正, 因此当你加上带有姓名的 TODO 时, 一般都是写上自己的名字.
// TODO(kl@gmail.com): Use a “*” here for concatenation operator.
// TODO(Zeke) change this to use relations.
// TODO(bug 12345): remove the “Last visitors” feature
8.10. 弃用注释
通过弃用注释(DEPRECATED comments)以标记某接口点已弃用.
9. 格式
9.1. 行长度
每行字符数不超过 80.
注释行可以超过 80 个字符, 这样可以方便复制粘贴.
包含长路径的 #include 语句可以超出80列.
头文件保护 (#define 保护)可以忽略该原则.
9.2. 非 ASCII 字符
尽量不使用非 ASCII 字符, 使用 UTF-8 编码.
9.3. 空格还是制表位
使用空格, 每次缩进 2 个空格.
应该设置编辑器将制表符转为空格
9.4. 函数声明与定义
返回类型和函数名在同一行, 参数也尽量放在同一行。
如果放不下就对形参分行, 分行方式与 [函数调用](http://zh-google-styleguide.readthedocs.io/en/latest/google-cpp-styleguide/formatting/#function-calls) 一致.<br />
甚至连第一个参数都放不下:
注意以下几点:
- 尽量有参数名,使用好的参数名.
- 只有在参数未被使用或者其用途非常明显时, 才能省略参数名.
- 返回类型和函数名尽量在一行.
- 如果返回类型与函数声明或定义分行了, 不要缩进.
- 左圆括号总是和函数名在同一行.
- 函数名和左圆括号间不要加空格.
- 圆括号与参数间没有空格.
- 左大括号总在最后一个参数同一行的末尾处, 不另起新行.
- 右大括号总是单独位于函数最后一行, 或者与左大括号同一行.
- 右圆括号和左大括号间总是有一个空格.
- 所有形参应尽可能对齐.
- 缺省缩进为 2 个空格.
- 换行后的参数保持 4 个空格的缩进.
9.5. Lambda 表达式
Lambda 表达式对形参和函数体的格式化和其他函数一致; 捕获列表同理, 表项用逗号隔开.
9.6. 函数调用
尽量一行写完函数调用 。
如果太长就分行:在圆括号里对参数分行, 要么参数另起一行且缩进四格.

如果一系列参数本身就有一定的结构, 可以酌情地按其结构来决定参数格式:
9.7. 列表初始化格式
格式化 列表初始化和格式化函数调用一样。
9.8. 条件语句
不在圆括号内使用空格.
关键字 if 和 else 另起一行.
所有情况下 if 和左圆括号间都有个空格. 右圆括号和左大括号之间也要有个空格.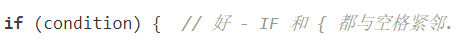
如果能增强可读性, 简短的条件语句允许写在同一行. 只有当语句简单并且没有使用 else 子句时使用:
只要其中一个分支用了大括号, 两个分支都要用上大括号
9.9. 循环和开关选择语句
switch 语句可以使用大括号分段, 以表明 cases 之间不是连在一起的. 如果有不满足 case 条件的枚举值, switch 应该总是包含一个 default 匹配 (如果有输入值没有 case 去处理, 编译器将给出 warning). 如果 default 应该永远执行不到, 简单的加条 assert:
在单语句循环里, 括号可用可不用:
空循环体应使用 {} 或 continue, 而不是一个简单的分号.
9.10. 指针和引用表达式
.或->前后不要有空格. 指针/地址操作符 (*, &) 之后不能有空格,如下: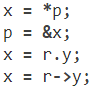


在单个文件内要保持风格一致, 所以, 如果是修改现有文件, 要遵照该文件的风格.
9.11. 布尔表达式
如果一个布尔表达式超过 标准行宽, 断行方式要统一.
可以考虑插入圆括号, 合理使用的话对增强可读性是很有帮助的。
9.12. 函数返回值
不要在 return 表达式里加上非必须的圆括号.
9.13. 变量及数组初始化
用 =, () 和 {} 均可.
小心使用列表初始化 {…} 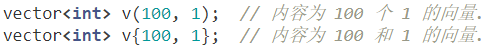
9.14. 预处理指令
预处理指令不要缩进, 从行首开始。即使预处理指令位于缩进代码块中, 指令也应从行首开始.
9.15. 类格式
在类中,控制块的声明依次序是 public:, protected:, private:, 每个都缩进 1 个空格.
注意事项:
- 所有基类名应在每行 80 列限制下尽量与子类名放在同一行.
- 关键词 public:, protected:, private: 前面缩进 1 个空格.
- 除第一个关键词 (一般是 public) 外, 其他关键词前要空一行. 如果类比较小的话也可以不空.
- 这些关键词后不要保留空行.
- public 放在最前面, 然后是 protected, 最后是 private.
- 关于声明顺序的规则请参考 声明顺序 一节.
9.16. 构造函数初始值列表
构造函数初始化列表放在同一行或按四格缩进并排多行.
9.17. 命名空间格式化
命名空间内容不缩进.
声明嵌套命名空间时, 每个命名空间都独立成行.
9.18. 水平留白
通用
循环和条件语句
操作符
模板和转换
9.19. 垂直留白
垂直留白越少越好.
不在万不得已, 不要使用空行. 尤其是: 两个函数定义之间的空行不要超过 2 行, 函数体首尾不要留空行, 函数体中也不要随意添加空行.
10. 规则特例
10.1. 现有不合规范的代码
当你修改使用其他风格的代码时, 为了与代码原有风格保持一致可以不使用本指南约定. 自己从新开始的代码,最好遵从本指南。
10.2. Windows 代码
如果你习惯使用 Windows 编码风格, 这儿有必要重申一下某些你可能会忘记的指南:
- 不要使用匈牙利命名法 (比如把整型变量命名成 iNum). 使用 Google 命名约定, 包括对源文件使用 .cc 扩展名.
- Windows 定义了很多原生类型的同义词 (YuleFox 注: 这一点, 我也很反感), 如 DWORD, HANDLE 等等. 在调用 Windows API 时这是完全可以接受甚至鼓励的. 即使如此, 还是尽量使用原有的 C++ 类型, 例如使用 const TCHAR * 而不是 LPCTSTR.
- 使用 Microsoft Visual C++ 进行编译时, 将警告级别设置为 3 或更高, 并将所有警告(warnings)当作错误(errors)处理.
- 不要使用 #pragma once; 而应该使用 Google 的头文件保护规则. 头文件保护的路径应该相对于项目根目录 (Yang.Y 注: 如 #ifndef SRCDIR_BAR_H, 参考 #define 保护 一节).
除非万不得已, 不要使用任何非标准的扩展, 如 #pragma 和 declspec. 使用 declspec(dllimport) 和 __declspec(dllexport) 是允许的, 但必须通过宏来使用, 比如 DLLIMPORT和 DLLEXPORT, 这样其他人在分享使用这些代码时可以很容易地禁用这些扩展.
在 Windows 上仍然有一些我们偶尔需要违反的规则:
通常我们 禁止使用多重继承, 但在使用 COM 和 ATL/WTL 类时可以使用多重继承. 为了实现 COM 或 ATL/WTL 类/接口, 你可能不得不使用多重实现继承.
- 虽然代码中不应该使用异常, 但是在 ATL 和部分 STL(包括 Visual C++ 的 STL) 中异常被广泛使用. 使用 ATL 时, 应定义 _ATL_NO_EXCEPTIONS 以禁用异常. 你需要研究一下是否能够禁用 STL 的异常, 如果无法禁用, 可以启用编译器异常. (注意这只是为了编译 STL, 自己的代码里仍然不应当包含异常处理).
- 通常为了利用头文件预编译, 每个每个源文件的开头都会包含一个名为 StdAfx.h 或 precompile.h的文件. 为了使代码方便与其他项目共享, 请避免显式包含此文件 (除了在 precompile.cc 中), 使用 /FI 编译器选项以自动包含该文件.
- 资源头文件通常命名为 resource.h 且只包含宏, 这一文件不需要遵守本风格指南.
11. 结束语
运用常识和判断力, 并且 保持一致.
编辑代码时, 花点时间看看项目中的其它代码, 并熟悉其风格.

若有收获,就点个赞吧
0 人点赞
