第03讲:如何设计与实现统一资源管理与调度系统
Hadoop 2.0 与 Hadoop 1.0 最大的变化就是引入了 YARN,而 Spark 在很多情况下,往往也是基于 YARN 运行,所以,相比于分布式文件系统 HDFS,YARN 是一个比较关键的组件,承担着计算资源管理与调度的工作,所以本课时将对其进行深入讨论,先务虚再务实,主要内容如下:
- 统一资源管理与调度系统的设计;
- 统一资源管理与调度系统的实现——YARN。
统一资源管理与调度系统的设计
YARN 的全称是 Yet Another Resource Negotiator,直译过来是:另一种资源协调者,但是它的标准名称是统一资源管理与调度系统,这个名称比较抽象,当遇到这种抽象的名词时,我喜欢把概念拆开来看,那么这个名称一共包含 3 个词:统一、资源管理、调度。
来看看第 1 个词语:统一
对于大数据计算框架来说,统一指的是资源并不会与计算框架绑定,对于所有计算框架来说,所有资源都是无差别的,也就是说这个系统可以支持多种计算框架,但这是狭义的统一,我们理解到这里就可以了。而广义上的统一,是指资源针对所有应用来说都是无差别的,包括长应用、短应用、数据库、后端服务,等等。
来看看第 2 个词语:资源管理
对于资源管理来说,最重要的是了解对于这个系统,什么才是它的资源,或者说是资源的维度,常见的有 CPU、内存、磁盘、网络带宽等,对于 YARN 来说,资源的维度有两个:CPU 和内存。这也是大数据计算框架最需要的资源。
最后一个词语:调度
说到调度,就没那么简单了。目前的宏观调度机制一共有 3 种:集中式调度器(Monolithic Scheduler)、双层调度器(Two-Level Scheduler)和状态共享调度器(Shared-State Scheduler),我们一个一个来说:
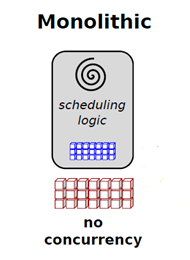
- 集中式调度器(Monolithic Scheduler)
集中式调度器全局只有一个中央调度器,计算框架的资源申请全部提交给中央调度器来满足,所有的调度逻辑都由中央调度器来实现。所以调度系统在高并发作业的情况下,容易出现性能瓶颈,如下图所示,红色的方块是集群资源信息,调度器拥有全部的集群资源信息(蓝色方块),集中式调度器的实现就是 Hadoop MapReduce 的 JobTracker,实际的资源利用率只有 70% 左右,甚至更低。Jobtracker 有多不受欢迎呢,从 Hadoop 2.0 中 YARN 的名字就可以看出:另一种资源协调器,你细品。这种在多个计算作业同时申请资源的时候,中央调度器实际上是没有并发的,完全是顺序执行。
- 双层调度器(Two-Level Scheduler)
顾名思义,双层调度器将整个调度工作划分为两层:中央调度器和框架调度器。中央调度器管理集群中所有资源的状态,它拥有集群所有的资源信息,按照一定策略(例如 FIFO、Fair、Capacity、Dominant Resource Fair)将资源粗粒度地分配给框架调度器,各个框架调度器收到资源后再根据应用申请细粒度将资源分配给容器执行具体的计算任务。在这种双层架构中,每个框架调度器看不到整个集群的资源,只能看到中央调度器给自己的资源,如图所示:
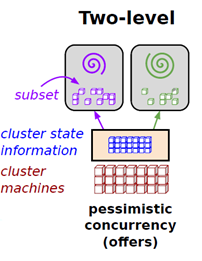
紫色和绿色的圆圈所在的方框是框架调度器,可以看到中央调度器把全部资源的两个子集分别交给了两个框架调度器,注意看,这两个子集是没有重合的,这种机制类似于并发中的悲观并发。
- 状态共享调度器
状态共享调度器是由 Google 的 Omega 调度系统所提出的一种新范型,与谷歌的其他论文不同,Omega 这篇论文对详细设计语焉不详,只简单说了下大体原理和与其他调度范型的比较。
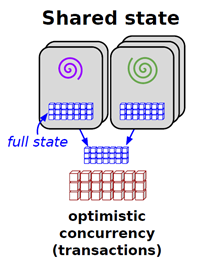
状态共享式调度大大弱化了中央调度器,它只需保存一份集群使用信息,就是图中间的蓝色方块,取而代之的是各个框架调度器,每个调度器都能获取集群的全部信息,并采用乐观锁控制并发。Omega 与双层调度器的不同在于严重弱化了中央调度器,每个框架内部会不断地从主调度器更新集群信息并保存一份,而框架对资源的申请则会在该份信息上进行,一旦框架做出决策,就会将该信息同步到主调度。资源竞争过程是通过事务进行的,从而保证了操作的原子性。由于决策是在自己的私有数据上做出的,并通过原子事务提交,系统保证只有一个胜出者,这是一种类似于 MVCC 的乐观并发机制,可以增加系统的整体并发性能,但是调度公平性有所不足。对于这种调度范式你可以不用深究,这里介绍主要是为了知识的完整性。
统一资源管理与调度系统的实现:YARN
前面一直在务虚,现在让我们来务实一下。YARN 是 Hadoop 2.0 引入的统一资源管理和调度系统,也很具有代表性,目前 Spark on YARN 这种模式也在大量使用,所以接下来,我们来讨论下 YARN。
简单来看看 YARN 的架构图,YARN 的架构是典型的主从架构,主节点是 ResourceManger,也是我们前面说的主调度器,所有的资源的空闲和使用情况都由 ResourceManager 管理。ResourceManager 也负责监控任务的执行,从节点是 NodeManager,主要负责管理 Container 生命周期,监控资源使用情况等 ,Container 是 YARN 的资源表示模型,Task 是计算框架的计算任务,会运行在 Container 中,ApplicationMaster 可以暂时认为是二级调度器,比较特殊的是它同样运行在 Container 中。
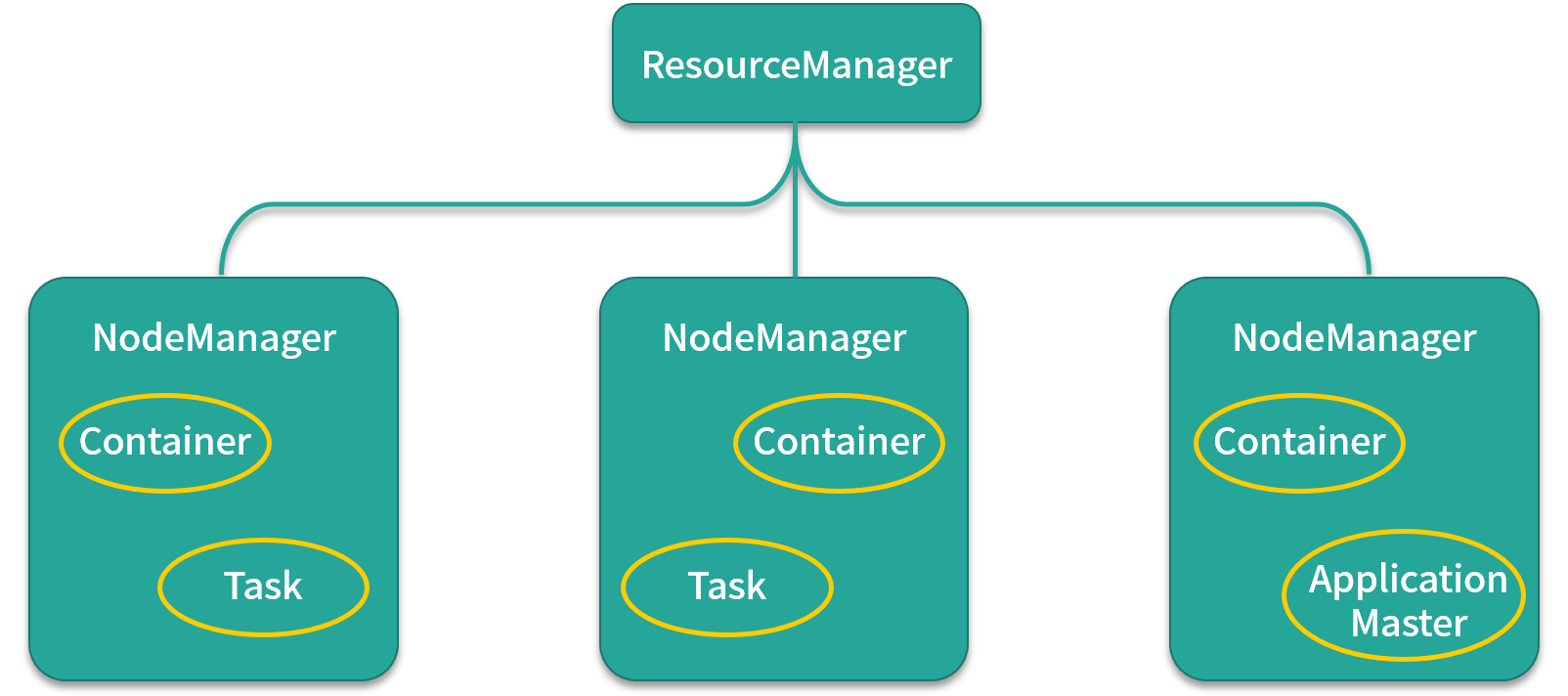
我们来看看 YARN 启动一个 MapReduce 作业的流程,如图所示:
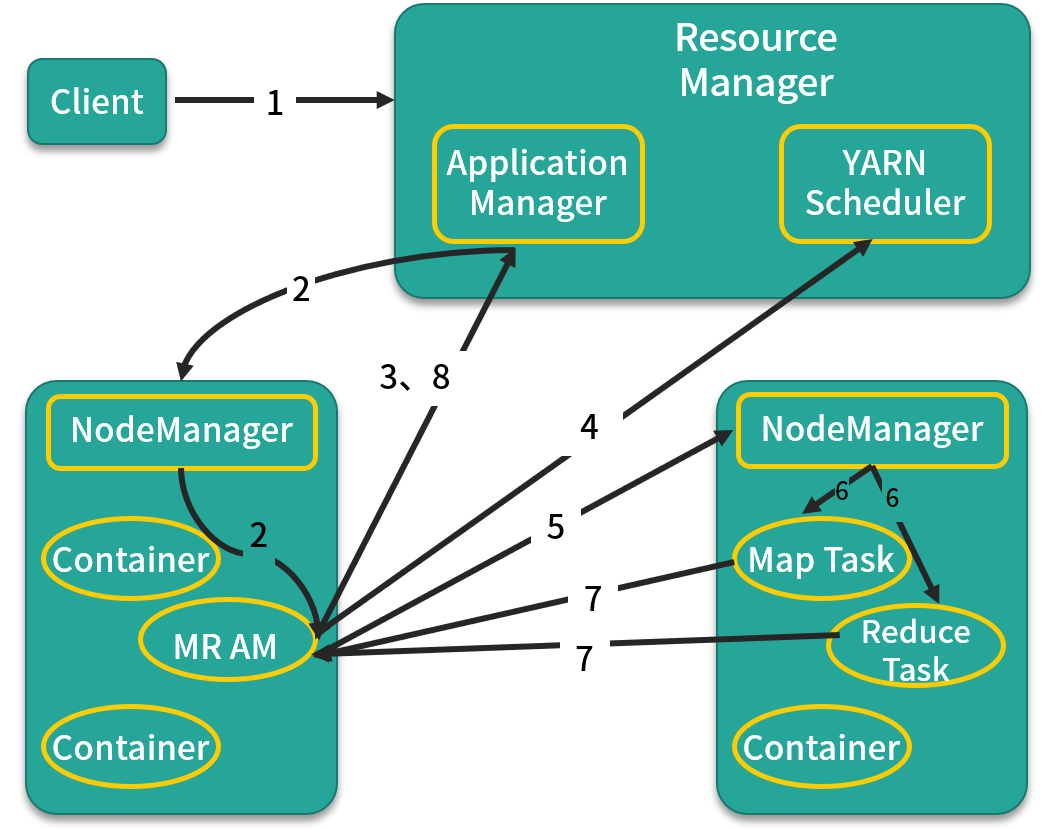
第 1 步:客户端向 ResourceManager 提交自己的应用,这里的应用就是指 MapReduce 作业。
第 2 步:ResourceManager 向 NodeManager 发出指令,为该应用启动第一个 Container,并在其中启动 ApplicationMaster。
第 3 步:ApplicationMaster 向 ResourceManager 注册。
第 4 步:ApplicationMaster 采用轮询的方式向 ResourceManager 的 YARN Scheduler 申领资源。
第 5 步:当 ApplicationMaster 申领到资源后(其实是获取到了空闲节点的信息),便会与对应 NodeManager 通信,请求启动计算任务。
第 6 步:NodeManager 会根据资源量大小、所需的运行环境,在 Container 中启动任务。
第 7 步:各个任务向 ApplicationMaster 汇报自己的状态和进度,以便让 ApplicationMaster 掌握各个任务的执行情况。
第 8 步:应用程序运行完成后,ApplicationMaster 向 ResourceManager 注销并关闭自己。
结合这 8 步,再结合前面的调度范式,相信你已经对 YARN 的这种机制有了更深刻的理解。上面这 8 步,有些时候面试官会喜欢问,记住就行了。
好了,到现在为止,我都没有说明 YARN 到底属于哪一种调度范式,现在绝大多数资料与网上的文章都将 YARN 归为双层调度,这个说法准确吗?ApplicationMaster 与前面讲的框架调度器(二级调度器)很像,回答这个问题有点复杂,涉及到对调度范式得深刻理解,我简单讲下,你可以看看前面那种双层调度的范式图:
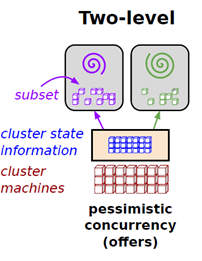
首先可以看到最下面的一个单词是 offers,还有蓝色和绿色的箭头方向,这说明什么问题呢?主调度器拥有整个集群资源的的状态,通过 Offer(主动提供,而不是被动请求)方式通知每个二级调度器有哪些可用的资源。每个二级调度器根据自己的需求决定是否占有提供的资源,决定占有后,该分区内的资源由二级调度器全权负责。
这句话怎么理解呢?如果你将集群资源看成一个整体,那么这种方式可以认为是预先将整个资源进行动态分区。作业则向二级调度器申请资源,可以多个作业共用一个二级调度器,此外,每个二级调度器和主调器都可以配置不同的调度算法模块。那么从这个点上来说,YARN 离真正的双层调度还有些差距,但和前面讲的 JobTracker 相比,已经是很大的进步了,并显著提升了调度性能,某度程度上,也可以说是一种双层调度,或者更准确地说,两次调度。所以如果在面试中,遇到这个问题,除非你和面试官都真的完全理解了 YARN 和双层调度的距离,否则还是回答 YARN 是双层调度吧。
由于 Spark 与 MapReduce 相比,是一种 DAG 计算框架,包含一系列的计算任务,比较特殊,所以 Spark 自己实现了一个集中式调度器 Driver,用来调用作业内部的计算任务。申请到的资源可以看成是申请分区资源,在该分区内,所有资源由 Driver 全权使用,以客户端方式提交的 Spark on Yarn 这种方式可以看成是 Driver 首先在资源管理和调度系统中注册为框架调度器(二级调度器),接收到需要得资源后,再开始进行作业调度。那么这种方式可以认为是一种曲线救国的双层调度实现方式,这个我们后面会讲到。
小结
本课时先介绍了三种调度范式:集中式、双层与状态共享,其中最常用的是双层调度模型,后面介绍了目前比较常用的一种统一资源管理与调度系统 YARN,Spark on YARN 也是非常常见的一种部署模式。由于 YARN 目前支持计算框架而不支持应用服务,可以看出,离真正的统一还有距离。此外,在绝大多数场景中,YARN 几乎都不会让你感觉到它的存在,所以对于分析师来说,本课时的内容你只需要了解就可以了。
(资料来源:拉勾教育 - 即学即用的Spark实战44讲)

若有收获,就点个赞吧
0 人点赞
