这个课时我们将进入:“Spark 核心数据结构:弹性分布式数据集 RDD”的学习,今天的课程内容有两个:
- RDD 的核心概念
- 实践环节:如何创建 RDD。
RDD 的核心概念
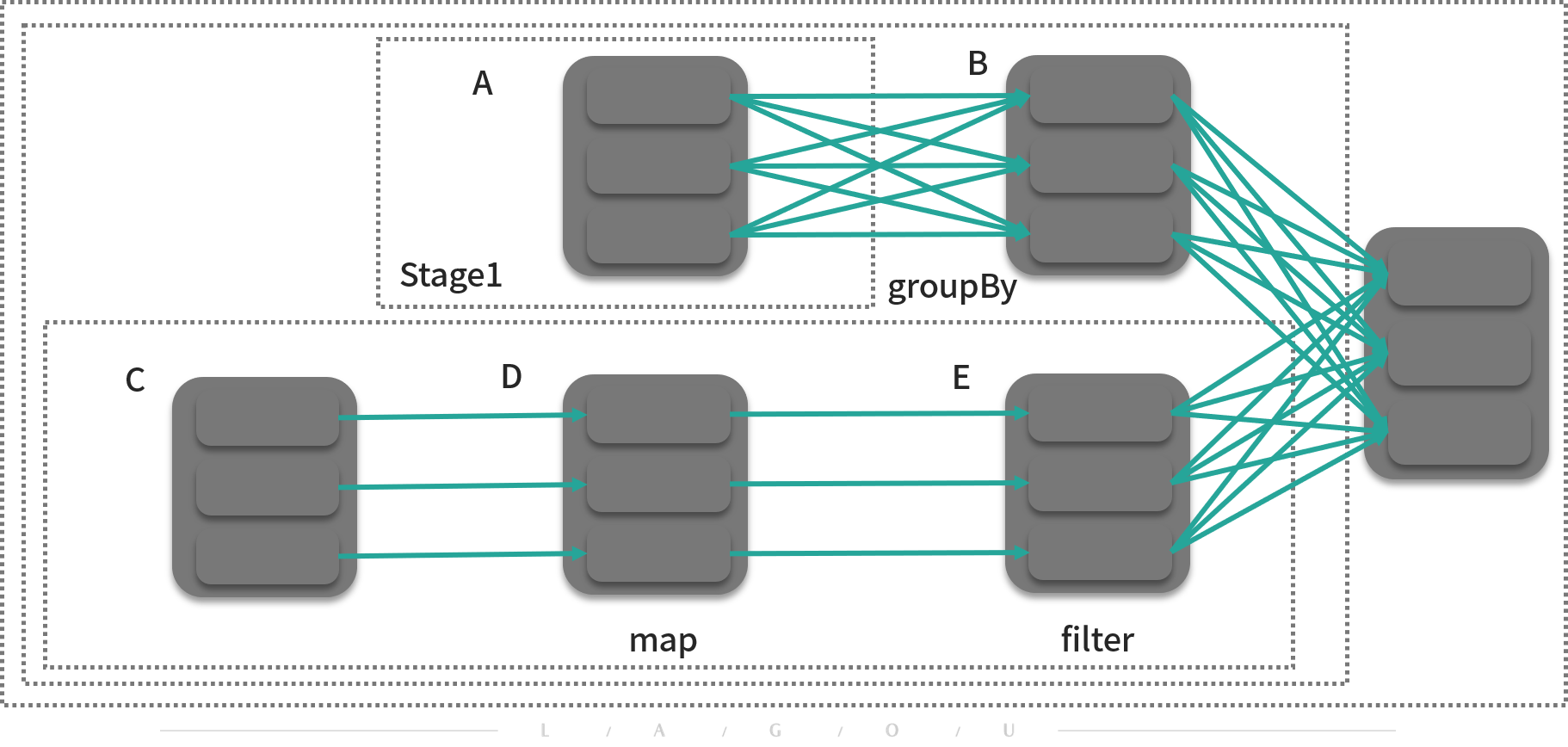
RDD 是 Spark 最核心的数据结构,RDD(Resilient Distributed Dataset)全称为弹性分布式数据集,是 Spark 对数据的核心抽象,也是最关键的抽象,它实质上是一组分布式的 JVM 不可变对象集合,不可变决定了它是只读的,所以 RDD 在经过变换产生新的 RDD 时,(如下图中 A-B),原有 RDD 不会改变。
弹性主要表现在两个方面:
- 在面对出错情况(例如任意一台节点宕机)时,Spark 能通过 RDD 之间的依赖关系恢复任意出错的 RDD(如 B 和 D 可以算出最后的 RDD),RDD 就像一块海绵一样,无论怎么挤压,都像海绵一样完整;
- 在经过转换算子处理时,RDD 中的分区数以及分区所在的位置随时都有可能改变。
每个 RDD 都有如下几个成员:
- 分区的集合;
- 用来基于分区进行计算的函数(算子);
- 依赖(与其他 RDD)的集合;
- 对于键-值型的 RDD 的散列分区器(可选);
- 对于用来计算出每个分区的地址集合(可选,如 HDFS 上的块存储的地址)。
如下图所示,RDD_0 根据 HDFS 上的块地址生成,块地址集合是 RDD_0 的成员变量,RDD_1由 RDD_0 与转换(transform)函数(算子)转换而成,该算子其实是 RDD_0 内部成员。从这个角度上来说,RDD_1 依赖于 RDD_0,这种依赖关系集合也作为 RDD_1 的成员变量而保存。
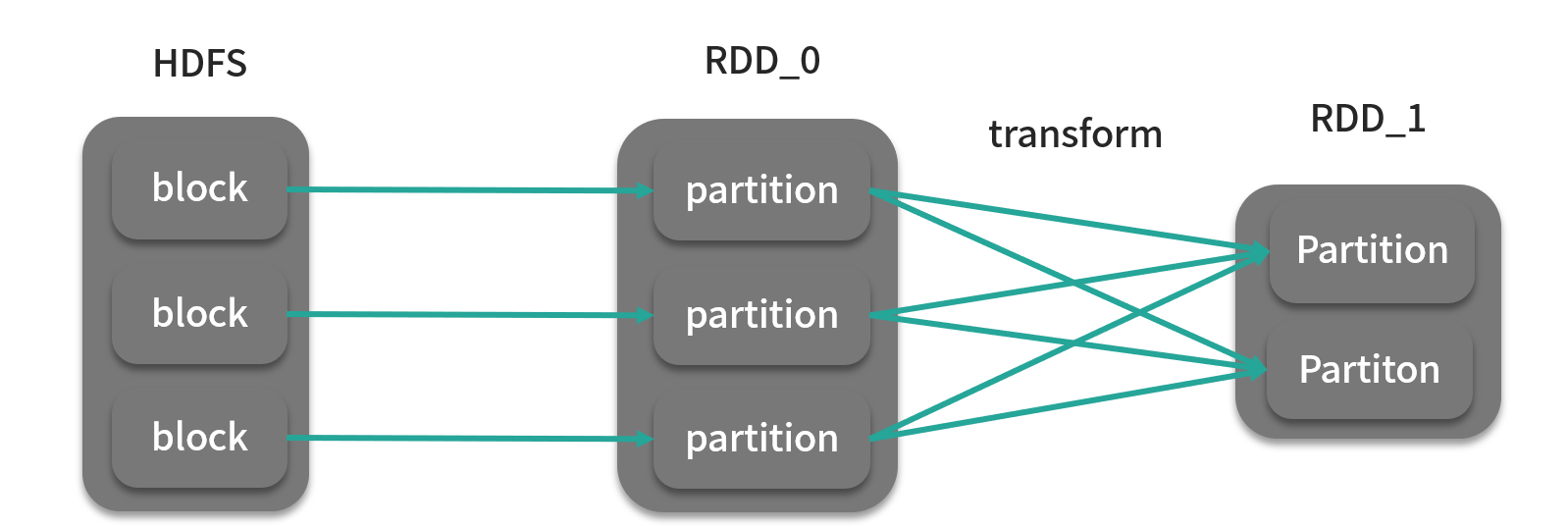
在 Spark 源码中,RDD 是一个抽象类,根据具体的情况有不同的实现,比如 RDD_0 可以是 MapPartitionRDD,而 RDD_1 由于产生了 Shuffle(数据混洗,后面的课时会讲到),则是 ShuffledRDD。
下面我们来看一下 RDD 的源码,你也可以和前面对着看看:
// 表示RDD之间的依赖关系的成员变量@transient private var deps: Seq[Dependency[_]]// 分区器成员变量@transient val partitioner: Option[Partitioner] = None// 该RDD所引用的分区集合成员变量@transient private var partitions_ : Array[Partition] = null// 得到该RDD与其他RDD之间的依赖关系protected def getDependencies: Seq[Dependency[_]] = deps// 得到该RDD所引用的分区protected def getPartitions: Array[Partition]// 得到每个分区地址protected def getPreferredLocations(split: Partition): Seq[String] = Nil// distinct算子def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] =withScope {map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)}
其中,你需要特别注意这一行代码:
@transient private var partitions_ : Array[Partition] = null
它说明了一个重要的问题,RDD 是分区的集合,本质上还是一个集合,所以在理解时,你可以用分区之类的概念去理解,但是在使用时,就可以忘记这些,把其当做是一个普通的集合。为了再加深你的印象,我们来理解下模块 1 中 01 课时的 4 行代码:
val list: List[Int] = List(1,2,3,4,5)println(list.map(x => x + 1).filter { x => x > 1}.reduce(_ + _))......val list: List[Int] = spark.sparkContext.parallelize(List(1,2,3,4,5))println(list.map(x => x + 1).filter { x => x > 1}.reduce(_ + _))
实践环节:创建 RDD
我一直强调,Spark 编程是一件不难的工作,而事实也确实如此。在上一课时我们讲解了创建 SparkSession 的代码,现在我们可以通过已有的 SparkSession 直接创建 RDD。在创建 RDD 之前,我们可以将 RDD 的类型分为以下几类:
- 并行集合;
- 从 HDFS 中读取;
- 从外部数据源读取;
- PairRDD。
了解了 RDD 的类型,接下来我们逐个讲解它们的内容:
并行化集合
这种 RDD 纯粹是为了学习,将内存中的集合变量转换为 RDD,没太大实际意义。
//val spark: SparkSession = .......val rdd = spark.sparkcontext.parallelize(Seq(1, 2, 3))
从 HDFS 中读取
这种生成 RDD 的方式是非常常用的。
//val spark: SparkSession = .......val rdd = spark.sparkcontext.textFile("hdfs://namenode:8020/user/me/wiki.txt")
从外部数据源读取
Spark 从 MySQL 中读取数据返回的 RDD 类型是 JdbcRDD,顾名思义,是基于 JDBC 读取数据的,这点与 Sqoop 是相似的,但不同的是 JdbcRDD 必须手动指定数据的上下界,也就是以 MySQL 表某一列的最值作为切分分区的依据。
//val spark: SparkSession = .......val lowerBound = 1val upperBound = 1000val numPartition = 10val rdd = new JdbcRDD(spark.sparkcontext,() => {Class.forName("com.mysql.jdbc.Driver").newInstance()DriverManager.getConnection("jdbc:mysql://localhost:3306/db", "root", "123456")},"SELECT content FROM mysqltable WHERE ID >= ? AND ID <= ?",lowerBound,upperBound,numPartition,r => r.getString(1))
既然是基于 JDBC 进行读取,那么所有支持 JDBC 的数据库都可以通过这种方式进行读取,也包括支持 JDBC 的分布式数据库,但是你需要注意的是,从代码可以看出,这种方式的原理是利用多个 Executor 同时查询互不交叉的数据范围,从而达到并行抽取的目的。但是这种方式的抽取性能受限于 MySQL 的并发读性能,单纯提高 Executor 的数量到某一阈值后,再提升对性能影响不大。
上面介绍的是通过 JDBC 读取数据库的方式,对于 HBase 这种分布式数据库来说,情况有些不同,HBase 这种分布式数据库,在数据存储时也采用了分区的思想,HBase 的分区名为 Region,那么基于 Region 进行导入这种方式的性能就会比上面那种方式快很多,是真正的并行导入。
//val spark: SparkSession = .......val sc = spark.sparkcontextval tablename = "your_hbasetable"val conf = HBaseConfiguration.create()conf.set("hbase.zookeeper.quorum", "zk1,zk2,zk3")conf.set("hbase.zookeeper.property.clientPort", "2181")conf.set(TableInputFormat.INPUT_TABLE, tablename)val rdd= sc.newAPIHadoopRDD(conf, classOf[TableInputFormat],classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable],classOf[org.apache.hadoop.hbase.client.Result])// 利用HBase API解析出行键与列值rdd_three.foreach{case (_,result) => {val rowkey = Bytes.toString(result.getRow)val value1 = Bytes.toString(result.getValue("cf".getBytes,"c1".getBytes))}
值得一提的是 HBase 有一个第三方组件叫 Phoenix,可以让 HBase 支持 SQL 和 JDBC,在这个组件的配合下,第一种方式也可以用来抽取 HBase 的数据,此外,Spark 也可以读取 HBase 的底层文件 HFile,从而直接绕过 HBase 读取数据。说这么多,无非是想告诉你,读取数据的方法有很多,可以根据自己的需求进行选择。
通过第三方库的支持,Spark 几乎能够读取所有的数据源,例如 Elasticsearch,所以你如果要尝试的话,尽量选用 Maven 来管理依赖。
PairRDD
PairRDD 与其他 RDD 并无不同,只不过它的数据类型是 Tuple2[K,V],表示键值对,因此这种 RDD 也被称为 PairRDD,泛型为 RDD[(K,V)],而普通 RDD 的数据类型为 Int、String 等。这种数据结构决定了 PairRDD 可以使用某些基于键的算子,如分组、汇总等。PairRDD 可以由普通 RDD 转换得到:
//val spark: SparkSession = .......val a = spark.sparkcontext.textFile("/user/me/wiki").map(x => (x,x))
小结
本课时带你学习完了 Spark 最核心的概念 RDD,本质上它可以看成是一个分布式的数据集合,它的目的就是隔离分布式数据集的复杂性,你也自己尝试了几种类型的 RDD。在实际情况中,大家经常会遇到从外部数据源读取成为RDD,如果理解了读取的本质,那么无论是什么数据源都能够轻松应对了。
这里我要给你留个思考题:如何指定你创建的 RDD 的分区数?

若有收获,就点个赞吧
0 人点赞
