通过前面一系列课时的学习,我想你基本已经了解进入编程环节前需要掌握的内容,那么本课时就带你正式进入 Spark 编程的学习。
Spark 编程风格主要有函数式,核心是基于数据处理的需求,用算子与 RDD 构建出一个数据管道,管道的开始是输入,管道的末尾是输出。而管道就是声明的处理逻辑,可以说是描述了一种映射方式。
不同种类的算子
RDD 算子主要分为两类,一类为转换(transform)算子,一类为行动(action)算子,转换算子主要负责改变 RDD 中数据、切分 RDD 中数据、过滤掉某些数据等,并按照一定顺序组合。Spark 会将转换算子放入一个计算的有向无环图中,并不立刻执行,当 Driver 请求某些数据时,才会真正提交作业并触发计算,而行动算子就会触发 Driver 请求数据。这种机制与函数式编程思想的惰性求值类似。这样设计的原因首先是避免无谓的计算开销,更重要的是 Spark 可以了解所有执行的算子,从而设定并优化执行计划。
RDD 转换算子大概有 20~30 多个,按照 DAG 中分区与分区之间的映射关系来分组,有如下 3 类:
- 一对一,如 map;
- 多对一,如 union;
- 多对多,如 groupByKey。
而按照 RDD 的结构可以分为两种:
- Value 型 RDD;
- Key-Value 型 RDD(PairRDD)。
按照转换算子的用途,我将其分为以下 4 类:
- 通用类;
- 数学/统计类;
- 集合论与关系类;
- 数据结构类。
在介绍算子时,并没有刻意区分 RDD 和 Pair RDD,你可以根据 RDD 的泛型来做判断,此外,通常两个功能相似的算子,如 groupBy 与 groupByKey,底层都是先将 Value 型 RDD 转换成 Key Value 型 RDD,再直接利用 Key Value 型 RDD 完成转换功能,故不重复介绍。
在学习算子的时候,你千万不要觉得这是一个多么高深的东西,首先,对于声明式编程来说,编程本身难度不会太大。其次,我在这里给你交个底,几乎所有的算子,都可以用 map、reduce、filter 这三个算子通过组合进行实现,你在学习完本课时之后,可以试着自己做做。下面,我们就选取这 4 类中有代表性、常用的算子进行介绍。
1. 通用类
这一类可以满足绝大多数需要,特别适合通用分析型需求。
map
def map[U: ClassTag](f: T => U): RDD[U]def map(self, f, preservesPartitioning=False)
这里第 1 行为算子的 Scala 版,第 2 行为算子的 Python 版,后面同理,不再做特别说明。
map 算子是最常用的转换算子,它的作用是将原 RDD 分区中 T 类型的数据元素转换成 U 类型,并返回为一个新 RDD。map 算子会作用于分区内的每个元素,如下图所示。
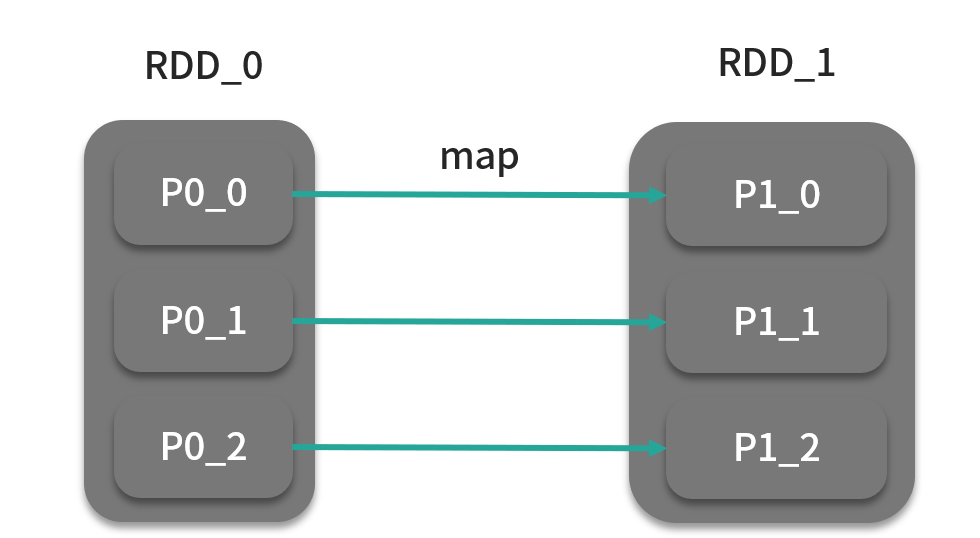
当然 T 和 U 也可以是同一个类型,具体的转换逻辑由自定义函数 f 完成,可能你会不太适应这种函数直接作为算子的参数,下面以 map 算子为例:
>>> rdd = sc.parallelize(["b", "a", "c"])>>> sorted(rdd.map(lambda x: (x, 1)).collect())[('a', 1), ('b', 1), ('c', 1)]
这是 Python 版的,逻辑很简单,对单词进行处理,注意看这里不光是用函数作为参数,而且是用 Python 的匿名函数 lambda 表达式的写法,这种匿名声明的方式是比较常用的。如果是 Scala 版的,匿名函数的写法则更为简单:
rdd.map { x => (x,1) }.collect()
Scala 还有种更简单的写法:
rdd.map ((_,1)).collect()
这种写法我是这样看的,这么写当然更为简洁,但是如果你暂时理解不了,没必要去深究它,直接用上一种写法就好了。
filter
def filter(f: T => Boolean): RDD[T]def filter(self, f)
filter算子可以通过用户自定义规则过滤掉某些数据,f 返回值为 true 则保留,false 则丢弃,如图:
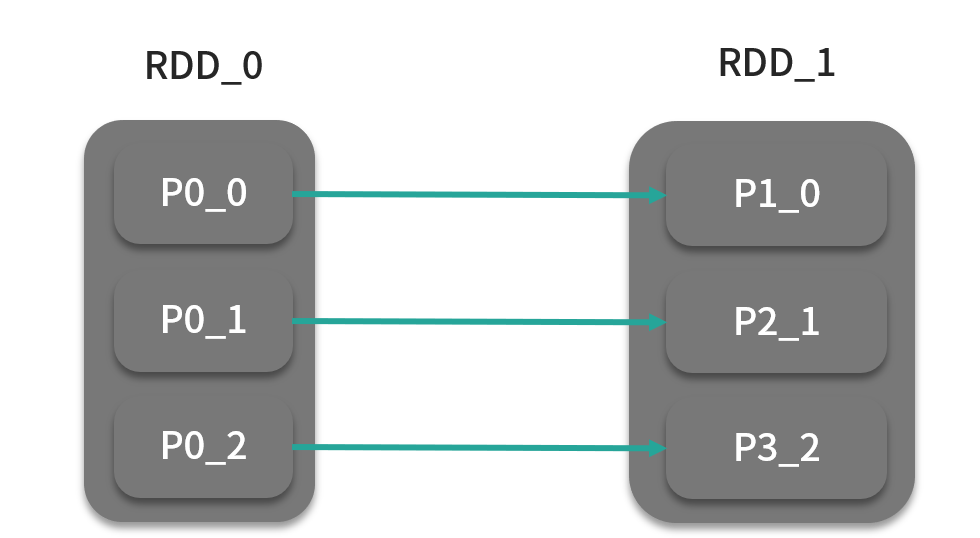
该算子作用之后,可能会造成大量零碎分区,不利于后面计算过程,需要在这之前进行合并。
reduceByKey
def reduceByKey(func: (V, V) => V): RDD[(K, V)]def reduceByKey(self, func, numPartitions=None, partitionFunc=portable_hash)
reduceByKey 算子执行的是归约操作,针对相同键的数据元素两两进行合并。在合并之前,reduceByKey 算子需要将相同键的元素分发到一个分区中去,分发规则可以自定义,分发的分区数量也可以自定义,所以该算子还可以接收分区器或者分区数作为参数,分区器在没有指定时,采用的是 RDD 内部的哈希分区器,如下图:
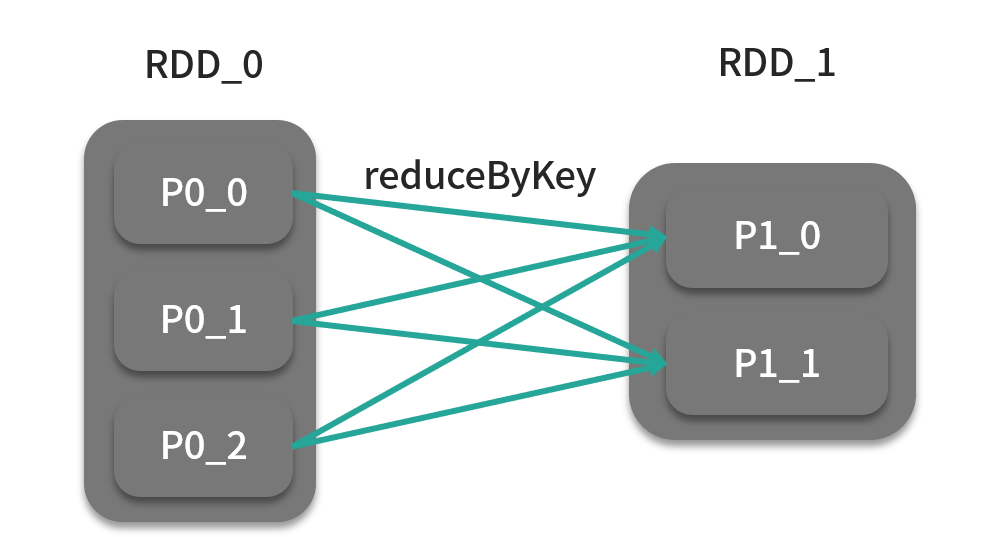
groupByKey
def groupByKey(): RDD[(K, Iterable[V])]def groupByKey(self, numPartitions=None, partitionFunc=portable_hash)
groupByKey 在统计分析中很常用到,是分组计算的前提,它默认按照哈希分区器进行分发,将同一个键的数据元素放入到一个迭代器中供后面的汇总操作做准备,它的可选参数分区数、分区器,如下图:
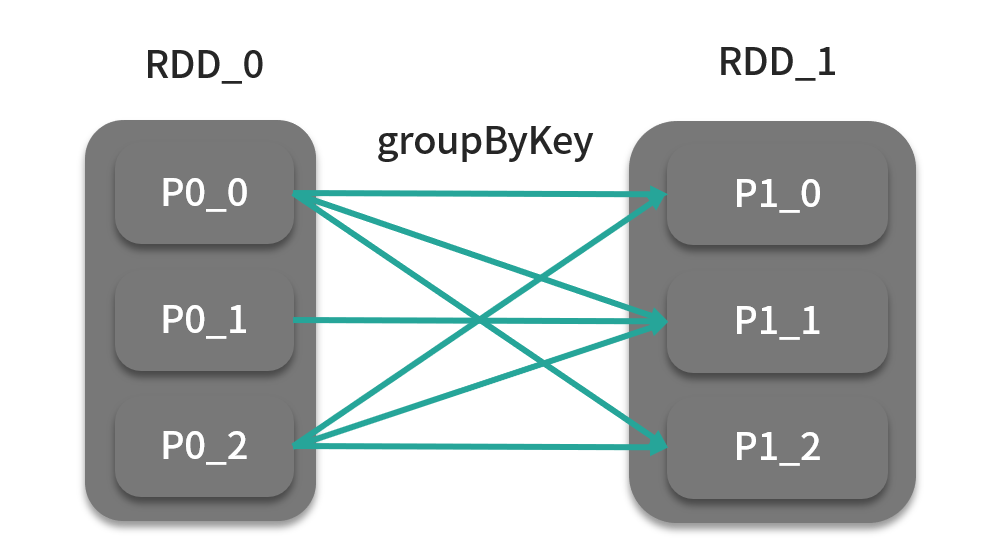
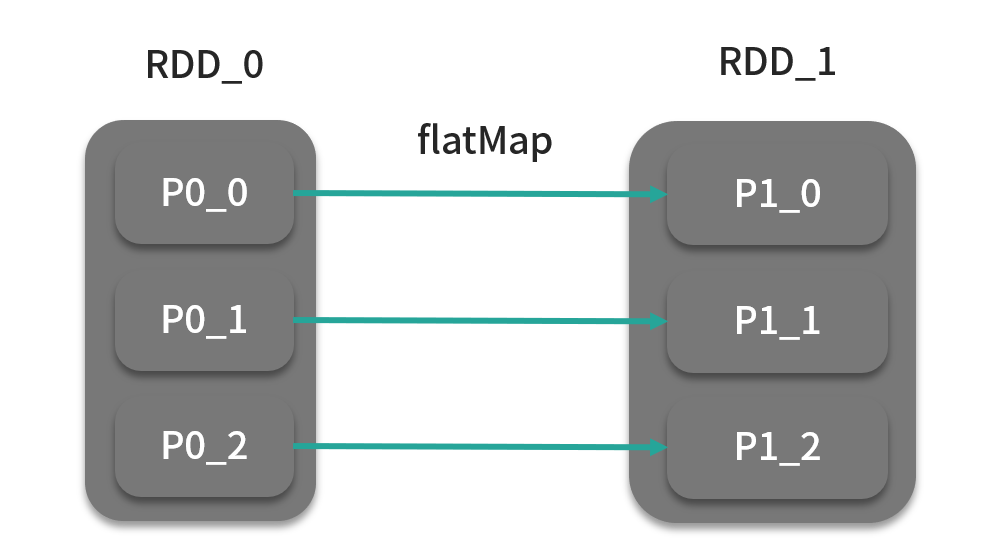
flatMap
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U]def flatMap(self, f, preservesPartitioning=False)
flatMap 算子的字面意思是“展平”,flatMap 算子的函数 f 的作用是将 T 类型的数据元素转换为元素类型为 U 的集合,如果处理过程到此为止,我们将 RDD_1 的一个分区看成一个集合的话,分区数据结构相当于集合的集合,由于集合的集合是有层次的 你可以理解为一个年级有多个班级,而这种数据结构就不是“平”的,所以 flatMap 算子还做了一个操作:将集合的集合合并为一个集合。如下图:
2. 数学/统计类
sampleByKey
这类算子实现的是某些常用的数学或者统计功能,如分层抽样等。
def sampleByKey(withReplacement: Boolean, fractions: Map[K, Double], seed: Long = Utils.random.nextLong): RDD[(K, V)]def sampleByKey(self, withReplacement, fractions, seed=None)
分层抽样是将数据元素按照不同特征分成不同的组,然后从这些组中分别抽样数据元素。Spark 内置了实现这一功能的算子 sampleByKey,withReplacement 参数表示此次抽样是重置抽样还是不重置抽样,所谓重置抽样就是“有放回的抽样”,单次抽样后会放回。fractions 是每个键的抽样比例,以 Map 的形式提供。seed 为随机数种子,一般设置为当前时间戳。
3. 集合论与关系类
这类算子主要实现的是像连接数据集这种功能和其他关系代数的功能,如交集、差集、并集、笛卡儿积等。
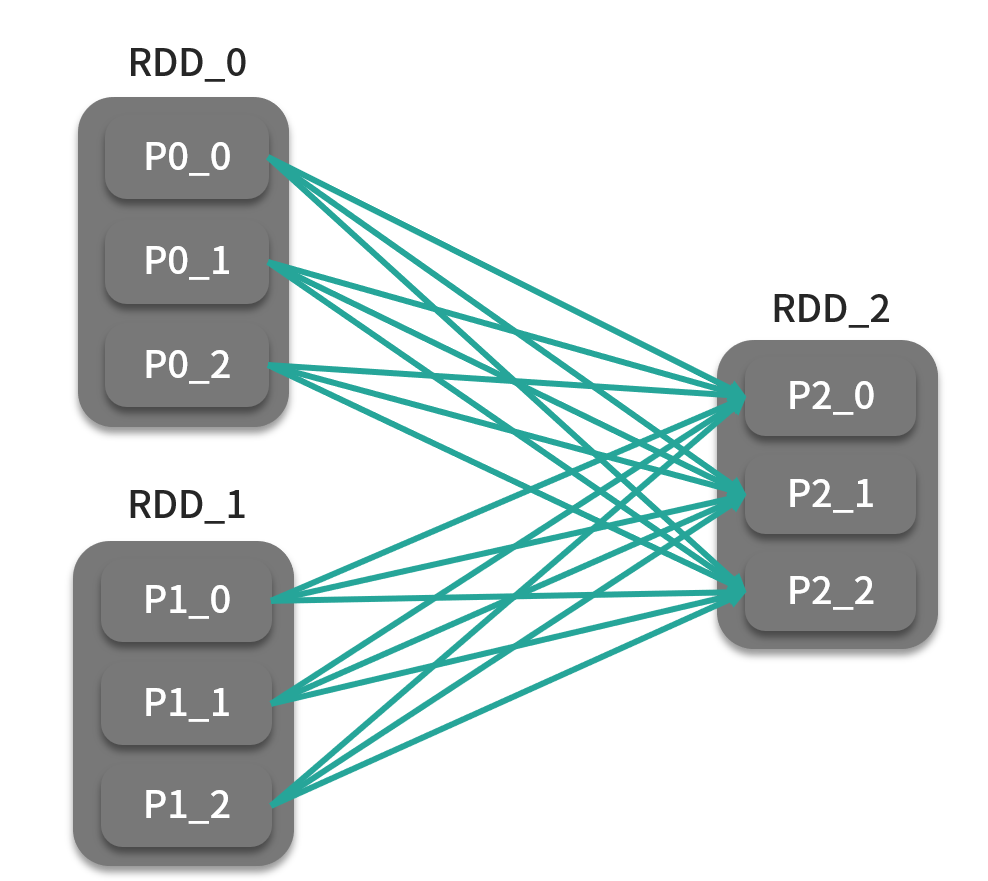
cogroup
def cogroup[W](other: RDD[(K, W)]): RDD[(K, (Iterable[V], Iterable[W]))]def cogroup(self, other, numPartitions=None)
cogroup 算子是很多算子的基础,如 intersection、join 等。简单来说,cogroup 算子相当于多个数据集一起做 groupByKey 操作,生成的 Pair RDD 的数据元素类型为 (K, (Iterable[V], Iterable[W])),其中第 1 个迭代器为当前键在 RDD_0 中的分组结果,第 2 个迭代器为 RDD_1 的结果,如下图:
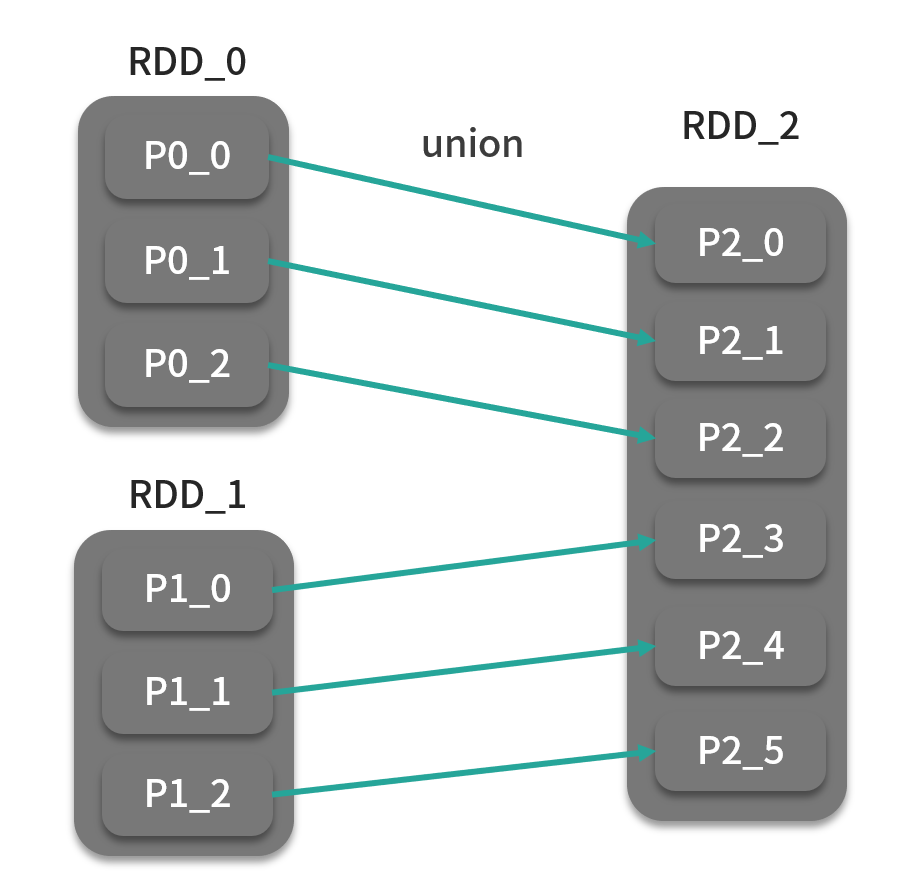
union
def union(other: RDD[T]): RDD[T]def union(self, other)
union 算子将两个同类型的 RDD 合并为一个 RDD,类似于求并集的操作。如下图:
4. 数据结构类
这类算子主要改变的是 RDD 中底层的数据结构,即 RDD 中的分区。在这些算子中,你可以直接操作分区而不需要访问这些分区中的元素。在 Spark 应用中,当你需要更高效地控制集群中的分区和分区的分发时,这些算子会非常有用。通常,我们会根据集群状态、数据规模和使用方式有针对性地对数据进行重分区,这样可以显著提升性能。默认情况下,RDD 使用散列分区器对集群中的数据进行分区。一般情况下,集群中的单个节点会有多个数据分区。数据分区数一般取决于数据量和集群节点数。如果作业中的某个计算任务地输入在本地,我们将其称为数据的本地性,计算任务会尽可能地根据本地性优先选择本地数据。
partitionBy
def partitionBy(partitioner: Partitioner): RDD[(K, V)]:def partitionBy(self, numPartitions, partitionFunc=portable_hash)
partitionBy 会按照传入的分发规则对 RDD 进行重分区,分发规则由自定义分区器实现。
coalesce/repartition
def coalesce(numPartitions: Int, shuffle: Boolean = false, partitionCoalescer: Option [Partition Coalescer] = Option.empty)(implicit ord: Ordering[T] = null): RDD[T]def repartition(num Partitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
coalesce 会试图将 RDD 中分区数变为用户设定的分区数(numPartitions),从而调整作业的并行程度。如果用户设定的分区数(100)小于 RDD 原有分区数(1000),则会进行本地合并,而不会进行 Shuffle;如果用户设定的分区数大于 RDD 原有分区数,则不会触发操作。如果需要增大分区数,则需要将 shuffle 参数设定为 true,这样数据就会通过散列分区器将数据进行分发,以达到增加分区的效果。
还有一种情况,当用户设置分区数为 1 时,如果 shuffle 参数为 false,会对某些节点造成极大的性能负担,用户可以设置 shuffle 参数为 true 来汇总分区的上游计算过程并行执行。repartition 是 coalesce 默认开启 shuffle 的简单封装。另外,你应该能够注意到,大部分转换算子,都提供了 numPartitions 这个可选参数,意味着在作业流程的每一步,你都可以细粒度地控制作业的并行度,从而提高执行时的性能,但这里你需要注意,提交作业后 Executor 的数量是一定的。
行动算子
行动算子从功能上来说作为一个触发器,会触发提交整个作业并开始执行。从代码上来说,它与转换算子的最大不同之处在于:转换算子返回的还是 RDD,行动算子返回的是非 RDD 类型的值,如整数,或者根本没有返回值。
行动算子可以分为 Driver 和分布式两类。
Driver:这种算子返回值通常为 Driver 内部的内存变量,如 collect、count、countByKey 等。这种算子会在远端 Executor 执行计算完成后将结果数据传回 Driver。这种算子的缺点是,如果返回的数据太大,很容易会突破 Driver 内存限制,因此使用这种算子作为作业结束需要谨慎,主要还是用于调试与开发场景。
分布式:与前一类算子将结果回传到 Driver 不同,这类算子会在集群中的节点上“就地”分布式执行,如 saveAsTextFile。这是一种最常用的分布式行动算子。
我们先来看看第一种:
def reduce(f: (T, T) => T): Tdef reduce(self, f)
与转换算子 reduce 类似,会用函数参数两两进行归约,直到最后一个值,返回值类型与 RDD 元素相同。
def foreach(f: T => Unit): Unitdef foreach(self, f)
foreach 算子迭代 RDD 中的每个元素,并且可以自定义输出操作,通过用户传入的函数,可以实现打印、插入到外部存储、修改累加器等迭代所带来的副作用。
还有一些算子类型如 count、reduce、max 等,从字面意思也很好理解,就不逐个介绍了。
以下算子为分布式类型的行动算子:
def saveAsTextFile(path: String): Unitdef saveAsTextFile(self, path, compressionCodecClass=None)
该算子会将 RDD 输出到外部文件系统中,例如 HDFS。这个在实际应用中也比较常用。
下面来看看几个比较特殊的行动算子,在计算过程中,用户可能会经常使用到同一份数据,此时就可以用到 Spark 缓存技术,也就是利用缓存算子将 RDD 进行缓存,从而加速 Spark 作业的执行速度。Spark 缓存算子也属于行动算子,也就是说会触发整个作业开始计算,想要缓存数据,你可以使用 cache 或者 persist 算子,它们是行动算子中仅有的两个返回值为 RDD 的算子。事实上,Spark 缓存技术是加速 Spark 作业执行的关键技术之一,尤其是在迭代计算的场景,效果非常好。
缓存需要尽可能地将数据放入内存。如果没有足够的内存,那么驻留在内存的当前数据就有可能被移除,例如 LRU 策略;如果数据量本身已经超过可用内存容量,这时由于磁盘会代替内存存储数据,性能会下降。
def persist(newLevel: StorageLevel): this.typedef cache(): this.typedef unpersist(blocking: Boolean = true): this.type
其中,cache() = persist(MEMORY_ONLY),Spark 在作业执行过程中会采用 LRU 策略来更新缓存,如果用户想要手动移除缓存的话,也可以采用 unpersist 算子手动释放缓存。其中 persist 可以选择存储级别,选项如下:

如果内存足够大,使用 MEMORY_ONLY 无疑是性能最好的选择,想要节省点空间的话,可以采取 MEMORY_ONLY_SER,可以序列化对象使其所占空间减少一点。DISK是在重算的代价特别昂贵时的不得已的选择。MEMORY_ONLY_2 与 MEMORY_AND_DISK_2 拥有最佳的可用性,但是会消耗额外的存储空间。
小结
本课时介绍了常用的转换算子与行动算子,其中最核心的当然属于通用类的转换算子,其余算子也是非常常用的。另外没有覆盖到的,你可以在使用中通过查阅文档进行学习,这也是学习 Spark 的必经之路。
另外,前面讲到 RDD 是一种分布式集合,那么对于复杂的计算,如果用集合这种形式的数据结构完成计算,未免太复杂、太底层了,也不利于代码的可读性,所以在第 3 个模块中,会学习 Spark 的高级编程接口 DataFrame 和 Spark SQL,如果你是工程师的话,RDD 与算子这种数据处理方式无疑是需要掌握的。
最后,鉴于本课时的内容需要实践加以巩固,所以特地给你留了 3 道习题:
练习题 1:
join 算子其实是 cogroup 和 flatMap 算子组合实现的,现在你自己能实现 join 算子吗?当然你也可以阅读 Spark 源码找到 join 算子的实现方法,也算你对!
练习题 2:
用 Spark 算子实现对 1TB 的数据进行排序?这个问题,在第 11 课时,会揭晓答案,但现在还是需要你进行编码。
练习题 3:
SELECT a, COUNT(b) FROM t WHERE c > 100 GROUP BY b
这是一句很简单的 SQL,你能用算子将它实现吗?
这 3 道题,你一定要仔细思考,并动手编码,最后别忘了一定要用行动算子触发计算。最后再次强调,由于本课时由专栏的方式呈现,需要你在理解专栏后自己再消化一遍,而要吃透本课时的内容,唯一的办法就是动手编码,所以上面 3 道题请你务必完成。
最后再来回顾一下今天的内容:我们介绍了 Spark 常用的转换算子和行动算子,简言之,转换算子用来声明逻辑,而行动算子用来触发计算。如果你对那种匿名函数作为参数的算子还有些陌生,没关系,下个课时我会对这种编程风格进行解构,让你彻底地理解这种编程风格。

若有收获,就点个赞吧
0 人点赞
