第06讲:Spark 抽象、架构与运行环境
本课时我们进入:“Spark 抽象、架构与运行环境”的学习。从这个模块开始,我们会开始学习 Spark 的具体技术,本模块的内容主要包含两部分:
- Spark 背后的工程实现;
- Spark 的基础编程接口。
注意,本模块的内容对于工程师来说比较重要,需要扎实掌握。
我将从 3 个方面对本课时的内容进行讲解,主要是:
- Spark 架构;
- Spark 抽象;
- Spark 运行环境。
Spark 架构
前面讲过,在生产环境中,Spark 往往作为统一资源管理平台的用户,向统一资源管理平台提交作业,作业提交成功后,Spark 的作业会被调度成计算任务,在资源管理系统的容器中运行。在集群运行中的 Spark 架构是典型的主从架构,如下面这张图所示。这里稍微插一句,所有分布式架构无外乎两种,一种是主从架构(master/slave),另一种是点对点架构(p2p)。
我们先来看看 Spark 架构,在运行时,Driver 无疑是主节点,而 Executor 是从节点,当然,这 3 个 Executor 分别运行在资源管理系统中的 3 个容器中。
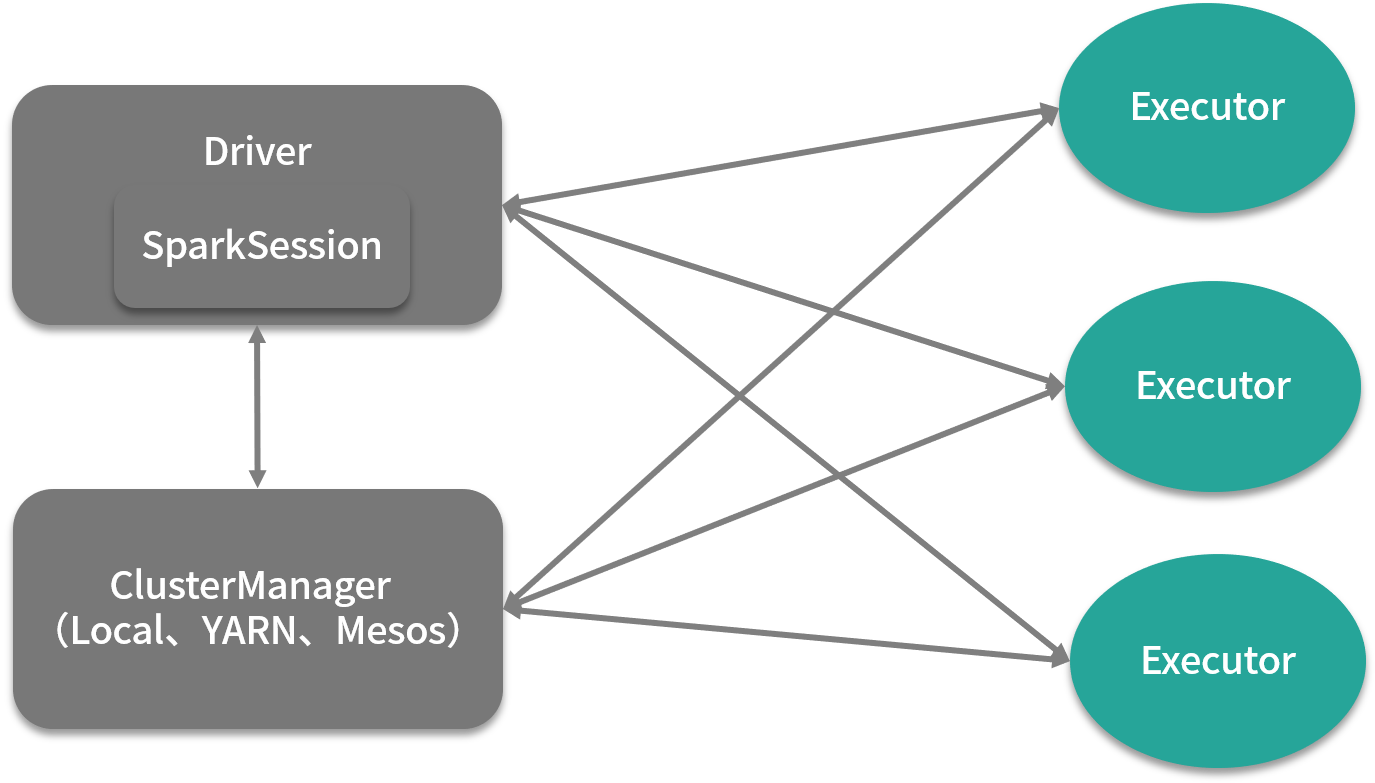
在 Spark 的架构中,Driver 主要负责作业调度工作,Executor 主要负责执行具体的作业计算任务,Driver 中的 SparkSession 组件,是 Spark 2.0 引入的一个新的组件,曾经我们熟悉的 SparkContext、SqlContext、HiveContext 都是 SparkSession 的成员变量。
因此,用户编写的 Spark 代码是从新建 SparkSession 开始的。其中 SparkContext 的作用是连接用户编写的代码与运行作业调度以及任务分发的代码。当用户提交作业启动一个 Driver 时,会通过 SparkContext 向集群发送命令,Executor 会遵照指令执行任务。一旦整个执行过程完成,Driver 就会结束整个作业。这么说稍微有点抽象,你可以通过下面这张图更细致的感受这个过程。
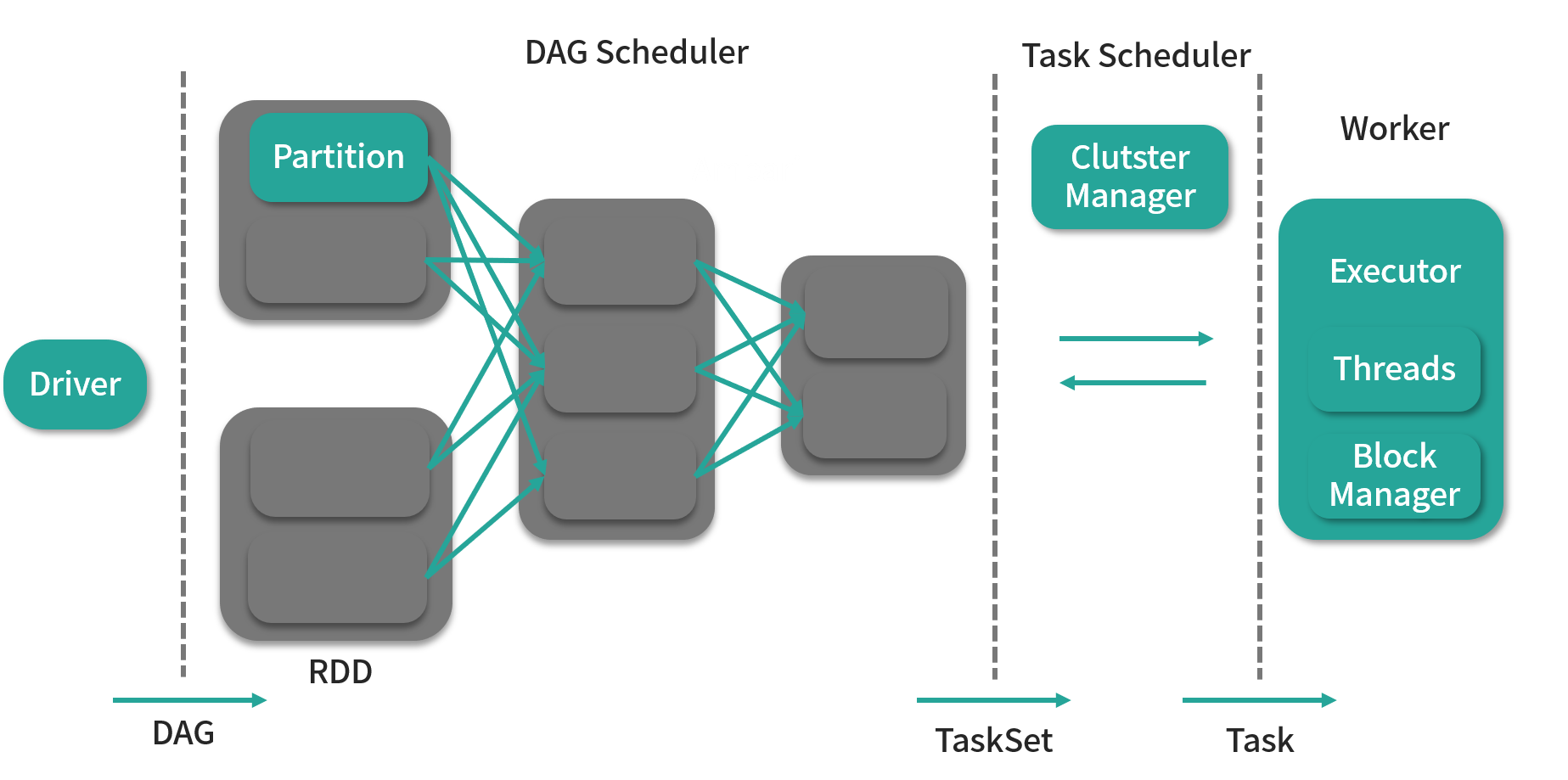
比起前面那张图,该图更像是调大了放大镜倍数的展示结果,能让我们将 Driver 与 Executor 之间的运行过程看得更加清楚。
- 首先,Driver 会根据用户编写的代码生成一个计算任务的有向无环图(Directed Acyclic Graph,DAG),这个有向无环图是 Spark 区别 Hadoop MapReduce 的重要特征;
- 接着,DAG 会根据 RDD(弹性分布式数据集,图中第 1 根虚线和第 2 根虚线中间的圆角方框)之间的依赖关系被 DAG Scheduler 切分成由 Task 组成的 Stage,这里的 Task 就是我们所说的计算任务,注意这个 Stage 不要翻译为阶段,这是一个专有名词,它表示的是一个计算任务的集合;
- 最后 TaskScheduler 会通过 ClusterManager 将 Task 调度到 Executor 上执行。
可以看到,Spark 并不会直接执行用户编写的代码,而用户代码的作用只是告诉 Spark 要做什么,也就是一种“声明”。看到这里,或许你可以大致明白 Spark 的执行流程,但可能对于一些概念还是会有些不清楚,这个问题,我们将通过下面的内容进行解答。
Spark 抽象
当用户编写好代码向集群提交时,一个作业就产生了,作业的英文是 job,在 YARN 中,则喜欢把作业叫 application,它们是一个意思。Driver 会根据用户的代码生成一个有向无环图,下面这张图就是根据用户逻辑生成的一个有向无环图。
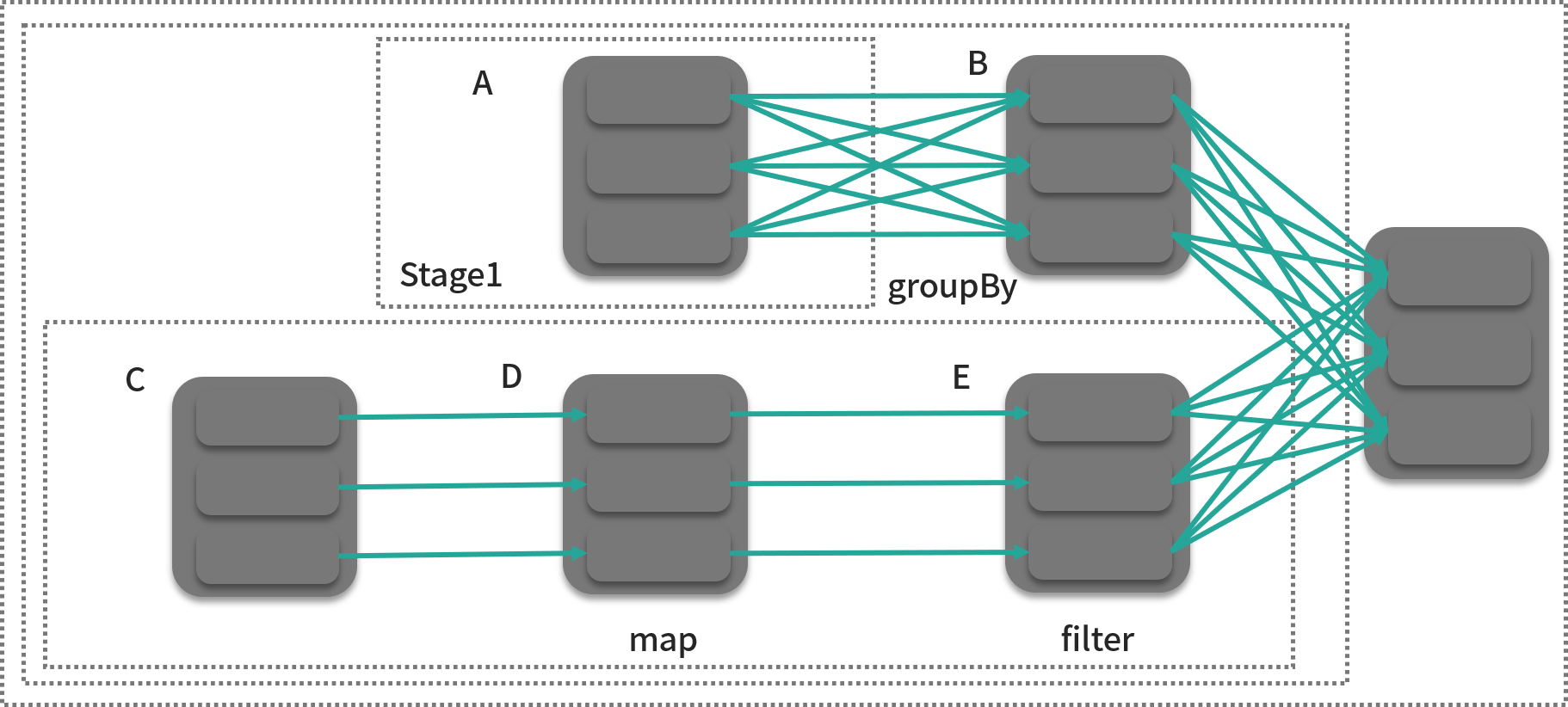
仔细看这张图,可以大概反推出计算逻辑:A 和 C 都是两张表,在分别进行分组聚合和筛选的操作后,做了一次 join 操作。
在上图中,灰色的方框就是我们所说的分区(partition),它和计算任务是一一对应的,也就是说,有多少个分区,就有多少个计算任务,显然的,一个作业,会有多个计算任务,这也是分布式计算的意义所在,我们可以通过设置分区数量来控制每个计算任务的计算量。在 DAG 中,每个计算任务的输入就是一个分区,一些相关的计算任务所构成的任务集合可以被看成一个 Stage,这里”相关”指的是某个标准,我们后面会讲到。RDD 则是分区的集合(图中 A、B、C、D、E),用户只需要操作 RDD 就可以构建出整个 DAG,从某种意义上来说,它就是为了掩盖上面的概念而存在的。
在明白上面的概念后,我们来看看 Executor,一个 Executor 同时只能执行一个计算任务,但一个 Worker(物理节点)上可以同时运行多个 Executor。Executor 的数量决定了同时处理任务的数量,一般来说,分区数远大于 Executor 数量才是合理的。
所以同一个作业,在计算逻辑不变的情况下,分区数和 Executor 的数量很大程度上决定了作业运行的时间。
Spark 运行环境
在上个课时讲到如何部署 Spark 时,已经讲到了 Spark 的运行环境,这里主要聊聊如何基于某个运行环境初始化 SparkSession。我们先来看看 Scala 版本,我们在前面准备好的 Scala 项目中,写下如下代码:
import org.apache.spark.sql.SparkSessionval spark = SparkSession.builder().master("yarn-client").appName("New SS").config("spark.executor.instances", "10").config("spark.executor.memory", "10g").getOrCreate()import spark.implicits._
执行到这里,SparkSession 就初始化完成了,后面用户就可以开始实现自己的数据处理逻辑,不过你可能已经注意到了,在代码中,我们通过配置指明了 Spark 运行环境时的 YARN,并且是以 yarn-client 的方式提交作业(YARN 还支持 yarn-cluster 的方式,区别在与前者 Driver 运行在客户端,后者 Driver 运行在 YARN 的 Container 中)。
另外值得注意的一点是,我们一共申请了 10 个 Executor,每个 10g,不难算出一共 100g。按照前面的结论,是不是改成 100 个 Executor,每个 1g,作业执行速度会大大提升呢?这个问题的答案是不确定。因为在总量不变的情况下,每个 Executor 的资源减少为原来的十分之一,那么 Executor 有可能无法胜任单个计算任务的计算量(或许能,但是完成速度大大降低),这样你就不得不提升分区数来降低每个计算任务的计算量,所以完成作业的总时间有可能保持不变,也有可能还会增加,当然,也有可能降低。
看到这里,你可能已经对作业的性能调参有点感觉了,其实和机器学习的调参类似,都是在一定约束下(这里就是资源),通过超参数的改变,来实现某个目标(作业执行时间)的最优化。当然,这里要特别说明的是,此处为了简化,只考虑了 Executor 的资源,没有考虑 Driver 所需的资源,另外资源也简化为一个维度:内存,而没有考虑另一个维度 CPU。
最后来看看 Python 版代码:
from pyspark.sql import SparkSessionspark = SparkSession \.builder \.master("yarn-client") \.appName("New SS") \.config("spark.executor.instances", "10") \.config("spark.executor.memory", "10g") \.getOrCreate()
小结
本课时主要向你介绍了 Spark 的架构,以及作业执行的原理,第 2 部分向你介绍了 Spark 的几个关键抽象,也就是关键概念,最后一部分,我们做了一点点实践:初始化 SparkSession,为后面的学习打下基础。最后再留一个思考题,如何通过配置指定每个Executor所需的CPU资源。
另外,在上面的代码中,我们都是通过硬编码来指定配置,同 Java 一样,Spark 也支持直接通过命令行参数进行配置,而这也是官方推荐的。

若有收获,就点个赞吧
0 人点赞
