第05讲:如何选择 Spark 编程语言以及部署 Spark
从下个模块开始,我们就会进入 Spark 的学习中,在正式开始学习 Spark 之前,首先需要选择自己要使用的 Spark 编程语言,了解如何部署 Spark,另外再根据选择搭建一个简单、方便的 Spark 运行环境。
本课时的主要内容有 3 块:
- Spark 编程语言种类,如何选择 Spark 编程语言;
- 部署 Spark;
- 如何安装 Spark 的学习环境。
Spark 的编程语言
Spark 在诞生之初就提供了多种编程语言接口:Scala、Java、Python 和 SQL,在后面的版本中又加入了 R 语言编程接口。对于 Spark 来说,虽然其内核是由 Scala 编写而成,但编程语言从来就不是它的重点,从 Spark 提供这么多的编程接口来说,Spark 鼓励不同背景的人去使用它完成自己的数据探索工作。尽管如此,不同编程语言在开发效率、执行效率等方面还是有些不同,我将目前 Spark 各种编程语言优缺点罗列如下:
| 类型 | 开发效率 | 执行效率 | 成熟度 | 支持类型 | |
|---|---|---|---|---|---|
| Scala | 编译型 | 中 | 高 | 高 | 原生支持 |
| Java | 编译型 | 低 | 高 | 高 | 原生支持 |
| Python | 解释型 | 高 | 中 | 中 | PySpark |
| R | 解释型 | 高 | 中 | 低 | SparkR |
| SQL | 解释型 | 高 | 高 | 高 | 原生支持 |
现在我们对每个语言的优缺点进行详细的分析:
- Scala 作为 Spark 的开发语言当然得到了原生支持,也非常成熟,它简洁的语法也能显著提高开发效率;
- Java 也是 Spark 原生支持的开发语言,但是 Java 语法冗长且不支持函数式编程(1.8 以后支持),导致它的 API 设计得冗余且不合理,再加上需要编译执行,Java 开发效率无疑是最低的,但 Java 程序员基数特别大,Java API 对于这些用户来说无疑很友好;
- Python 与 R 语言都是解释型脚本语言,不用编译直接运行,尤其是 Python 更以简洁著称,开发效率自不必说,此外 Python 与 R 语言本身也支持函数式编程,这两种语言在开发 Spark 作业时也是非常自然,但由于其执行原理是计算任务在每个节点安装的 Python 或 R 的环境中执行,结果通过管道输出给 Spark执行者,所以效率要比 Scala 与 Java 低;
- SQL 是 Spark 原生支持的开发语言,从各个维度上来说都是最优的,所以一般情况下,用 Spark SQL 解决问题是最优选择。
如果你才刚开始学习 Spark,那么一开始最好选择一门自己最熟悉的语言,这样 Spark 的学习曲线会比较平缓。如果从零开始,建议在 Scala 与 Python 中间选择,Scala 作为 Spark 的原生开发语言,如果想要深入了解 Spark 有必要掌握。
Python 开发速度方面的优势可以赋予开发人员极强的数据工程实践能力与数据科学探索能力,加上 Python 在数据科学领域的广泛应用,可以更好地发挥 Spark 在数据处理方面的优势。
基于以上原因,本专栏绝大多数例子,都会用 Scala 和 Python 语言实现。简言之,如果你是大数据工程师,以前比较熟悉 Java,那么建议选 Scala,除此之外,尤其是分析师,选 Python。
这里要特别说明的是,Spark 是由 Scala 开发而成,对于Java、Scala 编程接口来说,在执行计算任务时,还是由集群中每个节点的 JVM(Scala 也是 JVM 语言)完成。但是如果采用 Python、R 语言编程接口,那么执行过程是由集群中每个节点的 Python 与 R 进程计算并通过管道回传给 JVM,所以性能上会有所损失。
部署 Spark
Spark 的编程语言,都属于 Spark 表现层面的东西,程序写好了,如何让 Spark 这个分布式架构运行起来,还有些工作要做,总结起来还需要 2 步:
1. 选择统一资源管理与调度系统
我们在 03 课时介绍了统一资源管理与调度系统,作为计算框架的一员,同样的,Spark 也需要运行在某个统一资源管理与调度系统,目前 Spark 支持的统一资源管理与调度系统有:
- Spark standalone
- YARN
- Mesos
- Kubernetes
- 本地操作系统
Spark standalone 这种模式类似于前面讲的 Hadoop 1.0 的 MapReduce,由于缺点不少,基本不太适合在生产环境使用;Kubernetes 则是直到最新的 Spark 2.4.5 版本才支持;如果 Spark 运行在本地操作系统上,那么这就是我们说的伪分布模式,特别适合学习以及分析师用来处理中等数据量的数据,性能也还不错,当然这里指的是对单机性能而言。那么目前虽然支持 Spark on YARN 模式是目前最普遍的,但是 Mesos 才是 Spark 最先支持的平台,这里简单讲讲 Spark 是如何运行在 Mesos 上,你可以借此复习下前面的知识:
主要分 5 步:
- SparkContext 在 Mesos master 中注册为框架调度器。
- Mesos slave 持续同步以向 Mesos master 发送资源信息。
- 一个或者多个资源供给将信息发送给 SparkContext(下发资源)。
- SparkContext 接收资源供给。
- 在 Mesos slave 上启动计算任务。
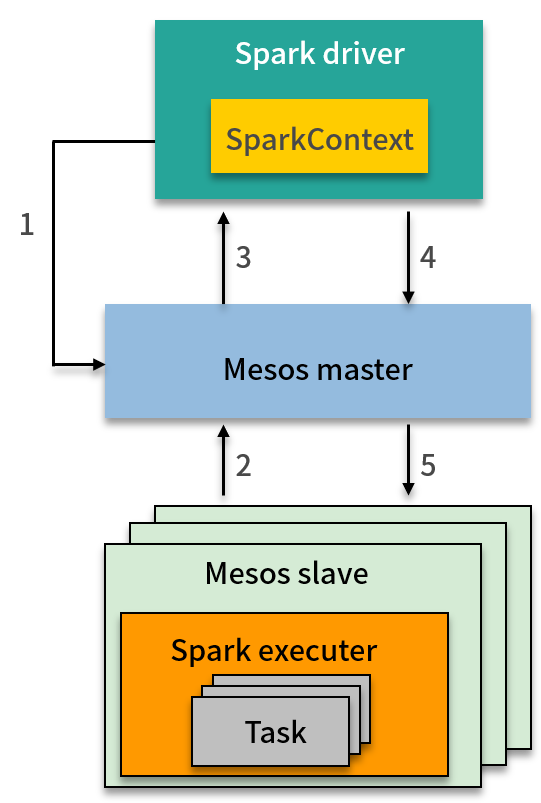
一般来说,无论你基于公司的大数据平台进行开发还是分析,底层的统一资源管理与调度系统是什么对于工程师和分析师来说是无需关心的,对于代码来说没有任何不同,区别只体现在一些提交参数上。
2. 提交 Spark 作业
前面提到,如果大数据平台使用了统一资源管理与调度系统,那么上层的计算框架就变成了这个资源系统的用户。这样做的结果是直接简化了计算框架的部署。对于部署计算框架这个问题,你可以用客户端/服务端,也就是 C/S 这种模式来理解。
我们把大数据平台看成是一个服务端,那么相应的就会有一些客户端,也就是一些节点,比如在 Hadoop 中,我们把这些客户端称为 Hadoop 客户端,你可以通过客户端访问 HDFS 或者提交作业。
所以,这些客户端也会有一份相应的安装包,按照客户端进行配置,Spark 也不例外,我们只需在客户端节点部署一份 Spark 安装包,并且正确配置,以YARN为例,需要你将YARN的配置文件复制到Spark客户端的配置文件夹下,就可以从该节点向大数据平台提交作业。提交的作业就会在集群中被调度为计算任务。
如何安装Spark的学习环境
在学习之前,一定要准备一个便于学习和调试的环境,本课时我将带领你根据自己的需要搭建一个学习环境,也就是前面说的伪分布模式。对于选择 Scala 的用户来说,以伪分布模式运行 Spark 是一件很简单的事情,只需要在下面链接下载预编译好的 Spark 安装包,将里面的 jar 包导入到项目空间中就可以了,这个项目就可以作为你的学习环境,每次写好的代码也可以马上运行并得到结果。
还有一种方法,你可以用 Maven 项目来进行管理,这当然更好,我更推荐这种。
但对于 Python 用户来说,会稍微麻烦一点,这里将其总结为 5 步:
- 安装 Anaconda
- 用 Anaconda 安装 Jupyter notebook
- 用 Anaconda 安装 PySpark
- 运行 Jupyter notebook
- 运行测试代码
这个过程大概需要 15 分钟,现在我们开始吧。
1. 安装 Anaconda
安装之前可以先卸载以前安装的 Python,这样统一由 Anaconda 进行管理。Anaconda 是包管理器和环境管理器,对于 Python 数据分析师来说是必备软件之一,我们可以在官网根据不同的操作系统下载对应版本(都选择 Python 3.7):
安装完成后,我们就可以在控制台使用 pip 命令了。
2. 安装 Jupyter
Jupyter notebook 是一个交互式的 Web 笔记本应用,可以支持多种编程语言,事实上 Anaconda+Jupyter notebook 已成为数据分析的标准环境。那么 Jupyter notebook 还有一个非常适合的场景,就是教育,它的笔记本特性可以非常好地将学习过程固化。由于前面我们已经安装好了 Anaconda,所以安装 Jupyter notebook 只需要执行下面这两条命令即可:
pip install --upgrade pippip install jupyter
3. 安装 PySpark
现在通过 Anaconda 安装 PySpark 已经很方便了,只需要在控制台执行如下命令:
pip install -U -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark
我在里面换了一个清华的源,国内用户会快一点。另外要注意的是,直接执行这条命令有可能会安装失败,Windows 用户需要以管理员身份运行控制台,再执行命令。如下图:

Mac 用户可以用 sudo 前缀执行该条命令,如下:
sudo pip install -U -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark
4. 启动 Jupyter notebook
前面几步完成后,我们就可启动 Jupyter notebook。在控制台执行以下命令:
jupyter notebook --ip=0.0.0.0 --notebook-dir='E:\\JupyterWorkspace'
需要注意文件夹要事先创建好,这个就是你的笔记本文件夹。启动后,浏览器会弹出,可以在控制台里面找到Jupyter notebook的链接,如下图所示:

将链接复制到浏览器中,就可以使用 Jupyter notebook 了,如下图所示:

5. 运行测试代码
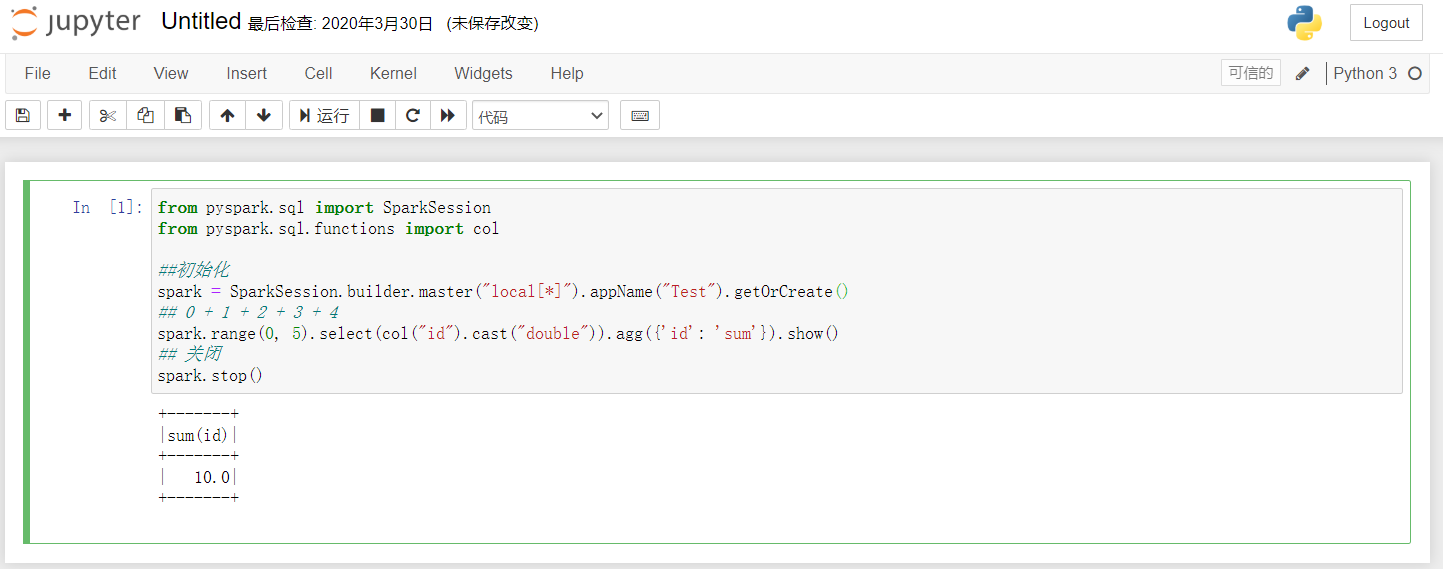
为了测试安装的结果,我们新建一个笔记本,在单元格中写入如下代码:
from pyspark.sql import SparkSessionfrom pyspark.sql.functions import col##初始化spark = SparkSession.builder.master("local[*]").appName("Test").getOrCreate()## 0 + 1 + 2 + 3 + 4spark.range(0, 5).select(col("id").cast("double")).agg({'id': 'sum'}).show()## 关闭spark.stop()
代码的作用是 Spark 对元素为 0~4 的数组进行求和处理,运行代码,Jupyter notebook 会展示运行结果。如下图所示:
这里特别说明的是,代码中的参数local[*]指明了 Spark 基于本地操作系统运行,如果基于 YARN、Mesos 或者 Kubernetes,只需要对应修改该参数即可。
小结
本课时主要介绍了 Spark 编程语言以及选择建议,并结合第 3 课时的内容,介绍了 Spark 部署与提交作业的方式,并帮助你搭建一个方便的学习 Spark 的环境。
学完了本课时的内容,这里还有一个小问题留给你:前面说到伪分布模式的参数为local[*],那么是否可以将 *替换为具体数字,如果可以,会引起怎样的变化呢?
(资料来源:拉勾教育 - 即学即用的Spark实战44讲)

若有收获,就点个赞吧
0 人点赞
