问题描述
在阿里云EMR环境下,使用Spark SQL3.1.1 查询存放在hive-metastore和oss之上的iceberg表,会发现存在很多数据量非常小的task。
查询的query模式如下:
SELECT * FROM hive_prod.iceberg_db.store_sales WHERE ss_customer_sk = 10702517;
在spark的dashboard上查看这个query的详细情况如下:
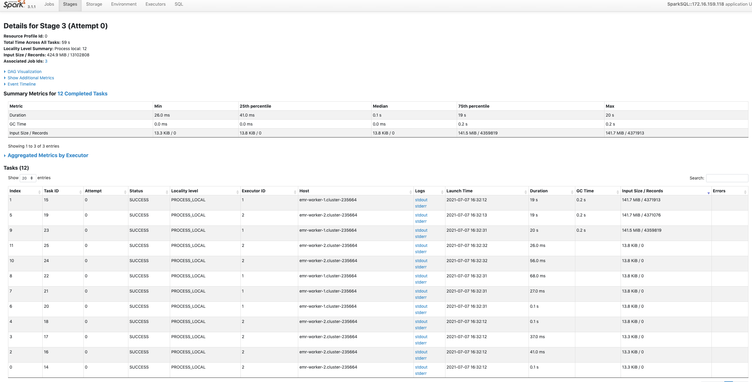
这里我们分出来的12个task中,有3个task的数据在140MB左右,另外的9个task数据在13KB左右。问题就在于为何会分配出来9个13KB这么小的task呢?
在下文中我们对这个问题进行详细的分析。
原因调查
首先,通过debug我们可以非常确定这个点查再plan task的阶段,把 ss_customer_sk = 10702517 这个filter下推到了parquet文件级别。因为整个表的文件数有接近2000个,而现在只分配出来12个task,那么必然在文件级别做了下推,否则至少会出现数千个task的。
接着来分析,为什么是分出来12个task呢?
这是因为ss_customer_sk=10702517这个值通过max-min分析,落在了三个不同分区的三个不同文件内。这3个文件的大小都在512MB左右。而iceberg的 read.split.target-size 默认值为128MB。也就是说这3个文件会按照128MB大小切成一个个task,这样算下来就是12个task,每个task的大小在128MB上下,分配的最小单元是rowGroup的大小。
由于用户写入数据时,按照ss_customer_sk排序之后写入到iceberg表。那么对于3个文件中的每一个文件,只有一个row-group存在这个ss_customer_sk这个值,换句话说这12个task中总共只有3个task存在待搜索的值。
再次分析iceberg的代码发现,iceberg的parquet reader其实已经把filter下推到了row-group级别(代码参考:https://github.com/apache/iceberg/blob/90225d6c9413016d611e2ce5eff37db1bc1b4fc5/parquet/src/main/java/org/apache/iceberg/parquet/ReadConf.java#L107)
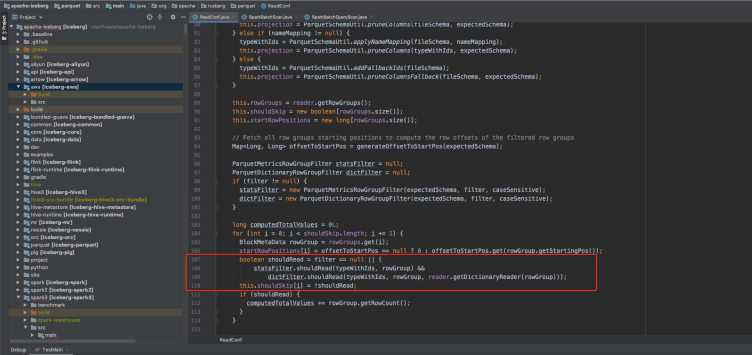
这也就意味着其余9个task只是查了一下统计信息,就可以断定key肯定不在这个 task内。于是我们就看到了12个task中,只有3个task扫了128MB左右的数据,其余9个task只扫了13KB的数据。
总结:本质上是因为iceberg支持了filter下推到row-group级别,所以大量的row-group数据可以直接跳过扫描。那些空task就是被跳过的row-group。

若有收获,就点个赞吧
0 人点赞
