问题描述
有用户在HMS下面创建了一个Iceberg表如下:
$ ./bin/hiveCREATE TABLE iceberg_ddl(id BIGINT,data STRING) STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';
这时,用户想在这个iceberg_ddl表中新增一个column:
ALTER TABLE iceberg_ddl ADD COLUMNS (new_column STRING COMMENT 'new_column docs');
结果发现报如下错误:
21/12/06 11:34:58 INFO conf.HiveConf: Using the default value passed in for log id: f2b4f668-c68b-49cb-8dce-dd7777379d28
21/12/06 11:34:58 INFO session.SessionState: Updating thread name to f2b4f668-c68b-49cb-8dce-dd7777379d28 main
21/12/06 11:34:58 INFO ql.Driver: Compiling command(queryId=openinx_20211206113458_0b806087-bfb5-4c98-9875-664e08923702): ALTER TABLE iceberg_ddl ADD COLUMNS (new_column STRING COMMENT 'new_column docs')
FAILED: SemanticException [Error 10134]: ALTER TABLE cannot be used for a non-native table iceberg_ddl
21/12/06 11:34:58 ERROR ql.Driver: FAILED: SemanticException [Error 10134]: ALTER TABLE cannot be used for a non-native table iceberg_ddl
org.apache.hadoop.hive.ql.parse.SemanticException: ALTER TABLE cannot be used for a non-native table iceberg_ddl
at org.apache.hadoop.hive.ql.parse.DDLSemanticAnalyzer.validateAlterTableType(DDLSemanticAnalyzer.java:1354)
at org.apache.hadoop.hive.ql.parse.DDLSemanticAnalyzer.addInputsOutputsAlterTable(DDLSemanticAnalyzer.java:1533)
at org.apache.hadoop.hive.ql.parse.DDLSemanticAnalyzer.addInputsOutputsAlterTable(DDLSemanticAnalyzer.java:1479)
at org.apache.hadoop.hive.ql.parse.DDLSemanticAnalyzer.analyzeAlterTableModifyCols(DDLSemanticAnalyzer.java:2718)
at org.apache.hadoop.hive.ql.parse.DDLSemanticAnalyzer.analyzeInternal(DDLSemanticAnalyzer.java:279)
at org.apache.hadoop.hive.ql.parse.BaseSemanticAnalyzer.analyze(BaseSemanticAnalyzer.java:258)
at org.apache.hadoop.hive.ql.Driver.compile(Driver.java:512)
at org.apache.hadoop.hive.ql.Driver.compileInternal(Driver.java:1317)
at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1457)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1237)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1227)
at org.apache.hadoop.hive.cli.CliDriver.processLocalCmd(CliDriver.java:233)
at org.apache.hadoop.hive.cli.CliDriver.processCmd(CliDriver.java:184)
at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:403)
at org.apache.hadoop.hive.cli.CliDriver.executeDriver(CliDriver.java:821)
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:759)
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:686)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:244)
at org.apache.hadoop.util.RunJar.main(RunJar.java:158)
原因分析
本质上Hive对于非native的表只容许修改table properties,其他的所有DDL都不容许操作。而iceberg虽然存在HMS是作为Hive的managed表,但是依然不是hive native的表。所以,无法在hive客户端中修改iceberg的schema结构。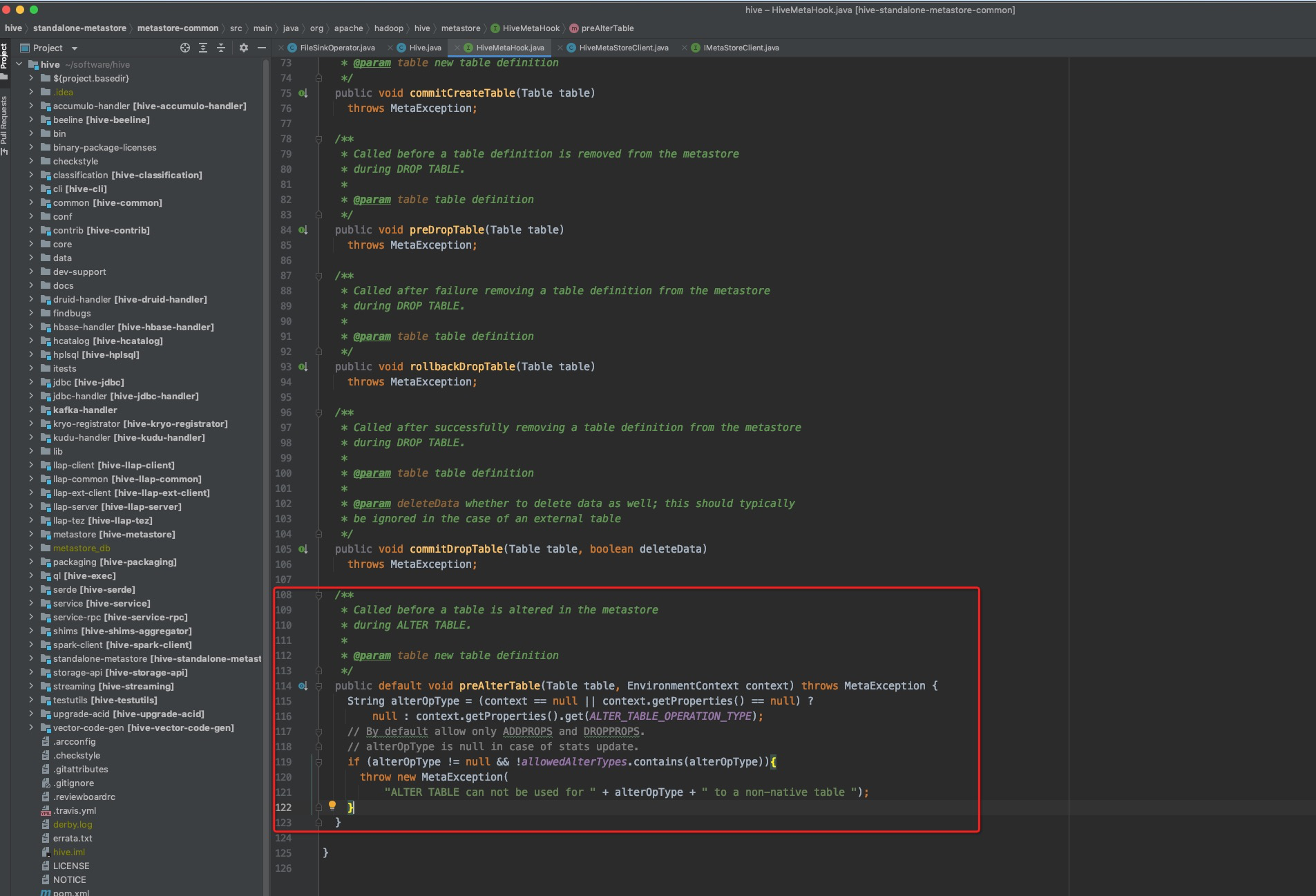
解决方案
建议采用spark命令行来修改iceberg表的schema结构。通过如下方式打开spark的命令行(在阿里云EMR集群上不需要再额外设置—jars参数了,因为spark默认能加载到iceberg依赖包):
./bin/spark-sql --jars /Users/openinx/software/apache-iceberg/spark/v3.1/spark-runtime/build/libs/iceberg-spark-3.1-runtime-0.13.0-SNAPSHOT.jar \
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions \
--conf spark.sql.catalog.hive=org.apache.iceberg.spark.SparkSessionCatalog \
--conf spark.sql.catalog.hive.type=hive \
--conf spark.sql.catalog.hive.uri=thrift://localhost:9083
在spark-sql中执行如下语句:
DESC hive.default.iceberg_ddl;
ALTER TABLE hive.default.iceberg_ddl ADD COLUMNS (
new_column string comment 'new_column docs'
);
最后再hive客户端中查看最新的 iceberg_ddl表,会发现最新的schema已经添加上了new_column这个列:
hive> desc iceberg_ddl ;
id bigint from deserializer
data string from deserializer
new_column string new_column docs
Time taken: 0.267 seconds, Fetched: 3 row(s)
至此,问题解决!

若有收获,就点个赞吧
0 人点赞
