背景
我们有一个PB级数据量的用户,他通过开源的Spark + Iceberg 在阿里云上构建了一个测试数据湖。他定义的 Schema 如下:
CREATE DATABASE hive_prod.iceberg_db;CREATE TABLE hive_prod.iceberg_db.user_data (`id` STRING,`content` BINARY,`date` STRING,`hour` STRING,`part` STRING)USING icebergPARTITIONED BY (`date`, `hour`, `part`)TBLPROPERTIES ('write.format.default' = 'parquet','write.target-file-size-bytes'='536870912');
这个用户在该张表上做的查询全部为:
SELECT * FROM hive_prod.iceberg_db.user_logs WHERE id = ?
他为了能够在iceberg表中快速地根据 id 做查询,在将用户数据导入到 iceberg 表中之前,全部按照 id 做了排序之后再写入iceberg。也就是写入的时候,通过如下 SQL 来进行数据的导入:
INSERT INTO hive_prod.iceberg_db.user_logsPARTITION (`date`='2021-07-01', `hour`='15', `part`='01')SELECT * FROM original.user_logsORDER BY id;
就是这样,用户把数据按照id排序之后,一个个地加载到新建的 iceberg 分区内。这样每一个iceberg的分区数据,都是严格按照 id 做的排序。换句话说,每一个iceberg表的分区内最多只有一个文件会命中用户的QUERY: SELECT * FROM hive_prod.iceberg_db.user_logs WHERE id = ? ,这样查询的效率大大增加。
但是,用户在做如下查询时,发现整个表中所有的文件都被加载出来,然后依次扫描了一遍,从而导致查询的效率非常之低。
SELECT * FROM hive_prod.iceberg_db.user_logs WHERE id = ' 36141644';
那么,到底是什么原因导致这种查询最终扫了所有文件呢?
定位
首先,用户在这个 user_logs 表中生成的数据类似如下:
id : ' 36141644'content : 'xxxxxxxxxxxxxxxxxx'date : '2021-06-01'hour : '02'part : '01'
注意,id 字段是一个长度为32字节的字符串,内容为 1 ~ 10^9,为了补齐为32字节,用户做了前置填空格处理,所以我们看到的 id = ‘ 36141644’ 。
我们知道,apache iceberg 对于 equals 这种 filter 是可以直接下推到文件级别的,甚至对于parquet文件来说,是直接下推到 row-group 级别的。那么,按照道理,这种查询应该会过滤掉大量的数据文件,最终一个分区只有一个文件命中查询条件,最后我们只需要扫描那个文件就行。
但现在明显不是这样,于是我们开始做一些debug:
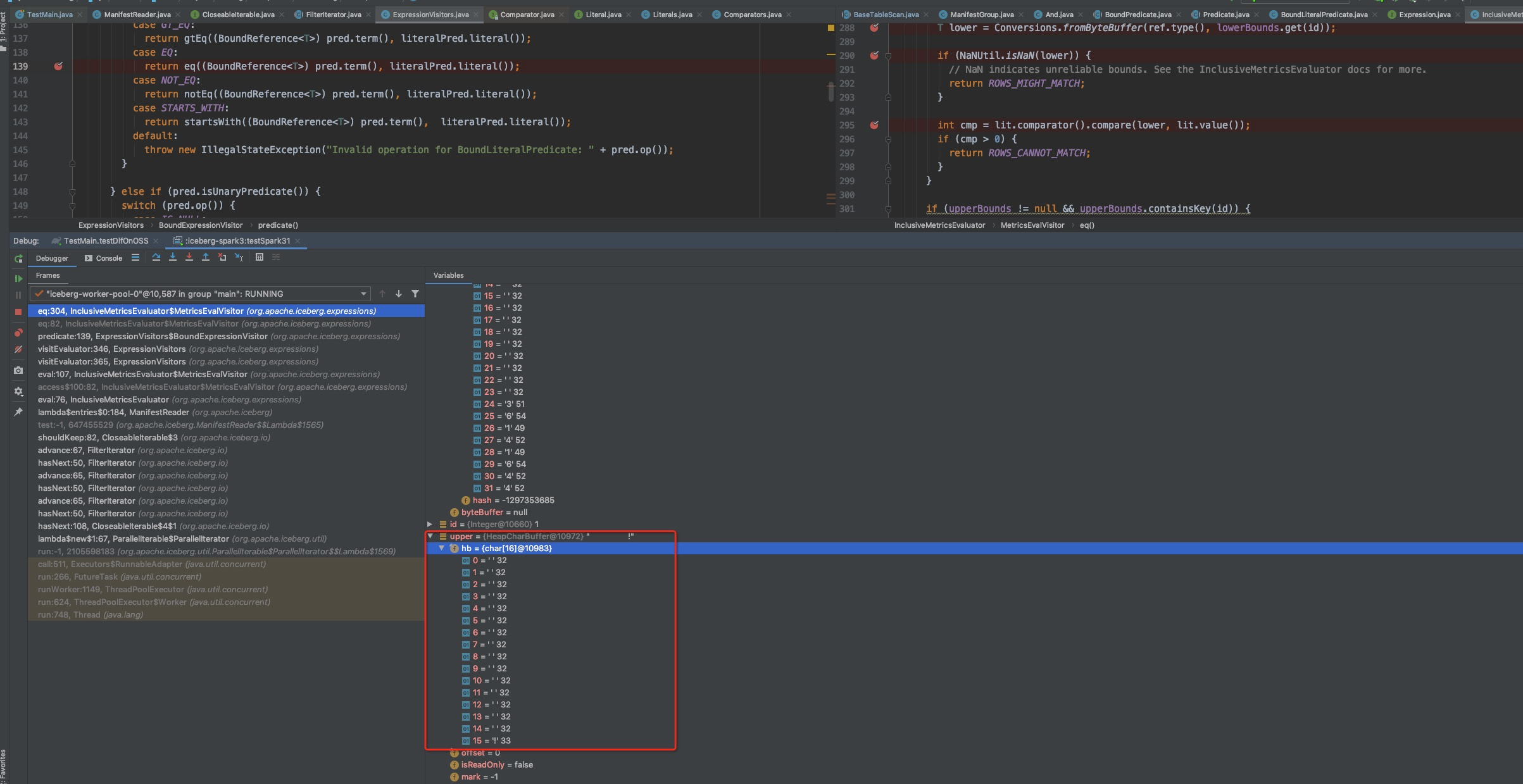
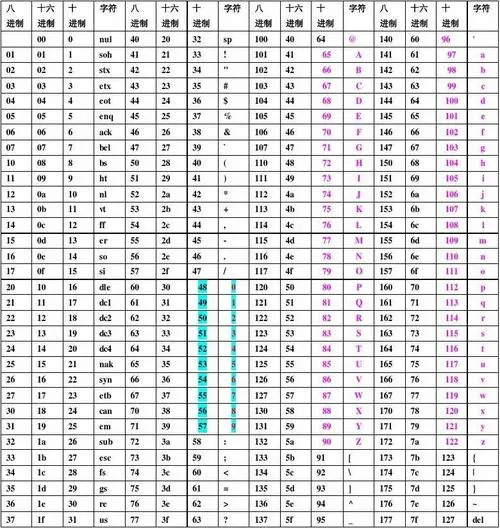
我们发现在读取iceberg表中的parquet文件时, uppper-bound列表和lower-bound列表已经只剩下16字节了,这16个字节内前面15个字节全部都是空格,最后一个字节是空格的下一个字符 ‘!’。 参考如下 assic 编码:
那么,到底是什么原因导致 iceberg 的metadata文件内把每个 column 的统计信息给truncate到16字节了呢?
稍稍 google 一下之后,发现原来这个 PR 做了一个实现:https://github.com/apache/iceberg/pull/254
简单来说,就是为了避免某些长度特别长的字段因为统计信息占用太多的metadata空间,所以有一个默认参数 write.metadata.metrics.default = truncate(16) 。因此,在数据写入到 apache iceberg 表时,就会把对应的字段truncate为16字节,作为max-min统计信息存储到 iceberg 的metadata中。最终,就发生了我们碰到的那个问题。
那么,为什么truncate(16)之后,会导致所有的文件都不能被有效data skipping掉呢?
这跟用户写入的 user_id 模式有关。虽然这个user_id是32字节的,但是由于前面16字节全部都是空格,这就导致统计信息里面的所有lower_bound全部是16字节的空格,upper_bound全部都是15字节的空格 + 1字节的’!’。最终的效果就是什么文件都无法data skipping掉了。
总结
要解决这个问题非常简单,就是设置参数为:
write.metadata.metrics.default = truncate(32)

若有收获,就点个赞吧
0 人点赞
