技术提问
1. 实践
a. 流批一体有那些实践案例,离线链路如何修正实时链路?
- Netflix 通过 Flink + Iceberg 来实现 Backfill / Bootstrap 新作业。
- Flink + TT&ODPS VS Flink + Iceberg。 (第四部分增量处理的答案可以在这里找到。)
b. MySQL数据同步到iceberg的最佳实践,如何调整写入方式实现最快的查询性能,能写入时按主键分桶吗?
开源版本 flink-cdc-connector 目前的不足:
一张mysql cdc表,对应一张iceberg表。所有的列都需要写一遍,非常繁琐。
- 解法: 引入新的Flink SQL语法
CREATE TABLE iceberg_tableAS (SELECT * FROM mysql_cdc_table);
- 解法: 引入新的Flink SQL语法
一张mysql cdc表,对应一张iceberg表,对应一个flink streaming job。线上mysql 1000张表,则意味着线上的mysql binlog要被1000个mysql slave拉取,压力太大。
- 解法:建议使用 debezium 工具将binlog通过一个作业导入 Kafka,再用mysql-cdc-connector或其他工具统一从kafka拉取,减轻拉取线上mysql binlog的负担。
- flink-cdc-connector 在拉取全量+增量的时候,需要锁表。而且导出全量数据是单线程,大表很慢。
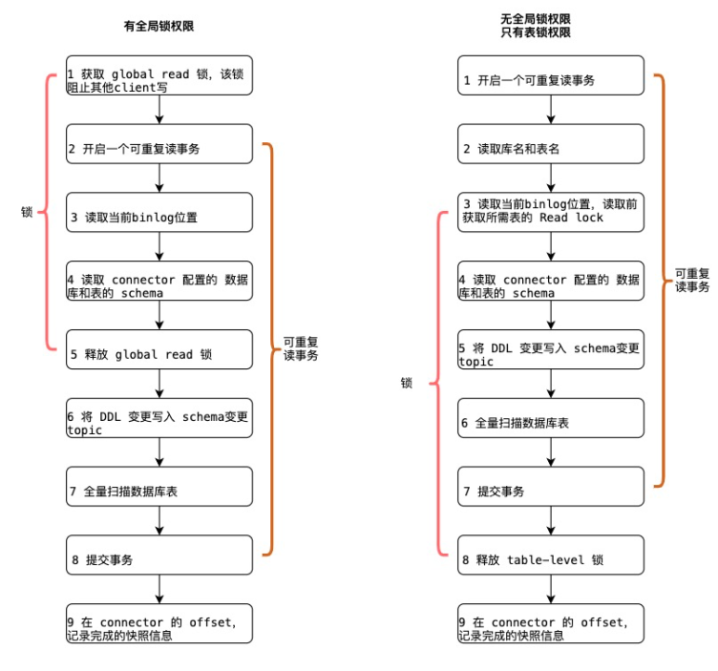
- 解法:参考 [DBLog](https://arxiv.org/pdf/2010.12597v1.pdf) 和 [DDD-3](https://github.com/debezium/debezium-design-documents/blob/main/DDD-3.md) 论文实现新版本的 flink-cdc-connector。
- 建议按主键分 bucket。
- 写入时按照bucket(pk) shuffle写入
- 保证语义正确性:同一个key的不同版本落在同一个并发之上。
- 各bucket内数据均衡
- 一个bucket一个writer,避免打开太多writer导致流式作业出现OOM。
- 读取时大大缩小待JOIN的delete文件。
- 写入时按照bucket(pk) shuffle写入

- 创建表格时按照主键列做分区字段。
```sql
— correct
CREATE TABLE iceberg_cdc_table
(
user_id STRING,
last_visit_ts STRING,
info STRING,
PRIMARY KEY (user_id)
) PARTITIONED BY (user_id) WITH ( ‘connector’=’iceberg’, ‘catalog-type’=’hive’, ‘uri’ = ‘thrift://localhost:9083’, ‘warehouse’=’hdfs://nn:’ );
— incorrect
CREATE TABLE iceberg_cdc_table
(
user_id STRING,
last_visit_ts STRING,
info STRING,
PRIMARY KEY (user_id)
)
PARTITIONED BY (last_visit_ts)
WITH (
‘connector’=’iceberg’,
‘catalog-type’=’hive’,
‘uri’ = ‘thrift://localhost:9083’,
‘warehouse’=’hdfs://nn:’
);
```
- 数据合并
- 推荐采用离线合并策略。
a. 边写入边合并时,乐观锁机制。容易发生冲突,导致重试频繁?
- 对于 v1 来说:
- append-only的两个 txn 发生冲突,并不会产生额外的成本。后面的 txn 直接提交即可。
- 最佳实践:
- 5 min 做checkpoint实时写入
- 采用定时调度的方式,启动离线作业来合并。
- 对于 v2 来说:
- 若批量更新作业与compaction作业冲突,那么要么批量更新作业重试,要么compaction作业重试。
- 若流式更新作业与compaction作业冲突,那么直接按照v1策略重试即可。

更详细的上下文可以参考《Handle the case that RewriteFiles and RowDelta commit the transaction at the same time》。
b. Kafka schema 变更,能否实现自动或一键式下沉到 iceberg ?
3. 读取
a. Trino 暂时不支持读取 v2 格式表,需要通过 SparkSQL,如果是用 Pilo 提供服务,如何做到路由?
- aws 的 trino团队 和阿里云的trino团队,在推进这件事情。不需要通过额外的路由服务来实现。
b. Spark SQL 当前通过kyuubi提供服务,存在任务启动延迟,请求带来 30s 左右额外耗时?
- 不太熟悉kyuubi这个组件,启动延迟需要profile一下。
4. 增量处理
a. 增量处理如何实现?
b. 增量处理支持批处理模式,还是流式模式?
- 目前社区版本 Flink 支持流模式,同时也支持批模式。
- 目前社区版本 Spark 支持 Structure Streaming,同时也支持批作业读取。
c. 当前 Flink 支持从某个Snopshot开始的增量读取,Spark能否支持?
a. Iceberg 表接入元数据中心,感知建表、删表操作,或统一管理。
- 参考阿里云数据湖构建文档。
社区PR
1. parquet格式支持bloom filter加速
https://github.com/apache/iceberg/pull/2642
2. Spark On HDFS 加速
https://github.com/apache/iceberg/pull/2577/files
a. 设置option禁止某些情况下去拿block的location。
b. 多线程启动ReadTask。

若有收获,就点个赞吧
0 人点赞
