一、介绍
数据处理的方式角度
- 流式数据处理
- 批量数据处理
数据处理延迟的长短
- 实时数据处理:毫秒级别
- 离线数据处理:小时 or 天级别
SparkStreaming是一个准实时(秒,分钟),微批次(时间)的数据处理框架
Spark Streaming 用于流式数据的处理。Spark Streaming 支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ 和简单的 TCP 套接字等等。数据输入后可以用 Spark 的高度抽象原语
如:map、reduce、join、window 等进行运算。而结果也能保存在很多地方,如 HDFS,数据库等。

和 Spark 基于 RDD 的概念很相似,Spark Streaming 使用离散化流(discretized stream)作为抽象表示,叫作 DStream。DStream 是随时间推移而收到的数据的序列。在内部,每个时间区间到的数据都作为 RDD 存在,而 DStream 是由这些 RDD 所组成的序列(因此得名“离散化”)。所以简单来讲,DStream 就是对 RDD 在实时数据处理场景的一种封装。
1、特点
- 易用
- 容错
- 易整合到Spark体系
2、整体架构
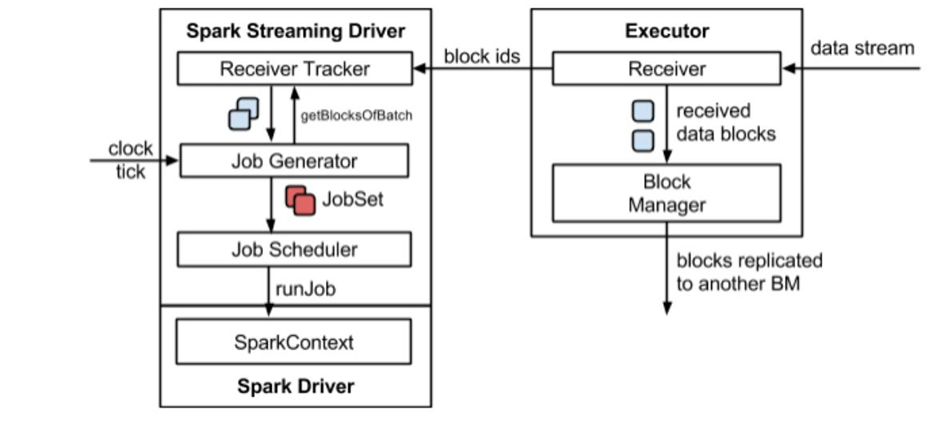
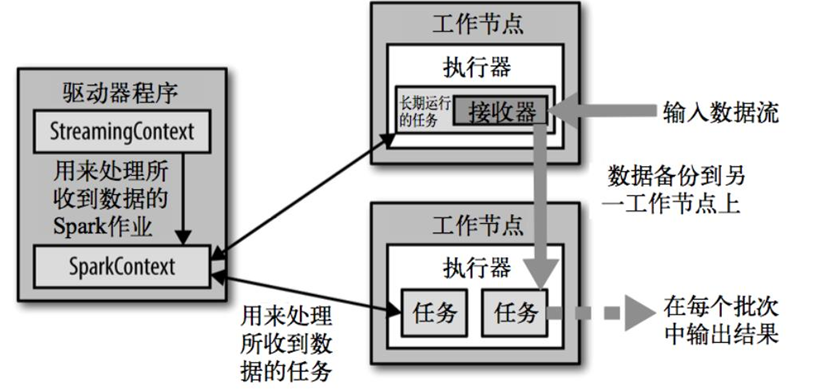
3、背压机制
Spark 1.5 以前版本,用户如果要限制 Receiver 的数据接收速率,可以通过设置静态配制参数“spark.streaming.receiver.maxRate”的值来实现,此举虽然可以通过限制接收速率,来适配当前的处理能力,防止内存溢出,但也会引入其它问题。比如:producer 数据生产高于 maxRate,当前集群处理能力也高于 maxRate,这就会造成资源利用率下降等问题。
为了更好的协调数据接收速率与资源处理能力,1.5 版本开始 Spark Streaming 可以动态控制数据接收速率来适配集群数据处理能力。背压机制(即 Spark Streaming Backpressure): 根据JobScheduler 反馈作业的执行信息来动态调整 Receiver 数据接收率。通过属性“spark.streaming.backpressure.enabled”来控制是否启用 backpressure 机制,默认值false,即不启用。
二、Dstream
添加Spark Streaming依赖
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.12</artifactId><version>3.0.0</version></dependency>
1、永远的WordCount
使用netcat工具创建临时端口不断发送数据,
我们使用SparkStreaming需要创建一个SparkStreamingContext
object WordCount {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("wc")// 创建一个StreamingContext,第一个参数是SparkConf配置,第二个是采集周期(频率)// Duration是个时间,默认毫秒,是一个样例类,可以使用伴生对象// val context = new StreamingContext(conf, Duration(3000L))val ssc = new StreamingContext(conf, Seconds(3))// 3、建立socket端口连接val lineStreams: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 9999)// 4、切分成单词val words: DStream[String] = lineStreams.flatMap(_.split(" "))// 5、映射成次数val tuple: DStream[(String, Int)] = words.map((_, 1))// 6、统计val wordCount: DStream[(String, Int)] = tuple.reduceByKey(_ + _)// 7、打印wordCount.print()// 启动SparkStreamingContextssc.start()// 由于处理,需要一直启动,不可以停止ssc.awaitTermination()}}
启动netcat服务器
nc -lk 9999
在内部实现上,DStream 是一系列连续的 RDD 来表示。每个 RDD 含有一段时间间隔内的数据。
2、RDD队列
测试过程中,可以通过使用 ssc.queueStream(queueOfRDDs)来创建 DStream,每一个推送到这个队列中的 RDD,都会作为一个 DStream 处理。
object RDD_Queue {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("wc")// 创建一个StreamingContext,第一个参数是SparkConf配置,第二个是采集周期(频率)// Duration是个时间,默认毫秒,是一个样例类,可以使用伴生对象// val context = new StreamingContext(conf, Duration(3000L))val ssc = new StreamingContext(conf, Seconds(3))// 创建RDD队列val queue = new mutable.Queue[RDD[Int]]()// 这个onAtTime表示是否允许只有一个队列被一次获取中消费val stream: InputDStream[Int] = ssc.queueStream(queue, oneAtATime = false)val wordCount: DStream[(Int, Int)] = stream.map((_, 1)).reduceByKey(_ + _)// 7、打印wordCount.print()// 启动SparkStreamingContextssc.start()// 启动之后,不断往queue中添加数据for(i <- 1 to 5){queue += ssc.sparkContext.makeRDD(1 to 300, 10)Thread.sleep(2000)}// 由于处理,需要一直启动,不可以停止ssc.awaitTermination()}}
3、自定义数据源
自定义数据采集器
1、继承Receiver,定义泛型
2、重写onStart()和onStop()
object RDD_CustomDataSource {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("wc")// 创建一个StreamingContext,第一个参数是SparkConf配置,第二个是采集周期(频率)// Duration是个时间,默认毫秒,是一个样例类,可以使用伴生对象// val context = new StreamingContext(conf, Duration(3000L))val ssc = new StreamingContext(conf, Seconds(3))val stream: ReceiverInputDStream[String] = ssc.receiverStream(new MyReceiver)stream.print()// 启动SparkStreamingContextssc.start()// 启动之后,不断往queue中添加数据// 由于处理,需要一直启动,不可以停止ssc.awaitTermination()}class MyReceiver extends Receiver[String](storageLevel = StorageLevel.MEMORY_ONLY) {private var flag = false// 启动,抓取数据override def onStart(): Unit = {new Thread(new Runnable {override def run(): Unit = {while (true) {val message = "采集的数据是:" + new Random().nextInt().toString// 保存消息store(message)Thread.sleep(500)}}}).start()}// 停止,接收override def onStop(): Unit = {flag = false}}}
4、Kafka数据源
ReceiverAPI:需要一个专门的 Executor 去接收数据,然后发送给其他的 Executor 做计算。存在的问题,接收数据的 Executor 和计算的 Executor 速度会有所不同,特别在接收数据的 Executor速度大于计算的 Executor 速度,会导致计算数据的节点内存溢出。早期版本中提供此方式,当前版本不适用
DirectAPI:是由计算的 Executor 来主动消费 Kafka 的数据,速度由自身控制。
1、Kafka 0-8 Direct 模式(当前版本不适用)
依赖:
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-8_2.11</artifactId><version>2.4.5</version></dependency>
自动维护offset
object DirectAPIAuto02 {val getSSC1: () => StreamingContext = () => {val sparkConf: SparkConf = newSparkConf().setAppName("ReceiverWordCount").setMaster("local[*]")val ssc = new StreamingContext(sparkConf, Seconds(3))ssc}def getSSC: StreamingContext = {//1.创建 SparkConfval sparkConf: SparkConf = newSparkConf().setAppName("ReceiverWordCount").setMaster("local[*]")//2.创建 StreamingContextval ssc = new StreamingContext(sparkConf, Seconds(3))//设置 CKssc.checkpoint("./ck2")//3.定义 Kafka参数val kafkaPara: Map[String, String] = Map[String, String](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG ->"linux1:9092,linux2:9092,linux3:9092",ConsumerConfig.GROUP_ID_CONFIG -> "atguigu")//4.读取 Kafka数据val kafkaDStream: InputDStream[(String, String)] =KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaPara,Set("atguigu"))//5.计算 WordCountkafkaDStream.map(_._2).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).print()//6.返回数据ssc}def main(args: Array[String]): Unit = {//获取 SSCval ssc: StreamingContext = StreamingContext.getActiveOrCreate("./ck2", () =>getSSC)//开启任务ssc.start()ssc.awaitTermination()}}
手动维护offset
object DirectAPIHandler {def main(args: Array[String]): Unit = {//1.创建 SparkConfval sparkConf: SparkConf = newSparkConf().setAppName("ReceiverWordCount").setMaster("local[*]")//2.创建 StreamingContextval ssc = new StreamingContext(sparkConf, Seconds(3))//3.Kafka参数val kafkaPara: Map[String, String] = Map[String, String](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG ->"hadoop102:9092,hadoop103:9092,hadoop104:9092",ConsumerConfig.GROUP_ID_CONFIG -> "atguigu")//4.获取上一次启动最后保留的 Offset=>getOffset(MySQL)val fromOffsets: Map[TopicAndPartition, Long] = Map[TopicAndPartition,Long](TopicAndPartition("atguigu", 0) -> 20)//5.读取 Kafka数据创建 DStreamval kafkaDStream: InputDStream[String] = KafkaUtils.createDirectStream[String,String, StringDecoder, StringDecoder, String](ssc,(m: MessageAndMetadata[String, String]) => m.message())//6.创建一个数组用于存放当前消费数据的 offset信息var offsetRanges = Array.empty[OffsetRange]//7.获取当前消费数据的 offset信息val wordToCountDStream: DStream[(String, Int)] = kafkaDStream.transform { rdd =>offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRangesrdd}.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)//8.打印 Offset信息wordToCountDStream.foreachRDD(rdd => {for (o <- offsetRanges) {println(s"${o.topic}:${o.partition}:${o.fromOffset}:${o.untilOffset}")}rdd.foreach(println)})//9.开启任务ssc.start()ssc.awaitTermination()}}
2、Kafka 0-10 Direct 模式
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.12</artifactId><version>3.0.0</version></dependency><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-core</artifactId><version>2.10.1</version></dependency>
object DirectAPI {def main(args: Array[String]): Unit = {//1.创建 SparkConfval sparkConf: SparkConf = newSparkConf().setAppName("ReceiverWordCount").setMaster("local[*]")//2.创建 StreamingContextval ssc = new StreamingContext(sparkConf, Seconds(3))//3.定义 Kafka参数val kafkaPara: Map[String, Object] = Map[String, Object](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG ->"linux1:9092,linux2:9092,linux3:9092",ConsumerConfig.GROUP_ID_CONFIG -> "atguigu","key.deserializer" ->"org.apache.kafka.common.serialization.StringDeserializer","value.deserializer" ->"org.apache.kafka.common.serialization.StringDeserializer")//4.读取 Kafka数据创建 DStreamval kafkaDStream: InputDStream[ConsumerRecord[String, String]] =KafkaUtils.createDirectStream[String, String](ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](Set("atguigu"), kafkaPara))//5.将每条消息的 KV取出val valueDStream: DStream[String] = kafkaDStream.map(record => record.value())//6.计算 WordCountvalueDStream.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).print()//7.开启任务ssc.start()ssc.awaitTermination()}}
5、Dstream转换
DStream 上的操作与 RDD 的类似,分为 Transformations(转换)和 Output Operations(输出)两种,此外转换操作中还有一些比较特殊的原语,如:updateStateByKey()、transform()以及各种 Window 相关的原语
1、有状态转换操作
将数据保存到一个检查点目录中,每次加载这个缓存中的目录。updateStateByKey
object StatefuleOption {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("spark-streaming")val ssc = new StreamingContext(conf, Seconds(3))// 必须设置检查点作为缓存的目录ssc.checkpoint("cache")val linesStream: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 9999, storageLevel = StorageLevel.MEMORY_ONLY)val state: DStream[(String, Int)] = linesStream.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)// 根据key有状态更新// 第一个值表示相同的key的value数据,// 第二个值表示缓冲区的相同的key的value数据.updateStateByKey((seq: Seq[Int], buffer: Option[Int]) => {val newVal = buffer.getOrElse(0) + seq.sumOption(newVal)})state.print()ssc.start()ssc.awaitTermination()}}
1、window
Window Operations 可以设置窗口的大小和滑动窗口的间隔来动态的获取当前 Steaming 的允许
状态。所有基于窗口的操作都需要两个参数,分别为窗口时长以及滑动步长。
- 窗口时长:计算内容的时间范围;
- 滑动步长:隔多久触发一次计算。
注意:这两者都必须为采集周期大小的整数倍。
WordCount 第三版:3 秒一个批次,窗口 12 秒,滑步 6 秒。
关于 Window 的操作还有如下方法:
(1)window(windowLength, slideInterval): 基于对源 DStream 窗化的批次进行计算返回一个新的 Dstream;
(2)countByWindow(windowLength, slideInterval): 返回一个滑动窗口计数流中的元素个数;
(3)reduceByWindow(func, windowLength, slideInterval): 通过使用自定义函数整合滑动区间流元素来创建一个新的单元素流;
(4)reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]): 当在一个(K,V)对的 DStream 上调用此函数,会返回一个新(K,V)对的 DStream,此处通过对滑动窗口中批次数据使用 reduce 函数来整合每个 key 的 value 值。
(5)reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]): 这个函数是上述函数的变化版本,每个窗口的 reduce 值都是通过用前一个窗的 reduce 值来递增计算。通过 reduce 进入到滑动窗口数据并”反向 reduce”离开窗口的旧数据来实现这个操作。一个例子是随着窗口滑动对 keys 的“加”“减”计数。通过前边介绍可以想到,这个函数只适用于”可逆的 reduce 函数”,也就是这些 reduce 函数有相应的”反 reduce”函数(以参数 invFunc 形式传入)。如前述函数,reduce 任务的数量通过可选参数来配置。
object StatefuleOption_window {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("spark-streaming")val ssc = new StreamingContext(conf, Seconds(3))val stream: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 9999)// 每隔三秒采集,每次移动1秒val ds: DStream[String] = stream.window(Seconds(3), Seconds(1))ds.print()val dss: DStream[(String, Int)] = stream.flatMap(_.split(" ")).map((_, 1))// 根据key和windows聚合// 第一个是数据增加的函数// 第二个是数据减少的函数// 第三个是.reduceByKeyAndWindow((x: Int, y: Int) => {x + y},(x: Int, y: Int) => {x - y},// 3:窗口间隔Seconds(6),// 4:滑动间隔Seconds(2))dss.print()ssc.start()ssc.awaitTermination()}}
2、无状态转换操作
无状态转化操作就是把简单的 RDD 转化操作应用到每个批次上,也就是转化 DStream 中的每一个 RDD。部分无状态转化操作列在了下表中。注意,针对键值对的 DStream 转化操作(比如reduceByKey())要添加 import StreamingContext._才能在 Scala 中使用。
1、transform
拿到最原始的RDD后进行操作
1、DStream功能不完善
2、需要代码周期性的执行
object Statefuless_Transform {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("spark-streaming")val ssc = new StreamingContext(conf, Seconds(3))// 必须设置检查点作为缓存的目录ssc.checkpoint("cache")val linesStream: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 9999, storageLevel = StorageLevel.MEMORY_ONLY)// 写代码的位置:Driver端val stream: DStream[String] = linesStream.transform(stream => stream.map(// 写代码的位置:Driver端// 流式数据,源源不断的rdd,代码可以周期性执行rdd => {// 写代码的位置:rdd内部:Executor端rdd}))// 写代码的位置:Driver端val s: DStream[String] = stream.map(stream => {// 写代码的位置:rdd内部:Executor端stream})s.print()ssc.start()ssc.awaitTermination()}}
2、join
两个流之间的 join 需要两个流的批次大小一致,这样才能做到同时触发计算。计算过程就是对当前批次的两个流中各自的 RDD 进行 join,与两个 RDD 的 join 效果相同。
object Statefuless_Join {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("spark-streaming")val ssc = new StreamingContext(conf, Seconds(3))ssc.checkpoint("cp")val data9999: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 9999, storageLevel = StorageLevel.MEMORY_ONLY)val data8888: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 8888, storageLevel = StorageLevel.MEMORY_ONLY)val map9999: DStream[(String, Int)] = data9999.map((_, 9))val map8888: DStream[(String, Int)] = data8888.map((_, 8))// 所谓ds的join操作,其实就是两个RDD的joinval joinDS: DStream[(String, (Int, Int))] = map9999.join(map8888)joinDS.print()ssc.start()ssc.awaitTermination()}}
6、DStream输出
如果一个 DStream 及其派生出的 DStream 都没有被执行输出操作,那么这些 DStream 就都不会被求值。
如果 StreamingContext 中没有设定输出操作,整个 context 就都不会启动。
常见的输出操作:
- print()
- saveAsTextFiles()
- saveAsObjectFiles()
- saveAsHadoopFiles()
- foreachRDD(func)
注意:
1) 连接不能写在 driver 层面(序列化)
2) 如果写在 foreach 则每个 RDD 中的每一条数据都创建,得不偿失;
3) 增加 foreachPartition,在分区创建(获取)。
7、优雅停机
处理完当前数据之后关闭
/*** Stop the execution of the streams, with option of ensuring all received data* has been processed.** @param stopSparkContext if true, stops the associated SparkContext. The underlying SparkContext* will be stopped regardless of whether this StreamingContext has been* started.* @param stopGracefully if true, stops gracefully by waiting for the processing of all* received data to be completed*/def stop(stopSparkContext: Boolean, stopGracefully: Boolean): Unit = {var shutdownHookRefToRemove: AnyRef = nullif (LiveListenerBus.withinListenerThread.value) {throw new SparkException(s"Cannot stop StreamingContext within listener bus thread.")}synchronized {// The state should always be Stopped after calling `stop()`, even if we haven't started yetstate match {case INITIALIZED =>logWarning("StreamingContext has not been started yet")state = STOPPEDcase STOPPED =>logWarning("StreamingContext has already been stopped")state = STOPPEDcase ACTIVE =>// It's important that we don't set state = STOPPED until the very end of this case,// since we need to ensure that we're still able to call `stop()` to recover from// a partially-stopped StreamingContext which resulted from this `stop()` call being// interrupted. See SPARK-12001 for more details. Because the body of this case can be// executed twice in the case of a partial stop, all methods called here need to be// idempotent.Utils.tryLogNonFatalError {scheduler.stop(stopGracefully)}// Removing the streamingSource to de-register the metrics on stop()Utils.tryLogNonFatalError {env.metricsSystem.removeSource(streamingSource)}Utils.tryLogNonFatalError {uiTab.foreach(_.detach())}Utils.tryLogNonFatalError {unregisterProgressListener()}StreamingContext.setActiveContext(null)Utils.tryLogNonFatalError {waiter.notifyStop()}if (shutdownHookRef != null) {shutdownHookRefToRemove = shutdownHookRefshutdownHookRef = null}logInfo("StreamingContext stopped successfully")state = STOPPED}}if (shutdownHookRefToRemove != null) {ShutdownHookManager.removeShutdownHook(shutdownHookRefToRemove)}// Even if we have already stopped, we still need to attempt to stop the SparkContext because// a user might stop(stopSparkContext = false) and then call stop(stopSparkContext = true).if (stopSparkContext) sc.stop()}
- 新建一个线程用作优雅停机
- 在第三方存储中设置中断标志
- 重启时从检查点恢复数据
object SparkStreaming08_Close {def main(args: Array[String]): Unit = {/*线程的关闭:val thread = new Thread()thread.start()thread.stop(); // 强制关闭*/val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")val ssc = new StreamingContext(sparkConf, Seconds(3))val lines = ssc.socketTextStream("localhost", 9999)val wordToOne = lines.map((_,1))wordToOne.print()ssc.start()// 如果想要关闭采集器,那么需要创建新的线程// 而且需要在第三方程序中增加关闭状态new Thread(new Runnable {override def run(): Unit = {// 优雅地关闭// 计算节点不在接收新的数据,而是将现有的数据处理完毕,然后关闭// Mysql : Table(stopSpark) => Row => data// Redis : Data(K-V)// ZK : /stopSpark// HDFS : /stopSpark/*while ( true ) {if (true) {// 获取SparkStreaming状态val state: StreamingContextState = ssc.getState()if ( state == StreamingContextState.ACTIVE ) {ssc.stop(true, true)}}Thread.sleep(5000)}*/Thread.sleep(5000)val state: StreamingContextState = ssc.getState()if ( state == StreamingContextState.ACTIVE ) {ssc.stop(true, true)}System.exit(0)}}).start()ssc.awaitTermination() // block 阻塞main线程}}
恢复数据
object SparkStreaming09_Resume {def main(args: Array[String]): Unit = {val ssc = StreamingContext.getActiveOrCreate("cp", ()=>{val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")val ssc = new StreamingContext(sparkConf, Seconds(3))val lines = ssc.socketTextStream("localhost", 9999)val wordToOne = lines.map((_,1))wordToOne.print()ssc})ssc.checkpoint("cp")ssc.start()ssc.awaitTermination() // block 阻塞main线程}}
三、案例实操
1、环境准备
添加依赖
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.0.0</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.12</artifactId><version>3.0.0</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.12</artifactId><version>3.0.0</version></dependency><!-- https://mvnrepository.com/artifact/com.alibaba/druid --><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.1.10</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.27</version></dependency><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-core</artifactId><version>2.10.1</version></dependency>
实时数据生成 ```scala object MockData { def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster(“local[*]”).setAppName(“mock-data”) // new StreamingContext(conf,S)
// 生成模拟数据 // 格式 timestamp area city userId adId // 含义:时间戳 区域 城市 用户 广告
val kafkaProperties = new Properties() // 添加配置 kafkaProperties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,”192.168.29.128:9092”) // kafka集群地址 kafkaProperties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,”org.apache.kafka.common.serialization.StringSerializer”) // key的序列化配置 kafkaProperties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,”org.apache.kafka.common.serialization.StringSerializer”) // value的序列化配置 val producer = new KafkaProducerString, String // 将数据通过Application => Kafka => SparkStreaming => Analysis
while(true) {
mockData().foreach(data => {// 向Kafka中生成数据
// producer.send(new ProducerRecordString,String)
println(data)})Thread.sleep(2000)
}
} def mockData(): ListBuffer[String] = {
val list = ListBuffer[String]()val areaList = ListBuffer[String]("华北","华东","华南")val cityList = ListBuffer[String]("北京","上海","深圳")for (i <- 1 to 30){val area = areaList(new Random().nextInt(3)) + 1val city = areaList(new Random().nextInt(3)) + 1val userId = new Random().nextInt(6) + 1val adId = new Random().nextInt(6) + 1list.append(s"${System.currentTimeMillis()} ${area} ${city} ${userId} ${adId}")}list
}
}
- JdbcUtils```scalaobject JdbcUtil {private var dataSource = init()def init(): DataSource = {val prop = new Properties()prop.setProperty("url","jdbc:mysql://localhost:3306/spark-streaming")prop.setProperty("driverClassName","com.mysql.jdbc.Driver")prop.setProperty("user","root")prop.setProperty("password","root")prop.setProperty("maxActive","50")DruidDataSourceFactory.createDataSource(prop)}def getCon:Connection = {dataSource.getConnection()}}
2、需求一:广告黑名单
实现实时的动态黑名单机制:将每天对某个广告点击超过 100 次的用户拉黑。
注:黑名单保存到 MySQL 中
**
思路:
1、判断用户是否在白名单(目前存在mysql表)
2、判断点击是否超过阈值
3、更新点击次数

若有收获,就点个赞吧
0 人点赞
