一、环境准备
1、创建Maven项目
idea安装Scala插件,方便Scala开发。
2、WordCount案例
添加依赖
<dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.0.0</version></dependency></dependencies><build><plugins><!-- 该插件用于将 Scala代码编译成 class文件 --><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.2.2</version><executions><execution><!-- 声明绑定到 maven的 compile阶段 --><goals><goal>testCompile</goal></goals></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.1.0</version><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build>
创建一个object准备测试
第一种方法:
读取分组后的数量获取个数
object WordCountTest {def main(args: Array[String]): Unit = {// 1、连接Sparkval conf: SparkConf = new SparkConf().setMaster("local").setAppName("WordCount")val sparkContext = new SparkContext(conf)// 2、执行业务操作// 2.1、读取文件,一行一行val lines: RDD[String] = sparkContext.textFile("datas")// 2.2、将一行分割后转换val value: RDD[(String, Int)] = lines.flatMap(_.split(" ")).groupBy(word => word).map {case (word, list) => {(word, list.size)}}// 2.3、收集数据value.collect().foreach(println)// 3、关闭连接sparkContext.stop()}}
第二种方法:
通过每次映射成数量1,相加得到
object WordCountTest2 {def main(args: Array[String]): Unit = {// 1、连接Sparkval conf: SparkConf = new SparkConf().setMaster("local").setAppName("WordCount")val sparkContext = new SparkContext(conf)// 2、执行业务操作// 2.1、读取文件,一行一行val lines: RDD[String] = sparkContext.textFile("datas")// 2.2、将一行分割后转换val value: RDD[(String, Int)] = lines.flatMap(_.split(" "))// 缺少聚合的感觉, 将每个分割的单词获取到数量.map(word => (word, 1)).groupBy(tuple => tuple._1).map {// 将元组第二个数量相加计算case (word, list) => {list.reduce((word1, word2) => (word1._1, word1._2 + word2._2))}}// 2.3、收集数据value.collect().foreach(println)// 3、关闭连接sparkContext.stop()}}
上面两种方法感觉和scala中的单词统计差不多呀。spark也没什么快速的呀。
下面来演示一个spark提供的功能:reduceByKey()
object WordCountTest3 {def main(args: Array[String]): Unit = {// 1、连接Sparkval conf: SparkConf = new SparkConf().setMaster("local").setAppName("WordCount")val sparkContext = new SparkContext(conf)// 2、执行业务操作// 2.1、读取文件,一行一行val lines: RDD[String] = sparkContext.textFile("datas")// 2.2、将一行分割后转换val value: RDD[(String, Int)] = lines.flatMap(_.split(" "))// 缺少聚合的感觉, 将每个分割的单词获取到数量.map(word => (word, 1))// spark中提供方法 reduceByKey(),对相同key的value进行操作.reduceByKey(_ + _)// 2.3、收集数据value.collect().foreach(println)// 3、关闭连接sparkContext.stop()}}
运行spark过程中有记录日志
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties21/06/06 10:26:46 INFO SparkContext: Running Spark version 3.0.021/06/06 10:26:46 INFO ResourceUtils: ==============================================================21/06/06 10:26:46 INFO ResourceUtils: Resources for spark.driver:21/06/06 10:26:46 INFO ResourceUtils: ==============================================================21/06/06 10:26:46 INFO SparkContext: Submitted application: WordCount21/06/06 10:26:46 INFO SecurityManager: Changing view acls to: dell21/06/06 10:26:46 INFO SecurityManager: Changing modify acls to: dell21/06/06 10:26:46 INFO SecurityManager: Changing view acls groups to:21/06/06 10:26:46 INFO SecurityManager: Changing modify acls groups to:21/06/06 10:26:46 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(dell); groups with view permissions: Set(); users with modify permissions: Set(dell); groups with modify permissions: Set()21/06/06 10:26:47 INFO Utils: Successfully started service 'sparkDriver' on port 50500.21/06/06 10:26:47 INFO SparkEnv: Registering MapOutputTracker21/06/06 10:26:47 INFO SparkEnv: Registering BlockManagerMaster21/06/06 10:26:47 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information21/06/06 10:26:47 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up21/06/06 10:26:47 INFO SparkEnv: Registering BlockManagerMasterHeartbeat21/06/06 10:26:47 INFO DiskBlockManager: Created local directory at C:\Users\dell\AppData\Local\Temp\blockmgr-1de988b3-117d-4408-acae-672d8a0e5c7e21/06/06 10:26:47 INFO MemoryStore: MemoryStore started with capacity 2.5 GiB21/06/06 10:26:47 INFO SparkEnv: Registering OutputCommitCoordinator21/06/06 10:26:47 INFO Utils: Successfully started service 'SparkUI' on port 4040.21/06/06 10:26:47 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://jovo:404021/06/06 10:26:48 INFO Executor: Starting executor ID driver on host jovo21/06/06 10:26:48 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 50515.21/06/06 10:26:48 INFO NettyBlockTransferService: Server created on jovo:5051521/06/06 10:26:48 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy21/06/06 10:26:48 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, jovo, 50515, None)21/06/06 10:26:48 INFO BlockManagerMasterEndpoint: Registering block manager jovo:50515 with 2.5 GiB RAM, BlockManagerId(driver, jovo, 50515, None)21/06/06 10:26:48 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, jovo, 50515, None)21/06/06 10:26:48 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, jovo, 50515, None)21/06/06 10:26:48 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 241.5 KiB, free 2.5 GiB)21/06/06 10:26:49 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 23.4 KiB, free 2.5 GiB)21/06/06 10:26:49 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on jovo:50515 (size: 23.4 KiB, free: 2.5 GiB)21/06/06 10:26:49 INFO SparkContext: Created broadcast 0 from textFile at WordCountTest3.scala:1621/06/06 10:26:49 INFO FileInputFormat: Total input paths to process : 221/06/06 10:26:49 INFO SparkContext: Starting job: collect at WordCountTest3.scala:2921/06/06 10:26:49 INFO DAGScheduler: Registering RDD 3 (map at WordCountTest3.scala:22) as input to shuffle 021/06/06 10:26:49 INFO DAGScheduler: Got job 0 (collect at WordCountTest3.scala:29) with 2 output partitions21/06/06 10:26:49 INFO DAGScheduler: Final stage: ResultStage 1 (collect at WordCountTest3.scala:29)21/06/06 10:26:49 INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 0)21/06/06 10:26:49 INFO DAGScheduler: Missing parents: List(ShuffleMapStage 0)21/06/06 10:26:49 INFO DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[3] at map at WordCountTest3.scala:22), which has no missing parents21/06/06 10:26:49 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 6.8 KiB, free 2.5 GiB)21/06/06 10:26:49 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 4.0 KiB, free 2.5 GiB)21/06/06 10:26:49 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on jovo:50515 (size: 4.0 KiB, free: 2.5 GiB)21/06/06 10:26:49 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:120021/06/06 10:26:49 INFO DAGScheduler: Submitting 2 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[3] at map at WordCountTest3.scala:22) (first 15 tasks are for partitions Vector(0, 1))21/06/06 10:26:49 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks21/06/06 10:26:49 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, jovo, executor driver, partition 0, PROCESS_LOCAL, 7369 bytes)21/06/06 10:26:49 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)21/06/06 10:26:50 INFO HadoopRDD: Input split: file:/E:/IdeaProjects/spark/datas/1.txt:0+2421/06/06 10:26:50 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 1326 bytes result sent to driver21/06/06 10:26:50 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, jovo, executor driver, partition 1, PROCESS_LOCAL, 7369 bytes)21/06/06 10:26:50 INFO Executor: Running task 1.0 in stage 0.0 (TID 1)21/06/06 10:26:50 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 429 ms on jovo (executor driver) (1/2)21/06/06 10:26:50 INFO HadoopRDD: Input split: file:/E:/IdeaProjects/spark/datas/2.txt:0+2421/06/06 10:26:50 INFO Executor: Finished task 1.0 in stage 0.0 (TID 1). 1197 bytes result sent to driver21/06/06 10:26:50 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 22 ms on jovo (executor driver) (2/2)21/06/06 10:26:50 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool21/06/06 10:26:50 INFO DAGScheduler: ShuffleMapStage 0 (map at WordCountTest3.scala:22) finished in 0.555 s21/06/06 10:26:50 INFO DAGScheduler: looking for newly runnable stages21/06/06 10:26:50 INFO DAGScheduler: running: Set()21/06/06 10:26:50 INFO DAGScheduler: waiting: Set(ResultStage 1)21/06/06 10:26:50 INFO DAGScheduler: failed: Set()21/06/06 10:26:50 INFO DAGScheduler: Submitting ResultStage 1 (ShuffledRDD[4] at reduceByKey at WordCountTest3.scala:23), which has no missing parents21/06/06 10:26:50 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 4.2 KiB, free 2.5 GiB)21/06/06 10:26:50 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 2.6 KiB, free 2.5 GiB)21/06/06 10:26:50 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on jovo:50515 (size: 2.6 KiB, free: 2.5 GiB)21/06/06 10:26:50 INFO SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:120021/06/06 10:26:50 INFO DAGScheduler: Submitting 2 missing tasks from ResultStage 1 (ShuffledRDD[4] at reduceByKey at WordCountTest3.scala:23) (first 15 tasks are for partitions Vector(0, 1))21/06/06 10:26:50 INFO TaskSchedulerImpl: Adding task set 1.0 with 2 tasks21/06/06 10:26:50 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 2, jovo, executor driver, partition 0, NODE_LOCAL, 7143 bytes)21/06/06 10:26:50 INFO Executor: Running task 0.0 in stage 1.0 (TID 2)21/06/06 10:26:50 INFO ShuffleBlockFetcherIterator: Getting 2 (120.0 B) non-empty blocks including 2 (120.0 B) local and 0 (0.0 B) host-local and 0 (0.0 B) remote blocks21/06/06 10:26:50 INFO ShuffleBlockFetcherIterator: Started 0 remote fetches in 6 ms21/06/06 10:26:50 INFO Executor: Finished task 0.0 in stage 1.0 (TID 2). 1394 bytes result sent to driver21/06/06 10:26:50 INFO TaskSetManager: Starting task 1.0 in stage 1.0 (TID 3, jovo, executor driver, partition 1, NODE_LOCAL, 7143 bytes)21/06/06 10:26:50 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 2) in 59 ms on jovo (executor driver) (1/2)21/06/06 10:26:50 INFO Executor: Running task 1.0 in stage 1.0 (TID 3)21/06/06 10:26:50 INFO ShuffleBlockFetcherIterator: Getting 2 (108.0 B) non-empty blocks including 2 (108.0 B) local and 0 (0.0 B) host-local and 0 (0.0 B) remote blocks21/06/06 10:26:50 INFO ShuffleBlockFetcherIterator: Started 0 remote fetches in 0 ms21/06/06 10:26:50 INFO Executor: Finished task 1.0 in stage 1.0 (TID 3). 1327 bytes result sent to driver21/06/06 10:26:50 INFO TaskSetManager: Finished task 1.0 in stage 1.0 (TID 3) in 21 ms on jovo (executor driver) (2/2)21/06/06 10:26:50 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool21/06/06 10:26:50 INFO DAGScheduler: ResultStage 1 (collect at WordCountTest3.scala:29) finished in 0.084 s21/06/06 10:26:50 INFO DAGScheduler: Job 0 is finished. Cancelling potential speculative or zombie tasks for this job21/06/06 10:26:50 INFO TaskSchedulerImpl: Killing all running tasks in stage 1: Stage finished21/06/06 10:26:50 INFO DAGScheduler: Job 0 finished: collect at WordCountTest3.scala:29, took 0.959135 s21/06/06 10:26:50 INFO SparkUI: Stopped Spark web UI at http://jovo:4040(Hello,4)(Scala,2)(Spark,2)21/06/06 10:26:50 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!21/06/06 10:26:50 INFO MemoryStore: MemoryStore cleared21/06/06 10:26:50 INFO BlockManager: BlockManager stopped21/06/06 10:26:50 INFO BlockManagerMaster: BlockManagerMaster stopped21/06/06 10:26:50 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!21/06/06 10:26:50 INFO SparkContext: Successfully stopped SparkContext21/06/06 10:26:50 INFO ShutdownHookManager: Shutdown hook called21/06/06 10:26:50 INFO ShutdownHookManager: Deleting directory C:\Users\dell\AppData\Local\Temp\spark-96350eb7-0893-463d-8378-952598592965Process finished with exit code 0
如果我们不想要显示这些日志的时候,可以通过配置log4j进行忽略。
在类路径下编写log4j.properties配置文件
log4j.rootCategory=ERROR, consolelog4j.appender.console=org.apache.log4j.ConsoleAppenderlog4j.appender.console.target=System.errlog4j.appender.console.layout=org.apache.log4j.PatternLayoutlog4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n# Set the default spark-shell log level to ERROR. When running the spark-shell,the# log level for this class is used to overwrite the root logger's log level, so that# the user can have different defaults for the shell and regular Spark apps.log4j.logger.org.apache.spark.repl.Main=ERROR# Settings to quiet third party logs that are too verboselog4j.logger.org.spark_project.jetty=ERRORlog4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERRORlog4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERRORlog4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERRORlog4j.logger.org.apache.parquet=ERRORlog4j.logger.parquet=ERROR# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive supportlog4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATALlog4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
3、spark运行环境
Spark 作为一个数据处理框架和计算引擎,被设计在所有常见的集群环境中运行, 在国内工作中主流的环境为 Yarn,不过逐渐容器式环境也慢慢流行起来。接下来,我们就分别看看不同环境下 Spark 的运行
1、Local模式
之前一直在使用的模式可不是 Local 模式哟。所谓的 Local 模式,就是不需要其他任何节点资源就可以在本地执行 Spark 代码的环境,一般用于教学,调试,演示等,之前在 IDEA 中运行代码的环境我们称之为开发环境,不太一样。
将 spark-3.0.0-bin-hadoop3.2.tgz 文件上传到 Linux 并解压缩,放置在指定位置,路径中不要包含中文或空格
启动local环境:
bin/spark-shell
本地模式中已经给我们准备好了一个SparkContext对象,叫做sc,直接使用即可。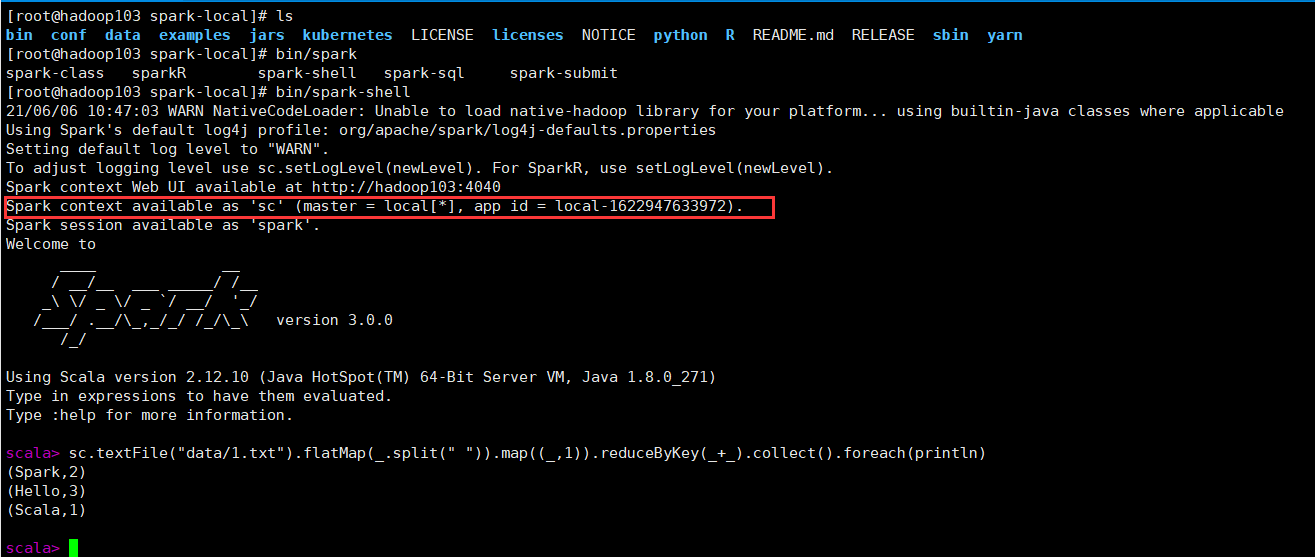
sc.textFile("data/1.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect().foreach(println)
我们开发肯定不在shell中操作,就需要提交jar包来运行,使用bin/spark-submit提交任务
[root@hadoop103 spark-local]# bin/spark-submit --helpUsage: spark-submit [options] <app jar | python file | R file> [app arguments]Usage: spark-submit --kill [submission ID] --master [spark://...]Usage: spark-submit --status [submission ID] --master [spark://...]Usage: spark-submit run-example [options] example-class [example args]Options:--master MASTER_URL spark://host:port, mesos://host:port, yarn,k8s://https://host:port, or local (Default: local[*]).--deploy-mode DEPLOY_MODE Whether to launch the driver program locally ("client") oron one of the worker machines inside the cluster ("cluster")(Default: client).--class CLASS_NAME Your application's main class (for Java / Scala apps).--name NAME A name of your application.--jars JARS Comma-separated list of jars to include on the driverand executor classpaths.--packages Comma-separated list of maven coordinates of jars to includeon the driver and executor classpaths. Will search the localmaven repo, then maven central and any additional remoterepositories given by --repositories. The format for thecoordinates should be groupId:artifactId:version.--exclude-packages Comma-separated list of groupId:artifactId, to exclude whileresolving the dependencies provided in --packages to avoiddependency conflicts.--repositories Comma-separated list of additional remote repositories tosearch for the maven coordinates given with --packages.--py-files PY_FILES Comma-separated list of .zip, .egg, or .py files to placeon the PYTHONPATH for Python apps.--files FILES Comma-separated list of files to be placed in the workingdirectory of each executor. File paths of these filesin executors can be accessed via SparkFiles.get(fileName).--conf, -c PROP=VALUE Arbitrary Spark configuration property.--properties-file FILE Path to a file from which to load extra properties. If notspecified, this will look for conf/spark-defaults.conf.--driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M).--driver-java-options Extra Java options to pass to the driver.--driver-library-path Extra library path entries to pass to the driver.--driver-class-path Extra class path entries to pass to the driver. Note thatjars added with --jars are automatically included in theclasspath.--executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).--proxy-user NAME User to impersonate when submitting the application.This argument does not work with --principal / --keytab.--help, -h Show this help message and exit.--verbose, -v Print additional debug output.--version, Print the version of current Spark.Cluster deploy mode only:--driver-cores NUM Number of cores used by the driver, only in cluster mode(Default: 1).Spark standalone or Mesos with cluster deploy mode only:--supervise If given, restarts the driver on failure.Spark standalone, Mesos or K8s with cluster deploy mode only:--kill SUBMISSION_ID If given, kills the driver specified.--status SUBMISSION_ID If given, requests the status of the driver specified.Spark standalone, Mesos and Kubernetes only:--total-executor-cores NUM Total cores for all executors.Spark standalone, YARN and Kubernetes only:--executor-cores NUM Number of cores used by each executor. (Default: 1 inYARN and K8S modes, or all available cores on the workerin standalone mode).Spark on YARN and Kubernetes only:--num-executors NUM Number of executors to launch (Default: 2).If dynamic allocation is enabled, the initial number ofexecutors will be at least NUM.--principal PRINCIPAL Principal to be used to login to KDC.--keytab KEYTAB The full path to the file that contains the keytab for theprincipal specified above.Spark on YARN only:--queue QUEUE_NAME The YARN queue to submit to (Default: "default").--archives ARCHIVES Comma separated list of archives to be extracted into theworking directory of each executor.
运行案例程序
bin/spark-submit \> --class org.apache.spark.examples.SparkPi \> --master local[2] \> ./examples/jars/spark-examples_2.12-3.0.0.jar \> 10
2、Standalone模式
local 本地模式毕竟只是用来进行练习演示的,真实工作中还是要将应用提交到对应的集群中去执行,这里我们来看看只使用 Spark 自身节点运行的集群模式,也就是我们所谓的独立部署(Standalone)模式。Spark 的 Standalone 模式体现了经典的 master-slave 模式。
1、编辑conf中的slaves,将节点添加。
2、修改spark-env.sh,配置JAVA_HOME和集群master节点
export JAVA_HOME=/opt/jdk1.8.0_271SPARK_MASTER_HOST=hadoop103SPARK_MASTER_PORT=7077
注意:7077 端口,相当于 hadoop3 内部通信的 8020 端口,此处的端口需要确认自己的 Hadoop配置
配置好以后可以通过sbin/start-all.sh启动spark集群。
提交应用:
bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master spark://hadoop103:7077 \./examples/jars/spark-examples_2.12-3.0.0.jar \10
参数解析:
bin/spark-submit \--class <main-class>--master <master-url> \... # other options<application-jar> \[application-arguments]
- —class 表示要执行程序的主类
- —master spark://hadoop103:7077 独立部署模式,连接到 Spark 集群
- spark-examples_2.12-3.0.0.jar 运行类所在的 jar 包
- 数字 10 表示程序的入口参数,用于设定当前应用的任务数量
- —executor-memory 1G :指定每个executor可用内存为1G
- —total-executor-cores 2:所有executor共可用核数
- —executor-cores:指定每个executor可用的cpu核数
- application-arguments 传给 main()方法的参数
3、配置历史服务器
由于 spark-shell 停止掉后,集群监控 hadoop103:4040 页面就看不到历史任务的运行情况,所以开发时都配置历史服务器记录任务运行情况
1、修改spark-defaults.conf,配置日志存储路径
spark.eventLog.enabled truespark.eventLog.dir hdfs://hadoop103:8020/directory
注意:需要启动 hadoop 集群,HDFS 上的 directory 目录需要提前存在
sbin/start-dfs.shhadoop fs -mkdir /directory
2、修改spark-env.sh,添加日志配置
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080-Dspark.history.fs.logDirectory=hdfs://hadoop103:8020/directory-Dspark.history.retainedApplications=30"
- 参数 1 含义:WEB UI 访问的端口号为 18080
- 参数 2 含义:指定历史服务器日志存储路径
- 参数 3 含义:指定保存 Application 历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数
3、启动历史服务器sbin/start-history-server.sh
重新执行任务:
bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master spark://hadoop103:7077 \./examples/jars/spark-examples_2.12-3.0.0.jar \10
4、配置高可用
使用Zookeeper设置多个Master,避免单点故障
1、停止集群并且启动zk
2、修改spark-env.sh配置文件
注释如下内容:#SPARK_MASTER_HOST=hadoop103#SPARK_MASTER_PORT=7077添加如下内容:#Master监控页面默认访问端口为 8080,但是可能会和 Zookeeper冲突,所以改成 8989,也可以自定义,访问 UI监控页面时请注意SPARK_MASTER_WEBUI_PORT=8989export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER-Dspark.deploy.zookeeper.url=k8s-node01,k8s-node02,hadoop103-Dspark.deploy.zookeeper.dir=/spark"
3、在另一台机器单独启动Master
sbin/start-master.sh
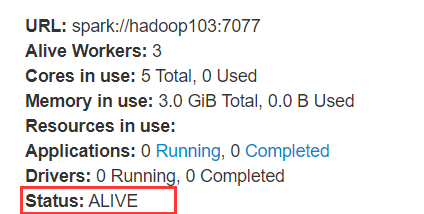
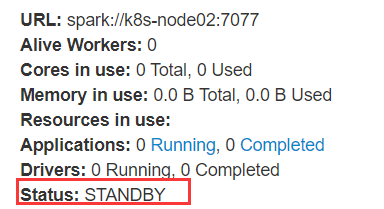
现在提交任务到集群
bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master spark://hadoop103:7077,k8s-node02:7077 \./examples/jars/spark-examples_2.12-3.0.0.jar \10
随便杀一个master,另外一个standby状态的等检测到之后就会上位了。
5、Yarn模式
独立部署(Standalone)模式由 Spark 自身提供计算资源,无需其他框架提供资源。这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但是你也要记住,Spark 主要是计算框架,而不是资源调度框架,所以本身提供的资源调度并不是它的强项,所以还是和其他专业的资源调度框架集成会更靠谱一些。所以接下来我们来学习在强大的 Yarn 环境下 Spark 是如何工作的(其实是因为在国内工作中,Yarn 使用的非常多)。
1、修改Hadoop的yarn-site.xml配置文件
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是 true --><property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是 true --><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property>
2、修改conf/spark-env.sh,添加JAVA_HOME和YARN_CONF_DIR配置
export JAVA_HOME=/opt/jdk1.8.0_271YARN_CONF_DIR=/opt/module/hadoop-3.1.4/etc/hadoop
3、启动HDFS和yarn
然后提交一个任务
bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master yarn \--deploy-mode cluster \./examples/jars/spark-examples_2.12-3.0.0.jar \10
4、配置历史服务器
1、修改spark-defaults.conf,配置日志存储路径
spark.eventLog.enabled truespark.eventLog.dir hdfs://hadoop103:8020/directory
注意:需要启动 hadoop 集群,HDFS 上的目录需要提前存在。
2、修改spark-env.sh,添加日志配置
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080-Dspark.history.fs.logDirectory=hdfs://hadoop103:8020/directory-Dspark.history.retainedApplications=30"
3、启动历史服务器
sbin/start-history-server.sh
6、kubernetes &Mecos
https://spark.apache.org/docs/latest/running-on-kubernetes.html
7、windows
使用cmd脚本启动即可。
8、部署模式对比
| 模式 | 机器安装数 | 需启动的进程 | 所属者 | 应用场景 |
|---|---|---|---|---|
| Local | 1 | 无 | Spark | 测试 |
| StandAlone | 3 | Maste及Worker | Spark | 单独部署 |
| Yarn | 1 | Yarn和HDFS | Hadoop | 混合部署 |
9、端口号
- Spark 查看当前 Spark-shell 运行任务情况端口号:4040(计算)
- Spark Master 内部通信服务端口号:7077
- Standalone 模式下,Spark Master Web 端口号:8080(资源)
- Spark 历史服务器端口号:18080
- Hadoop YARN 任务运行情况查看端口号:8088
二、运行架构
Spark 框架的核心是一个计算引擎,整体来说,它采用了标准 master-slave 的结构。如下图所示,它展示了一个 Spark 执行时的基本结构。图形中的 Driver 表示 master,负责管理整个集群中的作业任务调度。图形中的 Executor 则是 slave,负责实际执行任务。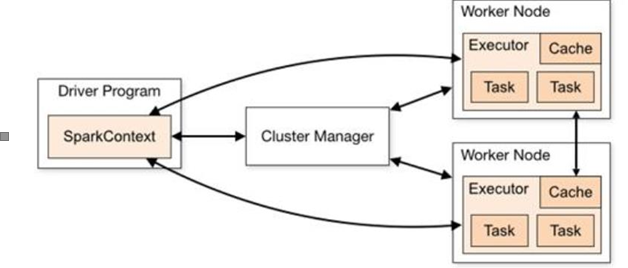
1、核心组件
1、Driver
Spark 驱动器节点,用于执行 Spark 任务中的 main 方法,负责实际代码的执行工作。
Driver 在 Spark 作业执行时主要负责:
- 将用户程序转化为作业(job)
- 在 Executor 之间调度任务(task)
- 跟踪 Executor 的执行情况
- 通过 UI 展示查询运行情况
实际上,我们无法准确地描述 Driver 的定义,因为在整个的编程过程中没有看到任何有关Driver 的字眼。所以简单理解,所谓的 Driver 就是驱使整个应用运行起来的程序,也称之为Driver 类。
2、Executor
Spark Executor 是集群中工作节点(Worker)中的一个 JVM 进程,负责在 Spark 作业中运行具体任务(Task),任务彼此之间相互独立。Spark 应用启动时,Executor 节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有 Executor 节点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他 Executor 节点上继续运行。
Executor 有两个核心功能:
- 负责运行组成 Spark 应用的任务,并将结果返回给驱动器进程
- 它们通过自身的块管理器(Block Manager)为用户程序中要求缓存的 RDD 提供内存式存储。RDD 是直接缓存在 Executor 进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
3、Master&Worker
Spark 集群的独立部署环境中,不需要依赖其他的资源调度框架,自身就实现了资源调度的功能,所以环境中还有其他两个核心组件:Master 和 Worker,这里的 Master 是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责,类似于 Yarn 环境中的 RM, 而Worker 呢,也是进程,一个 Worker 运行在集群中的一台服务器上,由 Master 分配资源对数据进行并行的处理和计算,类似于 Yarn 环境中 NM。
4、ApplicationMaster
Hadoop 用户向 YARN 集群提交应用程序时,提交程序中应该包含 ApplicationMaster,用于向资源调度器申请执行任务的资源容器 Container,运行用户自己的程序任务 job,监控整个任务的执行,跟踪整个任务的状态,处理任务失败等异常情况。
说的简单点就是,ResourceManager(资源)和 Driver(计算)之间的解耦合靠的就是ApplicationMaster。
2、核心概念
1、Executor与Core
Spark Executor 是集群中运行在工作节点(Worker)中的一个 JVM 进程,是整个集群中的专门用于计算的节点。在提交应用中,可以提供参数指定计算节点的个数,以及对应的资源。这里的资源一般指的是工作节点 Executor 的内存大小和使用的虚拟 CPU 核(Core)数量。
应用程序相关启动参数如下:
| —num-executors | 配置 Executor 的数量 |
|---|---|
| —executor-memory | 配置每个 Executor 的内存大小 |
| —executor-cores | 配置每个 Executor 的虚拟 CPU core 数量 |
2、并行度
在分布式计算框架中一般都是多个任务同时执行,由于任务分布在不同的计算节点进行计算,所以能够真正地实现多任务并行执行,记住,这里是并行,而不是并发。这里我们将整个集群并行执行任务的数量称之为并行度。那么一个作业到底并行度是多少呢?这个取决于框架的默认配置。应用程序也可以在运行过程中动态修改。
3、有向无环图(DAG)
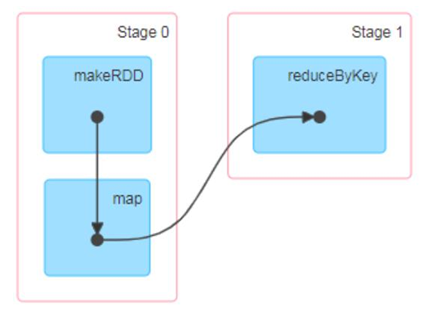
大数据计算引擎框架我们根据使用方式的不同一般会分为四类,其中第一类就是Hadoop 所承载的 MapReduce,它将计算分为两个阶段,分别为 Map 阶段 和 Reduce 阶段。对于上层应用来说,就不得不想方设法去拆分算法,甚至于不得不在上层应用实现多个 Job的串联,以完成一个完整的算法,例如迭代计算。 由于这样的弊端,催生了支持 DAG 框架的产生。因此,支持 DAG 的框架被划分为第二代计算引擎。如 Tez 以及更上层的Oozie。这里我们不去细究各种 DAG 实现之间的区别,不过对于当时的 Tez 和 Oozie 来说,大多还是批处理的任务。接下来就是以 Spark 为代表的第三代的计算引擎。第三代计算引擎的特点主要是 Job 内部的 DAG 支持(不跨越 Job),以及实时计算。
这里所谓的有向无环图,并不是真正意义的图形,而是由 Spark 程序直接映射成的数据流的高级抽象模型。简单理解就是将整个程序计算的执行过程用图形表示出来,这样更直观,更便于理解,可以用于表示程序的拓扑结构。
DAG(Directed Acyclic Graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会闭环。
4、提交流程
所谓的提交流程,其实就是我们开发人员根据需求写的应用程序通过 Spark 客户端提交给 Spark 运行环境执行计算的流程。在不同的部署环境中,这个提交过程基本相同,但是又有细微的区别,我们这里不进行详细的比较,但是因为国内工作中,将 Spark 引用部署到Yarn 环境中会更多一些,所以本课程中的提交流程是基于 Yarn 环境的。
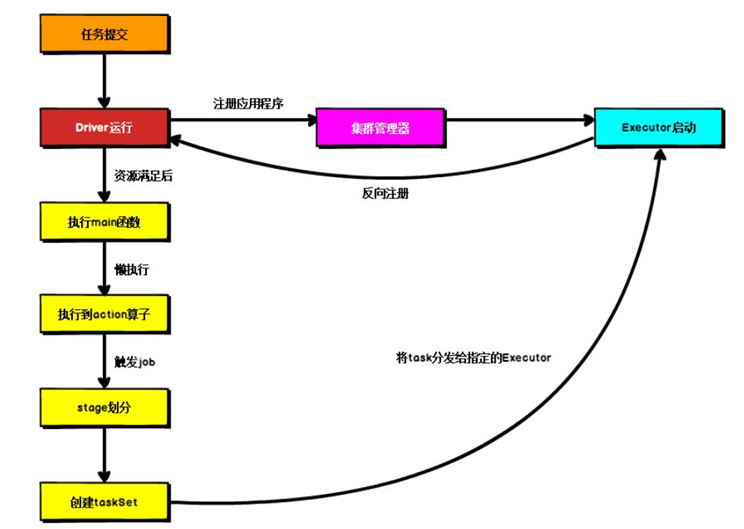
Spark 应用程序提交到 Yarn 环境中执行的时候,一般会有两种部署执行的方式:Client和 Cluster。两种模式主要区别在于:Driver 程序的运行节点位置。
5、 Yarn Client 模式
Client 模式将用于监控和调度的 Driver 模块在客户端执行,而不是在 Yarn 中,所以一
般用于测试。
- Driver 在任务提交的本地机器上运行
- Driver 启动后会和 ResourceManager 通讯申请启动 ApplicationMaster
- ResourceManager 分配 container,在合适的 NodeManager 上启动 ApplicationMaster,负责向 ResourceManager 申请 Executor 内存
- ResourceManager 接到 ApplicationMaster 的资源申请后会分配 container,然后ApplicationMaster 在资源分配指定的 NodeManager 上启动 Executor 进程
- Executor 进程启动后会向 Driver 反向注册,Executor 全部注册完成后 Driver 开始执行main 函数
- 之后执行到 Action 算子时,触发一个 Job,并根据宽依赖开始划分 stage,每个 stage 生成对应的 TaskSet,之后将 task 分发到各个 Executor 上执行。
6、Yarn Cluster模式
Cluster 模式将用于监控和调度的 Driver 模块启动在 Yarn 集群资源中执行。一般应用于实际生产环境。
- 在 YARN Cluster 模式下,任务提交后会和 ResourceManager 通讯申请启动ApplicationMaster
- 随后 ResourceManager 分配 container,在合适的 NodeManager 上启动 ApplicationMaster,此时的 ApplicationMaster 就是 Driver。
- Driver 启动后向 ResourceManager 申请 Executor 内存,ResourceManager 接到ApplicationMaster 的资源申请后会分配 container,然后在合适的 NodeManager 上启动Executor 进程
- Executor 进程启动后会向 Driver 反向注册,Executor 全部注册完成后 Driver 开始执行main 函数
- 之后执行到 Action 算子时,触发一个 Job,并根据宽依赖开始划分 stage,每个 stage 生成对应的 TaskSet,之后将 task 分发到各个 Executor 上执行。

若有收获,就点个赞吧
0 人点赞
