数据探索
数据清洗—>缺失值?
- 缺失值的原因
- 信息暂时无法获取。如商品售后评价
- 信息被遗漏。可能是因为输入时认为不重要、忘记填写了或对数据理解错误而遗
- 获取这些信息的代价太大。如统计某校所有学生每个月的生活费,家庭实际收入等等。
- 有些对象的某个或某些属性是不可用的。如一个未婚者的配偶姓名、一个儿童的固定收入状况等
- 处理方法
- 缺失值较多:直接舍弃该特征
- 缺失值较少(<10%):填充处理
- 缺失值填充的方法
- 异常值填充:将缺失值作为一种情况处理0
- 均值/条件均值填充:
- 均值:对于数值类型属性,可采用所有样本的该属性均值,
- 非数值类型,可采用所有样本的众数
- 最近距离法K-means:先根据欧式距离或相关分析来确定距离具有缺失数据样本最近的K个样本,将这K个值加权平均来估计该样本的缺失数据
- 算法拟合填充:对有值的数据采用随机森林等方法拟合,然后对有缺失值的数据进行预测,用预测的值来填充
具体算法的缺失值处理
简单统计分析,找到不合理的,比如年龄超过100岁
- 特征相似,但结果很偏离,比如相似的机型,购买率差别很大,或者如下图
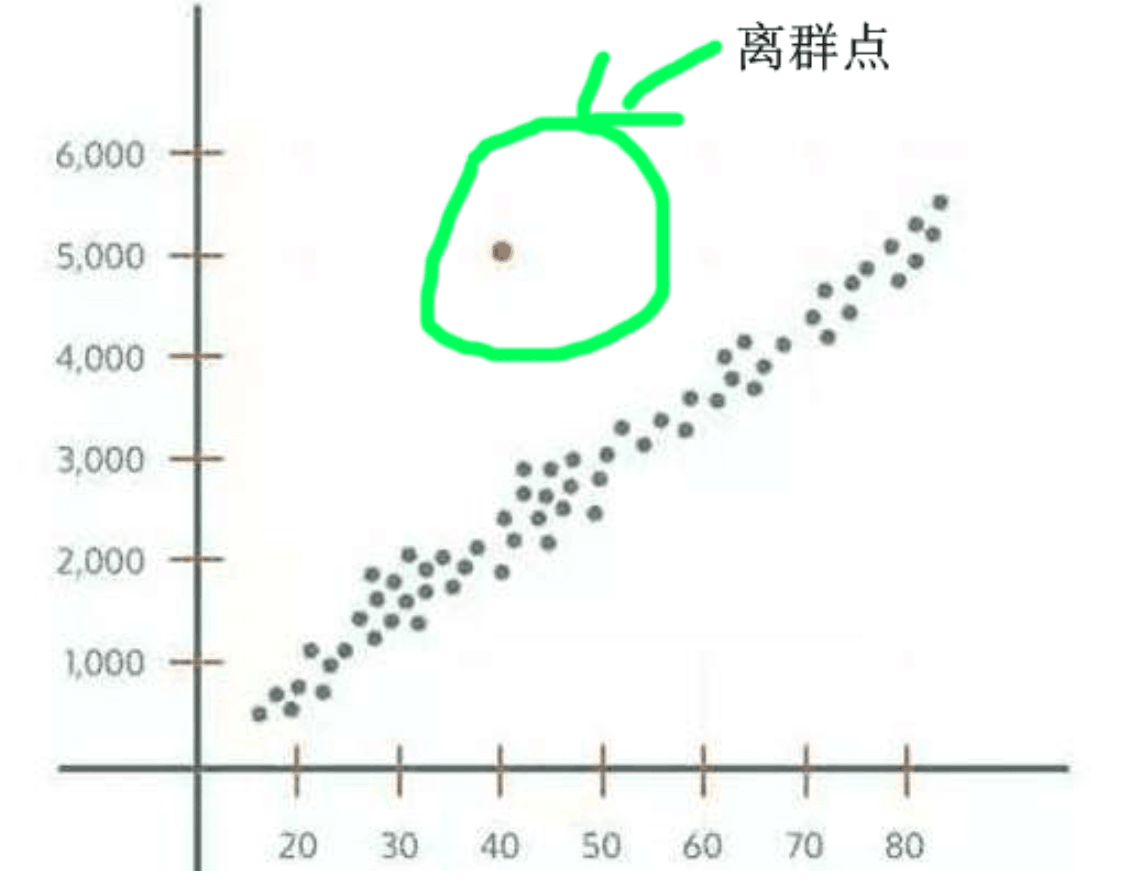
特征偏离
- 3δ原则
- 当数据服从正态分布,根据正态分布的定义可知,距离平均值3δ之外的概率为 P(|x-μ|>3δ) <= 0.003 ,这属于极小概率事件,在默认情况下我们可以认定,距离超过平均值3δ的样本是不存在的。 因此,当样本距离平均值大于3δ,则认定该样本为异常值。
- 当数据不服从正态分布,可以通过远离平均距离多少倍的标准差来判定,多少倍的取值需要根据经验和实际情况来决定。
- 箱型图分析
怎样选择有用的特征?
知乎的回答
- 3δ原则
决策树输出特征重要性
-
数值特征
为什么需要对数值类型的特征做归一化?离散化?
归一化
- Min-Max Scaling:将结果映射到[0,1]范围
- Z-Score归一化:将原始数据映射到均值为0,标准差为1的分布上
- 原因:
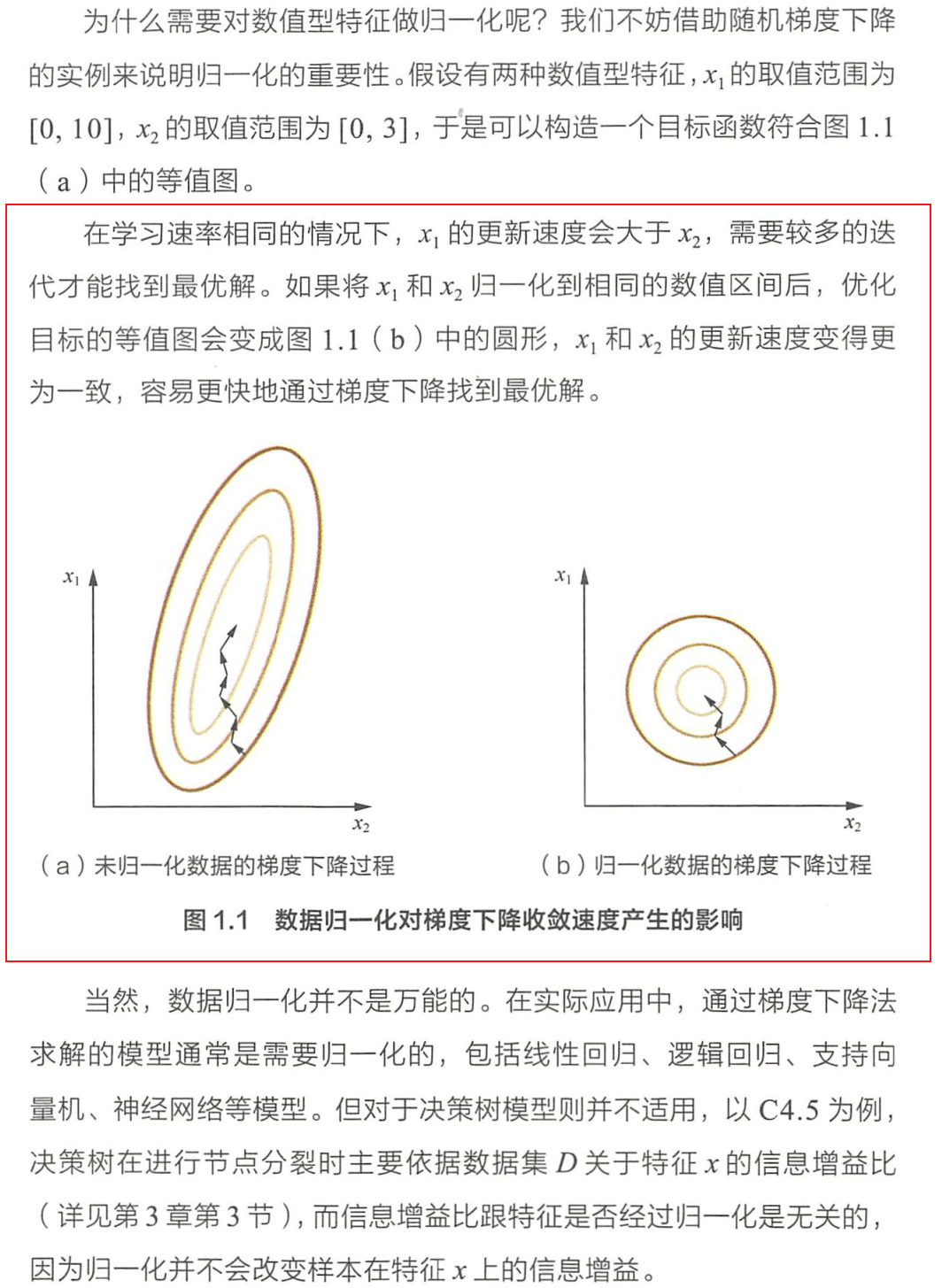
离散化:分段,等频等距。当数值的绝对大小和排序对结果没有影响时,只需分类即可。
标准化和归一化异同?如何选择?
- 异同:
都是线性变换,将原有数据进行了放缩,数据的大小顺序没有发生改变,影响归一化的主要是两个极值,而标准化里每个数据都会影响,因为计算均值和标准差。
- 归一化一般放缩到[0,1]
- 标准化则转为服从标准正态分布
- 如何选择
- 如果对输出结果范围有要求,用归一化
- 如果数据较为稳定,不存在极端的最大最小值,用归一化
- 如果数据存在异常值和较多噪音,用标准化,可以间接通过中心化避免异常值和极端值的影响
类别特征如何处理类别特征?
- 序号编码:通常用于处理类别建具有大小关系的数据
one-hot编码:用于处理类别建不具有大小关系的特征。但是当类别取值较多的时候需要注意 (1) 用向量的稀疏表示来节省空间 (2) 配合特征选择来降低维度。
一是在K近邻算法中,高维空间下两点之间的距离很难得到有效的衡量;二是在逻辑回归模型中,参数的数量会随着维度的增高而增加,容易引起过拟合问题;三是通常只有部分维度是对分类、预测有帮助,因此可以考虑配合特征选择来降低维度。
二进制编码:先用序号编码给每个类别赋予一个类别id,然后将类别id转为二进制编码,本质上是利用二进制对id进行了hash映射,得到0-1特征向量,且维度少于one-hot编码。
组合特征
什么是组合特征?如何处理高维组合特征?
《百面》P06
怎样有效地找到组合特征?
《百面》P09
决策树:每一条从根节点到叶节点的路径都可以看成一种特征组合的方式。
高维特征
如何处理高维特征?比如用户ID和内容ID?
文本特征
文本特征表示有哪些模型?他们的优缺点都是什么?
《百面》P11
- 词袋模型

- N-gram:将连续出现的n个词组成词组作为一个单独的特征放到向量表示中
- 主题模型:能够计算出每篇文章的主题分布
- 词嵌入模型:将词映射成K维的向量。再利用卷积神经网络和循环神经网络对其进行建模,提取文本的特征。
讲解TF-IDF原理,它有什么优点和缺点?针对它的缺点,你有什么优化思路?
优点是简单快速,结果比较符合实际情况。缺点是,单纯以”词频”衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。而且,这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的。
全文的第一段和每一段的第一句话,给予较大的权重。N-gram算法是什么?有什么优缺点?
优点在于它包含了前N-1个词所能提供的全部信息,这些词对于当前词的出现具有很强的约束力,然而它的缺点是需要相当规模的训练文本来确定模型的参数。当N很大时,模型的参数空间过大。Word2Vec (具体看word2vec那一节
讲解一下word2vec工作原理?损失函数是什么?
有两种网络结构,分别是CBOW(上下文预测一个词)和Skip-gram(一个词预测上下文)
损失函数一般用交叉熵
详细:https://www.cnblogs.com/pinard/p/7243513.htmlSkip-gram和cbow有何异同?
skip-gram是根据一个词预测其上下文,cbow是根据上下文预测改词。
负采样和hierachicalSoftmax ??
讲解一下LDA模型原理和训练过程?
Word2vec和LDA两个模型有什么区别和联系?
LDA利用文档中单词的共现关系来对单词按主题聚类,也可以理解为对“文档-单词”矩阵进行分解,得到“文档-主题”和“主题-单词”两个概率分布,而 Word2Vec其实是对“上下文-单词”矩阵进行学习,其中上下文由周围的几个单词组成,由此得到的刺向了表示更多地融入了上下文共现的特征,也就是说,如果两个单词所对应的Word2Vec向量相似度高,那么他们很可能经常在相同的上下文中出现。
主题模型和词嵌入两类方法最大的不同其实在于模型本身,主题模型是一种基于概率图模型的生成式模型,其似然函数可以写成若干条件概率连乘的形式,其中包括需要推测的隐含变量(即主题),而词嵌入模型一般表达为神经网络的形式,似然函数定义在网络的输出之上,需要通过学习网络的权重得到单词的稠密向量表示。
讲解贝叶斯平滑原理?以及如何训练得到平滑参数
贝叶斯平滑在朴素贝叶斯法中出现过
防止出现估计概率值为0,影响后续计算。

若有收获,就点个赞吧
0 人点赞
