研究 AL 最关键的就是研究在训练过程中的哪一个环节插入人工干预,以及怎样进行人工干预。最近在做 NLP 关系分类方面的模型,也是想加入主动学习的策略(因为是小样本数据集),所以来研究一下如何加入人工干预。
1 基本策略
1.1 经典策略
- 随机采样策略(Random Sampling, RS):RS 不需要跟模型的预测结果做任何交互,直接通过随机数从未标注样本池筛选出一批样本给专家标注,常作为主动学习算法中最基础的对比实验。
- 不确定性策略(Uncertainty Strategy, US):US 假设最靠近分类超平面的样本相对分类器具有较丰富的信息量,根据当前模型对样本的预测值筛选出最不确定的样本。
筛选最不确定(信息量最大)的样本,有一些基本的标准:
- 最不确定指标 ( Least Confidence,LC ) 选择最大概率最小的那个样本,认为这样的样本很“难”区分,因此有较大的标注价值。
- 比如二分类问题中,现在有 3 个样本,预测它们为两类的概率分别为
(0.9, 0.1),(0.51, 0.49),(0.7, 0.3)。第二个样本的最大概率0.51是所有三个最大概率(0.9, 0.51, 0.7)中最小的,所以第二个样本的标注价值最大。
- 比如二分类问题中,现在有 3 个样本,预测它们为两类的概率分别为
写成数学公式就是:

其中  为所有的标签类别。
为所有的标签类别。
- 边缘采样 ( Margin Sampling,MS )。选择预测概率中,最大概率和第二大概率相差最小的样本。

其中  为样本
为样本  预测概率中,最大概率和第二大概率对应的类别。特别的,针对二分类问题,Least Confidence 和 Margin Sampling 是等价的。
预测概率中,最大概率和第二大概率对应的类别。特别的,针对二分类问题,Least Confidence 和 Margin Sampling 是等价的。
- 多类别不确定采样 ( Multi-Class Level Uncertainty,MCLU) 是 MS 在多分类问题上的扩展,MCLU 选择离分类界面最远的两个样本,并将它们的距离差值作为评判标准。MCLU 能够在混合类别区域中筛选出最不确信度的样本,如下式所示。其中,
 表示被选中的样本,
表示被选中的样本, 表示样本
表示样本  所属的类别集合,
所属的类别集合, 表示最大预测概率对应的类别,
表示最大预测概率对应的类别, 表示样本 到分类超平面的距离。
表示样本 到分类超平面的距离。

- 熵值最大化 ( Maximize Entropy,ME ) 优先筛选具有更大熵值的样本,熵值可以通过计算
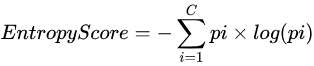
得到,其中  表示第
表示第  个类别的预测值。
个类别的预测值。

当然,在单类别分类中,KL 散度等价于交叉熵;而在多类别分类中就不一样啦。
- 样本最优次优类别 ( Best vs Second Best, BvSB ) [1] 主要是针对多分类问题的一种衡量指标,并且能够缓解 ME 在多分类问题上效果不佳的情况。BvSB 只考虑样本预测值最大的两个类别,忽略了其他预测类别的影响,从而在多分类问题上的效果更佳。
- 委员会投票(Query by Committee, QBC):[2] 一种基于版本空间缩减的采样策略,核心思想是优先选择能够最大程度缩减版本空间的未标记样本。
QBC 包括两个基本步骤:使用多个模型构成委员会、委员会中所有的模型依次对未标注样本进行预测并优先选出投票最不一致的样本进行标注。但这种方法具有很高的计算复杂度,因此提出了其他方法(详见链接)。
- 其他经典的策略: **梯度长度期望 (Expected Gradient Length,EGL) 策略根据未标注样本对当前模型的影响程度优先筛选出对模型影响最大的样本; EGL [3] 是代表性方法之一,能够应用在任意基于梯度下降方法的模型中。方差最小 (Variance Reduction,VR) 策略通过减少输出方差能够降低模型的泛化误差 **[4,5]; [5] 提出了一种基于图的 VR 衡量指标的主动学习方法,通过将所有未标注样本构建在同一个图中,每个样本分布在图中每个结点上。紧接着,通过调和高斯随机场分类器直接预测未标注样本所属的标签; 在优化的过程中,通过挑选一组未标注样本进行预测并获得对应的预测类别,使得未标注样本的预测类别方差最小。
1.2 扩展方法
现在没有 AL 模型是使用单一策略的,下面直接抄了集中扩展方法:
- 组合多种基本策略的主动学习方法**: 组合策略将多个基本策略以互补的方式进行融合,广泛应用于图像分类任务中 [6,7,8,9]。其中,Li 等[6] 基于概率分类模型提出一种自适应的组合策略框架。Li 等[6] 通过信息密度指标 (Information Density Measure) 将未标注样本的信息考虑在内,弥补了不确定性策略的不足**。如下算法所示,该算法能够自然地扩展到更多的组合策略。

- 结合半监督学习 (Semi-Supervised Learning) 的主动学习方法:半监督学习的一种基础方法是自训练 (self-traning) ,其核心步骤如下图所示。自训练算法在训练过程中根据模型的预测结果,挑选合适的样本并自主对其打标记,进而添加到下一轮训练集中。

因为一开始模型使用少量的初始化标注样本来保证模型的初始性能,所以初始化环节至关重要。正是因此,训练过程中很容易引入大量的噪声样本。文献 [10, 11, 12] 组合了不确定性策略和自学习方法 (Self-Training)。上述方法将半监督学习和主动学习巧妙地结合,充分利用各自的优势并弥补不足,取得了显著的成绩。然而,目前的半监督主动学习方法尚未对噪声样本进行有效地处理,因此仍会对模型造成不小的影响。
- 结合生成对抗网络 (Generative Adversarial Networks, GANs),它以无监督的训练方式对大量未标记样本进行训练,并通过生成器产生新的样本。
GANs 对提升主动学习方法的样本筛选效率具有重要的意义。
文献 [19,50] 将主动学习策略结合生成器构建目标函数,通过解决优化问题使得生成器直接生成目标样本,提升了筛选样本的效率。Huijser 等 [20] 首先使用 GAN 沿着与当前分类器决策边界垂直的方向生成一批样本。紧接着,通过可视化从生成的样本中找出类别发生改变的位置,并将其加入待标注样本集。
1.3 基本评价指标
目前看到的,主要是评价模型在保证不损失准确率的情况下,节约标注成本的性能:

其中 SavedRate 表示 ML 相对于全样本减少的标注成本;ExpertAnnotated 表示当模型达到预定的目标性能时,专家标注的样本数量;Full Samples 训练开始之前所有的未标记数据集。一般的实验会先进行全样本训练,并记录最佳验证机准确率,作为 AL 相关算法的目标准确率。
例如,在某组数据集中使用 AlexNet 模型对 Full Samples 张标注图像进行训练,记录训练过程中最佳的验证准确率 (Best accuracy) 并将其作为主动学习的目标准确率 (Target accuracy); 随后,模型通过迭代过程不断提升性能,当达到目标准确率时,记录专家所标注的样本数量 ExpertAnnotated; 此时,就可以算出SavedRate 的值,即该方法能够节约多少标注成本。此外,我们也会将主动学习方法与一些常见的方法进行比较,比如 RS 策略常用于基准对比实验 (baseline)。
References
=====博文等=====
- 知乎问题专栏 —- 主动学习(Active learning)算法的原理是什么,有那些比较具体的应用(1)
- 知乎问题专栏 —- 主动学习(Active learning)算法的原理是什么,有那些比较具体的应用(2)
=====Paper=====
[1] A. J. Joshi, F. Porikli, N. Papanikolopoulos. Multi-class active learning for image classifcation[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2009, 2372–2379.
[2] H. S. Seung, M. Opper, H. Sompolinsky. Query by committee[C]. Proceedings of the Annual Workshop on Computational Learning Theory, 1992, 287–294.
[3] B. Settles. Active learning[J]. Synthesis Lectures on Artifcial Intelligence and Machine Learning, 2012, 6(1):1–114.
[4] A. Atkinson, A. Donev, R. Tobias. Optimum Experimental Designs, with SAS[M]. Oxford University Press, 2007.
[5] M. Ji, J. Han. A variance minimization criterion to active learning on graphs[C]. Artifcial Intelligence and Statistics, 2012, 556–564.
[6] X. Li, Y. Guo. Adaptive active learning for image classifcation[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2013, 859–866.
[7] Y. Gu, Z. Jin, S. C. Chiu. Active learning combining uncertainty and diversity for multi-class image classifcation[J]. IET Computer Vision, 2014, 9(3):400–407.
[8] Z. Zhou, J. Shin, L. Zhang, S. Gurudu, M. Gotway, J. Liang. Fine-tuning convolutional neural networks for biomedical image analysis: Actively and incrementally *[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, 4761–4772.
[9] S. Patra, L. Bruzzone. A batch-mode active learning technique based on multiple uncertainty for svm classifer[J]. IEEE Geoscience & Remote Sensing Letters, 2012, 9(3): 497–501.
[10] W. Han, E. Coutinho, H. Ruan, H. Li, B. Schuller, X. Yu, X. Zhu. Semi-supervised active learning for sound classifcation in hybrid learning environments[J]. Plos One, 2016, 11(9):e0162075.
[11] K. Tomanek, U. Hahn. Semi-supervised active learning for sequence labeling[C]. Proceedings Meeting of the Association for Computational Linguistics, 2009, 1039–1047.
[12] G. Tur, D. Hakkani-Tür, R. E. Schapire. Combining active and semi-supervised learning for spoken language understanding[J]. Speech Communication, 2005, 45(2):171–186.
[13] J.-J. Zhu, J. Bento. Generative adversarial active learning[J]. arXiv preprint arXiv: 1702.07956, 2017.
[14] C. Mayer, R. Timofte. Adversarial sampling for active learning[J]. Computer Science, 2018.
[15] M. Huijser, J. C. van Gemert. Active decision boundary annotation with deep generative models[C]. Proceedings of the IEEE International Conference on Computer Vision, 2017, 5286–5295.

若有收获,就点个赞吧
0 人点赞
