0 写在前面
由于实验室项目的需要,最近开始接触主动学习的玩意。经过学长的推荐并且搜了下网上相关的博文,发现很多人都是通过论文 “Fine-tuning Convolutional Neural Networks for Biomedical Image Analysis: Actively and Incrementally“ 开启 Active Learning 的学习之路的。所以我也就追随同志们的足迹啦。
同时也发现了两位宝藏博主:
- 研究生毕设 + 阿里实习都做 Active Learning 的博主,博客里面开了专栏有 10 篇文章是探索 Active Learning 的。
- 上面论文的作者之一,90 后在读博士的个人主页以及解读该篇论文的博文
我写的这篇文章,主要就是基于上面两位先驱的工作,对主动学习再来一次不简单的入个门。同时毕竟一个完整的学习过程是需要输出的,所以结合自己所看所学所想 print 到 MarkDown ( bushi ) 有记忆的地方能够帮助自己更好的理解。
然后这里还有最开始从 B站 上找到的,在 ICML 上关于 Active Learning 的演讲。虽然是生肉,但语速不快,适合练耳 认真学习知识。
点击查看【bilibili】
1 主动学习概述
概述部分主要基于论文 “Fine-tuning Convolutional Neural Networks for Biomedical Image Analysis: Actively and Incrementally“ 以及多篇解读改论文的博文进行总结,同时作为一个 Active Learning 与 Deep Learning 的初学者,本文害将对一些领域相关的术语进行解释 (e.g. 迁移学习中的 fine-tune, 论文中使用的 patches 等)。本文参考文章的链接会分类呈现在 Reference 章节。
BTW. 因为我目前主攻方向是 NLP,所以也会尝试着将论文中的一些方法迁移到我正在做的关系抽取方向,写一点自己的思考。
1.1 问题的提出 —- 主动学习的初衷
目前深度学习人工神经网络取得了前所未有的成就,卷积神经网络 (CNNs) 在计算机视觉、NLP 等领域也带来了巨大的变革,但目前有监督学习所面临的最大问题是一方面所需要的数据集规模很大,另一方面标注数据集的时间、金钱、人力成本、计算资源等也是空前的。而论文中针对的生物医疗图像领域还不像我们平常见到的物体识别领域 (Object Detection) 有 ImageNet 等大数据集一样,医疗领域的图像需要医学专家(普通的图像我们自己就行)进行标注;常见的 X 光和 CT 一般一个人也就拍一张(数据量小),且标注一张的成本在 20~30 人民币;同时找专家看一张 CT 图时间也不短吧,不像你要识别图片里的猫瞅一眼就行了。
提出主动学习(AL, Active Learning)的初衷(论文作者原话)是:希望使用尽可能少的标签数据来训练一个效果 promising 的分类器。
(同样引自论文作者原话)现在深度学习很火,做的人也越来越多,那么它的门槛可以说是很低的,Caffe,Keras,Torch 等等框架的出现,让该领域的 programming 的门槛直接拆了。所以深度学习真正的门槛变成了很简单概念——钱。这个钱有两个很重要的流向,一是计算机的运算能力 (GPU Power),二是标记数据的数量。如果数据集规模越大,深度学习模型的性能更好,那就喜大普奔了,使劲砸钱整数据就行了,但其实数据量与性能之间是存在瓶颈的(下图应该很多人都见过):
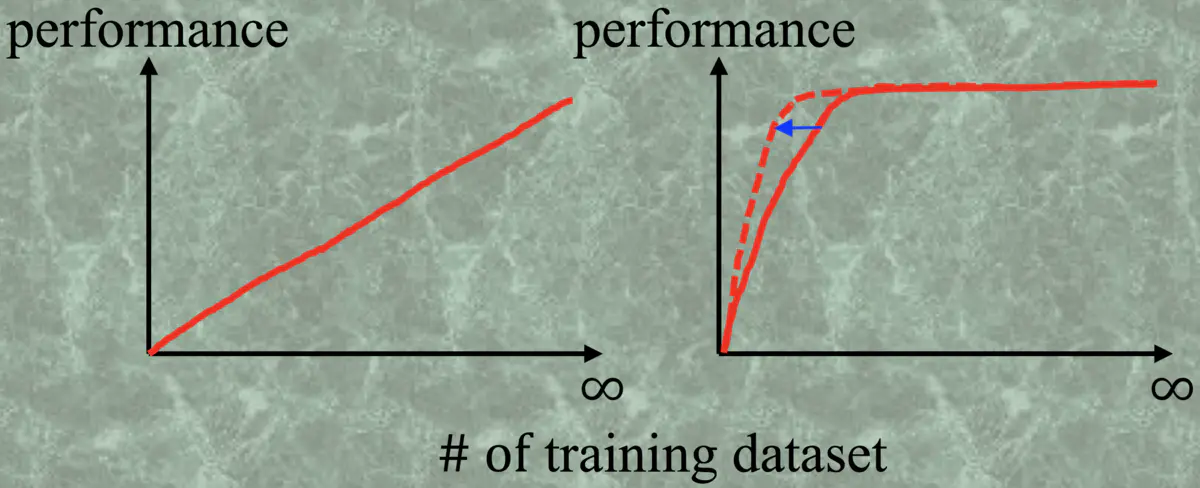
图1.1 数据集规模与分类器性能关系图
在右图中我们可以发现,当训练集的样本数打到某一个临界值的时候,分类器的性能就基本不变了,那在到达临界之后再投入时间和金钱那就是闲的!主动学习就是想让这个临界值变小,即用更少的训练样本来使模型更快地达到最佳性能。 右图中红实线代表随机选取训练集的情况,而红虚线就是理想情况下使用主动学习的手段来增加训练集,从而我们只需要使用更少的训练样本来达到最理想的性能。
当然这个临界值也是根据分类任务不同而存在明显差异的。比如让分类器进行黑白图像的分类(识别目标中只有纯黑图像和纯白图像),那这个临界值是特别小的,往往只需要几幅图像就可以训练一个精度很高的分类器;而如果是判断一个肿瘤的良恶性,那么临界值会很大,因为肿瘤的形状、大小、位置等特征非常多,分类器需要学习很多的样本才能达到一个比较稳定的性能(就算是专业的医生也需要看成百上千张 CT 才能比较准地判断)。
1.2 解决问题的思路 —- 主动学习的指导思想
现在问题很明了了,就是使用何种手段让临界值变小。主动学习给出的思路是,让模型能够自主挑选出“**难的”“信息量大的”“容易分错的**”样本进行训练 (hard mining)。那么 Active Learning 的核心就聚焦在了如何挑选当前分类器分类效果不理想的那些样本 (hard sample),当然这里我们假设这部分 hard sample 是对提升分类器性能最有效最快速的。那么我们如何在不知道真正标签的情况下**定义 hard sample?或者换个角度来想,怎么描述当前分类器对不同样本的分类结果的好坏?**
其实“难的”“信息量大”说的都是一个意思。因为深度学习输出的是属于某一类的概率(0~1),一个很直观的方法就是使用熵 (entropy) 来刻画信息量,把那些预测值模棱两可的样本挑出来,特别地对于二分类问题就是与测试越接近 0.5,它们的信息量越大。另一种方法是使用多样性 (diversity) 来刻画 labeled data 与 unlabelled data 之间的相似程度,相似程度低的就是难的样本。
这里简单总结一下选择 hard sample 的两个指标(论文中也是用的这两个,当然还有其他的一些指标)
- 熵 (entropy) —- 度量信息量,信息量大的应当被挑选出来作为 hard sample
- 多样性 (diversity) —- 刻画 labeled data 与 unlabelled data 之间的相似程度,相似程度越低样本越 hard
上面两个指标是 Active Learning 中十分重要的选择指标,也都是在“Active batch selection via convex relaxations with guaranteed solution bounds”中被提出的。
1.3 基于主动学习的分类器训练过程
主动学习的整体示意图如下: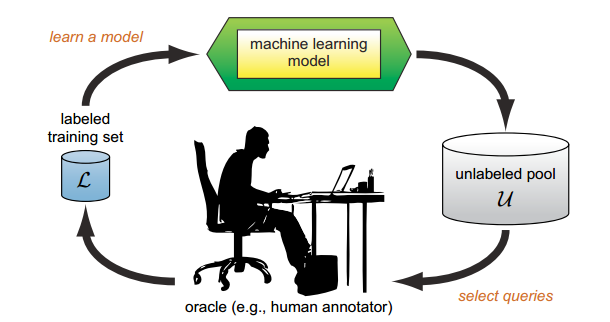
图1.2 主动学习整体流程图
- 选取合适的分类器(网络模型)记为 current_model 、主动选择策略、数据划分为 train_sample(带标注的样本,用于训练模型)、validation_sample(带标注的样本,用于验证当前模型的性能)、active_sample(未标注的数据集,对应于 ublabeled pool);
- 初始化:随机初始化或者通过迁移学习(source domain)初始化;如果有 target domain 的标注样本,就通过这些标注样本对模型进行训练;
- 使用当前模型 current_model 对 active_sample 中的样本进行逐一预测(预测不需要标签),得到每个样本的预测结果。此时可以选择 Uncertainty Strategy 衡量样本的标注价值,预测结果越接近 0.5 的样本表示当前模型对于该样本具有较高的不确定性,即样本需要进行标注的价值越高。当然了,评价样本价值的标准不止这一点,在整个训练过程中加入人工干预的步骤,也不局限于挑出价值高的样本(比如现在有在 dropout 层加入人工干预的论文);
- 专家对选择的样本进行标注,并将标注后的样本放至 train_sapmle 目录下;
- 使用当前所有标注样本 train_sample 对当前模型 current_model 进行 fine-tuning,更新 current_model;
- 使用 current_model 对 validation_sample 进行验证,如果当前模型的性能得到目标或者已不能再继续标注新的样本(没有专家或者没有钱),则结束迭代过程。否则,循环执行步骤 1 - 6。
从上面的描述中可以看出,Active Learning 不是一种全新的学习方式,而是帮助改善机器学习 | 深度学习模型综合性能的一种手段。**它被用作训练分类器的一个环节,着手点是改造训练集以提高训练效率**。在论文中针对医学图像分类领域使用主动学习来训练分类器,给出了一个训练过程示例:
- 首先,把所有的未标注图片数据在大量自然图像中训练的网络。大家知道现在有很多常用的网络,从最初的 LeNet、AlexNet、GoogLeNet、VGG、ResNet 这样的网络中去测试一遍,得到预测值。 然后挑出来那些最难的、信息量大的样本去标注
- 用这些刚刚标注了的样本去训练深度学习网络,得到一个网络 N
- 把剩下没有标签的图像(当作测试集)用 N 过一遍,得到预测值,挑一遍那些最难的,用人工去给它标注
- 把刚刚标注了的样本和原来已经标好的样本一起,也就是整个标注集拿来继续训练这个网络
- 重复 3 到 4 这个步骤,直到 [?]。
用一张图来表示上述训练的过程: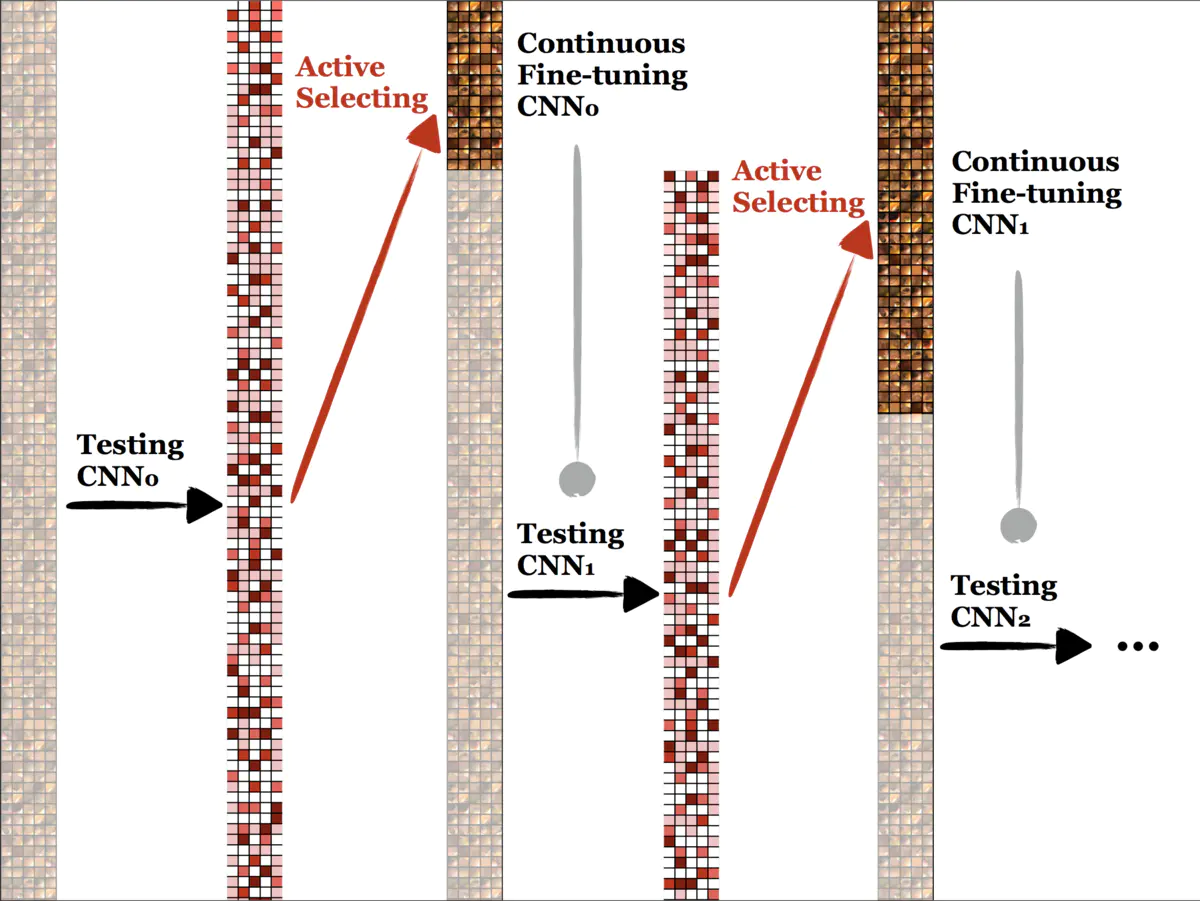
图1.3 主动学习训练过程示例
暗的表示 unlabeled 的数据,高亮的表示 labeled 的数据,CNN 的结构可以随便挑,CNN 是拍 retrained from ImageNet,得到的第二列表示每个image对应的 importance 指标,越红的说明 entropy 越大,或者diversity 越大,每次挑这些 important 的 sample 给专家标注,这样 labeled 的数据就变多了,用 labeled 的数据训练 CNN,得到新的更强的分类器了,再在 unlabelled data 上测试,挑出 entropy/diversity 大的样本,交给专家去标注,如此循环…
这里有一点是我们容易忽略的:上面也说了,主动学习是帮助改善模型性能的一个环节,而不是让你自己“设计一个主动学习的模型”。所以论文中做医学图像分类的整体思路是:将已有识别**自然图像性能突出的模型,通过主动学习的方法迁移**过来,用作医学图像分类。这其实是主动学习 + 迁移学习 (Transfer Learning) 的结合。简单而言,迁移学习就是将(在其他领域)已有成熟的性能优越的模型改吧改吧拿来做别的 tasks。
还有图1.2 中的 “Fine-tune (微调)“, 也是在训练过程中(尤其是迁移学习)优化训练效率与模型性能的方法,参考链接有两:
1.4 训练结束的条件
上面使用主动学习的训练过程中第 5 步,训练终止条件是画了问号的。论文作者在博客中给出了三个终止条件:
- 钱用光了
- 当前分类器对选出来的 hard samples 分类正确(或正确率足够高)
- 选出来的 hard samples 人类也无法标记
以上三种情况都可以让这个循环训练过程中断,第一种就很无奈了,没钱找人标记了…第二种情况和第三种情况的前提共识是如果难的样本都分类正确了,那么我们认为简单的样本肯定也基本上分类正确了,即便不知道标签。第三种情况,举例来说就是黑白图像分类,结果分类器模棱两可的图像是灰的…也就是说事实上的确分不了,并且当前的分类器居然能把分不了的样本也找出来,这时我们认为这个分类器的性能已经不错的了,所以循环训练结束。
至此,主动学习的基本思想就到位了。
2 深入论文,深耕细节
为了节省时间,直接找到了论文的中文翻译版来看,这也是来自于第 0 节开头提到的那位 CSDN 博主的专栏,同时文章中还有博主自己的一些思考,非常精华。本章节也是结合多篇文章总结论文中的细节,加上一点点个人的思考写(copy)出来的。
2.1 半监督学习 vs. 主动学习
这里直接引用一篇博客中的论述:半监督学习和主动学习都是从未标记样例中挑选部分价值量高的样例标注后补充到已标记样例集中来提高分类器精度,降低领域专家的工作量,但二者的学习方式不同:半监督学习一般不需要人工参与,是通过具有一定分类精度的基准分类器实现对未标注样例的自动标注;而主动学习有别于半监督学习的特点之一就是需要将挑选出的高价值样例进行人工准确标注。半监督学习通过用计算机进行自动或半自动标注代替人工标注,虽然有效降低了标注代价,但其标注结果依赖于用部分已标注样例训练出的基准分类器的分类精度,因此并不能保证标注结果完全正确。相比而言,主动学习挑选样例后是人工标注,不会引入错误类标。
2.2 数据扩充背锅 & diversity 的实际应用
根据论文作者在解读论文的文章中的描述:Diversity 是计算 labeled data 和 unlabeled data 之间的相似度,把和 labeled data 比较相似的作为简单样本,每次 active select 难样本,也就是挑出来和 labeled data 不太像的出来。体现在矩阵上就是行是 labeled data ,列是 unlabeled data ,在它们组成的大矩阵中找出最优的子矩阵。这个方法在理论上是可行的,但是实际应用中,数据量( labeled 和 unlabeled )会非常大,这个矩阵会特别的大,导致求最优解会很慢,或者根本得不出来最优解。因此,我们并不在image-level 上算 diversity。
由于标记的医学影像训练数据量和自然图像的没法比,数据扩充 ( Data Augmentation ) 是必须的环节,我们就抓住了这个点来设计 Diversity 这个指标。这里的假设是:经过 data augmentation 后的 patches,从 CNN 出来的预测值应该相对是一致的,因为它们的 truth 应该还是一致的。比如一张猫的图像,经过数据扩充,得到的那些个 patch 所对应的 truth 也应该都是猫。
这里解释两个概念:
- 数据扩充 ( Data Augmentation ):通过对已有数据进行变换等操作,从而扩充训练集的规模
- 比如在 image processing 领域,可以对图像进行平移、旋转、缩放、形变、加入噪声等等
- patches:在 data augmentation 中,由一个原始训练数据(常被称为 candidate)派生(扩展,augment)出来的全部数据(包括原来的数据)
- 比如由一张图像经过平移,得到 8 张 augmented data, 那么这九张图像就是 patches
这篇论文就是在 data augmentation 的基础上提出了计算 diversity 的方法:对于来自同一幅图像的 patch 集,如果它们的分类结果高度不统一了,那么这幅图像应为 hard sample.
从 diversity 的角度来讲,data augmentation 也增加了数据的多样性,但这里需要展开解释两点:
- 由于在 annotation 之前不知道 label,所以我们不能知道网络的预测正确还是错误,但是我们可以知道预测统一还是不统一。所以比如一幅猫的图,如果网络的预测很统一都是狗,那么我们也认为这是一个easy sample,不去 active select 它;
- 结合 data augmentation 的优点是我们可以知道哪些 patch 对应什么 image,比较容易控制。这样就可以在一个 image 內算 diversity 了,每个 image 的 patches 对应一个矩阵(上面提到的 diversity 矩阵),大小是一样的,非常的简洁,也容易控制计算量。
简单而言就是,对一个 image 进行 data augmentation 得到的 patches,看这些 patch 预测结果是否统一,如果不统一则认为这个 image 的 diversity 比较强,将其作为 hard sample。 同时我们可以只对 hard sample 进行 data augmentation,得到的 patches 直接放入训练集;而那些经过 data augmentation 被认定为 easy sample 的,也就没有做扩充的必要了。
但这种计算 diversity 的方式也存在局限,主要是 data augmentation 的锅:一幅图像经过平移、旋转、缩放等处理后,得到的 patch 可能是无法分类的,比如下面对猫的分类实例:
图2.1 Data Augmentation 过程中出现的问题举例
可以看到,上图中对于最左侧 candidate,网络预测的一致性很低(不统一),导致计算出来的 diversity 值很大,在我们前面的模型中应该被当作 hard sample 挑选出来。但仔细观察一下,即使是一个好的分类器(甚至是人)来识别中间图中的 1、2、3,也很难说这是个猫还是个啥。像这样的样本,是由于我们进行随机数据扩充 (Random Data Augmentation) 带来的,被称为 noisy labels。
论文给出的解决办法是少数服从多数:先想办法找到 patches 中的大多数 majority(图2.1 中就是 4~6),然后在 majority 上面计算 diversity —— 只要网络预测的大方向是统一的,那么我们认为就是统一的。放在图2.1 上说就是,想办法先将 1~3 这三个非主流撇了,抓住代表大多数的 4~6 —— 我们不希望这种图被当作 hard sample,因为当前的分类器实际上已经可以对这幅图进行正确的分类了。
针对图2.1 所示,经过改进的 diversity 算法,论文也给了个示例:我们计算它们的平均值,如果大于 0.5,大方向就是 label 1,反之大方向是 label 0,如果是前者,那么就从大到小取前 25% 的预测,其他的不要啦;如果是后者,就从小到大取前 25%,其他的不要啦。这样 Fig.4 就只剩下三个 0.9,它们的diversity 就非常小,也就不会被当作 hard sample 挑出来啦。成功解决了 data augmentation 带来的 noisy label issue。
2.3 Continuous Fine-tuning
在该论文之前尝试使用迁移学习 + 主动学习的模型中,使用的 fine-tune 都是 from scratch 的(从零开始的),即随着 labeled data 集不断变大,在每一轮迭代中被训练的 CNN 都是其他模型直接迁移过来的;而 Continuous Fine-tuning 是在上一轮迭代 fine-tuned 模型基础上再次进行 fine-tune 的。
前者的缺点是随着 labeled data 不断变多,对 GPU 的消耗很大,相当于每次都把上一轮经过 fine-tune 的 model 扔了不管了,在实际应用中的代价也很大;而 Continuous fine-tune 是基于一个事实的 —— 知识是有记忆的,毕竟人的学习就是一种连续渐进式的学习。
比如你给一个没见过猫的人(这里只是举例,不要较真hahaha)10 张含有猫的图片,他以后就可以很准确地识别出猫来,这其中一个很重要的原因是,他通过多年积累的经验(先验知识)已经能够轻易的认出狗、兔子、水瓶等其他东西(已经学习到了其他物体的特征),再看到猫的时候就可以根据已有知识进行判断。
但是 Continuous fine-tune 的问题是参数不好控制,比如 learning rate,需要适当的减小,而且比较容易再一开始调入 local minimum,这是因为一开始的标注数据不是很多。这种思路跟 sequential learning 以及 onling learning 是类似的。
2.4 模型整体算法

图2.2 模型整体算法
1.3 节提到的训练过程就是该算法的一个实例,可以对照着看。
从论文中给出来的结果看,使用主动学习策略一般使用传统学习方法一般的标注数据集,达到与之差不多甚至更高的分类效果。
3 总结
3.1 论文总结
该论文中的亮点,直接搬人家文章中的段落了:
- 从标注数据来说,从一个完全未标注的数据集开始,刚开始的时候不需要标注数据,最终以比较少量的数据达到很好的效果;选择样本的时候,是通过候选样本的一致性,选择有哪些样本是值得标注的;
- 然后,从 sequntial fine-tune 的方式,而不是重新训练;
- 自动处理噪音,就是刚才举的猫的那个例子,数据增强的时候带来的噪音,通过少数服从多数的方式把那些噪音去掉了;
- 在每个候选集只选少量的 patches 计算熵和 KL 距离,KL 距离就是描述 diversity 的指标,这样减少了计算量。传统的深度学习的时候会需要在训练之前就做数据增强,每个样本都是同等的;这篇文章里面有一些数据增强不仅没有起到好的作用,反而带来了噪音,就需要做一些处理;而且还有一些数据根本不需要增强,这样就减少了噪音,而且节省了计算
3.2 关于主动学习
主动学习的目的是使用较少的标注训练集,达到较好的训练效果。受限于看的文章还比较少,现在只基于这篇论文来总结一下应用主动学习的一般步骤:
- 选择一个该领域比较成熟的模型 N,用来做迁移学习;并准备一些未标记数据集;
- 将未标记数据集 UD 扔到 N 里面进行预测,根据 entropy, diversity 等指标选出一些 hard sample 放到 fine-tune dataset FD 中,并从 UD 中剔除;
- 将 FD 喂给 N 进行学习;
- 使用 UD 中的数据对 N 的分类准确性进行测试,如果性能已经足够好,就停止训练;否则回到第 2 步
上面的步骤中涉及到一些需要精心设计或调试的参数:第 2 步中每次选出来的 hard sample 的数量、模型的 learning rate 等等。
同时对于 NLP 领域,论文中计算 diversity 的方法是否适用于 NLP 中的 data augmentation 还得好好验证一番;目前 NLP 中做 RC 关系抽取的模型也大多是针对某一特殊应用场景的,泛化能力比较弱,能否找到用于当前我这个项目的拿来迁移的模型,也是个问题。
最后放个从论文作者的博文中摘的一段,就算是以后搞事情的指导思想了!
The way to create something beautiful is often to make subtle tweaks to something that already exists, or to combine existing ideas in a slightly new way. — “Hackers & Painters”
Reference
[1] 论文作者对论文解读的博文
[2] CSDN Active Learning 专栏文章 —- Active Learning 综述
[3] CSDN Active Learning 专栏文章 —- 论文翻译
[4] 微信推文 刘凯博士对论文的解读

若有收获,就点个赞吧
0 人点赞
