rehash 的触发时机和渐进式执行机制
Redis 什么时候做 rehash
Redis 会使用装载因子(load factor)来判断是否需要做 rehash。
装载因子的计算方式是:哈希表中所有 entry 的个数 除以 哈希表的哈希桶个数。
Redis 会根据装载因子的两种情况,来触发 rehash 操作:
- 装载因子 ≥ 1,同时,哈希表被允许进行 rehash
- 装载因子 ≥ 5
在第一种情况下,如果装载因子 = 1,同时我们假设,所有键值对是平均分布在哈希表的各个桶中的,
此时,哈希表可以不用链式哈希,因为一个哈希桶正好保存了一个键值对。
但是,如果此时再有新的数据写入,哈希表就要使用链式哈希了,这会对查询性能产生影响。
在进行 RDB 生成和 AOF 重写时,哈希表的 rehash 是被禁止的,这是为了避免对 RDB 和 AOF 重写造成影响。
如果,此时 Redis 没有在生成 RDB 和重写 AOF,那么,就可以进行 rehash。
否则的话,再有数据写入时,哈希表就要开始使用查询较慢的链式哈希了。
在第二种情况下,也就是装载因子 ≥ 5 时,就表明当前保存的数据量已经远大于哈希桶的个数,
哈希桶里会有大量的链式哈希存在,性能会受到严重影响,此时,就立马开始做 rehash。
上面说的是触发 rehash 的情况,
如果装载因子 < 1,或者装载因子 > 1 但 < 5,同时哈希表暂时不被允许进行 rehash(例如,实例正在生成 RDB 或者重写 AOF),此时,哈希表是不会进行 rehash 操作的。
采用渐进式 hash ,如果实例暂时没有收到新请求,是否做 rehash
采用渐进式 hash 时,如果实例暂时没有收到新请求,是不是就不做 rehash 了?
其实不是的。
Redis 会执行定时任务,定时任务中就包含了 rehash 操作。
定时任务,就是按照一定频率(例如每 100ms/ 次)执行的任务。
在 rehash 被触发后,即使没有收到新请求,Redis 也会定时执行一次 rehash 操作,
而且,每次执行时长不会超过 1ms,以免对其他任务造成影响。
主线程、子进程和后台线程的联系与区别
我在课程中提到了主线程、主进程、子进程、子线程和后台线程这几个词,
有些同学可能会有疑惑,我再帮你总结下它们的区别。
首先,我来解释一下进程和线程的区别。
从操作系统的角度来看,进程一般是指资源分配单元,例如一个进程拥有自己的堆、栈、虚拟内存空间(页表)、文件描述符等;而线程一般是指 CPU 进行调度和执行的实体。
了解了进程和线程的区别后,我们再来看下什么是主进程和主线程。
如果一个进程启动后,没有再创建额外的线程,这样的进程一般称为主进程或主线程。
Redis 启动后,本身就是一个进程,它会接收客户端发送的请求,并处理读写操作请求。
而且,接收请求和处理请求操作是 Redis 的主要工作,Redis 没有再依赖于其他线程,
所以,我一般把完成这个主要工作的 Redis 进程,称为主进程或主线程。
在主线程中,我们还可以使用 fork 创建子进程,或是使用 pthread_create 创建线程。
下面我先介绍下 Redis 中用 fork 创建的子进程有哪些。
- 创建 RDB 的后台子进程,同时由它负责在主从同步时传输 RDB 给从库
- 通过无盘复制方式传输 RDB 的子进程
- bgrewriteaof 子进程。(AOF 重写)
我们再看下 Redis 使用的线程。
从 4.0 版本开始,Redis 也开始使用 pthread_create 创建线程,
这些线程在创建后,一般会自行执行一些任务,例如执行异步删除任务。
相对于完成主要工作的主线程来说,我们一般可以称这些线程为后台线程。
关于 Redis 后台线程的具体执行机制,我会在第 16 讲具体介绍。
写时复制的底层实现机制
Redis 在使用 RDB 方式进行持久化时,会用到操作系统的写时复制技术。
我在第 5 节课讲写时复制的时候,
着重介绍了写时复制的效果:bgsave 子进程相当于复制了原始数据,而主线程仍然可以修改原来的数据。
今天,我再具体讲一讲写时复制的底层实现机制。
对 Redis 来说,主线程 fork 出 bgsave 子进程后,bgsave 子进程实际是复制了主线程的页表。
这些页表中,就保存了在执行 bgsave 命令时,主线程的所有数据块在内存中的物理地址。
这样一来,bgsave 子进程生成 RDB 时,就可以根据页表读取这些数据,再写入磁盘中。
如果此时,主线程接收到了新写或修改操作,那么,主线程会使用写时复制机制。
具体来说,写时复制就是指,主线程在有写操作时,才会把这个新写或修改后的数据写入到一个新的物理地址中,并修改自己的页表映射。
bgsave 子进程复制主线程的页表以后,假如主线程需要修改虚页 7 里的数据,
那么,主线程就需要新分配一个物理页(假设是物理页 53),
然后把修改后的虚页 7 里的数据写到物理页 53 上,而虚页 7 里原来的数据仍然保存在物理页 33 上。
这个时候,虚页 7 到物理页 33 的映射关系,仍然保留在 bgsave 子进程中。
所以,bgsave 子进程可以无误地把虚页 7 的原始数据写入 RDB 文件。
replication buffer 和 repl_backlog_buffer 的区别
在进行主从复制时,Redis 会使用 replication buffer 和 repl_backlog_buffer,
有些同学可能不太清楚它们的区别,我再解释下。
总的来说,
replication buffer 是主从库在进行全量复制时,主库用于保证主从库的数据一致性,
主库会在内存中用专门的 replication buffer,记录 RDB 文件生成后收到的所有写操作。
而 repl_backlog_buffer 是为了支持从库增量复制,主库上用于持续保存写操作的一块专用 buffer。
Redis 主从库在进行复制时,当主库要把全量复制期间的写操作命令发给从库时,
主库会先创建一个客户端,用来连接从库,然后通过这个客户端,把写操作命令发给从库。
在内存中,主库上的客户端就会对应一个 buffer,这个 buffer 就被称为 replication buffer。
Redis 通过 client_buffer 配置项来控制这个 buffer 的大小。
主库会给每个从库建立一个客户端,所以 replication buffer 不是共享的,而是每个从库都有一个对应的客户端。
repl_backlog_buffer 是一块专用 buffer,在 Redis 服务器启动后,开始一直接收写操作命令,
repl_backlog_buffer 是所有从库共享的。
主库和从库会各自记录自己的复制进度,所以,不同的从库在进行恢复时,会把自己的复制进度(slave_repl_offset)发给主库,主库就可以和它独立同步。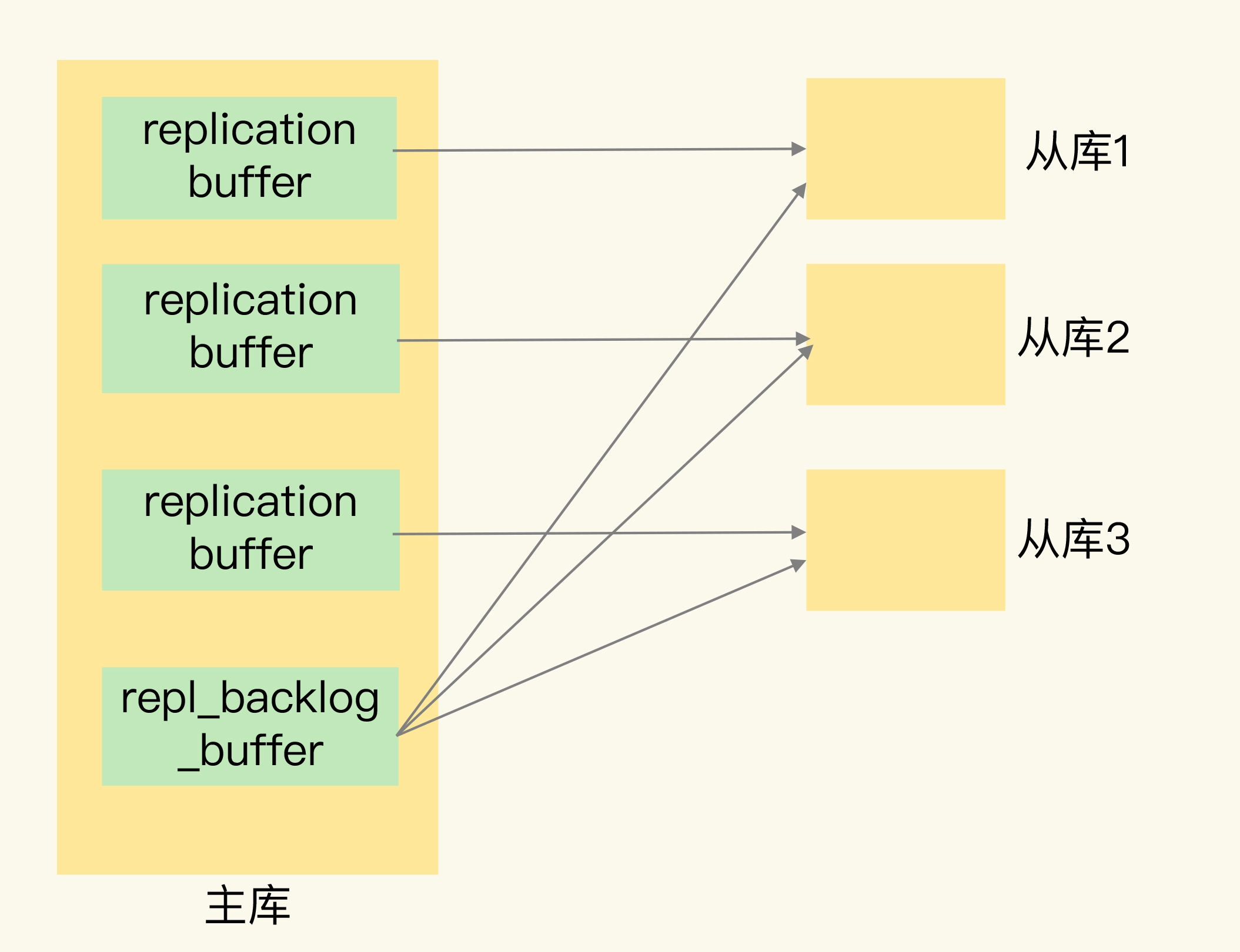

若有收获,就点个赞吧
0 人点赞
