Redis 中,String 类型如何保存数据
当保存的数据是 64 位有符号整数时,String 类型会把它保存为一个 8 字节的 Long 类型整数,这种保存方式通常也叫作 int 编码方式。
但是,当保存的数据中包含字符时,String 类型就会用简单动态字符串(Simple Dynamic String,SDS)结构体来保存。
String 类型的优劣局限
String 类型并不适用于所有场景,它有一个明显的短板是:它保存数据时所消耗的内存空间较多。
当 Redis 实例的内存空间消耗比较大时,就会产生如下问题:
- 成本增加:内存不够了,要花钱加内存
- 影响 Redis 的性能:大内存 Redis 实例影响生成内存快照 RDB 的时间消耗,从而导致响应变慢
dictEntry 和 redisObject
Redis 使用一个全局哈希表保存所有的键值对,哈希表的每一项是一个 dictEntry 的结构体,用来指向一个键值对。
dictEntry 结构体中有三个 8 字节的指针,分别指向 key、value 以及下一个 dictEntry,三个指针共 24 字节,如下图所示:
这三个指针只有 24 字节,但是会占用了 32 字节。这是因为 Redis 使用的内存分配库是 jemalloc。jemalloc 在分配内存时,会根据我们申请的字节数 N,找一个比 N 大,并且最接近 N 的 2 的幂次数作为分配的空间,这样可以减少频繁分配的次数。
所以说一个 dictEntry 结构占用固定的 32 字节。
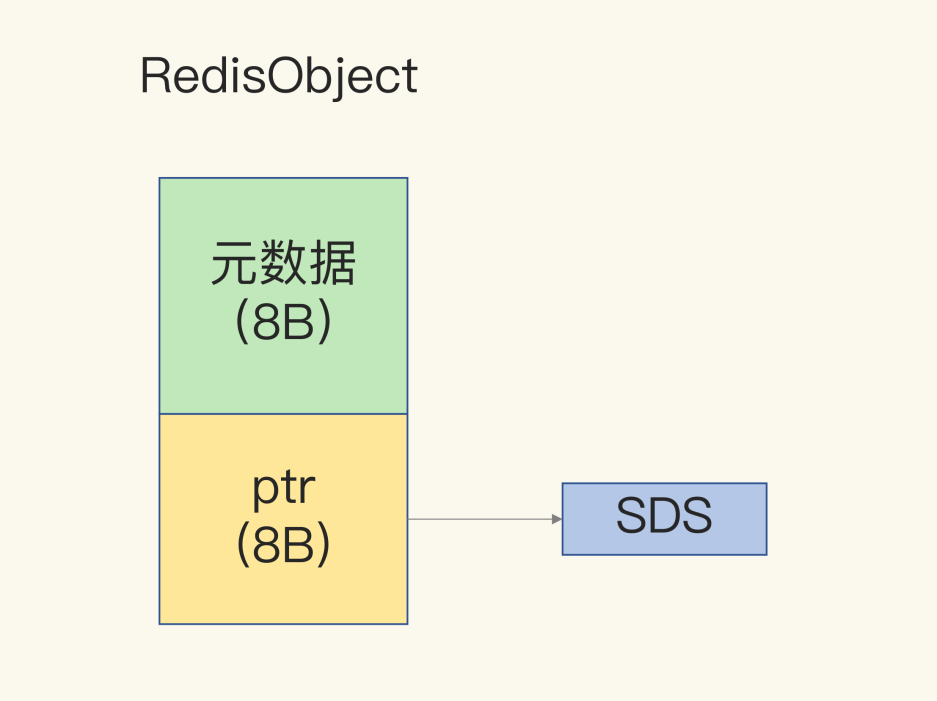
dictEntry 结构体中 key、value 指针指向的数据类型是 redisObject。
Redis 用 redisObject 结构体来记录一些元数据(比如),同时指向实际的数据(比如 SDS、zipList等)。
一个 redisObject 包含了 8 字节的元数据和一个 8 字节指针
- 元数据,比如编码方式(int 编码、embstr 编码、raw 编码)、最后一次访问的时间、被引用的次数等
- 指针指向具体数据类型的数据(例如指向 String 类型的 SDS 结构体所在的内存地址)
typedef struct dictEntry{// 键void *key;// 值union {void *val;uint64_tu64;int64_ts64;}v;// 指向下一个 entry 的指针struct dictEntry *next;} dictEntry;
struct redisObject {unsigned type:4;unsigned encoding:4;unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or* LFU data (least significant 8 bits frequency* and most significant 16 bits access time). */int refcount;void *ptr;};
SDS 结构体
Redis 使用字符数组来保存实际的字符串数据。
SDS 本质还是字符数组(char*),只是在字符数组基础上增加了额外的元数据。
SDS 结构体的属性有:
- len:字符数组的现有长度
- alloc:分配给字符数组的空间长度
- flags:SDS 结构体的类型
- buf[]:字符数据,用于保存实际的字符串数据
Redis 定义了多种类型的 SDS 结构体,并用 flags 属性来标识 SDS 的类型。
SDS 一共设计了 5 种类型,分别是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64,其中,sdshdr5 这一类型 Redis 已经不再使用了。
这 5 种类型的主要区别就在于,SDS 结构体中的字符数组的现有长度 len 和分配给字符数组的空间长度 alloc,这两个元数据的数据类型不同。
- sdshdr8 结构体的 len 和 alloc 属性的数据类型是 uint8_t
- sdshdr16 结构体的 len 和 alloc 属性的数据类型是 uint16_t
uint8_t 是 8 位无符号整型,会占用 1 字节的内存空间。当字符串类型是 sdshdr8 时,它能表示的字符数组的长度(包括数组最后一位\0)不会超过 256 字节(2 的 8 次方等于 256)。
而对于 sdshdr16、sdshdr32、sdshdr64 三种类型来说,它们的 len 和 alloc 数据类型分别是 uint16_t、uint32_t、uint64_t,即它们能表示的字符数组长度,分别不超过 2 的 16 次方、32 次方和 64 次方。分别占用 2 字节、4 字节和 8 字节 的内存空间。
实际上,SDS 之所以设计不同的类型,是为了能灵活的保存不同长度的字符串,从而有效节省内存空间。
typedef char *sds;/* Note: sdshdr5 is never used, we just access the flags byte directly.* However is here to document the layout of type 5 SDS strings. */struct __attribute__ ((__packed__)) sdshdr5 {unsigned char flags; /* 3 lsb of type, and 5 msb of string length */char buf[];};struct __attribute__ ((__packed__)) sdshdr8 {uint8_t len; /* used */uint8_t alloc; /* excluding the header and null terminator */unsigned char flags; /* 3 lsb of type, 5 unused bits */char buf[];};struct __attribute__ ((__packed__)) sdshdr16 {uint16_t len; /* used */uint16_t alloc; /* excluding the header and null terminator */unsigned char flags; /* 3 lsb of type, 5 unused bits */char buf[];};struct __attribute__ ((__packed__)) sdshdr32 {uint32_t len; /* used */uint32_t alloc; /* excluding the header and null terminator */unsigned char flags; /* 3 lsb of type, 5 unused bits */char buf[];};struct __attribute__ ((__packed__)) sdshdr64 {uint64_t len; /* used */uint64_t alloc; /* excluding the header and null terminator */unsigned char flags; /* 3 lsb of type, 5 unused bits */char buf[];};
int、embstr 和 raw 三种编码方式
我们上面提到 redisObject 结构体中用 type 存储了编码方式。我们下面介绍一些这三种编码方式。
为了节省内存空间,Redis 还对 Long 类型整数和 SDS 的内存布局做了专门的设计。
上面我们提到:当保存的数据是 64 位有符号整数时,String 类型会把它保存为一个 8 字节的 Long 类型整数,这种保存方式通常也叫作 int 编码方式。
并且如果保存的是 Long 类型整数时,redisObject 中的指针就直接赋值为整数数据了,这样就不用额外的指针再指向整数了,节省了指针的空间开销。
当保存的是字符串数据,并且字符串小于等于 44 字节时,redisObject 中的元数据、指针和 SDS 是一块连续的内存区域,这样就可以避免内存碎片。这种布局方式被称为 embstr 编码方式。
当然,当字符串大于 44 字节时,SDS 的数据量就开始变多了,Redis 就不再把 SDS 和 redisObject 布局在一起了,而是会给 SDS 分配独立的空间,并用指针指向 SDS 结构。这种布局方式被称为 raw 编码方式。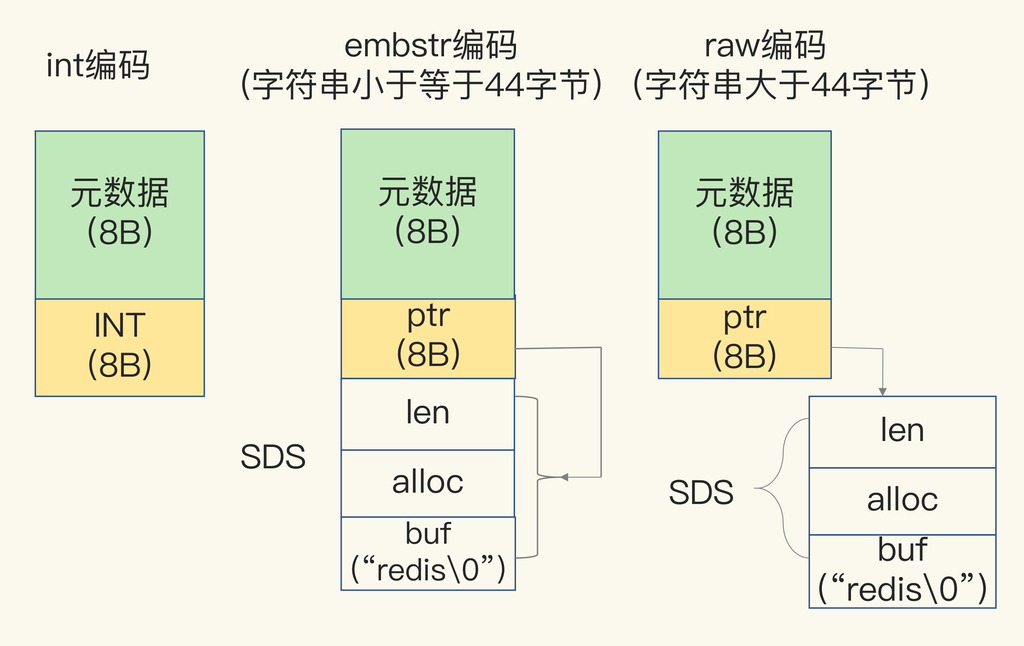
为什么要封装 char*,提供 SDS 结构体呢
原因一:不能实现保存任意二进制数据的需求
char* 字符串以“\0”表示字符串的结束,给保存数据带来一定的负面影响。如果我们要保存的数据中,本身就有“\0”,那么数据在“\0”处就会被截断,这就不能实现保存任意二进制数据的需求了
原因二:char* 相关的操作函数的时间复杂度高,影响字符串的操作效率。
参考资料

若有收获,就点个赞吧
0 人点赞
