作为键值数据库,Redis 的应用非常广泛,如果你是后端工程师,出去面试会被问到与 Redis 相关的性能问题。
比如说,为了保证数据的可靠性,Redis 需要在磁盘上读写 AOF 和 RDB,
RDB:Redis Database 默认开启,指定时间内执行指定次数写操作,将内存中的数据写入磁盘。 AOF:Append Only File 需要手动开启,完整性更高,默认每秒将写操作日志追加写入到磁盘。
但在高并发场景里,这就会直接带来两个新问题:
- 一个是写 AOF 和 RDB 会造成 Redis 性能抖动,
- 另一个是 Redis 集群数据同步和实例恢复时,读 RDB 比较慢,限制了同步和恢复速度。
那这个问题有没有好的解决方法呢?
一个可行的解决方案就是使用非易失内存 NVM (NonVolatile Memory),因为它既能保证高速的读写,又能快速持久化数据。NVM(非易失性内存)科普
NVM:当电流关掉后,所存储的数据不会消失的计算机存储器。
同样是使用 Redis,但是不同公司的“玩法”却不太一样,
比如说,有做缓存的,有做数据库的,也有用做分布式锁的。
不过,他们遇见的“坑”,总体来说集中在四个方面:
- CPU 使用上的“坑”,例如:数据结构的复杂度、跨 CPU 核的访问
- 内存使用上的“坑”,例如:主从同步和 AOF 的内存竞争
- 存储持久化上的“坑”,例如:在 SSD (Solid State Disk,固态硬盘) 上做快照的性能抖动
-
学习方法
不能只关注零散的技术点,要建立起一套完整的知识框架,系统观是至关重要的。
那么,如何高效地形成系统观呢?
我们做事情一般都希望“多快好省”,希望花很少的时间掌握更丰富的知识和经验,解决更多的问题。
听起来好像很难,但实际上,只要你能抓住主线,在脑海中绘制一幅 Redis 全景知识图,这完全是可以实现的。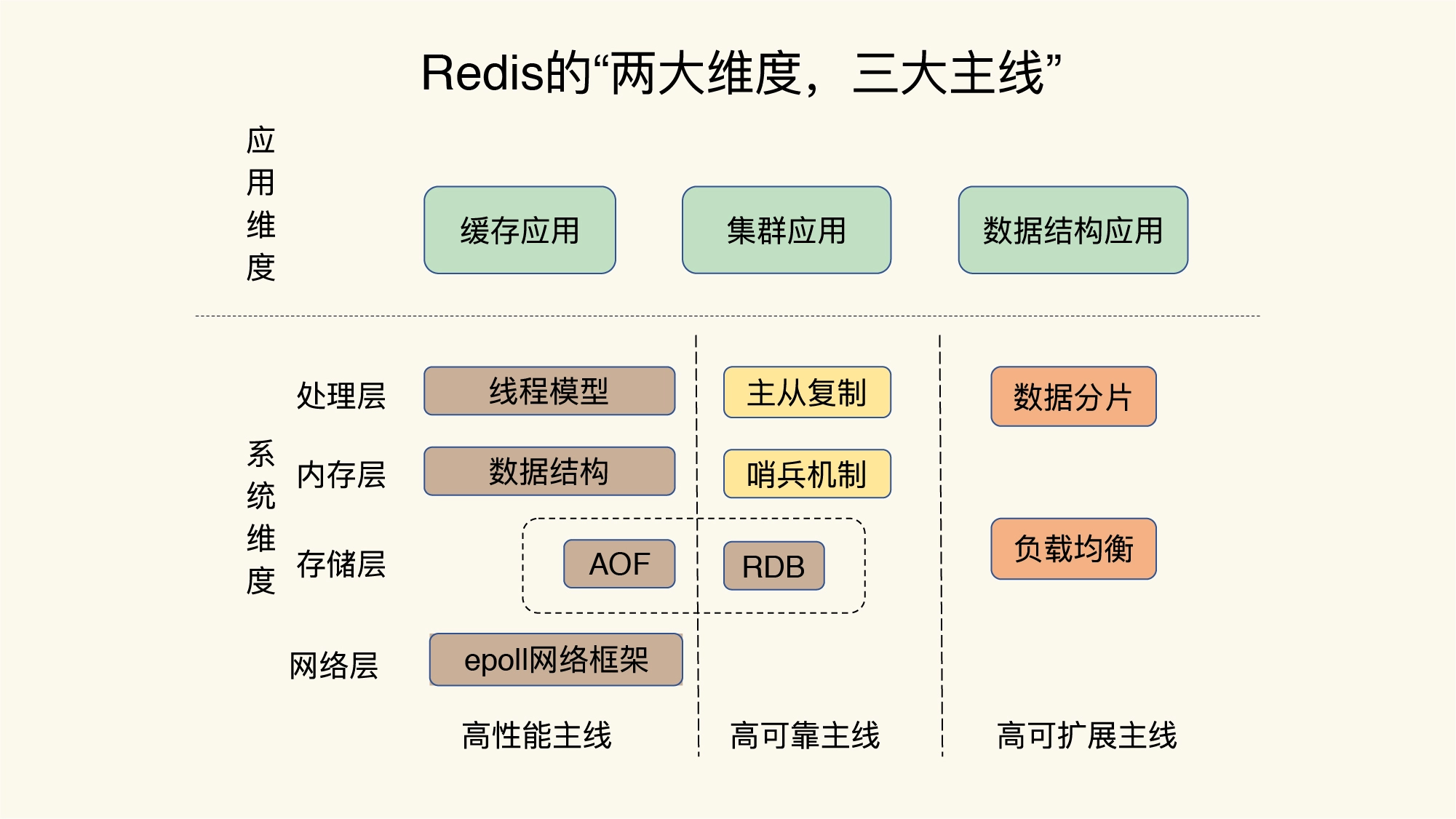
“两大维度”是指:系统维度和应用维度
- “三大主线”是指:高性能、高可靠和高可扩展(简称“三高”)
首先,从系统维度上说,你需要了解 Redis 的各项关键技术的设计原理,这些能够为你判断和推理问题打下坚实的基础,而且,你还能从中掌握一些优雅的系统设计规范,
例如:run-to-complete 模型、epoll 网络模型,这些可以应用到你后续的系统开发实践中。
这里有一个问题是,Redis 作为庞大的键值数据库,可以说遍地都是知识,一抓一大把,我们怎么能快速地知道该学哪些呢?接下来就要看“三大主线”的魔力了。
别看技术点是零碎的,其实你完全可以按照这三大主线,给它们分下类,就像图片中展示的那样,具体如下:
- 高性能主线,包括:线程模型、数据结构、持久化、网络框架
- 高可靠主线,包括:主从复制、哨兵机制
- 高可扩展主线,包括:数据分片、负载均衡
这样,就有了一个结构化的知识体系。
当你遇见这些问题时,就可以按图索骥,快速找到影响这些问题的关键因素,这是非常省时省力的
其次,在应用维度上,我建议你按照两种方式学习:“应用场景驱动”和“典型案例驱动”,一个是“面”的梳理,一个是“点”的掌握。
应用场景驱动
我们知道,缓存 和 集群是 Redis 的两大广泛的应用场景。
在这些场景中,本身就具有一条显式的技术链。
比如说,提到缓存场景,你肯定会想到缓存机制、缓存替换、缓存异常等一连串的问题。
不过,并不是所有的东西都适合采用这种方式,比如说 Redis 丰富的数据模型,就导致它有很多零碎的应用场景,很多很杂。
而且,还有一些问题隐藏得比较深,只有特定的业务场景下(比如亿级访问压力场景)才会出现,并不是普遍现象,所以,我们也比较难于梳理出结构化的体系。
典型案例驱动
这个时候,你就可以用“典型案例驱动”的方式学习了。
我们可以重点解读一些对 Redis 的“三高”特性影响较大的使用案例,例如:多家大厂在万亿级访问量和万亿级数据量的情况下对 Redis 的深度优化,解读这些优化实践,非常有助于你透彻地理解 Redis。
而且,你还可以梳理一些方法论,做成 Checklist(清单),就像是一个个锦囊,之后当你遇到问题的时候,就可以随时拿出自己的“锦囊妙计”解决问题了。
最后,我还想跟你分享一个非常好用的技巧。
我梳理了一下 Redis 各大典型问题,同时结合相关的技术点,手绘了一张 Redis 的问题画像图。
无论你遇见什么问题,都可以拿出来这张图,这样你就能快速地按照问题来查找对应的 Redis 主线模块了,然后再进一步定位到相应的技术点上。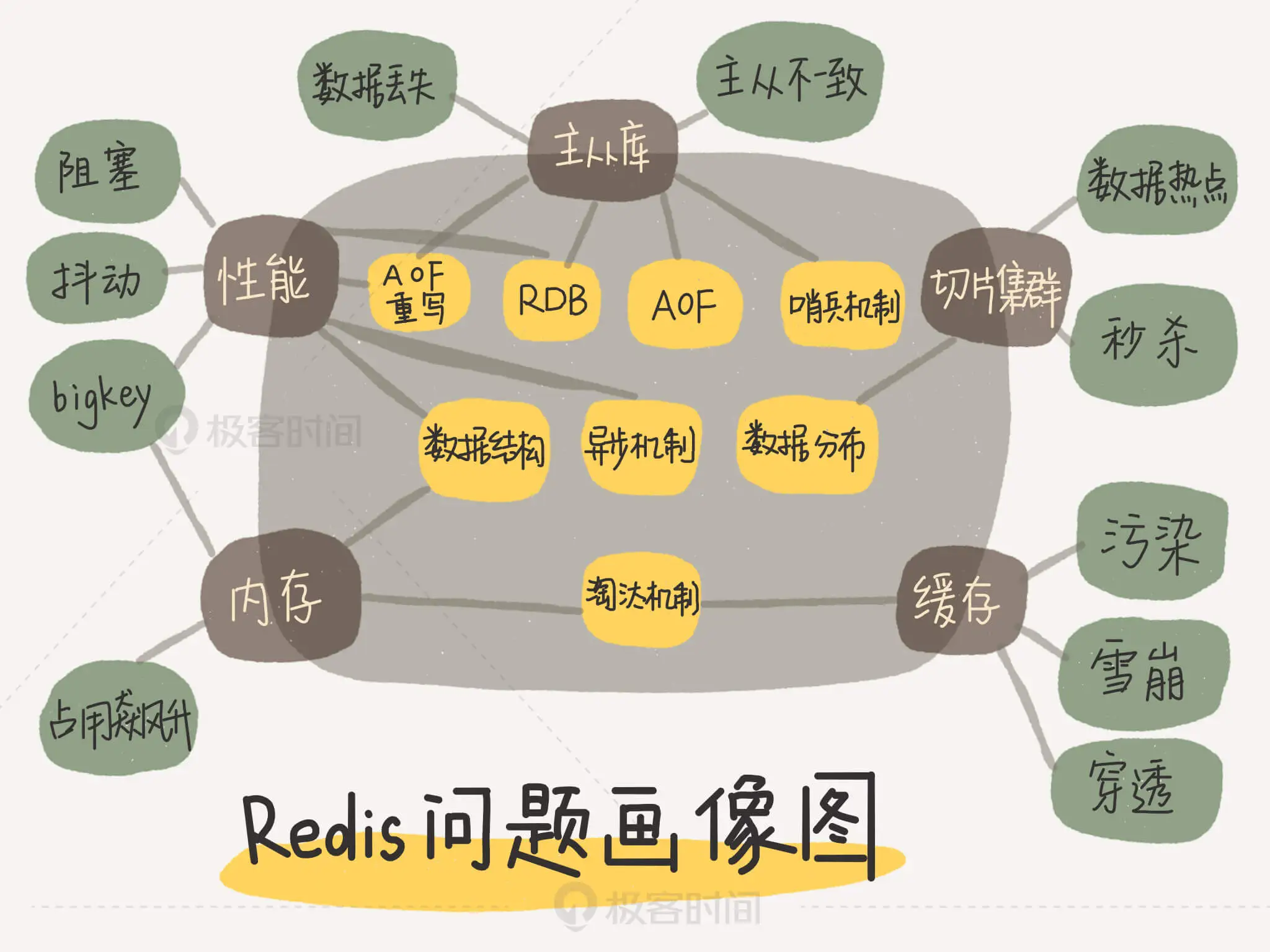
Redis 的主线模块
- 性能 主线模块
- 主从库 主线模块
- 切片集群 主线模块
- 缓存 主线模块
- 内存 主线模块
举个例子,如果你遇到了 Redis 的响应变慢问题,对照着这张图,你就可以发现,这个问题和 Redis 的性能主线相关,而性能主线又和数据结构、异步机制、RDB、AOF 重写相关。
找到了影响的因素,解决起来也就很容易了。
另外,在学习和使用的过程中,你完全可以根据你自己的方式,完善这张画像图,把你自己实践或掌握到的新知识点,按照“问题 —> 主线 —> 技术点”的方式梳理出来,放到这张图上。
这样一来,你的积累越来越多,画像也会越来越丰富。
以后在遇到问题的时候,就很容易解决了。
学习方法 总结
将系统划分为两个维度:应用维度 和 系统维度。
- 应用维度指的是:如何使用这个系统,这个系统的作用 或者 应用场景(Redis :缓存、分布式锁)
- 系统维度指的是:它的组件如何组合和相互作用。
对于应用维度,有两种学习方法:应用程序场景驱动 和 典型案例驱动。
对于系统维度,应该确保对系统有一个整体概念。
问自己一些问题,比如:
- 这个系统有多少层。
- 根据其设计指标 (比如:高性能、高可用 和 高可拓展)将系统划分为几个主线程,并使用这些主线程将应用维度、系统维度 和 具体场景联系起来。
本专栏的设计架构
基础篇:打破技术点之间的壁垒,带你建立网状知识结构
我会先从构造一个简单的键值数据库入手,带你庖丁解牛。
这有点像是建房子,只有顶梁柱确定了,房子有形了,你才能去想“怎么设计更美、更实用”的问题。
因此,在“基础篇”,我会具体讲解数据结构、线程模型、持久化等几根“顶梁柱”,让你不仅能抓住重点,还能明白它们在整体框架中的地位和作用,以及它们之间的相互联系。
明白了这些,也就打好了基础。
实践篇:场景和案例驱动,取人之长,梳理出一套属于自己的“武林秘籍”
前面说过,从应用的维度来说,在学习时,我们需要以“场景”和“案例”作为驱动。
因此,在“实践篇”,我也会从这两大层面来进行讲解。
在“案例”层面,我会介绍数据结构的合理使用、避免请求阻塞和抖动、避免内存竞争和提升内存使用效率的关键技巧。
在“场景”层面,我会重点介绍缓存和集群两大场景。
- 对于缓存而言,我会重点讲解缓存基本原理及淘汰策略,还有雪崩、穿透、污染等异常情况;
- 对于集群来说,我会围绕集群方案优化、数据一致性、高并发访问等问题,和你聊聊可行的解决方案。
未来篇:具有前瞻性,解锁新特性Redis 6.0
刚刚推出,增加了万众瞩目的多线程等新特性,因此,我会向你介绍这些新特性,以及当前业界对 Redis 的最新探索,这会让你拥有前瞻性视角,了解 Redis 的发展路线图,为未来的发展提前做好准备。
凡事预则立,这样一来,你就可以走在很多人的前面。

若有收获,就点个赞吧
0 人点赞
