Redis 是内存数据库,一旦服务器宕机,内存中的数据将全部丢失。
如果把 Redis 当作缓存使用,我们很容易想到的一个解决方案是:从后端数据库恢复这些数据,
但这种方式存在两个问题:
- 一是,需要频繁访问数据库,会给数据库带来巨大的压力
- 二是,这些数据是从慢速数据库中读取出来的,性能肯定比不上从 Redis 中读取,导致使用这些数据的应用程序响应变慢。
所以, 对 Redis 来说,实现数据的持久化,避免从后端数据库中进行恢复,是至关重要的。
目前,Redis 的持久化主要有两大机制,即 AOF 日志 和 RDB 快照。
AOF 日志是如何实现的
说到日志,我们比较熟悉的是数据库的写前日志(Write Ahead Log, WAL),
写前日志 也就是说,在实际写数据前,先把修改的数据记到日志文件中,以便故障时进行恢复。
不过,AOF 日志是写后日志,“写后”的意思是:Redis 是先执行命令,把数据写入内存,然后才记录日志。
AOF 为什么要先执行命令再记录日志呢?
要回答这个问题,我们要先知道 AOF 里记录了什么内容。
传统数据库的日志,例如:MySQL 的 Redo Log(重做日志),记录的是修改后的数据,
而 AOF 里记录的是 Redis 收到的每一条命令,这些命令是以文本形式保存的。
我们以 Redis 收到“set testkey testvalue”命令后记录的日志为例,看看 AOF 日志的内容。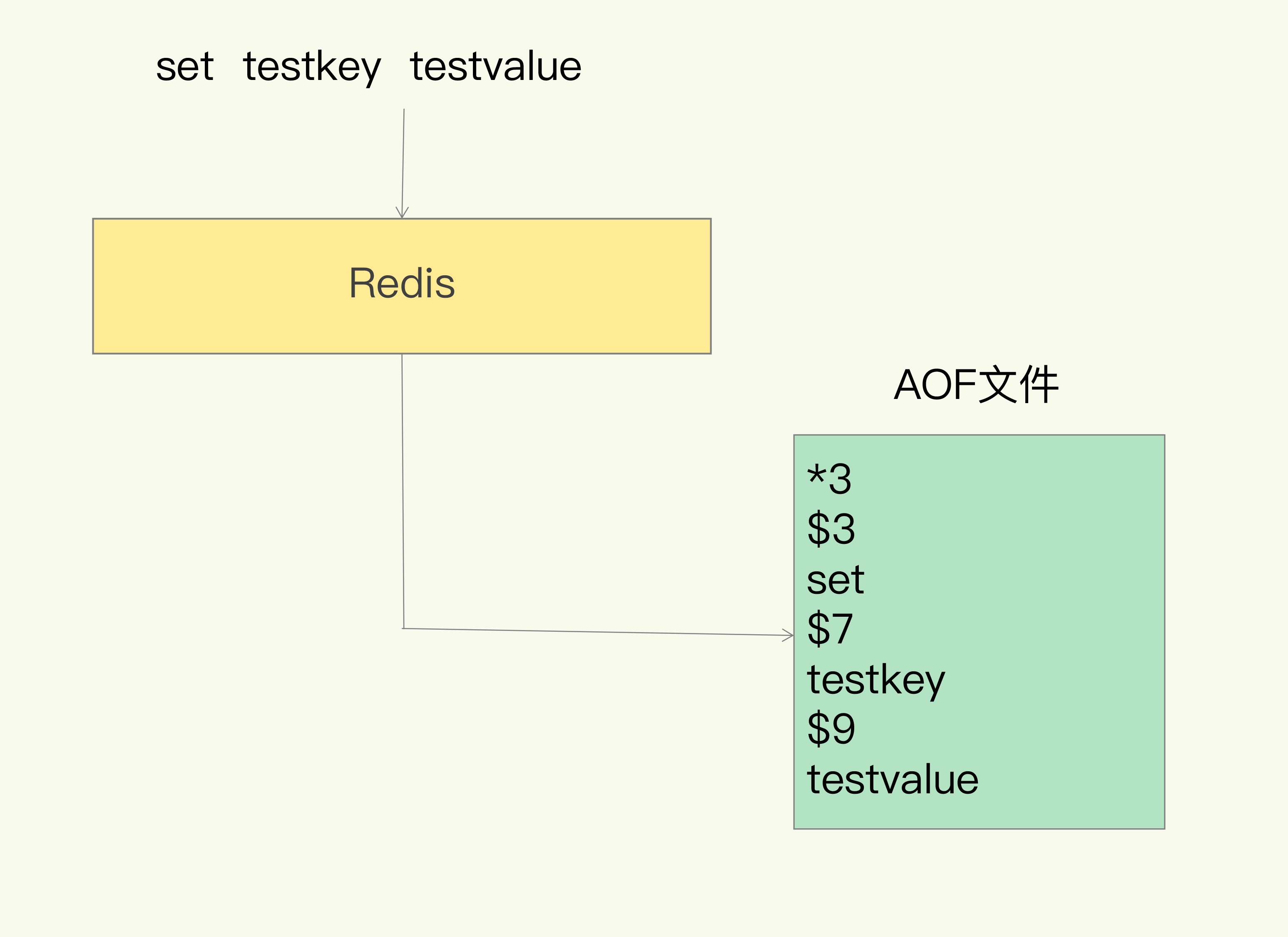
其中,“*3”表示当前命令有三个部分,每部分都是由“$+数字”开头,后面紧跟着具体的命令、键或值。
这里,“数字”表示这部分中的命令、键或值一共有多少字节。
例如,“$3 set”表示这部分有 3 个字节,也就是“set”命令。
但是,为了避免额外的检查开销,Redis 在向 AOF 里面记录日志的时候,并不会先去对这些命令进行语法检查。
所以,如果先记录日志再执行命令的话,日志中就有可能记录了错误的命令,
Redis 在使用日志恢复数据时,就可能会出错。
而写后日志这种方式,就是先让系统执行命令,只有命令能执行成功,才会被记录到日志中,
否则,系统就会直接向客户端报错。所以,Redis 使用写后日志的好处是:
- 可以避免出现记录错误命令的情况
- 减少了对命令进行语法检查的开销
- 它在命令执行后才记录日志,所以不会阻塞当前的写操作
不过,AOF 也有两个潜在的风险。
- 如果刚执行完一个命令,还没有来得及记录日志就宕机了,那么这个命令和相应的数据就有丢失的风险。
如果 Redis 是用作缓存,还可以从后端数据库重新读入数据进行恢复,但是如果 Redis 是直接用作数据库的
话,因为命令没有记录日志,所以就无法用日志进行恢复了。
- AOF 虽然避免了对当前命令的阻塞,但可能会给下一个操作带来阻塞风险。
这是因为,AOF 日志也是在主线程中执行的,如果在把日志文件写入磁盘时,磁盘写压力大,就会导致写磁
盘很慢,进而导致后续的操作无法执行。
仔细分析的话会发现,这两个风险都是和 AOF 写回磁盘的时机相关的。
这也就意味着,如果我们能够控制一个写命令执行完后,AOF 日志写回磁盘的时机,这两个风险就解除了。
三种 AOF 日志写回磁盘策略
对于这个问题,AOF 机制给我们提供了三种 AOF 日志写回磁盘策略,
也就是 AOF 配置项 appendfsync 的三个可选值。
- Always,同步写回:每个写命令执行完,立马同步地将日志写回磁盘
- Everysec,每秒写回:每个写命令执行完,只是先把日志写到 AOF 文件的内存缓冲区,每隔一秒把缓冲区中的内容写入磁盘
- No,操作系统控制的写回:每个写命令执行完,只是先把日志写到 AOF 文件的内存缓冲区,由操作系统决定 何时将缓冲区内容写回磁盘
针对避免主线程阻塞 和 减少数据丢失问题,这三种 AOF 日志写回磁盘策略都无法做到两全其美。
下面分析其中的原因。
- “同步写回”可以做到基本不丢数据,但是它在每一个写命令后都有一个慢速的写磁盘操作,不可避免地会影响主线程性能
- 虽然“操作系统控制的写回”在写完缓冲区后,就可以继续执行后续的命令,但是写磁盘的时机已经不在Redi s手中了,只要 AOF 日志没有写回磁盘,一旦宕机对应的数据就丢失了
- “每秒写回”采用一秒写回一次的频率,避免了“同步写回”的性能开销,虽然减少了对系统性能的影响,但是如果发生宕机,上一秒内未写磁盘的命令操作仍然会丢失。
所以,这只能算是,在避免影响主线程性能和避免数据丢失两者间进行折中。
三种 AOF 日志写回磁盘策略的对比
| 配置项 | 写回时机 | 优点 | 缺点 |
|---|---|---|---|
| Always | 同步写回 | 可靠性高,数据基本不丢失 | 每个写命令都进行日志写回磁盘, 对 Redis 的性能影响较大 |
| Everysec | 每秒写回 | 性能适中 | 宕机时,丢失一秒内的数据 |
| No | 操作系统控制的写回 | 性能好 | 宕机时,丢失数据较多 |
需要根据系统对高性能和高可靠性的要求,来选择使用哪种 AOF 日志写回磁盘策略。
总结一下就是:
想要获得高性能,就选择 No 策略。
想要得到高可靠性保证,就选择 Always 策略。
允许数据有一点丢失,又希望性能别受太大影响的话,那么就选择 Everysec 策略。
但是,按照系统的性能需求选定了写回策略,并不是“高枕无忧”了。
毕竟,AOF 是以文件的形式在记录接收到的所有写命令。
随着接收的写命令越来越多,AOF 文件会越来越大。
这也就意味着,我们一定要小心 AOF 文件过大带来的性能问题。
这里的“性能问题”,主要在于以下三个方面:
- 一是,文件系统本身对文件大小有限制,无法保存过大的文件
- 二是,如果文件太大,之后再往里面追加命令记录的话,效率也会变低
- 三是,如果发生宕机,AOF 中记录的命令要一个个被重新执行,用于故障恢复,
如果日志文件太大,整个恢复过程会非常缓慢,这就会影响到 Redis 的正常使用。
所以,我们要采取一定的控制手段,这个时候,AOF重写机制就登场了。
AOF 重写机制
日志文件太大了怎么办?
简单来说,AOF 重写机制就是在重写时,Redis 根据数据库的现状创建一个新的 AOF 文件,
也就是说,读取数据库中的所有键值对,然后对每一个键值对用一条命令记录它的写入。
比如说,当读取了键值对“testkey”: “testvalue”之后,AOF 重写机制会记录 set testkey testvalue这条命令。
这样,当需要恢复时,可以重新执行该命令,实现“testkey”: “testvalue”的写入。
为什么重写机制可以把日志文件变小呢?
实际上,重写机制具有“多变一”功能。
所谓的“多变一”,也就是说,旧日志文件中的多条命令,在重写后的新日志中变成了一条命令。
我们知道,AOF 文件是以追加的方式,记录接收到的写命令。
当一个键值对被多条写命令反复修改时,AOF 文件会记录相应的多条命令。
但是,在重写的时候,是根据这个键值对当前的最新状态,为它生成对应的写入命令。
这样一来,一个键值对在重写日志中只用一条命令就行了,而且,在日志恢复时,只用执行这条命令,就可以直接完成这个键值对的写入了。

当我们对一个列表先后做了 6 次修改操作后,列表的最后状态是 [“D”, “C”, “N”],
此时,只用 LPUSH u:list “N”, “C”, “D” 这一条命令就能实现该数据的恢复,这就节省了五条命令的空间。
对于被修改过成百上千次的键值对来说,重写能节省的空间就更大了。
不过,虽然 AOF 重写后,日志文件会缩小,但是,要把整个数据库的最新数据的操作日志都写回磁盘,仍然是一个非常耗时的过程。
这时,我们就要继续关注另一个问题了:重写会不会阻塞主线程?
AOF 重写会阻塞吗
和 AOF 日志由主线程写回不同,重写过程是由后台线程 bgrewriteaof 来完成的,
这是为了避免阻塞主线程,导致 Redis 性能下降。
我把重写的过程总结为“一个拷贝,两处日志”。
fork 之后父子进程的内存关系
“一个拷贝”是指,每次执行重写时,主线程 fork 出后台的 bgrewriteaof 子进程。
此时,fork 会把主线程的内存拷贝一份给 bgrewriteaof 子进程,这里面就包含了数据库的最新数据。
然后,bgrewriteaof 子进程就可以在不影响主线程的情况下,逐一把拷贝的数据写成操作,记入日志。
“两处日志”
因为主线程未阻塞,仍然可以处理新来的操作。此时,如果有写操作,
第一处日志是指:正在使用的 AOF 日志,Redis 会把这个操作写到它的缓冲区。
这样一来,即使宕机了,这个 AOF 日志的操作仍然是齐全的,可以用于恢复。
第二处日志是指:新的 AOF 重写日志。
这个操作也会被写到重写日志的缓冲区。这样,重写日志也不会丢失最新的操作。
等到拷贝数据的所有操作记录重写完成后,重写日志记录的这些最新操作也会写入新的 AOF 文件,
以保证数据库最新状态的记录。
此时,我们就可以用新的 AOF 文件替代旧 AOF 文件了。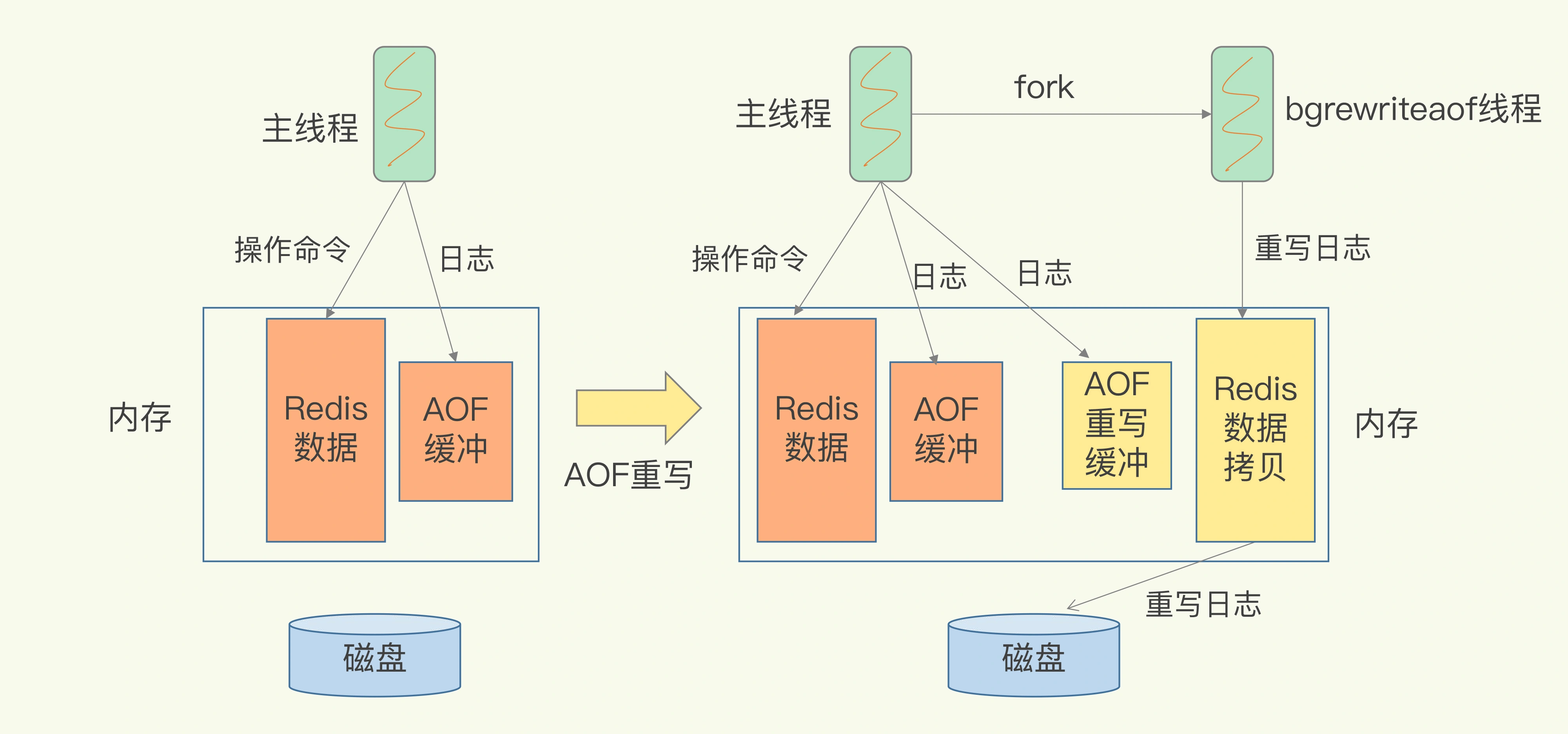
总结来说,每次 AOF 重写时,Redis 会先执行一个内存拷贝,用于重写;
然后,使用两个日志保证在重写过程中,新写入的数据不会丢失。
而且,因为 Redis 采用额外的线程进行数据重写,所以,这个过程并不会阻塞主线程。
小结
这节课,介绍了 Redis 用于避免数据丢失的 AOF 方法。
这个方法通过逐一记录操作命令,在恢复时再逐一执行命令的方式,保证了数据的可靠性和持久性。
这个方法看似“简单”,但也是充分考虑了对 Redis 性能的影响。
总结来说,它提供了 AOF 日志的三种写回策略,分别是 Always、Everysec 和 No,
这三种策略在可靠性上是从高到低,而在性能上则是从低到高。
此外,为了避免日志文件过大,Redis 还提供了 AOF 重写机制,直接根据数据库里数据的最新状态,
生成这些数据的插入命令,作为新日志。
这个过程通过后台线程完成,避免了对主线程的阻塞。
其中,三种写回策略体现了系统设计中的一个重要原则 ,即 trade-off,或者称为“取舍”,
“取舍”指的是:在性能和可靠性保证之间做取舍。
落盘时机和重写机制都是在“记日志”这一过程中发挥作用的。
例如,落盘时机的选择可以避免记日志时阻塞主线程,重写可以避免日志文件过大。
但是,在“用日志”的过程中,也就是使用 AOF 进行故障恢复时,我们仍然需要把所有的操作记录都运行一遍。再加上 Redis 的单线程设计,这些命令操作只能一条一条按顺序执行,这个“重放”的过程很慢。
那么,有没有既能避免数据丢失,又能更快地恢复的方法呢?
当然有,那就是 RDB 快照了。
每课一问
- AOF 日志重写的时候,是由 bgrewriteaof 子进程来完成的,不用主线程参与,我们今天说的非阻塞也是指子进程的执行不阻塞主线程。
但是,你觉得,这个重写过程有没有其他潜在的阻塞风险呢?如果有的话,会在哪里阻塞?
- AOF 重写也有一个重写日志,为什么它不共享使用 AOF 本身的日志呢?
问题1
这里有两个风险。
风险一:Redis 主线程 fork 创建 bgrewriteaof 子进程时,内核需要创建用于管理子进程的相关数据结构,
这些数据结构在操作系统中通常叫作进程控制块(Process Control Block,简称为 PCB)。
内核要把主线程的 PCB 内容拷贝给子进程。
这个创建和拷贝过程由内核执行,是会阻塞主线程的。
而且,在拷贝过程中,子进程要拷贝父进程的页表,这个过程的耗时和 Redis 实例的内存大小有关。
如果 Redis 实例内存大,页表就会大,fork 执行时间就会长,这就会给主线程带来阻塞风险。
风险二:bgrewriteaof 子进程会和主线程共享内存。
当主线程收到新写或修改的操作时,主线程会申请新的内存空间,用来保存新写或修改的数据,如果操作的是 bigkey,也就是数据量大的集合类型数据,那么,主线程会因为申请大空间而面临阻塞风险。
因为操作系统在分配内存空间时,有查找和锁的开销,这就会导致阻塞。
问题2
如果都用 AOF 日志的话,主线程要写,bgrewriteaof 子进程也要写,
这两者会竞争文件系统的锁,这就会对 Redis 主线程的性能造成影响。

若有收获,就点个赞吧
0 人点赞
