简介
作业类型
Yarn的由来
资源调度器有哪些
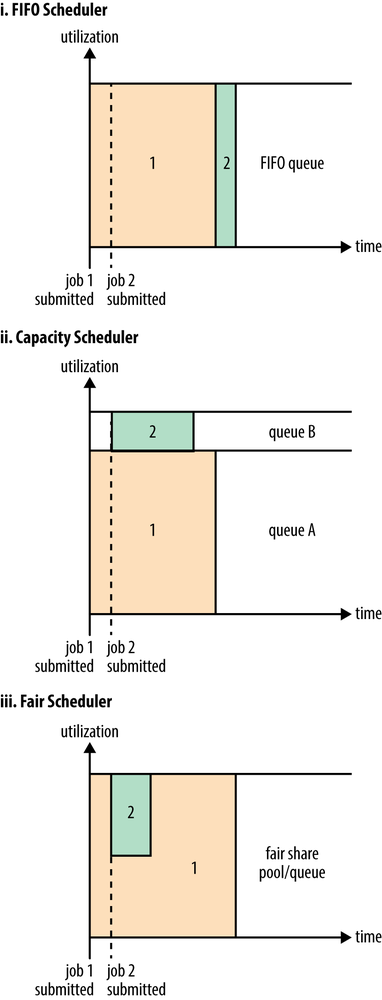
FIFOScheduler(先进先出调度器):
不支持抢占先机。如果有运行特别慢的任务,会影响其他任务
FairScheduler(公平调度器):
每个用户公平共享集群资源,支持抢占先机,如果有的任务长时间占用大量资源,超出其应该分配的资源比例,会终止得到过多资源的任务
CapacityScheduler(容量调度器):
有层次结构的队列,每个队列分配一定的容量(比如将小job和大job分配到不同的队列),单个队列内部支持FIFO
基本架构
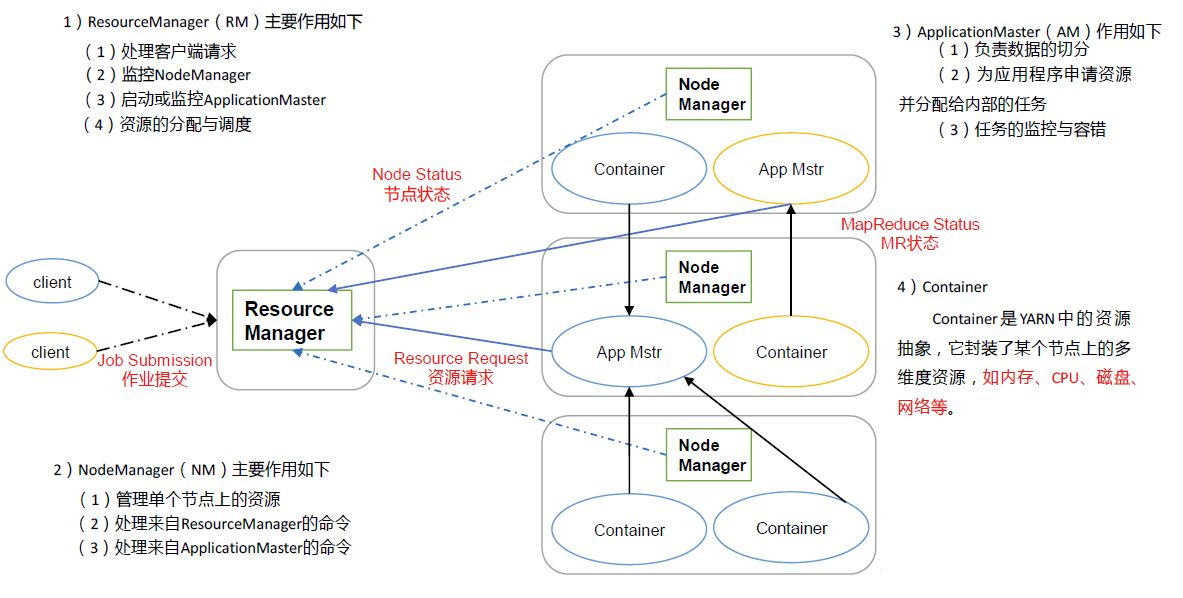
yarn的组件
ResourceScheduler插拔式组件
ResourceScheduler事件处理
Slot VS Container
slot决定cpu和内存的大小
container个数计算公式
总结
- RM和AM本质上就是对jobtracker进行绝对权力的肢解
- AM是一个任务的主
- NM是节点的主
- 1.0 mapreduce -> job
- 2.0 mapreduce -> application
YARN的工作机制
Yarn作业提交过程
资源表示模型
yarn支持的调度语义
yarn不支持的调度语义
资源调度模型
双层调度模型
资源保证机制
资源分配算法资源抢占模型
YARN容错能力
- 任务失败
- 任务VM会在退出之前向父 applicationmaster发送错误报告,记入用户日志,并释放容器以便资源可以为其他任务使用。 applicationmaster会尝试在其他节点重新调度执行任务,默认4次
- RM挂掉
- 单点故障,新版本可以基于 Zookeeper实现HA高可用集群,可通过配置进行设置准备RM,主提供服务,备同步主的信息,一旦主挂掉,备立即做切换接替进行服务
- NM挂掉
- 普通情况下,NM不止一个,当一个挂了,会通过心跳方式通知RM,RM将情况通知对应AM,AM作进一步处理(将原来这个机器上启动的任务交给另外节点接管
- 如果该nm上有am,整个任务挂掉了
- 如果该nm上没有am,整个任务不会挂掉
- AM挂掉
笔者强调:
- Yarn并不清楚用户提交程序的运行机制,只提供运算资源的调度(用户程序向yarn申请资源,yarn负责分配资源)
- Yarn中的主管角色是ResourceManager,具体提供运算资源的角色是NodeManager
- Yarn与运行的用户程序完全解耦,意味着Yarn上可以运行各种类型的分布式运算程序,如Spark、MapReduce、Storm、Tez等,前提是这些技术框架中有符合Yarn规范的资源请求机制即可
- 因为Yarn不参与用户程序的执行等,使得Yarn成为一个通用的资源调度平台。企业中以前存在的各种计算引擎集群都可以整合在一个资源管理平台上,提高资源利用率
- 调度器不参与任何与具体应用程序相关的工作,如不负责监控或者跟踪应用的执行状态等,也不负责重新启动因应用执行失败或者硬件故障而产生的失败任务,这些均交由应用程序相关的Application Master完成。
提交流程讲的很细

若有收获,就点个赞吧
0 人点赞
