2.1.1 Shuffle 原理
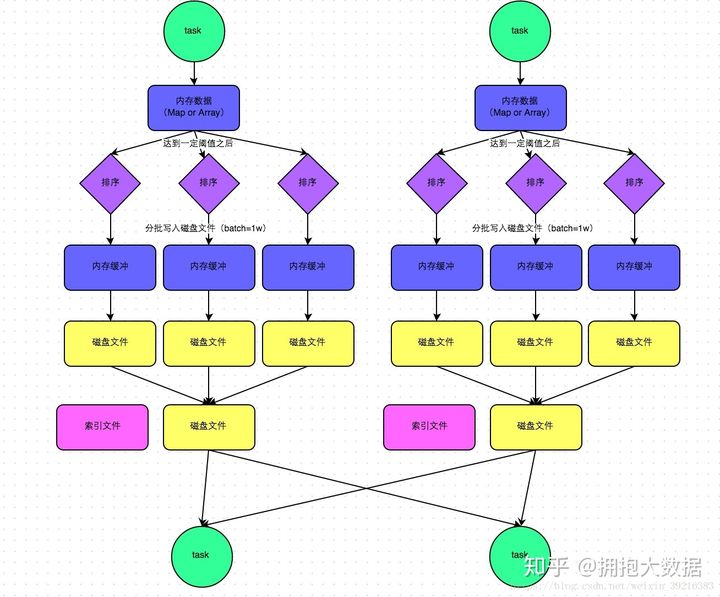
2.1.1.1 SortShuffle
- mapTask将map(聚合算子)或array(join算子)写入内存
- 达到阀值发生溢写,溢写前根据key排序,分批写入磁盘,最终将所有临时文件合并成一个最终文件,并建立一份索引记录分区信息。一个mapTask最终形成一个文件。
reduceTask拉取各个task中自己的分区数据去计算。
2.1.1.2 和hadoop shuffle的区别
两者触发shuffle的前提条件?
- MR没有所谓的DAG划分,一次MR任务就意味着一次shuffle
- spark则是RDD驱动的,行动算子触发时才会按宽窄依赖划分阶段,只有宽依赖才会发生shuffle
- 两者的排序区别?
- MR在reduce端还会进行一次合并排序
- spark则在map端就完成了排序,采用Tim-Sort排序算法
- 两者存数据规则?
- MR的reduce拉取的数据直接放磁盘再读
- spark则是先放内存,放不下才放磁盘
- 两者是什么时候开始计算的?
- MR在数据拉取完毕后才开始计算
- spark则是边拉边计算(reduceByKey原理)
基于以上种种原因,MR自定义分区器时往往还需要自定义分组,spark则不需要(或者说map结构已经是自定义分组了)。
2.1.2 Spark Job 提交流程(重点)
2.1.2.1 standalone
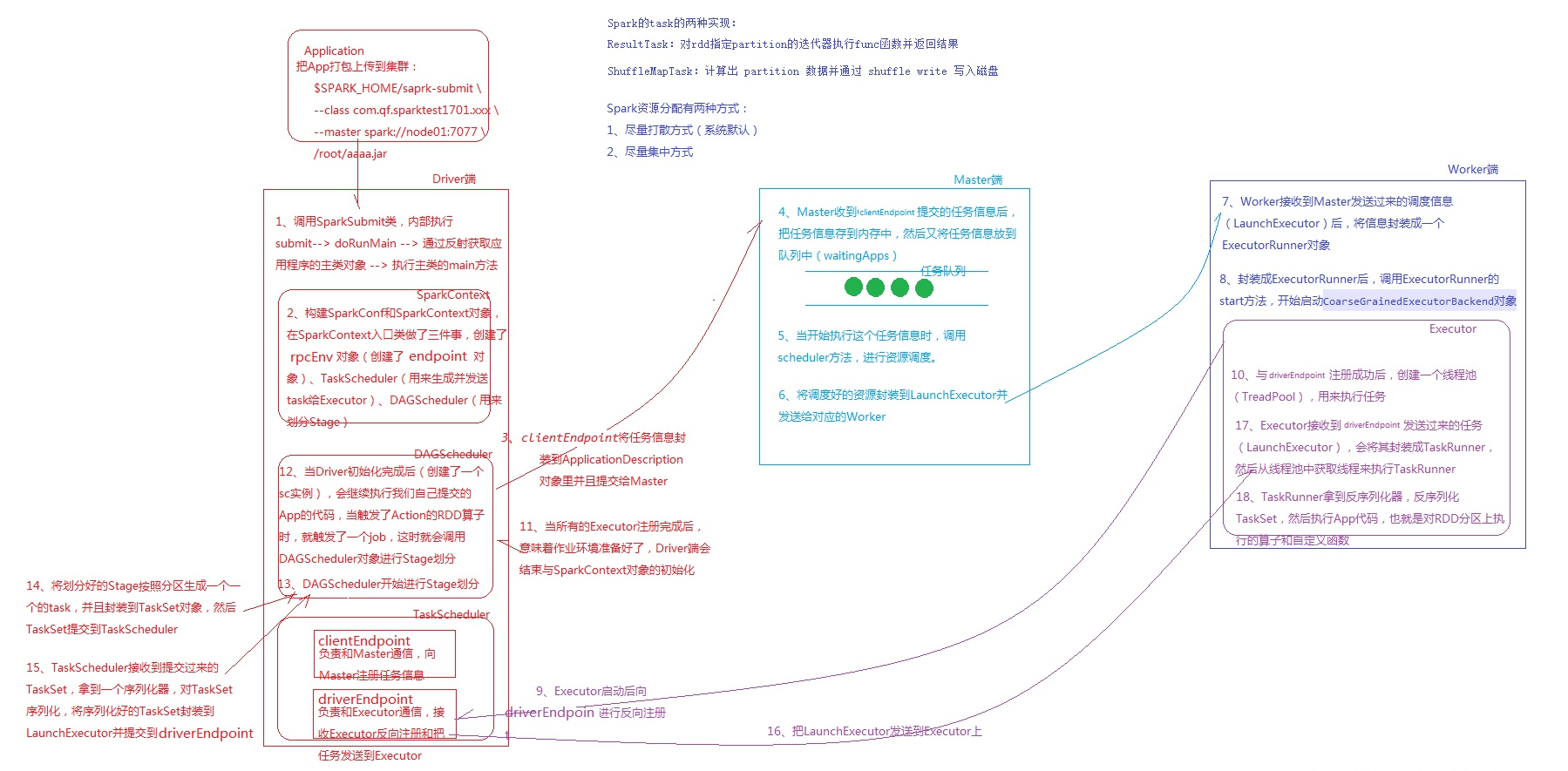
driver端:通过反射获取主类执行main方法 -> 创建sparkconf和sparkContext,创建通信环境、后端调度器(负责向master发送注册信息、向excutor发送task的调度器)、task调度器、DAG(根据宽窄依赖划分stage)调度器 ->封装任务信息提交给Master
- Master端:缓存任务信息并将其放入任务队列 -> 轮到该任务时,调用调度方法进行资源调度 ->发送调度信息给对应的worker
- Worker端:worker将调度信息封装成对象 -> 调用对象的start方法,启动excutor进程
- Excutor进程:启动后向driver端反向注册(driver端拿到信息后注册excutor,向其发送任务) -> 创建线程池,封装任务对象 -> 获取池中线程执行任务 -> 反序列化TastSet,执行给定的各种算子步骤
2.1.2.2 yarn-client
/??2.1.2.3 yarn-cluster
/???2.1.3 Job 运行原理
**
阶段一:我们编写driver程序,定义RDD的action和transformation操作。这些依赖关系形成操作的DAG。
阶段二:根据形成的DAG,DAGScheduler将其划分为不同的stage。
阶段三:每一个stage中有一个TaskSet,DAGScheduler将TaskSet交给TaskScheduler去执行,TaskScheduler将任务执行完毕之后结果返回给DAGSCheduler。
阶段四:TaskScheduler将任务分发到每一个Worker节点去执行,并将结果返回给TaskScheduler。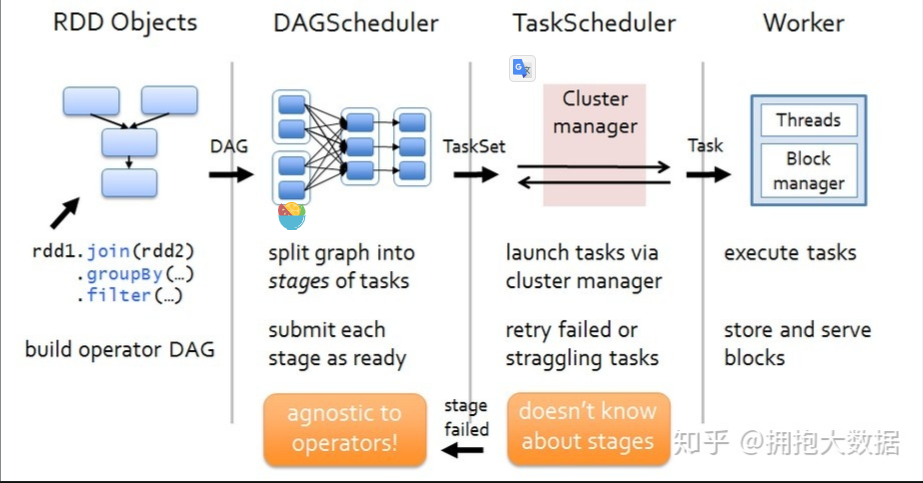
2.1.4 Task 重试与本地化级别
TaskScheduler遍历taskSet,调用launchTask方法根据数据”本地化级别”发送task到指定的Executor
task在选择Executor时,会优先第一级,如果该Executor资源不足则会等待一段时间(默认3s),然后逐渐降级。2.1.4.1 本地化级别
- PROCESS_LOCAL 进程本地化
- NODE_LOCAL 节点本地化
- NO_PREF 非本地化
- RACK_LOCAL 机架本地化
- ANY 任意
2.1.4.2 重试机制
taskSet监视到某个task处于失败或挣扎状态时,会进行重试机制
当某个task提交失败后,默认会重试3次,3次之后DAGScheduler会重新提交TaskSet再次尝试,总共提交4次,当12次之后判定job失败,杀死Executor
挣扎状态:当75%的Task完成之后,每隔100s计算所有剩余task已执行时间的中位数,超过这个数的1.5倍的task判定为挣扎task。2.1.5 DAG原理(源码级)
- sparkContext创建DAGScheduler->创建EventProcessLoop->调用eventLoop.start()方法开启事件监听
- action调用sparkContext.runJob->eventLoop监听到事件,调用handleJobSubmitted开始划分stage
- 首先对触发job的finalRDD调用createResultStage方法,通过getOrCreateParentStages获取所有父stage列表,然后创建自己。
如:父(stage1,stage2),再创建自己stage3 - getOrCreateParentStages内部会调用getShuffleDependencies获取所有直接宽依赖(从后往前推,窄依赖直接跳过)
在这个图中G的直接宽依赖是A和F,B因为是窄依赖所以跳过,所以最后B和G属于同一个stage - 接下来会循环宽依赖列表,分别调用getOrCreateShuffleMapStage:
— 如果某个RDD已经被划分过会直接返回stageID;否则就执行getMissingAncestorShuffleDependencies方法,继续寻找该RDD的父宽依赖,窄依赖老规矩直接加入:
— 如果返回的宽依赖列表不为空,则继续执行4,5的流程直到为空为止; — 如果返回的宽依赖列表为空,则说明它没有父RDD或者没有宽依赖,此时可以直接调用createShuffleMapStage将该stage创建出来 - 因此最终的划分结果是stage3(B,G)、stage2(C,D,E,F)、stage1(A)
- 创建ResultStage,调用submitStage提交这个stage
- submitStage会首先检查这个stage的父stage是否已经提交,如果没提交就开始递归调用submitStage提交父stage,最后再提交自己。
- 每一个stage都是一个taskSet,每次提交都会提交一个taskSet给TaskScheduler

若有收获,就点个赞吧
0 人点赞
